一种新的基于蚁群和凝聚的混合聚类算法
2010-11-26王小华王荣波
王小华,沈 杰,王荣波
(杭州电子科技大学计算机应用技术研究所,浙江杭州310018)
0 引 言
聚类分析是多元统计分析的一个重要分支,是一种无监督的分类,是把一个没有类别标记的样本集按某种相似性准则划分成若干个子集(类),使每一类中的样本点尽可能相似,而不同类中的样本点之间的差异尽可能大,其实质是寻找隐藏在数据中不同的数据模型。目前,常用的聚类算法有基于层次的凝聚算法、基于划分的算法、基于密度的算法以及基于各种生物模型的算法等[1]。由于聚类算法采取不同的模型,在聚类效果以及时间复杂度上各有不同,例如基于划分的K均值聚类算法,算法简单,效果尚佳,但是该算法对于初始参数敏感,不易于找到全局最优解,而蚁群算法易于找到全局优化解,而收敛速度相对较慢。本文提出一种基于蚁群算法[2]和凝聚算法的混合聚类算法,并对蚁群算法加以改进,在测试样本获得了满意的结果。
1 经典蚁群算法和凝聚算法
基于蚁群聚类现象建立了一种基本模型(BM)首先提出。后然,BM模型被推广到数据分析范畴[3-5],其主要思想是把待聚类的样本集数据随机初始散布在一个二维平面内,然后在该平面上放置人工蚂蚁对其进行聚类分析。随着该算法被一步步深入研究,各种改进后的算法竞相涌现,一种较为稳定的蚁群算法[2,6]被积淀下来。
定义:
(1)平均相似性
假设在时刻t某只蚂蚁在地点r发现一个数据对象o,则可将对象oi与其邻域对象oj的平均相似性定义为:
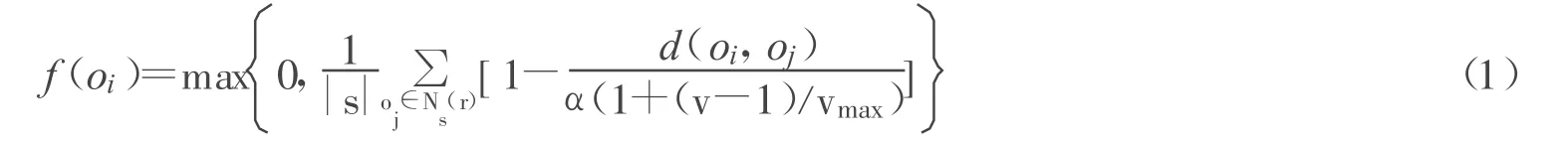
式中,α为相似性参数;v表示蚂蚁运动的速度;vmax为最大速度;Ns(r)表示地点r周围的以s为边长的正方形局部区域,d(oi,oj)表示对象oi和oj在属性空间中的距离。距离表示法较多,根据不同的数据类型可选用不同的距离表示方法。

式2是明可夫斯基距离。
(2)概率转换函数
概率转换函数是f(oi)的一个函数,将数据对象的平均相似性转化为拾起概率Pp或者放下概率Pd。

(3)算法描述
1)初始化蚁群算法参数,蚂蚁数量Ant-Size,最大迭代次数Max-Iterate,局部边长参数s等,将样本随即分布到二维平面。初始化蚂蚁,设置移动参数v。
2)For i=1,2,…,Max-Iterate:
For j=1,2,…,Ant-Size:
①根据式1计算对象平均相似性;
作为一种新型经济模式和商业模式,物流业发展共享经济中难免会遇到质疑和困难,有些问题会引起政府或者有关部门的干涉和禁止。在共享经济的快速发展与应用中,其更新速度远远超出了目前政府所监管的范畴和能力,政府还没有一个针对性地健全监管制度,一定程度上阻碍了物流业共享经济的发展。基于这种背景,为了更好地利用共享经济促进我国绿色物流的建设、实现对社会物流费用的有效降低,政府要充分发挥出其监管作用,建立起针对物流共享平台搭建以及合理运行的相关监管制度,形成一个允许试错、宽容、多元化、开放的经济环境,打破一味禁止和限制的监管弊端,完善经济环境,为物流共享经济的发展提供必要保障。
②如果蚂蚁无负载,根据式3计算拾起概率Pp。若Pp大于设定的阈值,拾起该物体;否则,蚂蚁拒绝拾起该物体而选择其它物体;
③如果蚂蚁有负载,根据式4计算放下概率Pd。若Pd大于设定的阈值,则放下该物体,并选择一个新的对象。
3)For i=1,2,…,n,其中n为所有样本点:
①如果某个样本点所在的领域小于某一阈值,则标记该样本点为孤立、异常点;
②否则给该对象分配一个类id,并且递归将其领域样本点标记为同一个id。
经典凝聚算法基本思想:以样本点的个数作为初始类个数,基于特定的相似度函数相继合并两个最相似的类,直到满足退出条件,聚类结束并获得聚类结果。
该算法思路简单,如果样本点大小为n,则算法的时间复杂度为O(n2log(n))。若样本点数量n规模大,则直接运用该算法消耗的时间比较大。
2 蚁群算法的改进
(1)在蚂蚁放置物体时采用紧凑算法。在二维平面图中若找到点直接放下物体容易产生松散的物体堆积,造成少量物体占据大量平面空间,从而在上述蚁群经典算法步骤3中递归产生类时模糊类边界。如图1所示。
图1中,b、d子图分别是a、c子图采用紧凑算法后蚂蚁放置物体后的二维平面图片段。标记为0的网格点,表明该点被物体占据,标记为1的网格点是经典蚁群算法中在放置物体时选择的点,标记为2的网格点是采用紧凑算法后蚂蚁放置物体的可能点之一。
(2)对可被蚂蚁拾起的物体进行基于评估函数的选择。改进的基本思想:根据蚂蚁负载时所经过的步数对物体放下后被重新选择的优先级进行设置:
1)若蚂蚁拾起物体后,没有移动即放下,或者在相对少的步数之内就放下物体,则表明该物体已经处于某一相对正确的类中,将该物体放入优先级低的队列;
2)若蚂蚁拾起物体后,走了相对较多的步骤才放下物体,则表明蚂蚁放下的物体刚刚加入某一类中,稳定性待测,则将该物体放入优先级高的队列;
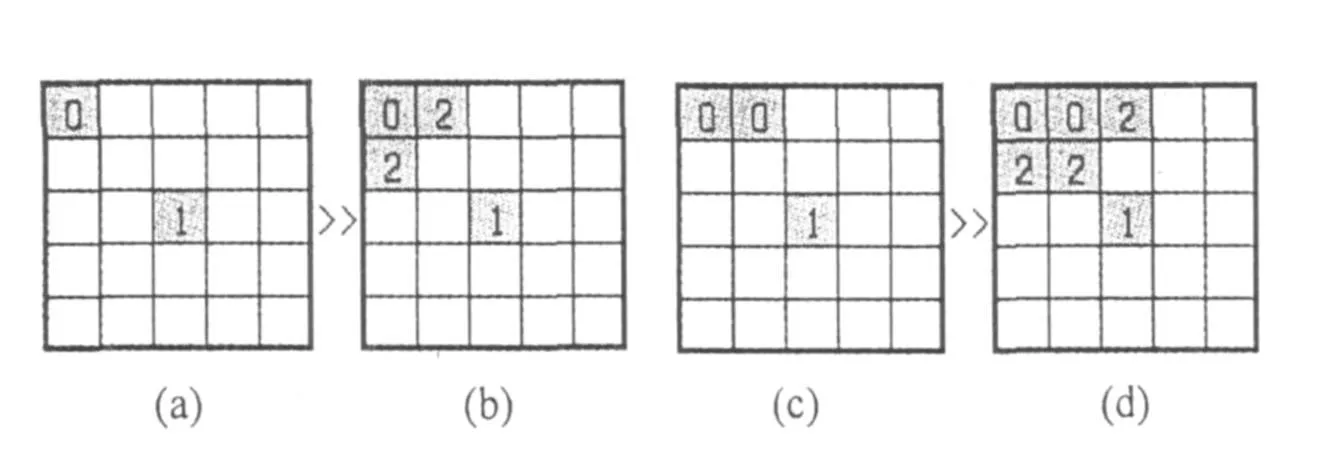
图1 采用紧凑算法后物体放置点
3)若蚂蚁拾起物体后走的步骤大于某一相对较大阈值,则可认为该物体为噪声点,将该物体放入不可再被蚂蚁负载队列;
4)当蚂蚁负载为空时,基于评估函数从未被负载的物体队列中获得物体,从而使不稳定的点以更大的概率融入合适的类中。
3 混合的蚁群算法和凝聚算法
由经典的凝聚算法可知,若直接使用凝聚对原始样本点进行聚类,由于样本点的数量直接制约了聚类的时间,若在蚁群算法迭代过程中,基于蚁群算法形成的粗聚类进行凝聚算法,则可以加速蚁群聚类算法,使得分散类获得直接合并的机会。如图2所示。

图2 凝聚算法效果图
图2(a)表示在蚁群算法作用下,一些小的类形成,但没有合并应该合并的类。图2(b)表示在对左图所代表的粗聚类结果进行凝聚后的聚类结果。
4 实验结果及分析
实验数据是来自UCI的iris花卉数据集[7],该数据集是由3种类别组成的150个样本采集点,每个样本点包含有4个属性。实验计算F-measure[2]值和运行时间,共进行10次,取其中最好的成绩作为结果。参与实验的算法除了本文提出的混合聚类算法,还有经典蚁群算法、遗传算法、禁忌搜索算法、模拟退火算法[6]。如表1所示。
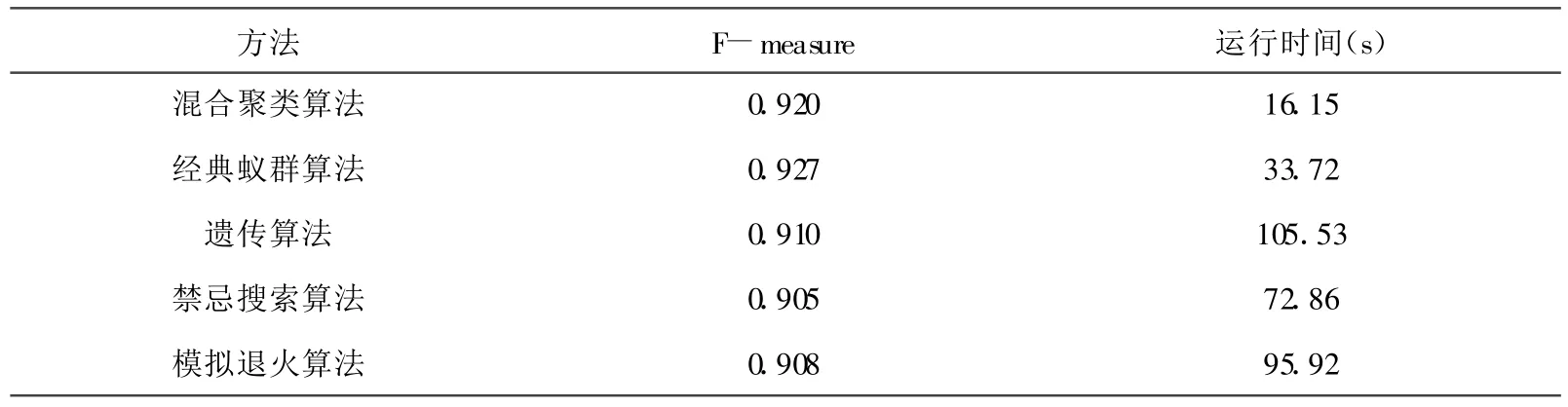
表1 聚类算法实验结果表
由表1的测试结果可知,本文改进的方法在F-measure值这项基本上与最好的经典蚁群算法持平,但在运行时间上有了很大的提高,获得了较好的结果。
5 结 论
本文提出一种基于蚁群算法和凝聚算法的混合聚类算法,该算法采用改进蚁群算法,并融入凝聚算法到蚁群算法模型。与经典蚁群算法相比,本文提出的方法在继承蚁群聚类算法的固有优点的同时,速度更快,效果更佳,另外对于样本中异常点加以检测,是一种较为新颖的混合聚类算法。
[1] 范明,范宏建.数据挖掘导论[M].北京:人民文学出版社,2006:320~321.
[2] 段海滨.蚁群算法原理及其应用[M].北京:科学出版社,2007:290~297.
[3] Deneubourg JL,Goss S,Franks N.The dynamics of collective sorting:robot-likeants and ant-like robots[J].Proceedings of the 1st International Conference on Simulation of Adaptive Behavior From Animal to Animal,1991,25(18):356~363.
[4] Dorigo M,Bonabeaub E,Theraulaz G.Antalgorithms and stigmergy[J].Future Generation Computer Systems,2000,16(8):851~871.
[5] Erik D,Lumer Baldo Faieta.Diversity and adaptation in populations of clustering ants[J].Proceedings of the third international conference on Simulation of adaptive behavior from animals to animals,1994,19(6):501~508.
[6] Shelokar P S,Jayaraman V K,Kulkarni BD.An ant colony approach for clustering[J].Analytic Chimica Acta,2004,33(23):187~195.
[7] Fisher R A.Iris Data Set[EB/OL].http://www.ics.uci.edu/mlearn/MLRepository.htm l.2009-04-08.
