17集总动力学模型和线性PLS模型在连续重整装置芳烃收率在线预测上的应用
2011-02-07山东省枣庄市中级人民法院山东省枣277100
杨 冬(山东省枣庄市中级人民法院,山东 省枣 277100)
侯卫锋,孙卫平(浙江中控软件技术有限公司,浙江 杭州 310053)
1 简介
催化重整工艺提供高辛烷值汽油组分和芳烃原料,同时副产氢气和液化气,是炼油工艺中重要的二次加工装置[1]。根据催化剂再生方式的不同,催化重整装置可以分为循环式重整、半再生重整和连续重整。
典型的连续重整装置由3~4个串联的绝热反应器构成,如图1所示。石脑油原料(由三百多个碳氢化合物构成,主要为C1~C12的烷烃、环烷烃、芳烃)与循环氢混合,经与反应产物换热,并经加热炉加热到一定温度后,进入第一反应器进行反应。由于重整反应以吸热的芳构化反应和环化反应为主,反应器内温降较为明显,所以在反应器之间辅以3~4个加热炉,使每个反应器入口温度达到工艺要求。
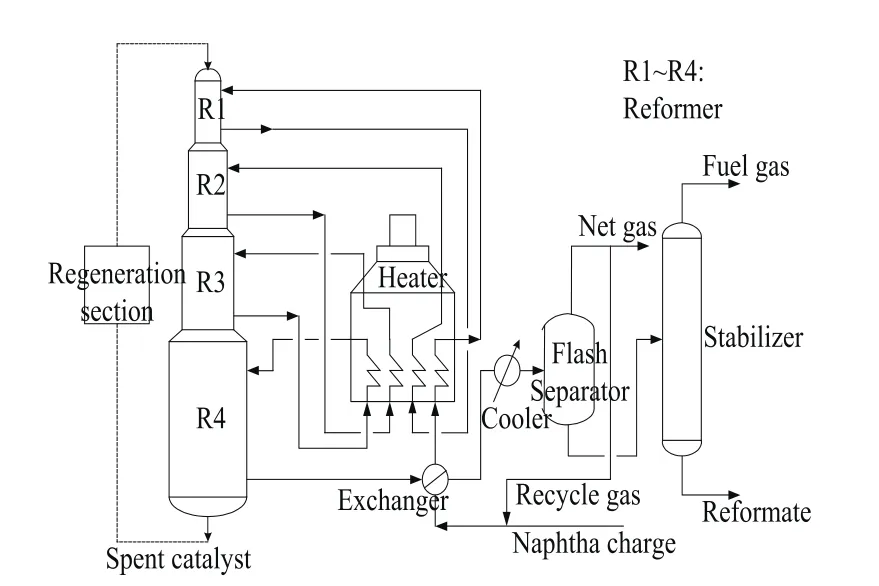
图1 连续重整装置简易流程图
由于催化重整反应体系含有三百多种组分,其中的反应更是不计其数,要详细模拟所有反应几乎是不可能的。对催化重整反应进行简化的常用方法是将动力学性质相似的组分用一个虚拟组分(或称为集总组分)代替,然后构造这些组分的反应网络。典型的集总反应模型包括Smith的4集总模型[2]、Ramage等的13集总模型[3]、翁惠新等的16集总模型[4、5]、丁福臣等的17集总模型[6、7]、Kmak等的22集总模型[8]、Jorge等的24集总模型[9、10]、Froment等[11]或谢新安等[12、13]的28集总模型、 Taskar等的35集总模型[14]以及Joshi等的79集总模型[15]等。 这些模型的准确性与很多因素相关,其中比较重要的因素之一是模型本身的复杂度。一般来讲,集总和反应数目越多,模型就越准确。
但是,复杂度高的动力学模型在实际应用中并不总是有效的。受限于国内化验室条件,对重整反应组分进行过于翔实的细分是不现实的。另外,模型复杂度越高,需要估计的动力学参数越多,模型求解也越困难。如果将集总动力学模型用于在线应用,考虑到实时性、方便性、稳定性和可靠性要求,对模型进行简化势在必行。所以,本论文使用胡永有等提出的只包含十七个集总组分和十七个反应的集总动力学模型,该模型已经被证明是准确的和高效的[16]。
芳烃收率是生产芳烃原料的连续重整装置(CCR)的重要技术指标,实时显示芳烃收率有助于实现装置的稳定生产和优化控制。与在线分析仪相比,使用在线预测技术(或称软测量技术)被证明是更加经济、及时和有效的。在本论文的第二节,首先对17集总模型进行了进一步简化,并对模型精度进行了离线验证。在第三节,提出了一个简单的包含16个过程变量的线性模型,线性模型的参数通过偏最小二乘法(PLS)进行回归,并同样对该模型的精度进行了验证。在第四节,17集总模型和线性PLS模型同时用于在线预测CCR装置的芳烃收率,并使用两个多月的样本数据对两个模型的预测效果进行了在线验证。论文中,提出了新的在线预测和校正策略,并讨论了两个模型在应用效果方面的区别。
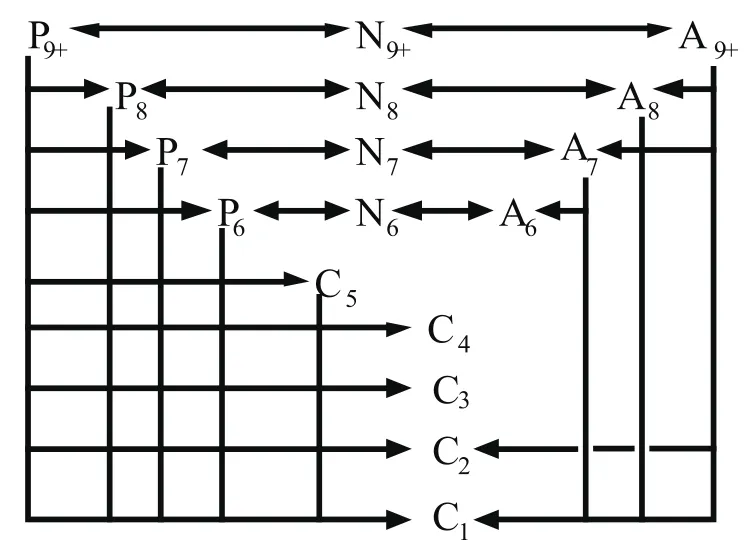
图2 催化重整反应网络图
2 17集总动力学模型及离线预测效果
胡永有等提出的17集总模型将重整原料划分为碳原子数从6到9+(9+代表9以及9以上)不等的烷烃(P)、环烷烃(N)和芳烃(A)以及裂化小分子(C1~C5)。集总反应网络如图2所示。所有的17个反应近似处理为拟一级均相反应,反应系数服从Arrhenius定律。
对于连续重整径向反应器,假设轴向截面催化剂分布、温度分布以及各组分浓度分布均匀,且无返混现象,如图2所示。据此,所得的反应器模型为:
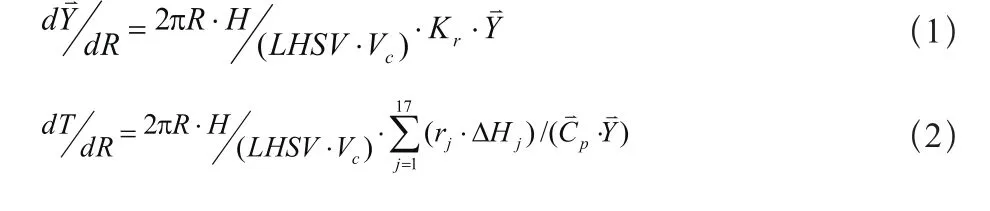
采用四阶龙格-库塔法和Gear法相结合的混合算法对式(1)进行积分求解,采用修正的欧拉算法对式(2)进行积分求解,即可计算反应器内的组成和温度变化曲线。
为缓解参数估计所带来的困难,活化能(E)和压力指数(b)采用同类催化剂的相关文献报道值[5],因此,只需估计17个频率因子( k0),由此带来的误差则累积到17个频率因子上。本文针对如图1所示的某工业级连续重整装置,选取不同操作条件下的工业数据和化验数据样本,经物料平衡校正后,对模型参数k0进行估计。
建立重整反应器模型后,还需要建立如图1所示的其他设备,如油气分离罐等的机理模型。由于循环氢从油气分离罐返回重整反应器,因此流程中存在循环流股,需要对整个流程的模型进行迭代求解,增加了模型求解时间。本文将循环氢这一循环流股切断,将循环氢流量和组成作为已知的输入参数,循环氢组成使用最新的化验数据。这样,除反应器以外的其他设备均不需要模拟,也不需要进行循环迭代求解,模型求解时间大大缩短,非常有利于在线应用。
本文使用大约33组工业数据样本对17集总动力学模型进行了验证。在这些样本中,装置负荷变化范围为91%~97%,进料芳潜含量变化范围为53%~62%。
在33组工业样本中,只有8组样本用于估计17个模型参数,其他25组样本用于模型预测和精度验证,验证结果如图3所示。从图中可以看出,17集总模型的预测结果与实际工业数据非常吻合。更详细的数据对比如表1所示。芳烃收率平均预测偏差只有0.37 wt%,所有25组样本的预测偏差范围为–1.06 wt%~+0.84 wt%。
简化后的17集总动力学模型稳定性好、求解速度快、预测精度高,非常适用于在线预测工业连续重整装置的芳烃收率。
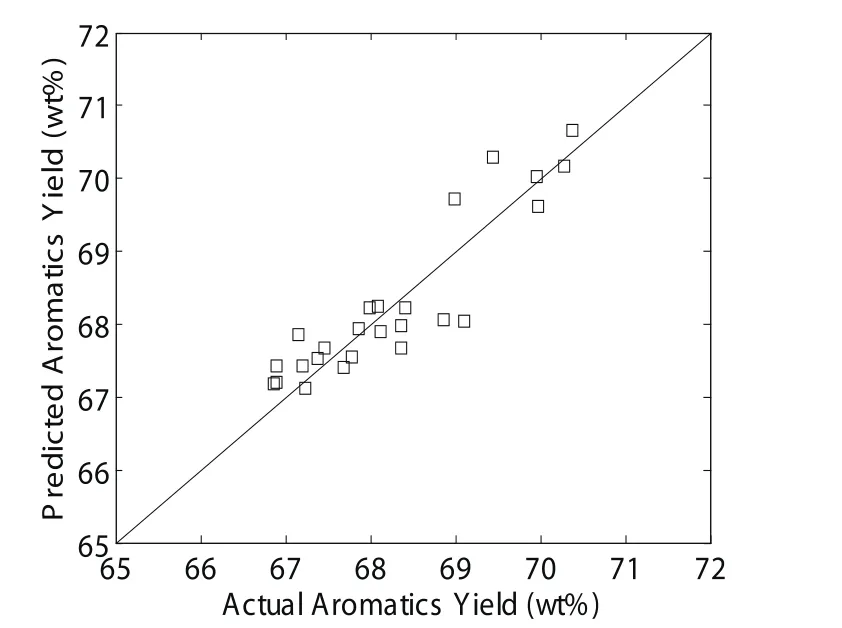
图3 17集总动力学模型的离线预测结果
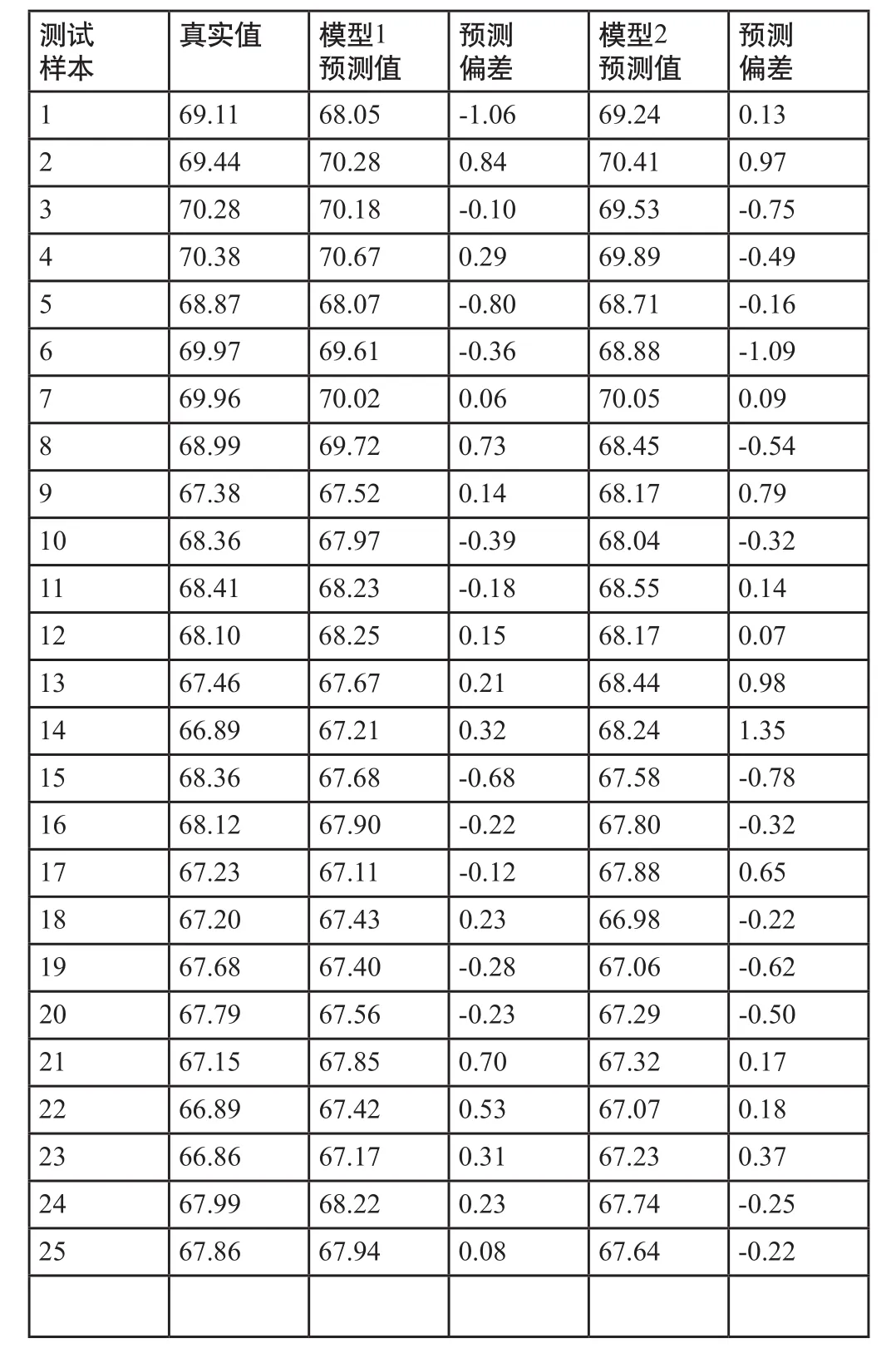
表1 17集总模型和线性PLS模型预测效果一览表
3 线性PLS模型及离线预测效果
利用17集总模型,可以研究很多过程变量,如装置负荷、进料组成、反应器入口温度、氢油比和反应温度等对芳烃收率的影响规律。结合这些灵敏度分析结果,本文提出了一个包含16个过程变量的线性模型,16个过程变量依次为进料液时空速、进料中六碳烷烃、七碳烷烃、八碳烷烃、九碳及以上烷烃、六碳环烷烃、七碳环烷烃、八碳环烷烃、九碳及以上环烷烃等组分的百分含量、进料芳烃含量、第一、二、三、四反应器入口温度、反应压力、氢油比等,该模型几乎涵盖了所有对芳烃收率有明显影响的过程变量。
由于所有工业样本数据都是在一个很小的范围内变化,线性模型的回归矩阵很有可能是病态的。另外,16个过程变量之间可能存在相关性。偏最小二乘法(PLS)被证明是可以解决上述问题的好的回归方法[17、18]。
PLS是化学计量学家为了解决预测建模的问题,根据启发式推理和直觉提出来的,它是对冗余的、高度相关的数据进行压缩、提取信息的有力工具。其基本思想是将输入输出数据集Xn×mx、Yn×my同时进行正交分解,从较高维的空间通过新的变量向量(称为潜变量向量)投影到较低维的新的空间上,令:

其中,n×k维矩阵T=[t1t2…tk]和U=[u1u2…uk]分别是矩阵X和Y在新空间上的潜变量。
主元数k是PLS的重要性质,可以通过交叉验证法确定,一般可取2~3。这样,通过较少数量和彼此互不相关的潜变量向量,就可以获得输入输出变量之间的关系。T和U的内部关系为,

当模型为线性模型时,

bi(i=1,2,…,k)即是我们所需求取的线性关联系数。
本文使用大约47组工业数据样本对线性PLS模型进行了验证。这些样本与第二节的33组样本是同一装置同时期的。
在47组工业样本中,22组样本用于估计线性模型参数,其他25组样本用于模型预测和精度验证,这25组样本与第二节的25组样本完全一样。在本文中,主元数k取为2。验证结果如图4所示。从图中可以看出,线性PLS模型的预测结果与实际工业数据同样非常吻合。更详细的数据对比如表1所示。芳烃收率平均预测偏差只有0.49wt%,所有25组样本的预测偏差范围为–1.09wt%~+1.35wt%。
从图3、4和表1可以看出,线性PLS模型与17集总模型的离线预测精度相当,同样适用于在线预测工业连续重整装置的芳烃收率。
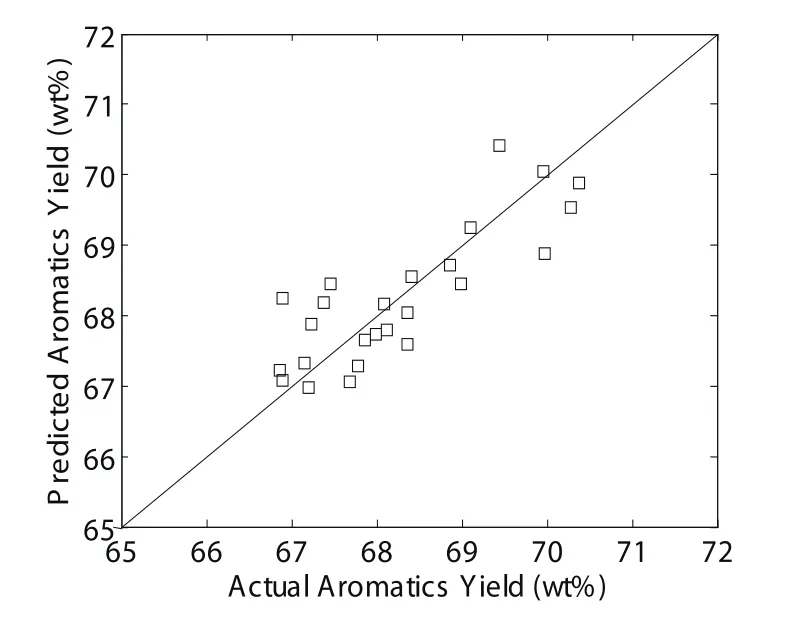
图4 线性PLS模型预测结果
4 芳烃收率在线预测
在将17集总动力学模型和线性PLS模型用于在线预测工业连续重整装置芳烃收率之前,需要考虑数据预处理、时序因素以及模型在线校正等问题。由于原料性质、装置负荷、操作条件和外部环境经常变化,模型参数在线校正问题变得越发重要。
具体到某工业级连续重整装置,作为两个模型的输入参数,进料体积流量、循环氢体积流量、四个反应器入口温度和反应压力可以从DCS系统实时获取,进料和循环氢组成每周化验分析3~4次,而重整油组成每天化验分析一次,因此,具体的在线预测和在线校正策略如下:
(1)由于进料和循环氢组成在2~3天内变化不大,实时计算时均采用最近一次的分析值,并假定保持不变,直至由新的分析值来取代;
(2)最近的连续12~16套数据用来初次回归模型参数;
(3)由于2~3天才能累积包含进出物料分析值的一套数据样本,在线模型参数校正同样每隔2~3天进行一次;新的样本增加进来,同时剔除最旧的样本,保持同样数量的样本不断校正模型参数。
本论文使用连续两个多月的多套数据样本用于验证上述两个模型的在线预测性能。采用上述模型在线预测和校正策略,两个模型的芳烃收率在线预测结果如图5所示。与图3和图4所不同的是,图5中的样本按时间顺序依次排列,虚线表示预测值,实线表示实际值。
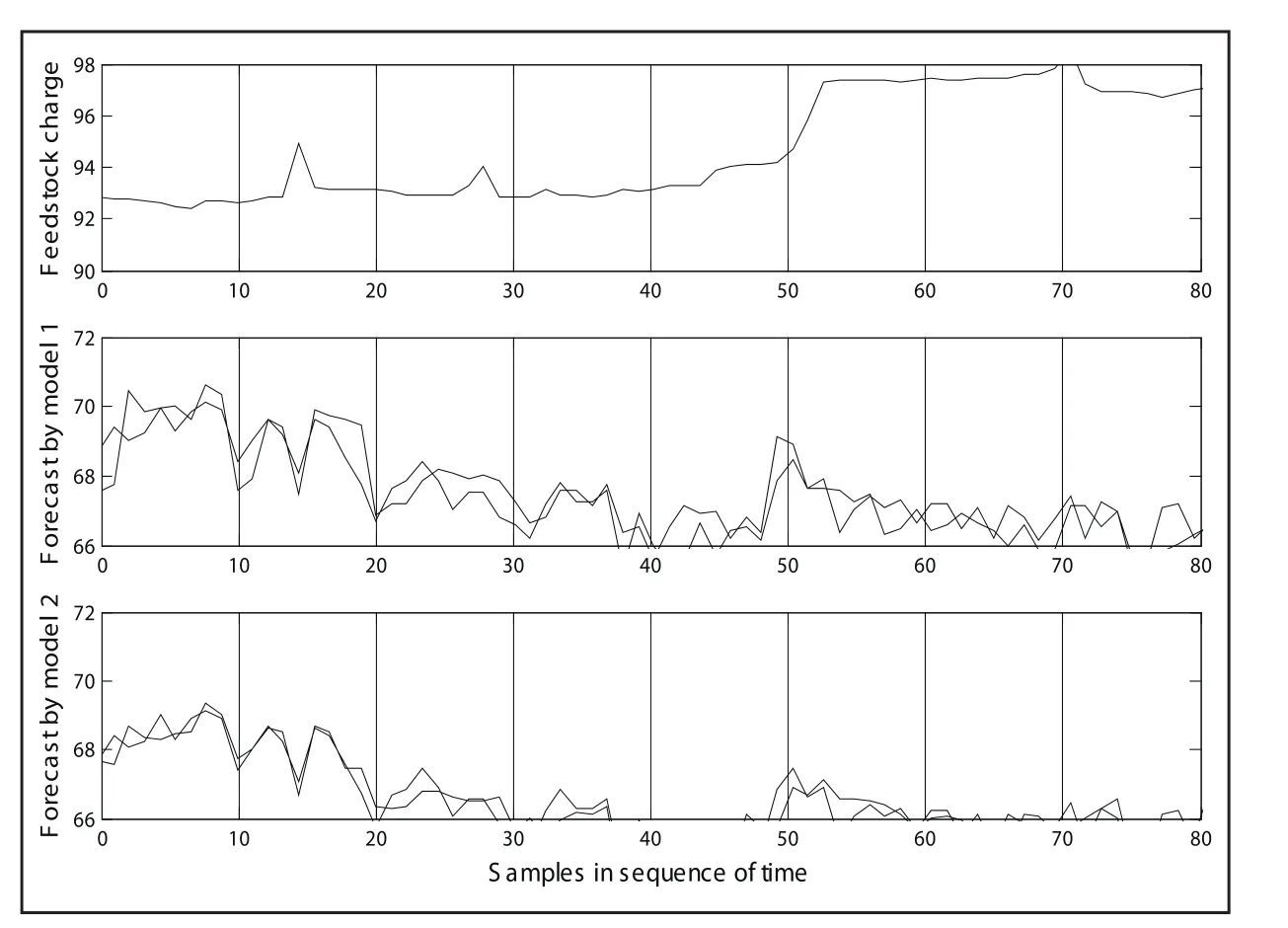
图5 17集总动力学模型和PLS模型在线预测结果
从图5中可以看出,两个模型的预测趋势跟实际趋势均非常吻合。当进料负荷变化较大时(如样本44~47时段),两个模型同样能够很好地跟踪实际芳烃收率的变化趋势。17集总反应动力学模型和线性PLS模型的芳烃收率在线预测偏差分别为0.52 wt% 和0.39 wt%,与两个模型的离线预测精度几乎相当(见图3和图4)。
两个模型的主要区别在于它们对训练样本(即在线校正模型参数时所需的样本)数目的敏感度有很大不同。如表2所示,当训练样本从20组减少到4组时,17集总模型的平均绝对偏差和残差平方和几乎没有发生明显变化,但线性PLS模型的平均绝对偏差和残差平方和随着训练样本数目的减少而有明显地增大。另外,从图5中还可以看出,当进料负荷发生明显变化时(如样本44~47时段),17集总动力学模型的预测精度要明显优于线性PLS模型。
17集总模型虽然具有上述优势,但由于线性PLS模型计算速度更快、参数回归算法也更稳定,因此,在工况变化不大时可以使用线性PLS模型在线计算该工业连续重整装置最重要的生产指标——芳烃收率,当进料性质、进料负荷或操作条件变化较大时,则切换成17集总模型进行在线预测。

表2 不同训练样本数目下17集总动力学模型和线性PLS模型的预测精度一览表
5 结论
简化后的17集总动力学模型和新提出的线性PLS模型同时用于预测某连续重整装置的芳烃收率,两个模型的离线预测精度相当,在线预测平均偏差只有0.52 wt% and 0.39 wt%。17集总模型被证明对于训练样本数目要求不高,并且当进料负荷等参数发生较大变化时比线性PLS模型更具优势。而线性PLS模型计算速度更快、参数回归算法也最稳定。两个模型可以同时用于在线预测,发挥各自的优势。

符号说明
[1]胡永有, 苏宏业, 褚健. 催化重整装置模拟研究综述[J]. 化工自动化及仪表, 2002, 29(2): 19~23.
[2]Smith, R. B., “Kinetic analysis of naphtha reforming with platinum catalyst”[M].Chem. Eng. Prog. 1959, 55 (6):76~80.
[3]Ramage, M. P., Graziani, K. R., Krambeck, F. J., “Development of Mobil’s kinetic reforming model” [M].Chem. Eng. Sci. 1980, 35:41~48.
[4]翁惠新, 孙绍庄, 江洪波. 催化重整集总动力学模型(Ⅰ)模型的建立[J]. 化工学报,1994, 45(4): 407~411.
[5]翁惠新, 江洪波, 陈志. 催化重整集总动力学模型(Ⅱ)实验设计和动力学参数估计[J]. 化工学报, 1994, 45(5): 531~537.
[6]丁福臣, 周志军, 杨桂忠等. 十七集总催化重整反应动力学模型研究(1)—模型的建立[J]. 石油化工高等学校学报, 2002, 15(1): 15~17.
[7]丁福臣, 周志军, 杨桂忠等. 十七集总催化重整反应动力学模型研究(2)—工业装置模拟[J]. 石油化工高等学校学报, 2002, 15(2): 22~25.
[8]Kmak, W. S., Stuckey, A. N., “Powerforming process studies with a kinetic simulation model”,AIChE National Meeting[C]. USA: New Orleans, 1973.
[9]Jorge, A. J., Eduardo, V. M., “Kinetic modeling of naphtha catalytic reforming reactions” [J].Energy&Fuels, 2000, 14:1032~1037.
[10]Jorge, A. J., Eduardo, V. M., etc., “modeling and simulation of four catalytic reactors in series for naphtha reforming”[J].Energy & Fuels, 2001, 15:887~893.
[11]Froment, G. F., “The kinetic of complex catalytic reactions” [M].Chem.Eng. Sci.1987, 2: 1073~1087.
[12]解新安, 彭世浩, 刘太极. 催化重整反应动力学模型的建立及其工业应用(1)—物理模型的建立[J]. 炼油设计, 1995, 25(6): 49~51.
[13]解新安, 彭世浩, 刘太极. 催化重整反应动力学模型的建立及其工业应用(2)—反应动力学模型的建立[J]. 炼油设计, 1996, 26(1): 44~47.
[14]Taskar, U., Riggs, J. B., “Modeling and optimization of a semiregenerative catalytic naphtha reformer”[J].AIChE J. 1997, 43: 740~753.
[15]Joshi, P. V., Klein, M. T., “Automated kinetic modeling of catalytic reforming at the reaction pathways level” [J].Rev. Pro. Chem. Eng. 1999, 2:169~193.
[16]胡永有, 苏宏业, 褚健. 工业重整装置建模和仿真[J]. 高校化学工程学报,2003, 17(4): 418~424.
[17]Yin, K. K., “Multivaria te statistical methods for fault detection and diagnosis in chemical process industries: A survey”[J]. Tren. Chem..Eng.,1998, 4:233~241.
[18]Kourti, T., “Process analysis and abnormal situation detection: From theory to practice”, IEEE Con. Sys. Mag. [J]. 2002,22 (5):12~25 .
