基于模糊数据模型的智能查询优化算法
2010-07-25左利云
左利云
0 引言
随着数据库技术应用领域的不断扩大,信息检索要求的不断提高,模糊信息越来越多,精确查询范畴已不能满足各种应用领域对数据库查询的要求。更重要的是,随着电子计算机、控制论、系统科学的迅速发展,要使计算机能像人脑那样对复杂事物具有识别能力,就必须研究和处理模糊性。因此对模糊查询技术的研究显得越来越重要。
现有关于模糊查询的研究也不少,但大多是侧重其应用和模糊数据库的构建,而对其查询效率提高优化的研究却比较少,较新的研究有郭喜平[1]等交互式给出各种模糊查询优化建议,但并未提出具体能提高查询效率的算法;金宗安[2]等通过设置隶属函数的参数、直方图的值调整模糊范围的大小,通过设置不同的可信度查询不同可靠性的数据,由于隶属函数的定义包括很多主观性的因素,因此通用性不是很好,更重要的是他并未对模糊查询的效率进行研究。而本文是在模糊查询的基础上结合相似查询,提出的一种可以明显提高查询效率的智能查询优化算法。
1 基于模糊数学模型的模糊查询
人的自然语言具有模糊性,为了实现用自然语言跟计算机进行直接对话,必须把人的语言及思维过程提炼成数学模型,才能给计算机输入指令,因此模糊数学模型应运而生。而模糊查询实现的理论基础就是模糊数学模型。
1.1 模糊数学模型的建立
首先给出模糊集合及其α截集的定义。
定义1 设在论域U上给定了一个映射:A:U→[0,1] ,u∣→A(u)
则称A为U上的模糊集,A(u)称为A的隶属函数(或称u对A的隶属度)。
定义2α截集:设A论域U上的模糊集合,隶属函数为A(u):U→[0,1] ,在A中隶属度大于或等于α值的元素集合,其中 0≤α<1(0<α≤1),分别称为A的强(弱)α-截集,表示为:Aα+={u∣u∈U,A(u) > α},Aα={u∣u∈U,A(u)≥α}。
一个模糊集的α-截集对应一个区间,其中α称为阈值,可以利用α-截集将一个模糊集合转化为普通集合。
1.2 模糊查询的实现
模糊查询的实现原理,是根据模糊模型将模糊的输入条件精确化,转换为标准的 SQL语句,去数据库中检索出相应结果集。基于前面已经建立好的数据模型和模糊模型,进行模糊查询的设计。要实现此类模糊查询,有两种方式:
(1) 建立模糊数据库模型
将模糊理论直接引入传统数据库,对数据表示和数据库进行模糊处理,并建立相应的查询语言。如有些字段的值是模糊化的,在进行数据库录入时,首先进行数据模糊化处理.将精确数据转化为模糊数据,而在数据查询时,直接进行模糊值的匹配。这种方法虽然查询简单,但在数据录入时需要进行额外计算工作,且模糊字段值的确定并不容易。
(2) 基于传统精确数据库
将 SOL语言本身进行模糊化扩展,将查询条件通过模糊计算,转化为一个模糊范围,再进行精确的 SQL查询。这种方法无需增加数据录入人员的负担,原有数据库无须修改,查询过程与一般查询相一致。操作简单,结果清晰明了,并且查询的模糊阈值易于动态修正变更。
由于目前的数据库还是以传统的精确关系数据库为绝大多数,而且无论从可操作性还是兼容性来看,方式(2)无疑是最合适的选择,因此模糊查询的实现,通过模糊理论模型,将模糊查询条件精确化来实现。即当用户输入自然语言的查询条件时,只要将其中关键模糊词的隶属函数找到,用它去匹配数据库中所有记录相应的字段,计算出隶属度,隶属度大于或等于给定的阈值的记录,就是用户要查询的数据。
2 基于模糊数据模型的智能查询优化算法
根据模糊查询的特点可知,模糊查询要比精确查询的花费更多,因此如何能发展出更快更高效的模糊查询算法显得十分重要。在此结合模糊查询及相似查询的优点,提出一种智能查询优化算法(Intelligent Inquire Optimization简称IIOP算法)。
2.1 特征极值点的提取
对于给定的一组数据序列A、一个模糊查询查询序列Q及一个距离阈值ε,智能查询要做的是如何有效的找出所有与查询序列Q的距离小于ε的序列。研究发现,如果直接对查询的数据序列进行相似查询,不但存储和计算效率低下,而且还会影响算法的准确性和可靠性,因此在进行相似查询之前,先对数据序列进行特征极值点提取,这样会大大提高查询速度。
IIOP算法采用的征极值点提取方法,是结合特征点提取法FPS算法[3]和极值点提取法IPS算法[4]来实现。其实现思路简单概括如下:特征极值点的选取,用极值法选择原始序列中对序列形态影响最大的点作为特征点,通过依次连接这些特征点实现序列的线段化。数据突变序列中用IPS算法的距离阈值ε作为选取转折点的依据,当数据序列中某个数据点ai与前后数据ai-1、ai+1平均值的距离大于,即时,ai为转折极值点。具体实现过程如图1所示。
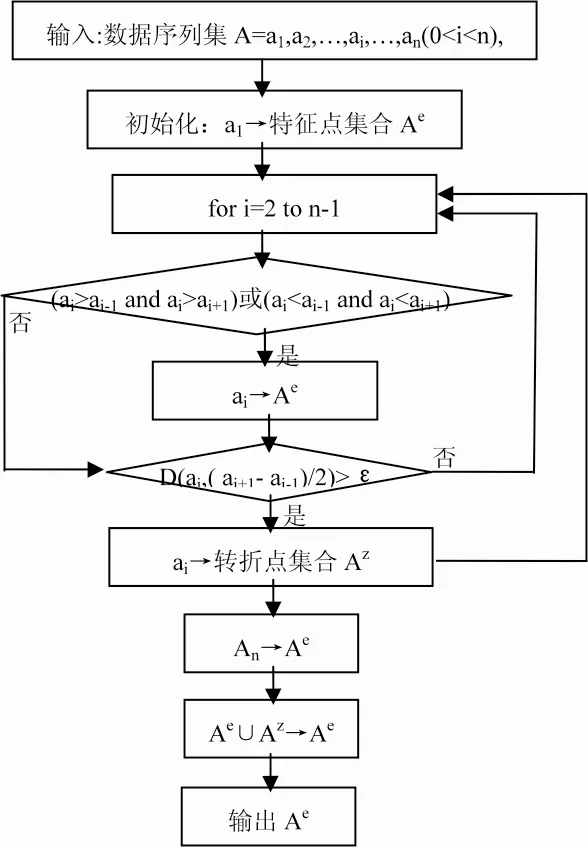
图1 特征极值点提取过程框图
该方法仅需一次扫描序列数据集,就可以保留反映数据序列变化模式的主要特征极值点,获得特征极值点集合Ae,极大减少了数据存储量。
2.2 特征极值点序列的相似查询
在数据序列的相似查询中,重要的是对于相似距离的度量。比较有名的有,通过欧几里德距离(Euclidean Distance) 的ED方法和动态时间弯曲距离(Dynamic Time Warping) 的DTW算法[5],比较序列间的相似。由于原始数据序列的DTW距离计算比较费时,而一般情况下序列都很长,因此计算距离需要比较长的时间。如果能从序列中抽取少量的、主要的特征则可以显著提高序列的查找速度。
故IIOP算法在2.1的基础之上,利用特征极值点序列代替原始的数据序列,采用基于DTW距离的相似性度量方法,比较序列之间的相似程度。
首先给出DTW距离的相似性度量公式。对于之前2.1中提取的特征极值点集合中的两个序列Ae=<a1e,a2e,…,aie,…,ame,>(0<i<m),Be=<b1e,b2e,…,bje,…bne,>(0<j<n),二者特征极值点DTW相似距离D的计算公式如下:
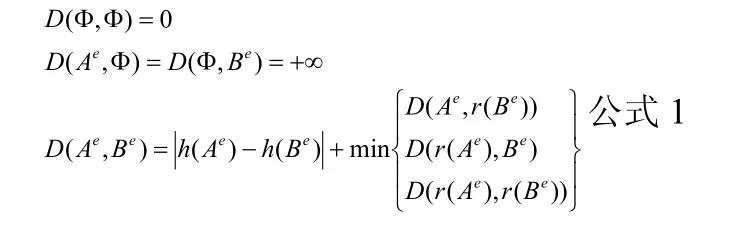
其中m、n为特征极值点个数。对数据序列执行 2.1中特征提取获得特征极值点后,得到的特征极值点序列中特征极值点个数可能不尽相同。由于特征极值点是反映数据序列变化趋势的重要标志,因此当两个数据序列的特征极值点个数差异超过阈值ε(ε≥1)后,IIOP算法认为两个数据序列不相似。只有当特征极值点个数差异小于ε时,才进行下一步DTW相似距离D的计算。具体步骤见图2。
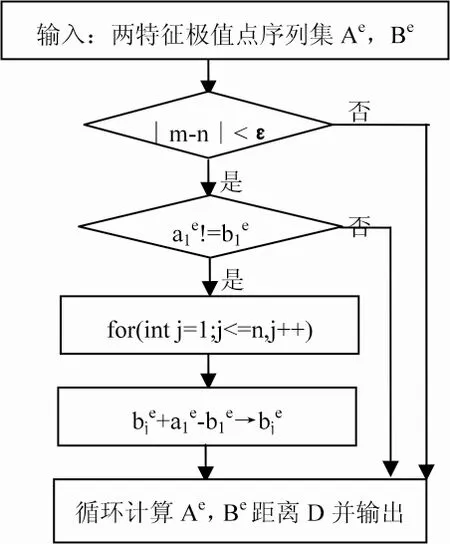
图2 相似查询过程示意图
近几年有关相似查询的算法,有基于分段多项式表示的PPR算法[6] 和利用主成分分析对MTS数据降维,聚类分析构造B+-树的Dbis算法[7] 等。本文提出的IIOP算法在相似查询的整个DTW度量过程中仅保留数据序列中的特征极值点,极大减少了数据存储量,提高了查询计算速度。
3 智能查询优化算法的仿真实验及结果分析
为了检验所提出智能查询优化算法——IIOP算法的性能,设计了仿真实验系统,实验运行环境为4个AMD皓龙2.4GHZ CPU(双核),16GB内存和840GB硬盘,软件环境是Microsoft Windows XP操作系统和ORACLE 10G数据库管理系统,算法使用的开发工具为Visual C++。因 IIOP算法查询效率主要表现在其相似查询方面,故将其分别与同类相似查询算法ED算法及经典DTW算法进行比较,观察它们在查询时间和查询准确率方面的表现。
实验数据源自2009年12月18日沪深股市的200家上市公司的交易数据集,数据序列数据点为1 258 953个,由于对原始数据序列进行特征极值点序列分段后获得的特征极值点序列中数据个数各不相同,因此在IIOP算法中进行相似性查询时,从200个样本序列中随机抽取10个样本序列作为查询目标序列,样本序列数据点个数平均为100 000。实验中DTW算法和IIOP算法阈值分别选取2和2.5,因其表现类似故只做出阈值取2的情况,3个算法在查询时间和准确率方面的表现如图3、4所示。
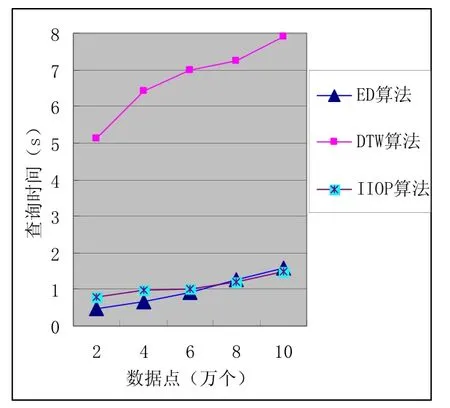
图3 三算法查询时间比较
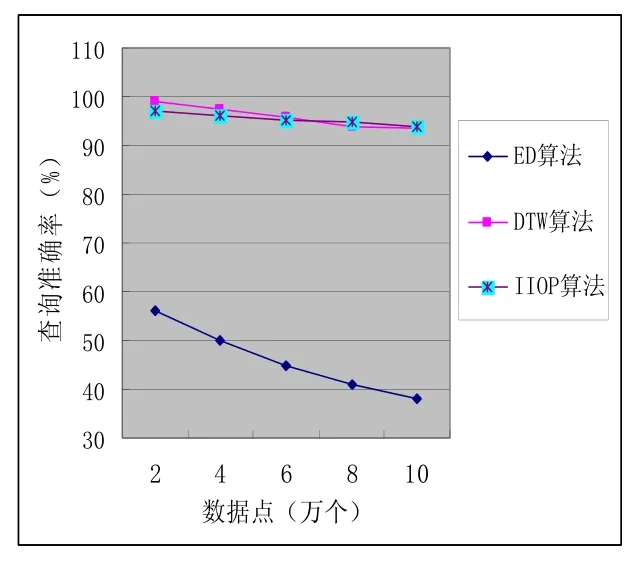
图4 三算法查询准确率比较
通过实验数据图比较不难发现,尽管ED算法的相似性聚类算法速度较快,但计算所得距离基本相似,分类效果较差,故准确率表现很差。IIOP算法的查询时间略高于ED算法,但查询质量远远优于ED算法,与经典DTW算法基本一致,而且IIOP算法的查询时间与样本数据的特征极值点个数紧密相关,特征极值点个数越少,运行速度越快。。
4 结束语
为了使数据库能处理现实世界中广泛存在的不精确的、模糊的数据,进一步扩展数据库的查询功能,提出基于模糊数学模型的模糊查询,但是有关模糊查询的查询效率的研究一直比较少,本文提出一种将模糊查询和相似查询完美结合起来的智能查询优化算法。该算法中模糊匹配查询符合人脑思维特性,因而更合理、更有效,同时为了提高查询效率提出首先对原始数据序列进行特征极值点的提取,极大减少了数据存储量,提高了查询计算速度。经实验验证该算法查询质量要优于同类ED、DTW算法。
[1] 金宗安,杨路明,谢东.关系数据库模糊查询的研究[J] .计算机工程,2009.7:63-65.
[2] 郭喜平,蒙应杰.模糊查询中的策略优化[J] .计算机工程与应用,2008.44(34):152-154.
[3] 肖辉,胡运发.基于分段时间弯曲距离的时间序列挖掘[J] .计算机研究与发展.2005.42(l):72-78.
[4] Th. Pavlidis,SL Horwitz.SegmentationofPlane Curves[J] .IEEE Transactions on Computer.1974.23(8):860-870.
[5] Vlachos M,Hadjieleftheriou M,Gunopulos D, Keogh E.Indexing multi-dimensional time-series with support for multi-ple distance measures.In:Proceedings of the 9th ACM Inter-national Conference on Knowledge Discovery and Data Mining,Washington DC, USA,2003,216-225.
[6] 周大镯,吴晓丽,闫红灿.一种高效的多变量时间序列相似查询算法[J] .计算机应用,2008.10:2541-2543.
