基于SWN理论的关键字抽取策略
2011-08-29赵峰
赵 峰
同济大学电子与信息工程学院,上海 201804
1 文本预处理和分词
文本预处理[1]是进行关键字抽取的第一个步骤。文本预处理操作,一般包括去除文档中的格式标记、过滤非法字符、字母大小写转换、去除停用词和稀有词、词干化处理和中文分词处理等处理步骤。
基于字符串匹配的分词方法通常又称为机械分词法或词典法,这种方法是基于一个相对完备的词典,对待分词文本按照特定的规则逐个进行字符串匹配,如果匹配则认为是一个词,一般在机械分词法中用少量词法、语法和语义信息等对分词系统辅助,使其达到最佳效果,由于其实现简单,目前几乎所有的分词方法都属于这一种。
根据每次匹配时优先考虑长词还是优先考虑短词,将基于字符串匹配的分词法又分为最大匹配法和最小匹配法。由于大多数汉字均可构成单字词,所以按最小匹配法分词的结果往往因分得太细而不合要求。反之,当待分词文本中出现“词中含词”的情况时,最大匹配法就可能因分得太粗而不合要求。本设计采用最大匹配算法进行分词。
2 共现分析
共现分析[5]是词语网络构建和分析的基础理论和方法论。
由于文本的半结构化特性,现有的成熟的数据挖掘技术无法发现文本中蕴含的大量信息;针对文本数据库内容的特殊性,提出许多文本挖掘方法。在众多文本挖掘方法中,共现分析以科学的分析原理、简便的操作流程和客观的分析结果,逐渐受到文本知识挖掘人员的青睐。该方法以文本的最小内容单位-词汇为分析对象,挖掘词汇语义,以此为基础实现文本内容的有效表示;并能对大规模文本集合进行文本精练和知识提取,可完成文本总结、文本分类、文本聚类、关联分析、分布分析及趋势预测等多种文本挖掘任务。
共现窗口是共现分析中一种非常重要的研究,即在同一共现窗口中出现的词是有关联的,具体到商品信息中,共现窗口可以选择一个自然段,也可以选择一个句子,即在一句话中出现的分词是有关联的。
3 SWN理论
3.1 平均最短路径长度
在网络中,两点间的距离被定义为连接两点的最短路所包含的边的数目,把所有结点对的距离求平均,就得到了网络的平均距离(average distance,也叫平均最短路径变化量)L。L表示网络的有效大小,代表两个结点间的最典型的分离距离。
我们用G表示一个网络所对应的拓扑结构图,N和K分别表示图中的结点总数和边的总数,k为从每个结点引出的平均边数。Ki是从第i个结点引出的边的个数(第i个结点的度)。则:
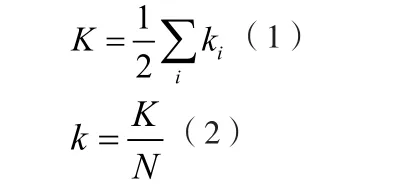
为了说明图的特性,又设dij 表示点vi和vj之间的平均最短路径,用|E(G')|表示任意一个图的G'中边的个数。
下面给出图的平均最短路径变化量的数学定义:
我们把图G中所有点之间的距离的平均值叫图G的平均最短路径长度,可表示为:
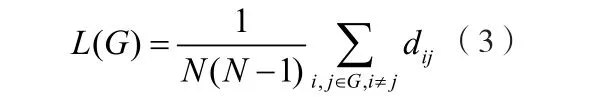
其中L(G)表示图G的平均最短路径长度。
设L为图G的平均路径长度,即所有边的权值之和和与顶点个数的比,L(i)为图Gi的平均路径长度,则在图G中去掉顶点i后形成的图Gi的平均路径变化量ΔLi为

3.2 簇系数
另外一个叫做簇系数(clustering coefficient)的参数,专门用来衡量网络节点聚类的情况。比如在朋友关系网中,你朋友的朋友很可能也是你的朋友;你的两个朋友很可能彼此也是朋友。簇系数就是用来度量网络的这种性质的。用数学化的语言来说,对于某个节点,它的簇系数被定义为它所有相邻节点之间连边的数目占可能的最大连边数目的比例,网络的簇系数C则是所有节点簇系数的平均值。
假设无向网络中顶点i与其他顶点相连的边数为ki条,这ki个顶点称为顶点i的邻居。显然,这ki个顶点之间最多可能有ki(ki-l)/2条边。而ki个顶点之间实际存在的边数为Ei,将实际存在的边数Ei与可能的边数ki(ki-l)/2相比得到顶点i的聚类系数Ci,公式如下:

图G的簇系数C是所有顶点簇系数Ci的平均值,用C(G)来表示:

设C为图G的簇系数平均值,C(i)为图Gi的簇系数平均值,则在图G中去掉顶点i后所形成的图Gi的簇系数变化量为ΔCi为
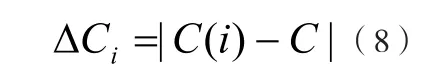
3.3 SWN理论
近年来复杂网络研究的兴起,学者们关注网络结构复杂性以及网络行为之间的关系。为研究不同复杂网络的结构共性,需要一种描述网络的统一工具,数学上称为图。任何一个网络都可以看作是由一些顶点按某种方式连接在一起而构成的图。复杂网络所构成的图普遍具有较大的簇系数和较小的平均最短路径长度,此时高聚类性和小世界效应会在网络中同时呈现,我们把这种网络叫做小世界网络(Small World Network),经过大量实验证实:SWN能客观准确的反映现实世界中的很多的复杂系统,在很多领域得到了广泛的应用。因此我们也可以将该理论用在关键字的抽取策略之中。
4 本文抽取算法步骤
首先对一篇待抽取关键字文本进行文本预处理,得到一个分词集合。然后由共现分析理论得到该文本的图结构,该图显然具有SWN理论所需的基本要素,即为一个小世界网络。在图中依次删除每一个结点,即每一个分词,然后计算该图的平均最短路径长度和簇系数变化量,如果两者变化值越大,则说明对该图的影响越大,即对文本的影响程度越大,则应该成为文本的关键字,否则不列为关键字。抽取关键字的数目可以根据具体情况而定。
5 结论
现阶段,文本挖掘领域并没有一种固定的、非常有效的从文本中提取关键词语的算法。其他的抽取算法也有很多,比如先计算文本各项的权重,以关键项及权重来表示文本特征,然后按照这些文本特征将多文本聚类,计算相似度,对每一聚类赋以关键字,以此来达到每篇文本的关键字抽取。随着越来越多的研究人员进入该领域研究,相信关键字抽取领域一定会有更好的进展。
[1]杨晖.基于标签分类内容共享平台的网页自动文摘模型[M].北京:清华大学出版社,2007:121-125.
[2]Van Charles.Information Retrieval.London:Butterworths,1979:54-59.
[3]H.P.Luhn.The automatic creation of literature abstracts.Sebastopol CA:IBM Journal of Research and Development,1958:34-38.
[4]李蕾,钟义信,郭祥昊.面向领域的理解型中文自动文摘系统[J].计算机研究与发展,2000(2):23-28.
[5]季姮,罗振声,万敏等.基于概念统计和语义层次分析的英文自动文摘研究[J].中文信息学报,2003(12):36-42.
[6]姜贤塔,陈根才.利用语料库技术的中文自动文摘系统[J].中文信息学报,1999(4):13-18.
[7]万敏,罗振声,季姮,等.基于概念统计的英文自动文摘研究[J].计算机工程与应用,2002(12):14-19.
