汉语共时语料库与追踪语料库: 语料库语言学的新方向
2011-06-28邹嘉彦邝蔼儿蔡永富
邹嘉彦,邝蔼儿,路 斌,蔡永富
(1.香港教育学院 语言资讯科学研究中心;2. 香港城市大学 中文、翻译及语言学系)
1 前言
20世纪末信息技术的兴起、互联网的普及以及汉语自然语言处理的技术不断提升和成熟,促使汉语语料库技术飞速发展[1-2]。20世纪80年代开始,世界各地区出现了许多汉语语料库。随着时间的推移,不少技术方面的困难得到克服,诸多难题得以解决,不少障碍得到清除,例如汉字的输入(计算机或手机)、输出和查询,编码的统一,大量资料的存储,计算速度的高速提升等。
进入21世纪,汉语语料库的发展更加深入和多元化。从内容上看,有多种发展,包括古汉语语料库、文言白话平行语料库等。从形式上看,有不少的专项语料库出现,例如儿童语料库、科技论文语料库和专利语料库[3]。从语种上看,除了单语种的汉语语料库,涉及汉语的多语种语料库快速发展,为跨语言的信息处理和检索提供了坚实基础,其中包括可比语料库(Comparable Corpora)和平行语料库(Parallel Corpora)。从加工深度上看,汉语语料库的标注层次越来越丰富,包括词性、句法、语义等深层次标记,例如宾夕法尼亚大学所建的中文树库和中文命题库,台北中研院中文树库、清华中文树库[4]、哈工大依存树库等。
这些新构建的汉语语料库,大多是为了各种语言工程而构建,比如自动分词[5]、词性标注、句法分析和语义分析等。值得注意的是,这些语料库很大部份是暂时性的、开放性的,有的仅收集数年的语料,很多现在已停止增补,在时间上没有持续性,例如北京语言学院(今北京语言大学)语料库、台北中研院平衡语料库[6-7]及北京航空学院(今北京航空航天大学)语料库等。
有的汉语语料库虽然持续搜集新的语料,但语料本身是未经处理的或只是自动处理而未经人工校对,例如LDC(The Linguistic Data Consortium)发布的中文Gigaword语料库[8],自2003年发布第一版,至今已更新至第四版,其语料来源也从最初的两家新闻社(新华社和台北中央社)扩展至另外六家(《联合早报》、法新社、中国新闻社、《光明日报》、《人民日报》、《解放军报》),但其为未经处理的生语料、且选取资料的时间跨度各不相同,比如最新添加的四家新闻社的新闻资料时间跨度只覆盖2006年11月至2008年12月。有标记的Gigaword语料库[9]对语料进行了自动处理,包括分词和词性标注,但其结果未经全面人工校对。这种情况可能影响一些追踪应用的准确性(见下面第2节)。
时至今日,语料库面临新的发展方向,即(1)“量”与(2)“质”的提高。网上可供利用的生语料可谓无穷无尽,有关资料的甄选及应用,成为语料库语言学发展的首务。如何进一步提升语料库的质素及用途,最大效率应用庞大的资料,进而从语言学范畴跃升到人民、社会科学等其他领域,是语料库语言学的新任务。与其他语料库有所不同的LIVAC汉语共时语料库持续处理泛华语地区17年4亿字的语料,演变成为真正的“时间锦囊”,为紧密追踪、科学观察泛华地区语言现象及有关社会文化演变,提供了坚实的基础和科学依据。
2 LIVAC语料库的延伸: 从“共时语料库”到“追踪语料库”
由香港教育学院语言资讯科学研究中心(前身为香港城市大学语言资讯科学研究中心)语料库实验室于1995年7月创建的LIVAC(Linguistic Variation in Chinese Speech Communities)共时语料库(以下简称LIVAC)[10],一开始就刻意有异于过去的构思,在长期、持续上做了充分准备,除了构建语言工程外,也以服务社会、追踪词汇语法和社会文化的发展为指标。自1995年启动,坚持共时性、历时性,至今已有17年。十多年来的实践充分证明,该语料库为跟踪、观察泛华地区语言现象及其背后社会文化演变,提供了量化的科学研究依据。
LIVAC语料库自1995年起不间断地共时收集、处理和分析来自包括香港、澳门、台北、北京、上海、广州、深圳以及新加坡、日本等多地有代表性的中文报章与传媒、电子新闻报道,选取内容包括各媒体中的社论、国际新闻、当地新闻、综合新闻、经济新闻、体育新闻、娱乐新闻以及广告等。
本语料库采用前所未有的严谨“视窗”模式,最大特点首先是“共时性”,即定期收集各地同日的同步语料,每次约5万字。由于收集内容上刻意相约或重复,以致可以专注探索用语的实况与内容表达比较。其次是兼顾“历时性”,自1995年至今历时十多年来从未间断,至今仍在运行,方便客观窥探到各种大小视窗内有代表性语言的全面动态以及有关语言背后的社会文化状况,可利用一系列大小连续的视窗来探索观察时期内不同地方的各种变化。
到2011年,LIVAC语料库处理过的总字数达4亿,收集的词种数目超过160万条,并进行了多项语言分析和标注(包括分词、词性标注及人工校对)*LIVAC语料库十多年恒长的自动分词,人工校对前平均准确率很难超过88-89%,因为部分新闻语料包括很多库外新词。,累积了大量有用的统计数据,在语言工程上取得了多方面成果。同时,这个跨期长、字数多、规模巨大的语料库,也为各个学科追踪研究提供了一个可靠、翔实的资料平台。
2000年期间,我们曾就香港回归及千禧年为主题,以LIVAC语料库数据为依据,做了一些有意义的分析和总结。2003年8月,我们在《中文信息处理若干重要问题》一书上发表题为《汉语共时语料库与信息开发》[11],对LIVAC语料库做了详尽介绍,并就共时语料库的特性、结构、信息开发、熵与专有名词等理论做了全面的分析及探讨,尝试为LIVAC语料库做一个重要的阶段性总结。这段期间,我们也与牛津大学出版社、商务印书馆[12]、复旦大学出版社和其他出版社在辞书出版方面进行了合作[13]。
时光荏苒,趁此机会,我们着重以LIVAC语料库21世纪首10年的资料为主,再一次分析和探讨,通过语料库搜集到的资料如何跟踪、分析最近十年来泛华语区汉语字词以及由此反映出来的新社会文化演变和发展趋势。
3 同中存异,异中有同: LIVAC京港台三地词汇异同的分析
汉语言是华夏文化的载体,使用汉语的各主要华人社会依顺各种历史发展都有各种“同”和“异”之处。我们可以从它们的用语寻找这些异同之处,从中了解背后文化发展的“同”和“异”。汉语的字与词有着密切的联带关系,LIVAC大型语料库处理过的语料提供了翔实的资料平台,让我们可以更精确看到各地使用的字、词和词组的相关异同及探索其背后的社会文化意义。
3.1 三地词汇的异同
从LIVAC所有17年语料看(见表1),如果只计京港台三地的近90万词汇,其中三地都同时出现的只占23.53~29.44%,而只在一地出现的词汇分别高达52.04%~61.46%,显示三地虽然同是使用现代汉语,但所用的词汇及用词习惯上仍有较大差异。这除了近代历史、地域原因外,应该与人文、社会制度、生活习惯等因素都有关系,也证实了异中有同的事实。
而只在两地出现的词汇中,香港、北京两地共现的词汇最多,占10%以上,香港、台湾两地共现的词汇次之,占10%左右,北京、台湾两地的共现词汇最少,仅8%以下,这显示在现代汉语17年总的用词方面,港、京两地相同的地方高于京、台两地。从宏观的近代历史角度看,这种情况是可以了解的。
如果缩小视窗范围,将焦点放在最近两年(2009至2010年),分别从三地各抽取最高频3 000词,可以观察到三地词汇同中存异(见图1): 三地同时出现的高频词高达53.4%,并总重复量达80%,说明三地在常用词方面,仍有很大的相似度。但只在两地出现的词汇中,只在港、台两地共现的词汇最多(12.1%),京台次之(9.73%),京港最小(6.9%),这个结果似乎有些出人意外,是否说明常用词方面反映出近两年里港、台两地有较多相同的关注点,而北京的常用词则与香港、台湾有较大的差别?这都值得更深入探讨。
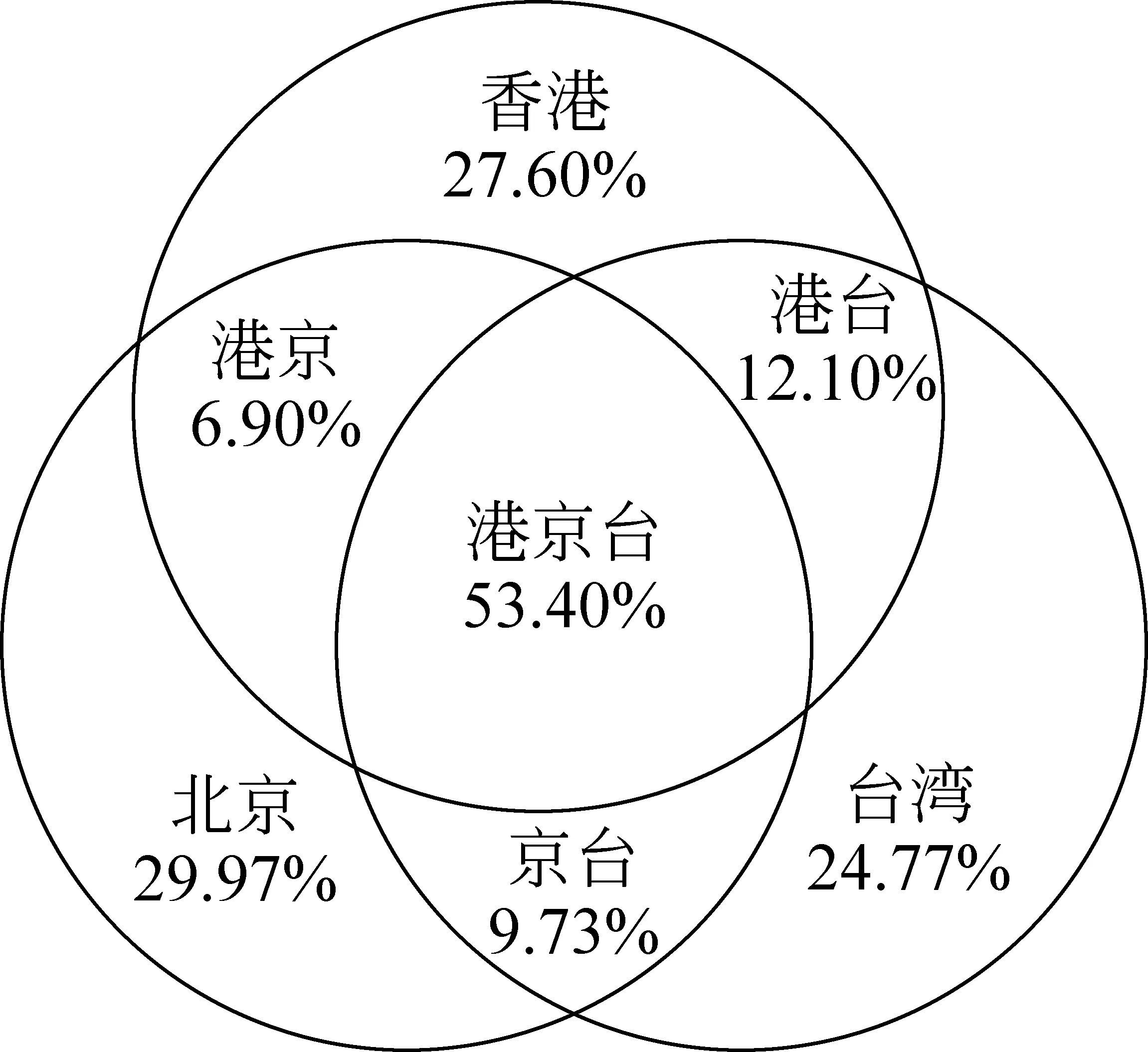
图1 2009年至2010年间三地高频3 000词所占比例
但是,覆盖率的概念需要详解。“熊猫”和“猫熊”两个词,在北京和台北的媒体都有出现过。只是,“猫熊”在台湾地区出现率远远高于中国大陆。这样“猫熊”是否应该算是泛华语的词汇呢?表2展示出不同共现率条件下各地共现词的数量。这也正是计算辞典学方面的一个主题。
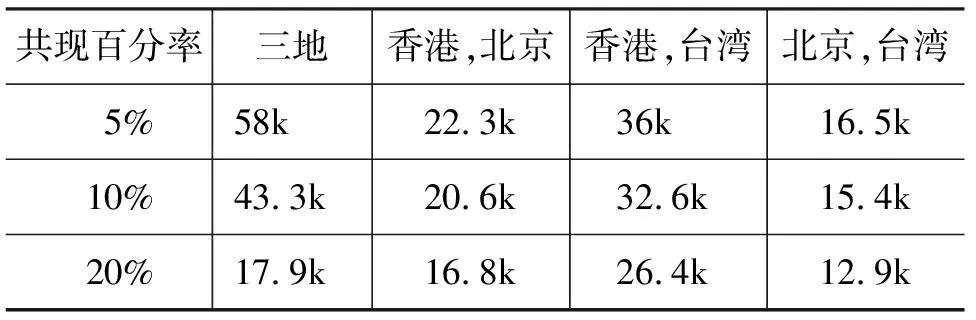
表2 共现词
3.2 三地词汇的兼类现象与流动性
各华语区对使用汉语的标准和习惯有着明显不同,这种同中存异的情况每每见于词汇、语法、词义等各个语言层次,词语兼类与词类的变化正是一个例子。
汉语的词类划分不如英语直接简单,因为汉语的词缺乏形态变化,同一个词形可以用在不同的位置,担当不同的语法角色,因此动词往往被用来修饰名词(如“红烧排骨”的“红烧”不一定是说把排骨红烧,而是指红烧的排骨)、名词又可以用来表达动作(如“每人每天都要微博一下”的“微博”本是名词,现在都用作很多人上网的其中一个动作)。动名兼类的词俯拾皆是。所谓动名兼类,是指一个词被广泛接受为同时拥有动词与名词特质,而这类词很多会经过动词名词化或名词动词化的转化过程,因此观察词语及其词类的流动性,可以比较各个地区在语言使用上的变化和趋向。
我们比较了LIVAC中香港、北京与台北三个子语料库里的动名兼类词[14],发现动词名词化的情况在北京语料出现要比在另外两个子语料库里多。其中在北京语料里,大概有18.5%的动词属于动名兼类,而在香港和台北语料分别只有14.4% 和 15.5% 的动词属于这类。数据一方面反映了汉语语法欧化的程度因地而异,另一方面也反映了不同社会的心理文化,对同一件事情的着眼点、用语表达方式和落墨点也有不同。表3列出了香港子语料库的一些动名兼类的例子,按动名用法的比例,可以分为三种情况: “刚开始名词化”、“动名用法相约”、以及“差不多完全名词化”。
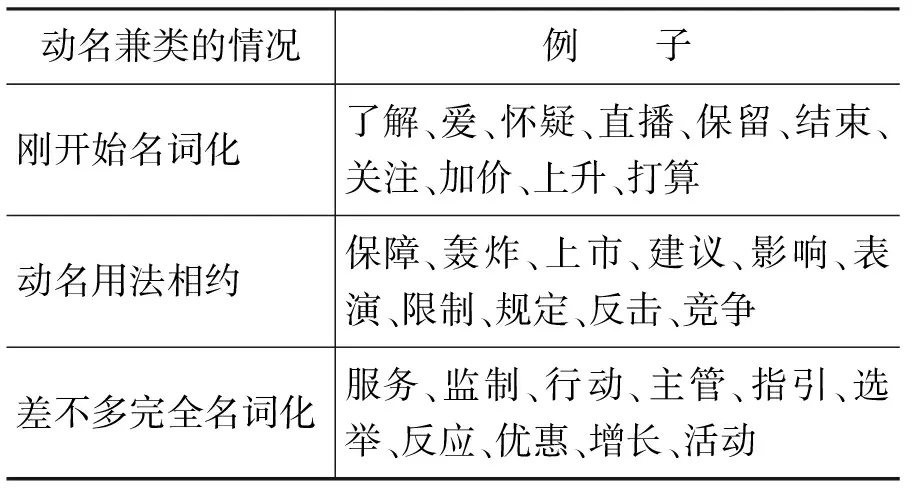
表3 不同阶段的动名兼类词例子(香港语料)
4 树与树林的分别: 词汇的演变与宏观看法
21世纪的首10年,很多新词在结构上有一个共同的特点,就是出现了许多前缀或后缀词素,例如: XX族、XX男、XX女,或者零XX、硬XX、软XX等等。这些词素除了很少一部分是新出现的或外来的词素外,其余大部份都是在旧有意义上加以引申,赋以新的词义。另一方面,它们有很强的构词能力,通过简缩、仿制、替换等方式,衍生出一系列的自成体系的新词。这种现象值得我们关注,尤其是有代表性的新语素,因为它们比个别新词有更深层次的意义,犹如关注个别树与成片树林之间的区别。
4.1 族
“族”本意指有血缘甚至组织的种族、民族、家族,也可以引申指称具各种共同特征的群体,如“语族”、“芳香族”。千禧年后,日语“xx一族”之类词语在两岸三地更流行起来,诱发了汉语里大量“xx族”新词的出现。“族”这个字根源于汉语,日本千多年来吸收汉字、汉语,现在这个“族”字变成了出口转内销,也反映华人开始把一向有宗亲认同的族群传统,延申到没有宗亲关系,而广泛出现以下的新词组。
4.1.1 只要有一些共同特征的群体,如“上班族”、“地铁族”、“受薪族”、“北漂族”、“钟摆族”、“商务族”、“蜗居族”、“纳税族”、“兼职族”、“弱势族”、“脚车族”、“候鸟族”、“早起族”等。
4.1.2 泛指某种宗亲以外而具有某种共同意愿的特征,如“追车族”、“追星族”、“赏樱族”、“血拼族”、“网购族”、“抢盐族”、“退盐族”、“网购族”、“蹭凉族”、“悲催族”。
4.1.3 又或者自认或被认定的某种特征,不管得到认同与否,如“电脑族”、“快闪族”、“单车族”、“背包族”、“隐婚族”、“麦兜族”、“新锐族”、“冲浪族”、“步行族”、“偷供族”、“套现族”、“哈台族”等等。
4.2 男、女
与“族”类似,也可以有多种的“男”和“女”新发展的词组,用来泛指具有某种特征的不同性别人群。这类词已存在多时,例如“猛男”、“舞男”、“卖花女”、“茶花女”、“叻女”等。日文里也有类似词语如“一代男”、“浮世男”、“市女”、“斋女”。但千禧年后,中文里的“男”、“女”新词组出现越来越多,分别指称具某种特征的“男”或“女”的群体或个体。例如:
4.2.1 “男”的有:“型男”、“宅男”、“电车男”、“召妓男”、“四割男”、“事旦男”、“激凸男”、“变态男”、“性侵男”、“花弗男”、“体贴男”、“外遇男”、“家暴男”、“败犬男”。
4.2.2. “女”的有:“熟女”、“剩女”、“应召女”、“骨女”、“洗脚女”、“下岗女”、“陪睡女”、“世青女”、“高职女”、“选秀女”、“躁郁女”、“干物女”、“精障女”。
比较之下发现,各地的“男”类词与“女”类词数量并不均衡,但大自然的分配应该是阴阳对称,应该是“男”、“女”平均分布。然而自然的律理与人为语用所反映的情况大有分别,这是否反映社会上男女地位或工能平等的发展不相对应?与重男轻女社会所引起男女同龄群人数不均有别?颇值得深思。还有的是,千禧年前日语与华语的“男”类词比“女”类词少,然而千禧年后华语的“男”类新词比较多了,这意味着什么呢?
4.3 零
“零”是一个客观的数词,没有客观或主观的价值,但现多用来表示强调“没有”,反映出一种后现代主义要标新立异、表面简单的两极化追求,如:
4.3.1 “零团费”、“零首期”、“零成本”、“零意外”、“零病例”、“零失球”、“零利肉”、“零噪音”、“零转会”、“零包装”、“零当选”、“零生意”、“零命中”、“零存款”、“零堵塞”、“零对白”、“零绯闻”。
此外,还有指抽象性的,难以计算的,如:
4.3.2 “零容忍”、“零交流”、“零拒绝”、“零宽容”、“零投入”、“零睇头”、“零麻烦”、“零创意”、“零受惠”、“零认识”、“零威胁”、“零效率”等。
千禧年后比千禧年前多了约八倍这样的“零”词语,这究竟意味着什么呢?
4.4 软、硬
“软”、“硬”原用来以形容实物,近来已渐渐虚化,一般人从“硬件、硬体”或“软件、软体”延申到熟悉的“硬道理”、“软实力”,近十年来虚化的“软”、“硬”系列词用得越来越普遍,例如:
4.4.1 “硬资产”、“硬推销”、“硬举措”、“硬军事”、“硬摇滚”、“硬执行”、“硬调剂”、“硬方针”、“硬实绩”、“硬优惠”。
4.4.2 “软商品”、“软手腕”、“软规定”、“软优势”、“软学科”、“软形象”、“软贪污”、“软宣传”、“软命题”、“软建设”、“软革命”。
但相比之下,“软”、“硬”系列词并不相等,“软”的新词组出现多于“硬”系词。
同类词组在语法上可由前缀“零”、“软”、“硬”和后缀“族”、“男”、“ 女”等识别,它们的词素由原义引申出新的意义,从这些例子的量与质的分析,可以看到过去二十一世纪前十年华人的社会文化对群体的认同有了新的见解与条件,并让群体种类数量很快增加,对“有”及“没有”绝对性高的分界与要求也越来越注重,而对“男”、“女”的看法也有了分化,并在某种程度上吃“软”不吃“硬”的各种内涵也扩展了并透露出来了。
值得注意的是,从数量上看,“族”类词在台湾最多,“女”、“零”类词香港最多,“软”类词北京最多。这种现象反映出的多方面深层意义,特另陈述。
5 榜上有名: 新闻热点人物及社会文化意义
一个地区的社会文化发展倾向及其演变,可从当地的新闻媒体上得到体现。因为新闻媒体的报道紧贴社会动态,反映了一定时期社会文化的关注倾向,并可为促进和推动社会文化演变的先哨。因此,要考察一个地区的社会文化,当地主要媒体或畅销传媒便是一个很好的客观考察对象。
作为反映一个地区的文化倾向的指标可以有多方面的,例如媒体对新闻内容的取材和报道、新旧词语的流行和消亡、读者对体育娱乐新闻的关心程度及兴趣点等等。其中有关新闻人物的见报率是一个十分重要的指标,因为绝大多数新闻都与人物、地点有关,新闻人物及地名的见报及其出现频率,可以反映出编者及受众关注哪一方面的新闻,对哪一方面的社会动态感兴趣,从而也反映出社会文化的定位和取向。因此,我们可从当地传媒报道所关注的新闻人物及地名见报频率中,寻找到一些有关的线索。LIVAC自2000年创建至今的“京港台沪双周名人榜”和“京港台沪全年名人榜”,就是为了达到这样一个目标。
5.1 名人榜
港台京沪名人榜自2000年创立,至今已有10年历史。正所谓“10年人事几番新”,我们特别把过去10年的名人榜作综合累计和回顾,看看各地有多少名人榜常客,甚至可以称为“常青树”,由此可以反映各地的社会文化的异同。10年来,四地上榜名人总数达8 468人,其中上海占3 174人,为四地之冠,香港最少,只有1 996人,四地都共同出现过的共有128人(见表4)。以各地区看,在过去10年都上榜的“常青树”,香港多达14人,除小布殊、陈水扁、曾荫权、胡锦涛四位举足轻重的政治人物之外,娱乐圈人士竟占了8人。反观台北及北京都各有七位常青树,除周杰伦及姚明外,其余全属政要。上海最特别,10年“常青树”只有姚明一人。以上数据显示,香港媒体的新闻视野较具稳定性,新闻人物变动不大,但覆盖范围广阔,有政治和娱乐人物;上海则流动性大,除姚明外,没有其他人能屹立10年。

表4 四地十年来上榜人数
5.2 杨利伟现象与族群认同
通过追踪名人榜,监察各媒体对新闻人物的报道,可以看到各地媒体对重大新闻、社会活动或新闻人物的重视程度或评价。以中国第一位太空人杨利伟为例,杨利伟成为首位登上太空的炎黄子孙,为中国完成首次载人航天计划,圆了中华民族千年的飞天梦,令中国成为第三个拥有载人航天科技的国家,杨利伟立即成为全球各新闻媒体争相报道的对象。中国大陆和香港社会都对此十分关注,传媒广泛报道,但在2003年LIVAC四地全年名人榜的统计,却发现一个有趣的现象。杨利伟的排名在上海榜上位居第11,北京榜居第13,香港榜居第25,唯独在台湾榜上,杨利伟名落孙山(见下文)。这与台北甚少报道这件事有关。个中原因值得细味研究,例如当时台湾社会对台湾的身份认同问题。相对于2000年陈水扁当选台湾的总统前后,北京传媒也不公开点名报道,致使他未能打入当年的全年综合榜。两件事相互比较,实在耐人寻味。
京港台沪四地2003年名人榜上榜名人分别为(按榜上先后次序排列):
香港: 小布殊、碧咸、萨达姆、董建华、刘德华、谢霆锋、张国荣、张柏芝、梅艳芳、胡锦涛、王见秋、温家宝、梁锦松、王菲、叶刘淑仪、郑秀文、唐英年、陈水扁、陈冠希、江泽民、梁朝伟、杨永强、李克勤、贝理雅、杨利伟;
台北: 小布希、陈水扁、哈珊、胡锦涛、刘泰英、李登辉、游锡堃、温家宝、江泽民、马英九、张国荣、布莱尔、谢深山、宋楚瑜、连战、吕秀莲、刘德华、朱安雄、阿诺、李远哲、郝龙斌、吴国栋、林全、游盈隆、证严;
北京: 胡锦涛、温家宝、布什、江泽民、吴邦国、萨达姆、李肇星、吴仪、阿巴斯、曾庆红、贾庆林、李长春、杨利伟、希拉克、姚明、李元龙、唐家璇、毛泽东、鲍威尔、阿拉法特、布莱尔、李瑞环、郁建兴、黄菊、陈卫国;
上海: 姚明、萨达姆、布什、陈良宇、韩正、胡锦涛、哈恩、贝克汉姆、奥尼尔、科比、杨利伟、巴金、小威廉姆斯、阿拉法特、小泉纯一郎、吴金贵、吴承瑛、乌代、成耀东、雷锋、陈贞虎、马良行、江泽民、阿加西、阿巴斯国。
5.3 冠名称呼与身份认同
新闻媒介对当地新闻的关注度,体现一个国家或地区对自己身份的认同程度,这可以从媒体对国家或地区领导人的称呼看出认同程度。在香港九七回归前后,LIVAC曾统计香港报章对中国国家主席及中国总理的称谓,从而分析香港媒体对自己身份的认同。当时观察到,在“主席”、“总理”之前冠以“中国”的比例很高,显示香港媒体多数不太认同自己是“中国”的身份。
现在,我们统计从1995年至今香港报章对中国国家主席及中国总理的称谓,结果发现(见图2),在“主席”、“总理”之前冠以“中国”的,逐年减少,直接称呼“主席”“总理”的逐年增加。可见,当时分析的结论认为,香港媒体多数已经开始认同自己是“中国”的身份,可以由此得到证实。
也值得注意的是,1995年至今香港报章对英国首相则一贯不变的冠名为“英国”。这似乎反映出香港人对英国向来持有一种身份上不认同的态度。

图2 称呼冠以“中国”的历年比例变化
5.4 新闻人物褒贬指数
见报率的高低,只能客观反映出社会对某些事件或人物的关心程度,并不能表示社会所关注的重要内容,例如对人物或事件的正负面评价。要得知媒体对新闻人物是褒或是贬,就必须做仔细审读和深入分析,才能得出正确的结果。
我们尝试以2004年港台京三地都曾出现的高见报率的七位名人为例,详细分析了与之有关的各新闻报道,按其不同程度的褒贬评价,自动给出正负评分,再综合计算出各人全年的褒贬指数,由最正面的10分到最负面的-10分(见表5)。
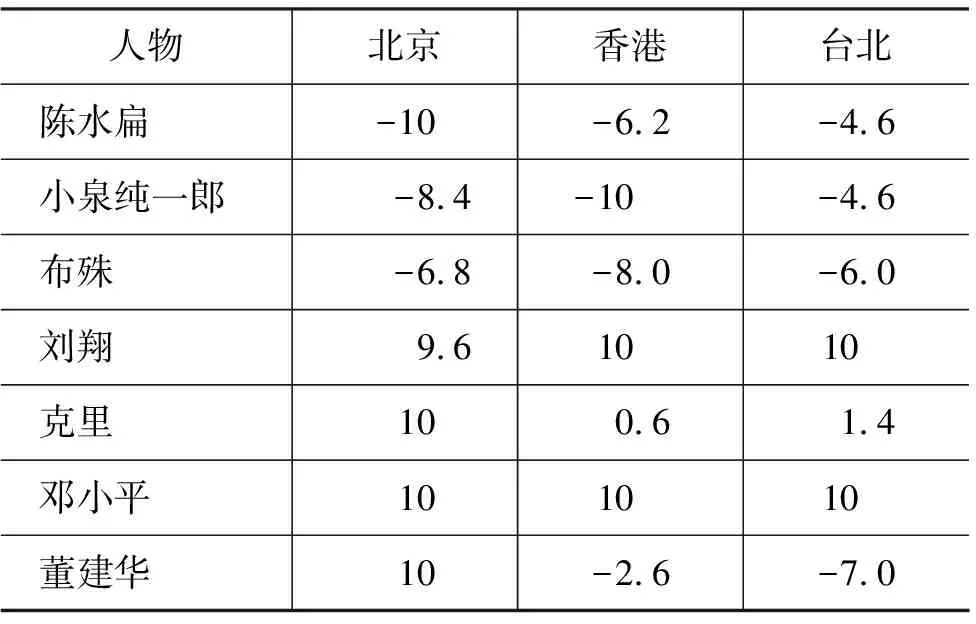
表5 名人褒贬指数(2004年)
从表中可见,在港台京三地中,北京媒体对新闻人物的评价最泾渭分明,除了对布殊贬中有褒外,其余各人的正负评价十分明显。相对地,香港媒体则较为平和,对董建华、陈水扁和布殊都有正负两面的报道,但贬抑还是多于褒扬,只是贬抑程度各有不同,布殊、陈水扁的负面指数就远高于董建华。
其次,以港台京为代表的华人地区媒体,对同一位新闻人物的正负面报道和评价,还是比较趋于一致,只是程度上有差别。例如对邓小平、刘翔和克里的报道大都是正面,尤其是邓小平和刘翔在三地几乎都是正面的报道;另一方面,陈水扁、小泉和布殊则都以负面新闻为多,北京对陈水扁的报道全都是负面,香港的报道也以负面为主,即使在台湾,他的负面新闻也多于正面。小泉纯一郎因为多次参拜靖国神社,北京和香港关于他的负面指数处于极高位置,台湾也多持负面评价。
较为有趣的是对董建华的评价,在海峡两岸各走极端,北京以褒扬为主,台湾则多予否定,香港褒贬不一。这些现象是否与三地的民生、社会形式与取态有关,也值得深入探讨。
6 结语
在自然语言处理领域,大规模语料库作为基础性的工具不可或缺,其重要性亦得到普遍认同,建立、开发、维护大规模语料库也是汉语信息处理取得新突破极为必要的工作环节。在中国中文信息学会成立的30年期间,我们见证了汉语自然语言处理技术得到的快速发展,而汉语语料库发展已经成熟到可以担当更有社会意义的新任务。超大规模的LIVAC语料库,兼具共时和历时的特点,不断地进行动态更新,为紧密追踪、科学观察泛华语区的语言现象和社会变迁,提供了坚实的基础和科学依据,可以帮助我们进一步客观的了解汉语及华语地区语言和多元化的社会发展。我们拭目以待中文信息处理的研究会层楼更上、有更多的新发展。
致谢本文的研究工作各阶段期间得到黎邦洋、周嘉宝、游汝杰、钱志安和多位研究人员的协助,并曾得到多方面的资助,特此致谢。
[1] 黄昌宁,李涓子.语料库语言学[M]. 北京: 商务印书馆. 2002.
[2] 俞士汶,朱学峰,王惠,等. 现代汉语语法信息词典详解(第二版)[M]. 北京: 清华大学出版社, 2002.
[3] Lu, B. and Tsou, B.K. Cultivating Large-Scale Parallel Corpora from Comparable Patents: From Bilingual to Trilingual and Beyond [C]//Proceedings of the Roundtable Conference on Linguistic Corpus and Corpus Linguistics in the Chinese Context, Hong Kong Institute of Education, 2011.
[4] 周强. 汉语句法树库标注体系[J]. 中文信息学报,2004, 18(4): 1-8.
[5] Sproat, R. and T. Emerson. Report of the First International Chinese Word Segmentation Bakeoff [C]//The ACL Second SIGHAN Workshop on Chinese Language Processing, Sapporo, Japan. 2003.
[6] 台北中央研究院平衡语料库[DB/OL]. http://www.sinica.edu.tw/ftms-bin/kiwi1/mkiwi.sh.
[7] Chen, K. J., C. R. Huang, L. P. Chang, H. L. Hsu. Sinica Corpus: Design Methodology for Balanced Corpora [C]//Proceedings of the 11th Pacific Asia Conference on Language, Information, and Computation (PACLIC’11), Seoul Korea. 1996: 167-176.
[8] Parker, R., Graff, D., Chen, K., Kong, J., and Maeda, K. Chinese Gigaword Fourth Edition[DB/CD]. Linguistic Data Consortium, Philadelphia. 2009.
[9] Huang, C.R. Tagged Chinese Gigaword Version 2.0[DB/CD]. Linguistic Data Consortium, Philadelphia. 2009.
[10] 香港教育学院语言资讯科学研究中心. LIVAC共时语料库[DB/OL]. http://www.livac.org.
[11] 邹嘉彦,黎邦洋. 汉语共时语料库与信息开发[M]//徐波,孙茂松,靳光谨.中文信息处理若干重要问题,北京: 科学出版社, 2003:147-165.
[12] 邹嘉彦,钱志安,邝蔼儿,等. 从共时语料库延伸到追踪语料库: LIVAC《汉语共时语料库》的新发展[C]//汉语语料库及语料库语言学圆桌会议论文集. 香港教育学院. 2011.
[13] 邹嘉彦,游汝杰. 全球华语新词语词典[M]. 北京: 商务印书馆. 2010.
[14] Kwong, O.Y. and Tsou, B.K. A Synchronous Corpus-Based Study of Verb-Noun Fluidity in Chinese [J]. Journal of Chinese Language and Computing, 2004,13(3): 227-278.
