基于云计算的移动商业智能系统研究*
2011-11-07曾蔚
曾 蔚
(泉州师范学院数学与计算机科学学院,福建 泉州 362000)
基于云计算的移动商业智能系统研究*
曾 蔚
(泉州师范学院数学与计算机科学学院,福建 泉州 362000)
针对传统商业智能系统在实时性、交互性和通用性上的不足,通过借鉴云计算强大的计算和存储能力,提出了一种Hadoop与关系数据库相结合的高实时移动商业智能系统解决方案.系统采用Hadoop架构替代数据仓库,实现了海量数据的分布式存储及分析计算,将高实时及高效请求交给处理效率更高的关系数据库,充分利用云计算的虚拟技术提升移动商业智能系统的海量数据处理能力;不仅降低了成本,更使得企业资源得到充分、灵活的应用,提高企业市场快速反应力与竞争力.
移动商业智能;云计算;Hadoop;关系数据库;Map/Reduce
传统的商业智能系统大多只为决策人员服务,且受到安全因素影响,分析数据更多地只能在本地用户终端体现,而体现的方式几乎都是普通的电脑.随着计算技术和互联网技术的飞速发展,销售、市场和决策人员的流动性和活动空间越来越大,涉及决策的管理人员越来越多,信息传递的实时性和交互式要求越来越高,这就对商业智能提出了更高的要求.下一代商业智能的发展要求其不仅仅能为高层决策者提供战略型决策,同时也能为企业内其他层次用户提供战术型决策和操作型决策[1].而企业内中层、基层管理人员及一线员工通常因外出工作而无法及时在电脑前查询分析数据.同时,近年来发行的各种智能手机及平板电脑已经能够存储大量数据,提供丰富的人机交互,甚至能展现各种复杂的可视化数据,这使得将商业智能分析数据移植于移动设备成为可能.然而,目前移动设备的计算能力和存储能力与PC机相比仍然存在很大的差距,具备强大的计算力和存储力的云计算为实现终端的智能提供了保证,将大量的计算和存储操作运行在廉价且高效的云中,将PC机、移动终端设备与瘦终端作为云计算的端,将商业智能分析通过用户随身携带的智能手机等移动终端将信息实时交付给企业内所有层次用户,甚至是客户及商业合作伙伴,这将使得企业能够对面临的问题做出快速反应,改善客户服务,从而赢得竞争优势,使企业资源得到充分、灵活的应用.
1 云计算与移动商业智能
1.1 移动商业智能
随着移动互联网的迅速发展,移动商业智能己成为商业智能的一个新的发展方向.基于移动互联网应用的商业智能不仅能够将过去局限的商业智能应用扩展到企业各层次员工,提高商业智能系统的利用率,而且还使得商业智能系统提供实时访问分析成为可能.与传统商业智能相比,移动商业智能具备以下几个特点∶第一,能够随时随地实时访问企业商业智能应用,员工不再因地理位置而受访问限制;第二,信息主动推送及个性化定制,企业可根据实际情况预先为各类员工定制按时推送信息,也可根据用户的个性化定制进行信息推送服务;第三,实时监控预警,当突发事件出现时,系统直接将警报信息发送到用户的移动设备,这使得员工可以及时采取措施避免损失.
1.2 云计算与移动商业智能
云计算是一种近几年兴起的一种新型技术架构,将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算能力、存储空间和各种软件服务[1].云计算具有低成本、安全可靠、可扩展等突出优点,它通过虚拟机、镜像部署执行等方法为用户提供服务[2].云计算与商业智能的结合将进一步促进移动商业智能的应用.首先,云计算可以增强商业智能处理海量数据的能力.将运算及存储能力通过网络迁移到云端,能够完成PC机无法应付的数据处理任务,用户只需通过PC机、移动设备等终端即可完成类似以往在PC机上的各种操作.而用户也无需为商业智能应用添置高性能移动设备,因为云计算最大程度地实现了资源共享,消除了时间和空间的限制.除此之外,传统商业智能的海量数据处理集中于数据仓库,近年来数据仓库的发展己能够大规模并行处理海量数据并对分析数据进行高效管理,而受到Map/Reduce框架强力支持的Hadoop是一种基于集群分布式架构,不论海量数据处理、成本、运算速度还是稳定性都优于数据仓库.其次,云计算能够提升商业智能的时效性.云计算能够让商业智能在更短的时间内获取交易数据,执行更强的数据分析功能,在突发事件发生时提供及时的信息反馈,充分发挥移动商业智能的实时优势[3].第三,云计算与商业智能的结合将降低成本.传统基于数据仓库的商业智能部署相当昂贵,除商业智能与数据仓库以外还需要承担IT成本和部署、前端商业智能展现工具的费用,在低成本地区建立大规模数据中心可以帮助企业在电力、网络带宽、软件和硬件等方面降低成本.以往资金能力不足以搭建自己的商业智能平台的中小企业无需购买任何硬件,无需安装软件,只需通过SaaS模式租用位于云端的移动商业智能应用.云计算与商业智能的结合可以使企业以较少的价格得到灵活且有弹性的商业智能服务.
2 基于云计算的移动商业智能架构
系统利用云计算的虚拟化技术建立了基础设施层、平台层、支撑层和应用层,其架构如图1所示.
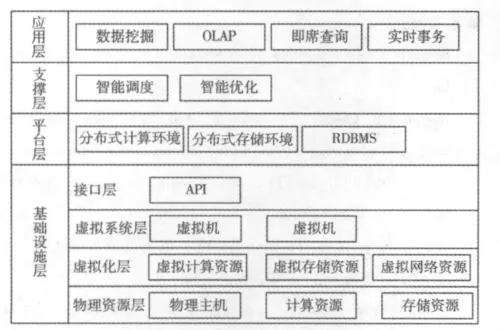
图1 基于云计算的移动商业智能系统架构
应用层提供了各种商业智能应用,如数据挖掘、OLAP、即席查询及实时事务处理.PC机及瘦客户端用户可以通过浏览器或者特定的客户端访问和使用这些服务,持有移动设备用户可使用各类移动终端通过移动通信网或无线网连接平台使用服务,系统将为持有不同类型设备的用户提供不同的界面及功能.
支撑层负责处理应用层中的应用请求,对其业务处理逻辑进行智能调度.商业智能系统面临的是巨量且不同存储和计算的请求,可分为海量数据处理请求、日常信息处理请求、高性能计算请求等.智能调度根据请求类型进行判断,若该请求对计算需求很小可以在关系数据库中找到则直接访问关系数据库;若请求需要较大的计算量和存储量则需要提交云计算平台执行并行计算.由于用户的移动设备可能是平板电脑等高性能智能设备,也可能是较为普通的低性能手机,智能优化识别各种移动设备不同的存储和计算能力并依据用户请求内容进行度量,为不同类型移动设备提供最适合其存储和计算能力的浏览结果.
平台层采用了分布式存储环境与关系数据库相结合的模式.企业各类网站产生的数据通过数据分析及抽取,将高实时性数据及低实时性数据分别抽取到关系数据库与分布式存储环境中,部分被频繁请求的分析数据也在分布式计算环境完成后同时导入到关系型数据库和分布式存储环境中,进一步提高移动商业智能系统的访问速度.分布式计算平台将用户请求分解为多个并行的子任务,充分利用环境中的多个计算资源节点,加速分析计算处理的过程.
基础设施层分为接口层、虚拟系统层、虚拟化层和物理资源层这四个子层.物理资源层将服务器、存储和网络等资源组织为资源池的方式进行统一管理,以获得最大资源利用率.虚拟化层利用虚拟化技术将硬件资源划分为“虚拟硬件”,从而提供虚拟CPU、存储、虚拟网络等更细粒度的资源.虚拟系统层打破了操作系统与物理资源之间的约束,该层中的虚拟机只能看到虚拟化层提供的虚拟硬件,不必考虑物理服务器的情况,从而提供更高的资源利用率和灵活性.接口层将基础设施的服务通过API的方式提供给上层.
3 Hadoop与关系型数据库相结合的海量数据实时计算
Hadoop是一个能够对大量数据进行分布式处理的框架,实现了 Google的 Map/Reduce应用[4].Hadoop是一种典型的主从式结构,其基本结构如图2所示,上层是主从式的Map/Reduce处理,下层是主从式的HDFS文件系统.HDFS集群包括一个NameNode和若干DataNode,NameNode负责管理各个DataNode和维护系统的元数据,DataNode用于实际对数据的存放,与用户直接建立数据通信.NamedNode作为文件系统负责运行在Master上,而DataNode运行在每个机器上.Hadoop实现了 Google的 Map/Reduce,JobTracker负责整个Map/Reduce的控制工作运行在Master上,TaskTracker则运行在每个机器上执行Task.对于一个大文件,Hadoop把它切割成一个个大小为16MB~64MB的块.这些块是以普通文件的形式分布存储在各个节点上的.通过此种方式,来达到数据的安全和可靠.
系统必须满足实时查询和数据挖掘,传统做法是让实时性查询由关系数据库承担,而数据仓库负责低实时的数据挖掘与分析,但是一旦数据量庞大时使用数据仓库将直接导致数据检索速度急剧下降,因此平台采用hadoop来替代数据仓库实现低实时的数据挖掘.但并不是使用Hadoop替换关系数据库与数据仓库,Hadoop的数据装载开销比关系数据库小,但效率却依然不如关系数据库[5],因此为同时满足用户高实时请求及高计算和存储能力请求,将关系型数据库与Hadoop相结合实现海量数据实时计算,其架构如图2所示.
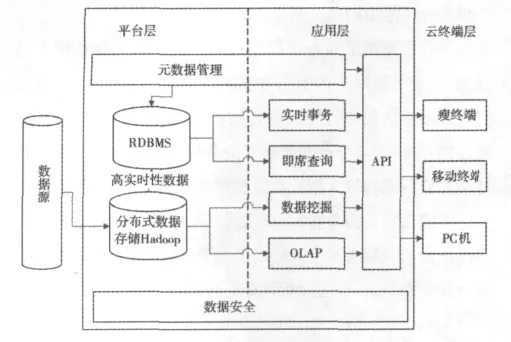
图2 Hadoop与关系型数据库相结合的海量数据实时计算架构
Hadoop的Map/Reduce架构可以快速地装载并处理大规模数据,因此由Hadoop负责从数据源抽取数据并对其进行解析,将一些要求高响应速度的数据或计算需求小的数据装载到关系数据库中实时响应用户请求,而对于某些请求频率较高的低实时数据则在Hadoop中进行预处理,待Map/Reduce完成分布式计算后将结果也存入关系数据库.
Hadoop中只有一个NameNode节点,当处理某些大型作业时可能需要运行数小时甚至是数天才能完成,作业运行时间偏长的缺点是NameNode一旦失败将丢失所有己经完成的中间结果,因此考虑对大型作业在其运行过程中定时保存中间结果,若NameNode失败还可以从磁盘中继续读入己完成中间结果继续处理.因此不论在Map还是Reduce部分均根据作业大小为其分配一定大小的内存来保存中间结果,待对应的内存写满才写入磁盘空间,且写入磁盘前还应对中间结果进行压缩来加快数据在内存与磁盘之间的传输速度.Hadoop为每个大型作业均分配一定大小的缓存,并定时将己完成的中间结果写入到缓存中,当缓存写满时则将中间结果进行压缩存入磁盘.若作业失败则可从己保存在磁盘中的中间结果继续计算,而不是重头开始计算.当作业完成时还必须有一个合并过程将所有的中间结果并行合并.当作业的第一个中间结果结束后,所有的Reduce均从己完成的中间结果并行下载该Reduce所需的数据块.同样地,为了提高IO读写效率,每个Reduce也将下载的中间结果缓存在一定大小的内存中,待对应内存写满时进行压缩并写入磁盘.当Reduce将所有的中间结果上对应的数据块全部下载完成后,再将数据块合并接着进行计算.
4 结论
鉴于传统的商业智能系统在实时性及利用率过低等方面的不足,结合云计算提出了一种具有高实时性的移动商业智能系统解决方案,给出了系统体系结构,结合Hadoop与关系数据库两者的优势,利用Hadoop从数据源中实时将数据载入关系数据库,提出了一种海量数据实时处理方式.基于云计算的移动商业智能系统具备灵活性、实时性等特点,较之传统的商业智能系统不仅降低了成本,还能够更快速地应对市场动态发展所带来的挑战.
[1]Hayes B.Cloud computing[J].Commun ACM,2008,51(7):9-11.
[2]Rajkumar B,Chee S Y,Srikumar V,et al.Cloud computing and emerging IT platforms:Vision,hype,and reality for delivering computing as the 5thutility[J].Future Generation Computer Systems,2009,25(6):599-616.
[3]穆向阳,缪宁,陈明,等.云计算环境下BI对企业核心竞争力的影响[J].情报杂志,2010,29(6):52.
[4]王鹏.云计算的关键技术与应用实例[M].北京:人民邮电出版社,2010.
[5]Pavlo A,Paulson E,Rasin A,et al.A comparison of approaches to large-scale data analysis[A].Proceedings of the 35thSIGMOD International Conference on Management of Data[C].New York:SIGMOD,2009.
(责任编校:晴川)
TP399
A
1008-4681(2011)05-0048-03
2011-07-11
曾蔚(1982-),女,福建泉州人,泉州师范学院数学与计算机科学学院助教,硕士.研究方向∶数据库技术、云计算.
