基于局部全局上下文引导的方面级情感分析
2024-02-21丁美荣赖锦钱曾碧卿徐马一陈炳志
丁美荣,赖锦钱,曾碧卿,徐马一,陈炳志
(1.华南师范大学 软件学院,广东 佛山 528225;2.武汉大学 计算机学院,湖北 武汉 430072)
0 引言
通常来说,情感分析任务分为3 类:基于文档的情感分析、基于句子的情感分析和基于方面的情感分析[1]。方面级情感分类(Aspect-level Sentiment Classification,ASC)是方面级情感分析(Aspect-Based Sentiment Analysis,ABSA)的子任务之一[2]。如图1 所示,在句子“Good dishes but terrible service attitude”中,对“dishes”和“service attitude”两个方面的情感极性分别为正和负。自深度神经网络问世以后,以卷积神经网络(Convolutional Neural Networks,CNN)[3]、门控递归单元(Gate Recurrent Unit,GRU)[4]、长短时记忆网络(Long-Short Term Memory,LSTM)[5]、图卷积网络(Graph Convolutional Network,GCN)[6]等为代表的深度神经网络模型广泛应用于自然语言处理领域[7]。在方面级情感分类任务中,随着注意力机制[8]的出现,深度神经网络与注意力机制相结合的模型长期占据主流地位,并取得了可喜的成果[9-11]。方面词上下文蕴含了丰富的句法信息,然而,受限于深度神经网络的黑盒特性,其内在机理规律往往难以解释,使得部分注意力机制未能充分捕捉文本中丰富的句法信息。
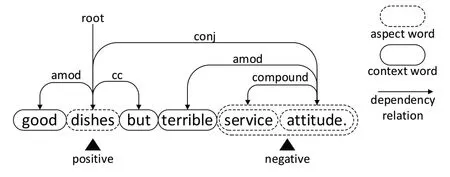
Fig.1 Example of sentimental dependencies图1 情感依赖解析示例
近年来,利用句法信息提取文本特征的模型备受关注,通过依赖分析不仅可以利用词与词之间的关系,而且能以更好的语义指导分析上下文与方面词之间的情感联系。依赖句法最早由Michel[12]提出,其构造依赖句法分析树(Dependency Syntax Parsing Tree,DSPT)显示句子的句法信息。例如,图1 展示了关于“Good dishes but terrible service attitude”餐厅评论的DSPT。其中“terrible”与“attitude”的依赖关系是“attitude”支配“terrible”,“terrible”服从于“attitude”。对于方面词“dishes”,其具有3 种依赖关系,即“dishes”支配“Good”,“dishes”支配“but”,“dishes”服从于“attitude”。在方面级情感分析领域使用图神经网络进行句法信息提取的研究十分新颖,但如何降低文本的依赖解析错误与改进文本语义信息特征的提取仍需要作进一步研究。
鉴于方面词上下文对方面词情感极性的影响较大,因此如何能挖掘到方面词上下文中的信息特征对于方面词情感极性预测具有非常重要的意义。为了克服方面词上下文对方面词情感极性的影响,本文提出基于局部全局上下文引导的方面级情感分类模型。一方面,通过引入依赖句法分析树为模型的输入增加更多元的句法信息特征,另外通过局部上下文聚焦机制使目标方面词到上下文的距离得到动态捕捉,从而更好地利用文本信息,同时也规避了部分文本噪音的影响;另一方面,将提炼后的局部特征向量与全局特征向量通过向量相加、相乘等方式进行引导处理,再通过使用全连接层的方式,较好地保留了提取的文本信息特征。最后,将处理过的局部向量与保留了信息特征的全局向量相加,作为输入在聚合模块进行处理,有效提取出方面词上下文的信息特征,提高了模型对情感极性的预测准确度。
1 相关工作
在以往学者的研究工作中,传统情感分析方法主要是基于文档级或句子级的,相比之下,基于方面的情感分析是面向实体的研究,是更精细的情感分析任务。
基于传统机器学习的方法则主要采用支持向量机(Support Vector Machines,SVM)[13]、k-最近邻(k-Nearest Neighbor,KNN)[14]、条件随机场(Conditional Random Field,CRF)[15]等进行情感分类。如Kiritchenko 等[16]使用SVM 检测客户评论中的方面词以及对应情感;Akhtar等[17]使用SVM 和CRF 进行印地语的情感分类,并取得了不错的效果;Patra 等[18]利用CRF 对Laptop 和Restaurant 数据集进行方面级情感分类,为消费者理性消费和制造商合理运营提供了一定的参考。总之,这些方法主要要求人工选择具有语义信息的特征进行训练,有效减少了意见词匹配的误差,但是这些机器学习方法仍然具有一定的局限性,比如在数据集文本上需要人工提取特征这一步骤,最后的情感分析结果严重依赖于人工选择的特征质量,并且无法对给定方面词及其上下文之间的依赖关系进行建模。
与基于传统机器学习的方法相比,深度神经网络具有更复杂的模型结构、更强的特征提取和特征拟合能力,并且省去了人工提取特征的过程,降低了人工成本。随着计算机硬件的发展、互联网的普及,深度神经网络也不再受到计算机硬件算力和样本数据的局限。在以注意力为主的序列模型方面,Cheng 等[19]使用扩展的上下文模块提高了Transformer 双向编码器的特征提取能力,同时提出成分聚焦模块来提高形容词和副词权重,以解决平均池的问题;Huang 等[20]提出结合注意力机制的AGSNP 模型,使用两个模块分别处理上下文词和方面词,取得了不错的效果;Ayetiran[21]提出两个变体,其中CNN 变体用来提取高层语义特征,BiLSTM 变体处理CNN 的输入,最后使用softmax 进行方面词情感极性预测。在以句法信息为主的模型方面,Wang 等[22]提出R-GAT 模型,首先对依赖解析树进行调整与剪枝,然后使用R-GAT 模型构建新的依赖树进行情感预测;Gu 等[23]提出EK-GCN 模型,融合了外部知识,使用外部情感词典为句子中的每个词分配情感分数,构造情感矩阵,在一定程度上弥补了句法依赖树不能捕获边缘标签的缺点。在围绕上下文建模的模型方面,Liu 等[24]提出的GANN 是一种封闭式的神经网络,其专门设计了GTR 模块用于学习方面词的信息表征,同时编码了上下文单词与方面词的语义距离、序列信息等情感线索;Phan 等[25]使用自注意力机制学习句法知识,提出句法相对距离以消除与方面词句法联系较弱的无关词的不利影响;Xu 等[26]提出基于动态局部上下文和依赖簇(DLCF-DCA)的情感分析模型,其中DLCF 可以动态捕获局部上下文的范围,而DCA 则着重于提取语义信息。DLCFDCA 在局部上下文中加入了动态阈值,并且设置了依赖簇进行特征提取,达到了不错的效果。
与基于注意力机制的模型相比,本文提出的模型融入了句法信息带来的信息特征,使得特征更加多元化。相比于基于句法分析的模型,本文提出的模型以上下文为关注重点,围绕上下文进行建模,同时引导局部上下文特征与全局特征进行特征交互而不是分别进行处理,有效保留了局部特征与全局特征,为后续进行特征聚合提供了有利条件。
2 LGCG模型
本文提出的基于局部全局的上下文引导网络(Local-Global Context Guiding Network,LGCG)模型如图2 所示。方面级的情感分类任务定义如下:给定长度为N 的句子,其由一组单词构成,每个方面词k均是句子的一部分。模型需要构建一个分类器预测一个或多个方面词的情感极性。其中,M 为方面词个数,M 始终小于N。

Fig.2 LGCG model图2 LGCG模型

Fig.3 Context information transmission图3 上下文信息传递
2.1 输入嵌入层
输入嵌入层将单词转换为携带语义信息的向量表示,对于一个句子,先使用预训练语言模型BERT[27]将每个词映射到嵌入向量ei∈Rd×1,其中词向量的维度为d。
在LGCG 模型中,输入嵌入层包括局部输入嵌入和全局输入嵌入,其中局部输入的构造为Wl={[CLS]+Sentence+[SEP]},全局输入的构造为Wg={[CLS]+Sentence+[SEP]+Aspect+[SEP]}。BERT 编码器会将局部输入与全局输入分别编码成,其中M、N分别为局部输入和全局输入的文本长度。[CLS]与[SEP]均为BERT 编码器的标识符,分别表示句子的开始与结束。
2.2 局部上下文聚焦
本文采用局部上下文聚焦(Local Context Focus,LCF)机制[28],使得模型能动态识别局部上下文范围,并对其进行更多的信息关注。另外,局部上下文聚焦使用上下文动态掩码(Context Dynamic Mask,CDM)与上下文动态加权(Context Dynamic Weighted,CDW)两种策略对上下文语义信息进行关注。
CDM 策略主要对语义相关性较低的上下文词进行屏蔽,并主动丢弃超过SynRD 距离的上下文语义信息。在CDM 策略中,将SynRD 设置为3。当SynRD 小于该词距离方面词的长度时,则说明该词对方面词具有一定影响,将其赋值为1;当SynRD 大于该词距离方面词的长度时,则说明该词对方面词无影响,将其赋值为0。输入序列中每个词经过同样的处理之后,均会产生长度一致的向量。CDM 策略具体计算过程如公式(3)—(5)所示。
CDW 策略则与CDM 策略不同,其对语义相关性较低的上下文词进行了权重处理,仍然保留了超过SynRD 距离的上下文语义信息。在依赖树的构造中,当句子的最大距离较大时,CDM 比CDW 有效,因为当最大距离很大时,也代表着局部上下文的范围更大。在此情况下,CDM可以更好地减少无关语义信息的干扰。反之,当最大距离较小时,局部上下文的范围有限,在此情况下,CDM 反而会丢失一部分局部上下文的语义信息,而CDW 可以保留局部上下文之外的部分语义信息,此时CDW 的加权效果会比CDM 更有效。CDW 策略具体计算过程如公式(6)—(8)所示。
其中,Global feature 为经过BERT 编码器编码后的全局特征向量,一方面,Global feature 与CDM/CDW 处理后的向量进行矩阵相乘,如公式(9)所示。另一方面,Global feature 与构造依赖树时生成的方面词依赖矩阵进行矩阵相乘,如公式(10)所示。其中,Depended 是由句法依赖树生成的矩阵。
2.3 特征聚合层
特征聚合模块(Features Aggregation,FA)包含两个全连接层与一个编码层。其中,第一个全连接层引入一个Dropout 层,而引入Dropout 则是为了防止过拟合的情况出现,同时提高模型对不同数据集的泛化能力。Featurel矩阵为CDM/CDW 矩阵与Depended 矩阵的相加。具体计算过程如公式(14)、(15)所示。
第二个全连接层引入一个池化层,用于将局部上下文和全局上下文的聚合特征由高维降至低维。在经过特征聚合层处理后,将聚合后的特征向量通过Encoder 编码器进行编码,之后通过池化层进行特征提炼,并应用其中一个层作为文本情感极性的预测结果,具体计算过程如公式(16)、(17)所示。其中,,dh为模型默认维度。
3 实验与分析
3.1 数据集
为了验证模型效果,本文选取SemEval-2014 的 Restaurant、Laptop 数据集[29]以及SemEval-2015 的Restaurant数据集[30]和SemEval-2016 的Restaurant 数据集[31]进行实验,这4 个数据集是当前方面级情感分类任务中使用最广泛的数据集。4 个数据集中的情感极性分为3 类:积极、中性和消极。所有数据集的统计信息如表1所示。
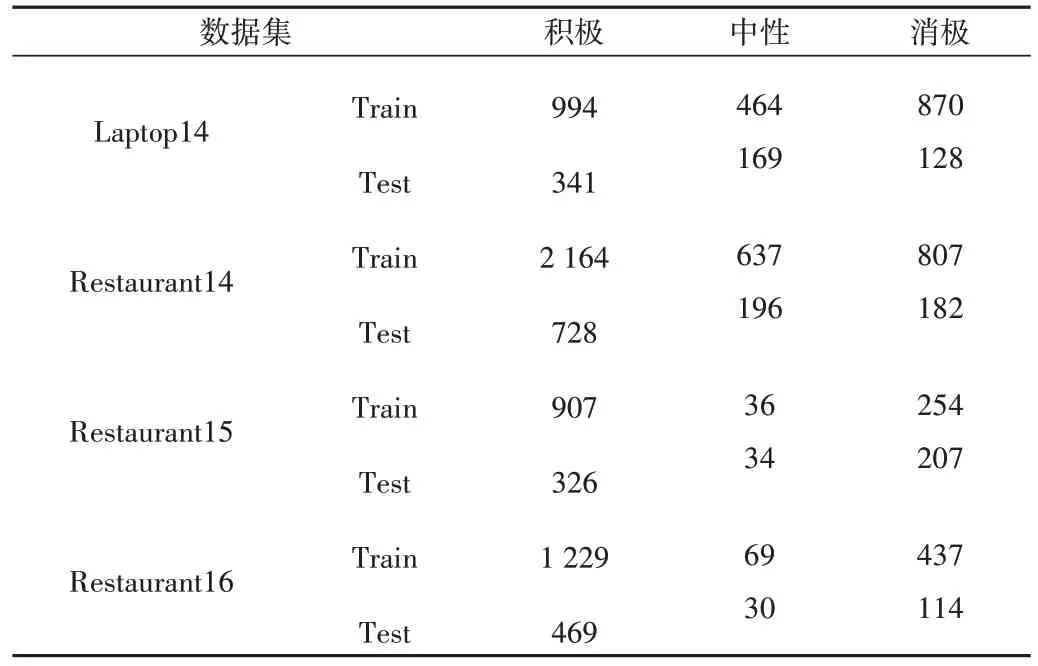
Table 1 Overall statistics of datasets表1 数据集总体统计
3.2 超参数设置
本文采用交叉熵损失函数作为目标函数,如公式(18)所示。
其中,C 为情感极性类别,为实际的情感极性类别,yi为模型预测的情感极性类别,λ为L2正则化参数,T为模型的参数集。
本文模型使用Pytorch 框架[32]实现,模型训练过程中采用Adam[33]优化器,参数初始化函数则是采用xavier_uniform[34],模型相关超参数如表2所示。

Table 2 Settings of model hyperparameter表2 模型超参数设置
3.3 评价指标
本文使用准确率[35](Accuracy)和Macro-F1[36](MF1)评估模型性能,计算过程如公式(19)-(23)所示。准确率表示所有类别中正确预测数在所有样本中的比例,通常准确率越高,表明模型性能越好。由于以上数据集分布不平衡,不能有效反映分类器的性能,所以采用MF1 作为额外的衡量标准。
对于情感极性分类i,TPi是正确预测的样本数,FPi是将积极样本错误预测为其他类别的积极样本数,FNi是将消极样本错误预测为其他类别的消极样本数,Pi是精确率(Precision),Ri是召回率(Recall),MF1 值则是所有类别的F1结果。
3.4 对比模型
为了全面、合理地评估模型,本文将方面级情感分类基线模型分成3 类:基于注意力、基于句法分析、基于上下文建模的基线模型。
3.4.1 基于注意力的基线模型
本文引入5 种具有代表性的基于注意力机制的方面级情感分类基线模型。
(1)IAN。IAN 以交互式注意力机制学习文本上下文和目标,分别生成目标和上下文的表征。到目前为止,IAN 提出的方面项与上下文的交互体系结构仍然是方面级情感分类任务中最常用的交互体系结构[37]。
(2)AOA。AOA 以相同的方式对各个方面词和句子进行建模,并捕获各个方面词和上下文句子之间的相互作用。AOA 模块联合学习方面词和句子的表征,并自动聚焦于句子中的重要部分[11]。
(3)CF-CAN。CF-CAN 提出扩展的上下文模块将上下文与目标词进行联系,使用一个多头的注意力层学习目标与上下文之间的关系,解决了以往采用注意力机制的模型需要将序列压缩成向量的问题[19]。
(4)ASGNP。ASGNP 改进了GSNP,用输出门代替消防门以控制输出,结合了注意力机制以有效提取上下文与方面词之间的语义相关性[20]。
(5)CNN-BiLSTM。CNN-BiLSTM 设计CNN 与BiLSTM的变体,可以从高级语义与上下文特征两个方向学习并进行捕获,修改了目标表征使得模型性能得到提高[21]。
3.4.2 基于句法分析的基线模型
(1)ASGCN-DG。ASGCN-DG 以句法约束和远程单词依赖性为重点,利用图卷积网络在句子的DSPT 上得到邻接矩阵,克服了注意力机制和基于CNN 模型的一些局限性。
(2)ASGCN-DT。ASGCN-DT 是ASGCN-DG 的一种变体。与ASGCN-DG 不同的是,ASGCAN-DT 构造的邻接矩阵较为稀疏,因为ASGCN-DT 认为在DSPT 中,父节点易受子节点影响。
(3)R-GAT+BERT。R-GAT+BERT 通过对DSPT 的重新调整和剪枝,定义了一个较为统一的面向方面词的依赖树结构,并使用关系图注意力网络对新的依赖树结构进行编码[22]。
(4)EK-GCN。EK-GCN 充分考虑了大量与文本相关的外部知识,通过引入外部知识重构句法依赖树,并设计了WSIN 模块以充分考虑当前方面词的信息,最后与评论的上下文信息进行交互[23]。
3.4.3 基于上下文建模的基线模型
(1)BERT-PT。BERT-PT 提出一种后训练方法,用于更好地调整BERT 以包含更多领域知识和任务知识,从而有效地帮助BERT 更好地适应当前任务。
(2)GANN。GANN 使用门截断RNN 学习信息,特别是方面相关的情感线索表征。其同时编码上下文单词之间的相对距离、方面词、序列信息和语义依赖关系,从而更好地进行情感极性分类[24]。
(3)LCFS-BERT-CDM。LCFS-BERT-CDM 设计了一种基于DSPT 的局部上下文聚焦机制,利用方面词与上下文之间的距离度量上下文中更重要的部分。LCFS-BERTCDM 屏蔽了离方面词较远的词[28]。
(4)LCFS-BERT-CDW。LCFS-BERT-CDW 是LCFSBERT-CDM 的一个变体,其考虑了离方面词较远的词带来的影响[28]。
3.5 实验结果与讨论
基线模型与本文模型的实验对比结果如表3 所示。由表3 可知,相对于对比的基线模型,本文提出的LGCG模型在方面级情感分类任务的4个数据集上,F1值以及准确率均有1%以上程度的提升。

Table 3 Experimental comparisons of several models in different datasets表3 几类模型在不同数据集上的实验结果对比 %
(1)LGCG 模型在方面级情感分类任务上的表现均超越了基于注意力的基线模型,主要因为其有效捕捉了局部文本中情绪信息词带来的影响。相比于CF-CAN 的多头共注意力,LGCG 提出一个特征聚合模块进行局部特征与全局特征的汇聚,提高了模型的表达能力。
(2)LGCG 模型在4 个数据集上的表现均优于基于句法分析的基线模型。不同于ASGCN-DG 模型所关注的邻接矩阵,LGCG 模型使用局部上下文聚焦机制,使得模型能动态识别不同方面词的局部上下文范围,更加关注局部上下文,而不采用图卷积网络提取文本的句法信息。其次,相比于R-GAT-BERT 模型,LGCG 模型在不需要调整依赖树结构的前提下,将句法信息融入模型,使得信息特征更加多元化,提高了模型的情感预测性能。
(3)LGCG 模型在基于上下文建模的基线模型中也取得了最高分数。其相比于LCFS-BERT 模型在4 个数据集上各项指标均有1%以上的提高,主要因为LCFS-BERT 模型虽然也采取LCF 机制,但其并未有效引导局部特征与全局特征进行交互,而是分别独立地处理信息。LGCG 模型在关注方面词局部上下文的同时,也进行了全局特征与局部上下文特征信息的融合操作,依赖矩阵使特征向量在融合过程中消除了部分信息噪音,从而使模型对情感极性的预测更为准确。
另外可以发现,相比于准确率,LGCG 模型在召回率上的表现会更突出一些,充分说明模型对情感极性的预测准确率有较大提升,也表明LGCG 模型的各个组件均起到了作用。
3.6 消融实验与分析
为了验证本文所提出模型中各个组件的性能,本文进行了消融实验。在4 个基准数据集上的实验结果如表4 所示。在表4 中,“without”表示去除相关组件,“equipped”则表示使用该组件。
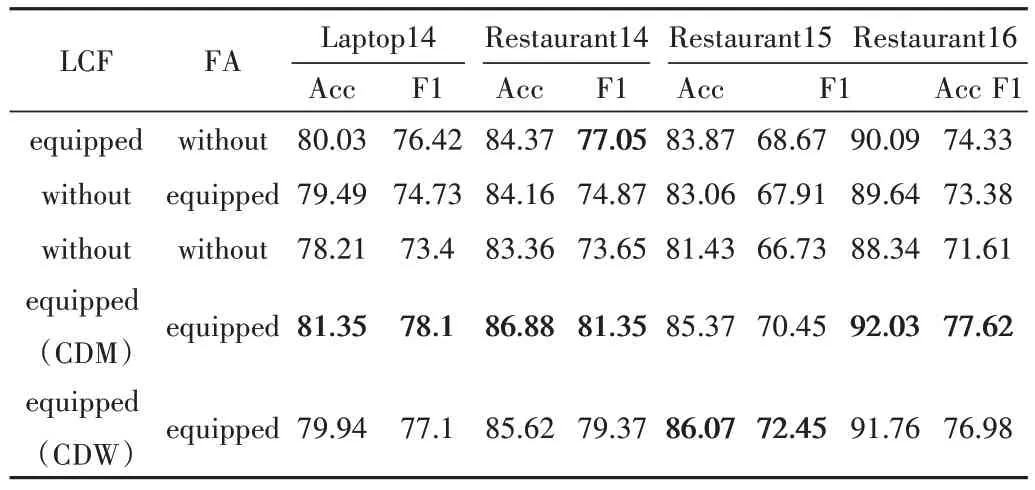
Table 4 Result of ablation experiments表4 消融实验结果 %
(1)可以看到当去除FA 模块时,模型对文本情感极性的预测准确率和F1 值在4 个数据集上均下降了1%以上。原因是模型虽然保留了对局部特征与全局特征交互的过程,但模型直接进行特征提取,缺少了特征聚合操作,导致模型对文本信息特征提取不足,表达能力下降。
(2)当去除LCF 模块时,此时在4个数据集上模型的准确率和F1值均下降了2%以上,其中F1值的下降程度更为明显,在Restaurant14、Restaurant15 数据集上分别下降了6.48%、4.54%,充分说明了LCF 模块在模型中对局部上下文的聚焦作用起到了至关重要的作用,是LGCG 模型的关键模块。
(3)当将LCF 模块与FA 模块都去除时,明显看到模型的各个指标在4 个数据集上均下降了3%~4%左右。这是因为模型缺少了主要模块,两个通道的信息特征并未进行特征交互,丢失了部分上下文信息特征,并且模型直接进行特征提取,模型提取的信息不足,导致情感极性的预测准确度下降。
总的来说,从消融实验结果可以看出,LGCG 模型的各个组件在方面级情感分类任务中均起到了至关重要的作用。
4 结语
本文提出基于局部上下文和特征融合的方面级情感分析模型LGCG,通过引入句法信息以丰富特征,同时使用LCF 机制以及局部全局特征引导的方式进行特征交互,很好地保留了文本中的信息特征,最后对特征进行聚合与提取,提高了模型的表达能力,有效提升了模型在方面级情感分类任务中的性能。在4 个基准数据集中与基线模型相比,本文提出的模型在F1 值以及准确率上均有1%以上的提升。
虽然本文模型与基线模型相比有一定的进步,但在实验中仍然发现了一些影响模型性能的问题:①使用不同的分词器工具会影响对情感极性的预测。针对此问题,未来将考虑采用更先进的分词器进行文本分词工作;②使用不同依赖树构造工具构造出的依赖树存在不一致的问题,导致模型性能表现不理想。针对此问题,未来将考虑使用更好的依赖树构造工具。
