基于交互属性增强的电影评分预测
2024-02-21许星波张明西朱衍熹
许星波,张明西,赵 瑞,朱衍熹
(上海理工大学 出版印刷与艺术设计学院,上海 200093)
0 引言
电影是人们生活中不可或缺的娱乐方式之一。对于数量众多的电影,用户需要一个评价标准帮助他们进行选择。其中,数值评分能直观表示一部电影的质量,准确地预测评分有助于用户寻找到其喜爱的电影,减轻信息过载问题[1]。现有电影评分预测方法主要包括从用户和电影的历史交互信息方面预测评分,针对交互信息建立共现矩阵,计算矩阵相似度或生成隐向量预测用户对电影的评分,例如基于邻域[2-3]、基于矩阵分解[4-6]的协同过滤;基于深度学习的方法构建神经网络,挖掘交互信息中用户行为规律和潜在特征向量,以减小模型预测误差[7-9]。
然而,单一的历史交互信息难以充分反映用户的偏好信息,会影响预测结果的准确性。为此,将辅助信息引入评分预测模型,例如通过自然语言技术对用户评论[10]、电影简介[11]等进行文本信息向量化,并对特征向量进行建模训练;结合映射函数[12]和自动编码器[13]优化矩阵分解模型,利用其分解属性的潜在特征提升预测准确性,虽然该类方法通过辅助信息能更有效地捕捉用户偏好,但大多将文本作为辅助信息未能直接、充分利用属性特征。
为此,本文提出一种基于交互属性增强的电影评分预测模型(Prediction Model for Movie Ratings Based on Interactive Attribute Enhancement,MRIAE),根据用户、电影和属性间的关系构建电影信息网络。首先,利用metapath2vec算法以网络节点形式,将不同属性映射到对应特征空间,以获得能表达网络结构和语义信息的特征向量;然后通过双塔预测模型嵌入用户和电影特征,并与各自属性特征融合实现评分预测。
1 相关工作
现有电影评分预测方法主要分为基于交互信息和结合辅助信息的方法。早期研究中,学者们分析用户对电影的历史交互信息预测用户行为。Sarwar 等[2]利用交互信息构建共现矩阵提出一种基于物品的协同过滤算法计算电影间相似性,通过用户对相似电影的历史评分数据预测用户对目标电影的评分。Koren 等[6]针对共现矩阵提出矩阵分解算法(MF),将用户和电影映射到相同的潜在特征空间,通过计算用户和项目特征向量的内积预测评分。
近年来,深度学习技术通过复杂网络结构进一步挖掘评分数据间的潜在特征。Lund 等[7]结合用户的历史评分数据设计了一种基于协同过滤的自动编码器,相较于基于邻域的基线模型具有更好的预测性能。He 等[8]针对数据特征交互提出NFM 模型,通过组合二阶线性特征和高阶非线性特征进一步提升了模型评分预测的准确性。Zhou等[9]通过距离计算得到用户和电影的交互特征及权重,使用Item2vec 映射特征向量设计多层全连接神经网络进行评分预测。
然而,上述方法依赖单一的历史交互信息,提升的预测性能有限,因此研究人员进一步引入评论、属性等辅助信息分析用户偏好。Zhu 等[10]对用户评论进行文本向量化,结合BiLSTM 网络分析情感倾向并填充用户评分矩阵进行相似度计算,以预测用户对电影的评分。Won 等[11]首先向量化电影概述,然后由嵌入层得到用户及其交互电影的潜在ID 表示,通过改进DeepFM 模型学习特征间的高阶、低阶信息,然后输出最终预测评分。Gantner 等[12]通过映射函数将用户或电影属性映射到潜在向量空间,然后结合映射函数优化得到具有属性意识的矩阵分解模型,从而提升模型的预测准确性。Xin 等[13]首先利用自动编码器提取用户、电影的属性与评分特征,然后结合特征重构评分矩阵,并最小化原始评分矩阵和重建评分矩阵之间的误差。Wang 等[14]将项目属性作为知识图的补充信息并引入,通过知识图嵌入方法将实体和关系转化为向量表示,然后结合图形注意机制学习不同属性对用户的影响,最后通过聚合传播层的用户和项目表示得到预测评分。
2 相关概念
2.1 异构网络
电影信息网络可定义为一个无向图G=(V,E),如图1所示。其中,V=VU∪VM∪VD1∪...∪VDi,VU为用户节点集合,VM为电影节点集合,VDi为第i种类型的属性节点集合;E=EUM∪EUDU∪EMDU,EUM表示用户与电影的交互关系边集合,EUDU表示用户及其属性的包含关系边集合,EMDM表示电影及其属性的包含关系边集合。同时,节点类型映射满足Φ:V→A,边类型映射满足Ψ:E→R,A、R分别表示节点类型集合与边类型集合。

Fig.1 Movie information network图1 电影信息网络
2.2 网络模式
本文设置一个描述电影信息网络中节点类型与节点类型间关系的元结构(见图2),形式化定义为TG=(A,R),其中节点类型集合A={U,M,DU,DM},边类型集合R={UM,UDU,UDM},DU=Du1∪… ∪Dun表示n种用户属性节点类型集合,DM=Dm1∪… ∪Dmn表示n种电影属性节点类型集合。

Fig.2 Network schema图2 网络模式
2.3 元路径
给定电影信息网络G和网络模式TG=(A,R),根据用户与电影交互中不同的语义信息定义元路径(见图3),如式(1)所示。其中,R=R0∘R1∘...∘Rl-1表示V1节点到Vl节点间路径的组合。
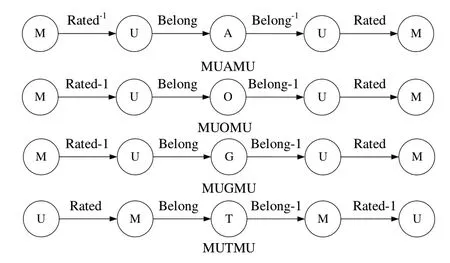
Fig.3 Metapath图3 元路径
2.4 电影评分预测
给定用户信息、电影信息及用户对电影的历史评分信息,电影评分预测问题就是将用户信息、电影信息中各特征转换为对应向量,即将用户和目标电影的ID 特征转换为向量eu、em,属性特征转换为向量dui、dmj(i=1,2,…,n),将ID 特征与各自属性特征向量交互融合得到用户特征u和电影特征m,以预测用户对电影的评分。
3 模型设计
为了准确预测电影评分,本文提出一个基于交互属性增强的电影评分预测模型MRIAE,主要分为属性嵌入增强模块和评分预测模块,如图4所示。
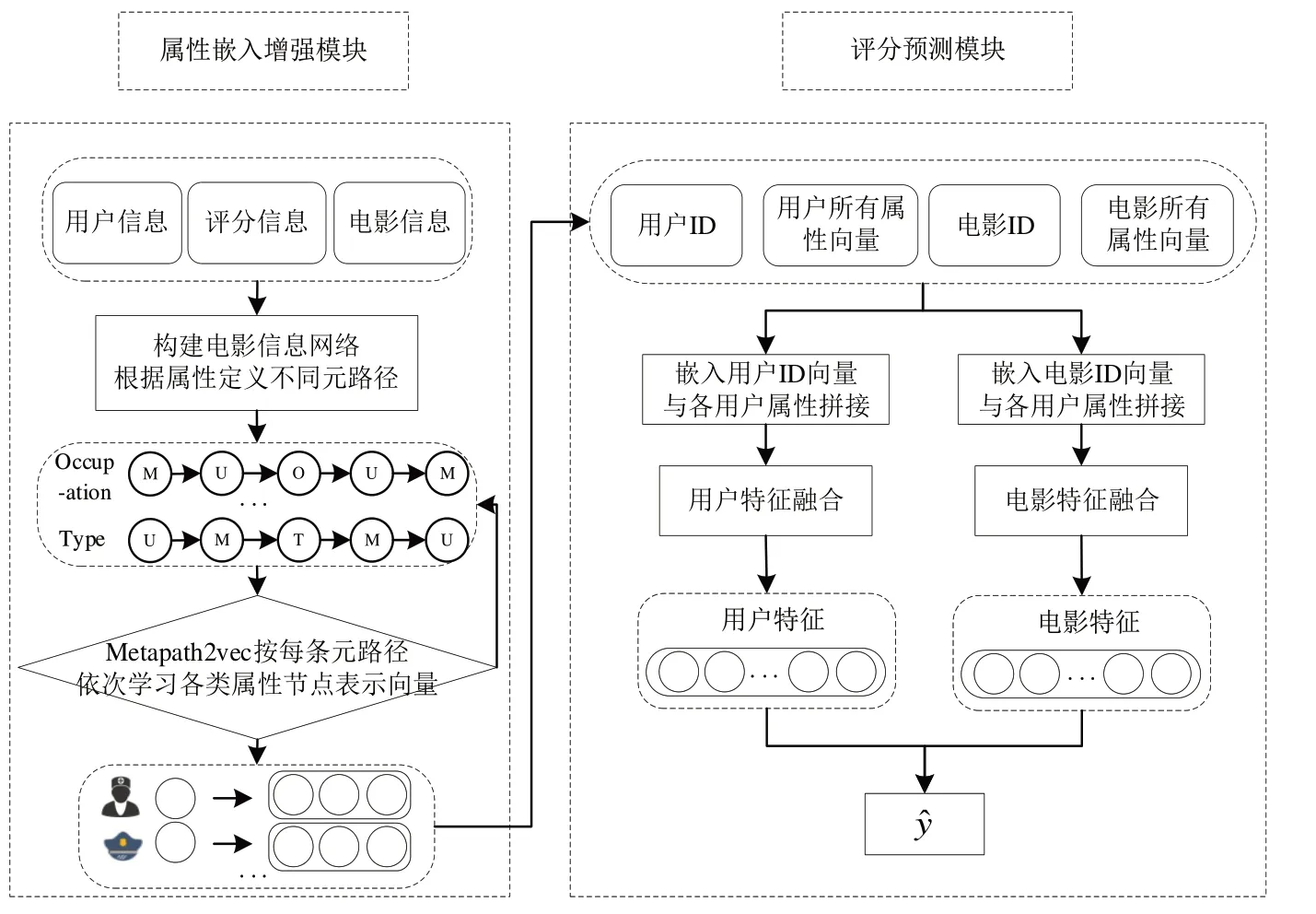
Fig.4 Model process framework图4 模型流程框架
3.1 属性嵌入增强模块
3.1.1 Metapath2vec
属性嵌入增强模块为获得属性特征的增强表征,深入挖掘电影信息网络中属性节点的潜在规律,通过属性节点在电影信息网络中的嵌入向量表示属性特征信息。网络中的用户节点VU、电影节点VM和多种属性节点VDi,由用户ID、电影ID 及各自属性特征抽象及编号获得,不同类型的边由节点间的关系构成。考虑到属性节点的结构信息和元路径语义信息提取因素,将选择Metapath2vec 算法[15]对电影信息网络中的属性节点进行向量化表示。Metapath2vec 算法将Word2vec 算法[16]学习文本语料库中单词上下文信息的概念引入异构网络,通过基于元路径的随机游走策略生成可被Skip-gram 模型学习的节点序列,随机游走的概率为:
式中:∈Vt为在第i种的t类型的节点,Nt+1()表示节点的邻居节点类型为t+1;(vi+1,) ∈E;∅(vi+1)=t+1表示第i个节点与第i+1个节点间存在边,并且第i+1 个节点的类型为t+1,随机游走过程中的节点类型t和t+1取决于定义的元路径P。
Skip-gram 模型设定窗口大小为w,将每个节点序列中的节点轮流作为中心词,最大化计算中心词节点和上下文节点的平均出现概率,以获得每个节点的表示向量:
Metapath2vec 在Skip-gram 模型的基础上,添加了对不同结点类型的限制,对于给定节点v,最大化其异构上下文的概率,具体的目标函数为:
式中:Nt(v)表示节点Vt的邻居集合,类型为t,即给定节点v,计算该点邻居节点ct出现的平均概率,并使其最大化。
P(ct|v;θ)为softmax 函数(见式(5)),Xv为节点v的表示向量。
3.1.2 属性节点表示学习
由于不同属性反映的偏好不同,准确把握用户兴趣是提升预测准确性的关键,为最大程度学习各类属性节点中的网络子结构与元路径语义信息,本文提出单属性元路径,如式(6)、式(7)所示。
式中:Di⊆DU且|Di|=1;Dj⊆DM且|Dj|=1。
图3 定义了电影信息网络中的4 条单属性元路径,如式(6)、式(7)所定义,每条单属性元路径中包含了一种用户属性或电影属性节点,模型利用Metapath2vec 每次依据一条单属性元路径随机游走并训练,可得到该元路径中对应类型属性节点的所有向量表示。
由式(2)可知,当t类型的第i个节点与下一节点vi+1间存在链接,且下一节点符合当前单属性元路径定义下的节点类型,则以概率p进行节点跳转。由此可得,用户、目标电影的不同类型属性的向量dui、dmj,其中dui表示第i种用户属性向量,dmj表示第j种电影属性向量。属性节点向量生成结构如图5所示。

Fig.5 Attribute node vector generation process图5 属性节点向量生成过程
通过单属性元路径的训练方式,不同网络子结构信息和元路径语义信息被有效融入对应的属性向量表示。例如,元路径UMTMU(用户—电影—电影类型—电影—用户)表示两个用户间共同观看相同类型电影的关系,而MUOUM(电影—用户—职业—用户—电影)表示具有相似职业两个用户观看同一部电影的关系,有助于充分学习不同属性节点的潜在特征,增强不同偏好的表达,使模型预测结果更准确。
3.2 评分预测模块
3.2.1 DSSM模型
2013 年,微软发布DSSM 模型的核心思想是将查询词和文档进行特征编码,计算其相似度以达到检索排序的目的[17]。Elkahky 等[18]在DSSM 基础上进行改进和扩展,将DSSM 应用到推荐系统召回任务中,分别使用两个深度神经网络构建用户特征和物品特征,一般称为双塔模型。该模型结构简单,能快速训练模型、优化参数,由于训练得到的用户特征及物品特征能离线存储在数据库中,因此有效提升了在线预测效率。通过属性嵌入增强模块预训练得到所有属性特征的向量表示后,考虑到用户属性特征和电影属性特征反映的偏好不同,本文使用双塔模型作为评分预测模块框架。如图6 所示,将用户和电影ID 作为向量嵌入,并输入用户和电影属性特征对应的向量,通过用户侧和电影侧网络交互融合来探索不同属性偏好对用户、电影的影响,最后对投影在各自统一空间的用户特征向量和电影特征向量进行评分预测。
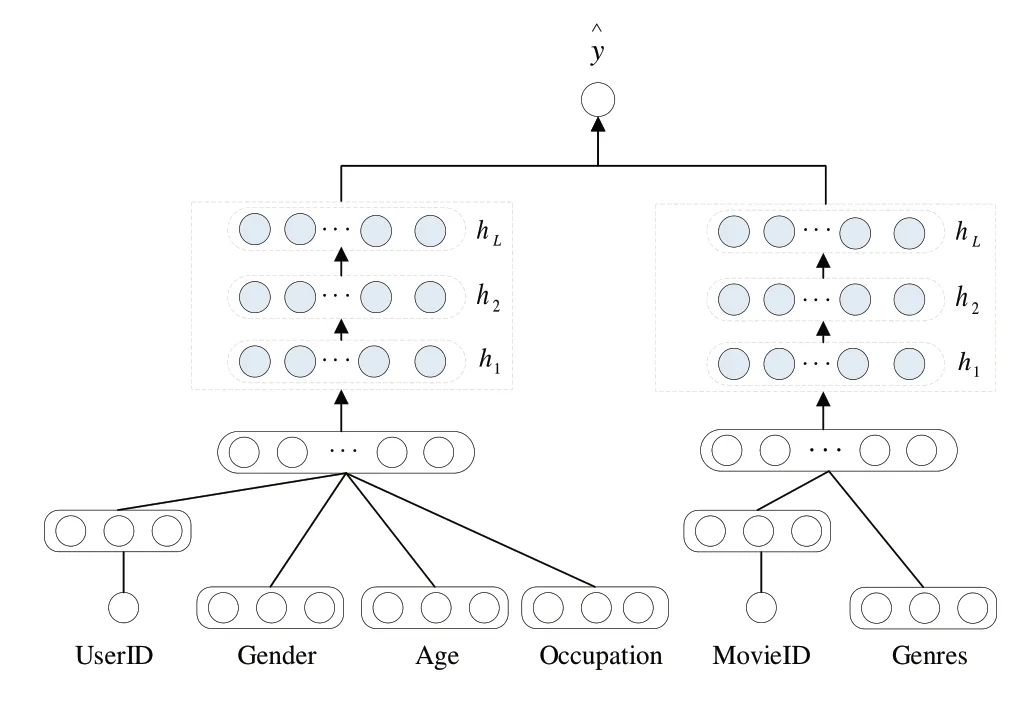
Fig.6 Attribute node vector generation process图6 属性节点向量生成过程
3.2.2 Embedding层
模型输入的用户特征分为两部分,一部分通过属性嵌入增强模块得到的用户属性向量,另一部分将用户ID 作为用户本身通过Embedding 层生成的用户特征向量,输入电影特征也分为相同的两部分。Embedding 层在模型建立时,将随机初始化权重参数矩阵E作为Embedding 矩阵,其中E∈Rm×k,m代表实体个数,k为向量维度。Embedding矩阵将实体i的ID 编号xi映射到表示空间Ei,如式(8)所示。经过Embedding 层,每个用户和电影ID 都转换为对应用户特征向量eu和电影特征向量em。
3.2.3 特征融合层
模型的用户侧子网络和电影侧子网络分别为两个同样的多层感知机,将用户特征向量eu和用户属性向量dui、电影特征向量em和电影属性向量dmj进行融合,然后投影到各自统一的特征空间。
首先,将eu、em与各自属性向量拼接得到用户特征u和电影特征m。其中,电影类型的多值属性对应多个属性向量,通过相加后拼接。
然后,将得到的用户特征u和电影特征m分别输入用户侧和项目侧的多层感知机进行训练,得到融合交互后的用户特征u'和电影特征m'。
式中:wul、bul为用户侧第l层权重和第l层偏置;wml、bml为电影侧第l层权重和第l层偏置;σ为激活函数Relu。
3.2.4 评分预测层
将得到的用户特征u'和电影特征v'进行点积得到最终预测评分,并与真实样本评分比较,通过MSE 函数优化损失。
式中:y为用户对电影的真实评分;为预测评分。
4 实验结果与分析
4.1 实验设置
4.1.1 数据集
本文在由Grouplens Research 团队收集的真实数据集Movielens-1m 上进行实验[19]。该数据集包括用户信息、电影信息和评分信息,通过抽象、编号信息中的各个字段得到用户节点、电影节点和属性节点。
(1)用户数据集包括用户ID、性别、年龄和职业字段,分别有6 040 名用户、性别、7 个年龄层和21 种职业,不同数字指代不同年龄层和职业类别。

Table 1 User dataset表1 用户数据集
(2)电影数据集包括电影ID 和电影类型字段,包括了3 883部电影和18种电影类型。

Table 2 Movie dataset表2 电影数据集
(3)评分数据集包括用户ID、电影ID 和用户对电影的评分字段。

Table 3 Rating dataset表3 评分数据集
4.1.2 评价指标
为了评估不同模型的预测性能,实验使用平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square Error,RMSE)作为评价指标,预测误差越小代表模型准确性越高。MAE 表示预测值与真实值yi绝对误差的平均值,代表预测值的平均误差幅度;RMSE 代表预测值i与真实值yi误差的平方和预测次数n比值的平方根。
4.1.3 比较方法
本文模型使用了用户与电影间的评分和属性信息,将其与使用评分信息或评分与属性信息的方法进行比较。其中,ItemCF 为基于物品的协同过滤算法,通过历史评分数据构建交互矩阵,完成物品间的相似度计算,然后利用与用户目标电影相似的邻居电影的评分,预测用户对目标电影的评分[2];PMF 为概率矩阵分解算法,将用户和项目的交互矩阵分解为用户隐式矩阵和电影隐式矩阵,再利用隐式矩阵预测用户对电影的评分[20];Wide&Deep 由线性模型与DNN 融合的组合模型,通过线性模型捕捉用户和物品低阶特征交叉,基于深度神经网络模型学习高阶特征交叉,然后联合训练两种模型共享输入层[21];NFM 为融合了FM 与DNN 的组合模型,通过设计Bi-Interaction 的方法处理二阶交叉信息,然后基于深度神经网络学习交叉特征[8];DeepFM 为结合了FM 模块和Deep 模块的模型,FM 模块学习用户和物品低阶特征交叉,Deep 模块学习高阶特征交叉,使模型实现高阶特征和低阶特征的交互[22];EDCN为结合bridge 和regulation module 对DCN 进行加强的模型,通过在隐藏层中进行信息交叉以捕获cross 和deep 层的隐藏信息[23]。
4.1.4 参数设置
MRIAE 模型分为属性嵌入增强模块和评分预测模块,根据经验初始化参数并分析数据,通过微调使其达到最佳性能。本文使用Metapath2vec 算法对属性特征进行预训练得到向量表示,设置游走长度为10,每个节点游走次数为100,窗口大小为7。由于嵌入维度参数对模型预测准确性存在重要影响,实验发现嵌入维度参数设置为16 时,可得到最佳预测效果。
在双塔预测模型中,选取80%的实验数据为训练集,剩余数据为测试集,用户侧和电影侧的MLP 网络各层神经元数量都设置为[516,256,128],学习率为0.000 1,训练次数epochs 为50,同时采用早停机制避免模型发射过拟合现象。ItemCF 和PMF 代表分析用户与电影交互行为的传统算法,只利用用户对电影的历史评分数据。WideDeep、NFM、DeepFM 和EDCN 代表学习高低阶特征交互的深度神经网络,为了保证模型间的公平性,本文模型使用相同的用户和电影信息,嵌入维度设置一致且模型参数规格设置接近。
4.2 实验结果
表4为各算法在Movielens-1m 数据集上的结果实验结果。由此可知,传统ItemCF、PMF 算法只考虑了用户和电影的交互关系,ItemCF 预测误差最大,PMF 相较于ItemCF在MAE、RMSE 指标上分别降低4.88%、5.83%。深度神经网络模型NFM、WideDeep、EDCN 和DeepFM 由于引入多种属性特征作为辅助信息,并学习了这些特征间的高阶和低阶交互,其评分预测误差均低于ItemCF、PMF,其中Deep-FM 表现最好。本文所提MRIAE 模型相较于传统算法ItemCF、PMF,在MAE 上分别降低了7.96%、6.93%,在RMSE 上分别降低3.24%、1.16%;相较于NFM、WideDeep、EDCN 和DeepFM,在MAE 上分别降低了1.5%、1.18%、1.16%和0.98%,在RMSE 上分别降低了1.07%、0.84%、0.71%和0.65%。

Table 4 Results of contrast experiment表4 对比实验结果
实验表明,本文模型不仅考虑了属性特征,还通过挖掘用户与电影的交互和从属关系,丰富了属性特征向量的表示,能学习得到具有不同属性偏好的用户和电影特征向量,可有效提升了评分预测准确率。
4.3 参数分析
4.3.1 属性表示对模型的影响
MRIAE 模型通过在属性嵌入增强模块学习用户和电影各属性特征的向量表示,作为评分预测模块的属性输入。为验证网络结构和语义信息对属性向量的增强效果,使用Embedding 层替代属性嵌入增强模块中的Metapath2vec 算法,在MAE、RMSE 指标上进行比较,如表5所示。

Table 5 Experimental results of different attribute representation methods表5 不同属性表示方法的实验结果
由表5 可见,通过Metapath2vec 学习属性节点嵌入后表示的各属性特征向量,在融合电影信息网络中不同元路径结构及语义信息后的结果较好,相较于Embedding 层在MAE、RMSE 指标上分别降低3.99%和4.27%,能有效提升模型预测的准确性。
此外,本文还研究了不同比例训练数据对预测结果的影响,如图7 所示。由此可见,随着训练数据比例提升,两种模型的MAE、RMSE 值逐渐减小,使用Metapath2vec 的MRIAE 模型在不同比例训练数据下的结果均优于仅用Embedding 层提取属性特征的模型。实验证明了利用电影信息网络的结构和语义信息能有效增强属性特征的表示能力,可提升模型预测准确性。

Fig.7 Influence of different scales of training data on error图7 不同比例训练数据对误差的影响
4.3.2 嵌入维度对模型的影响
在将节点转化为表示向量的过程中,特征维度的选择对模型预测准确性有着重要影响。为验证属性向量维度对预测结果的影响,以MAE、RMSE 为指标分别选择维度d=[8,16,32,64,128]在数据集上进行实验,结果如表6所示。由此可知,当d=16 时预测误差最低;当d由8 向16增加时MAE 和RMSE 降低,因为过低的向量维度会损失部分用户和电影信息,随着向量维度增加,属性特征表示就更丰富,因此预测误差更小;当d由16 增加到32 及更高时MAE 和RMSE 逐渐升高,因为过高的维度增加了属性特征的向量表示的噪声,导致模型误差上升。

Table 6 Experimental results of different embedding dimensions表6 不同嵌入维度的实验结果
图8 为不同嵌入维度的MAE 值、RMSE 值随迭代次数的变化情况。由此可见,随着嵌入维度增加,模型到达最优解所需的训练轮次越来越少,当d=16 时预测误差最小,而d=128 时模型收敛所需的轮次最少,但预测误差最大。

Fig.8 Influence of embedding dimension on error图8 嵌入维度对误差的影响
4.4 案例研究
为了进一步理解模型的预测过程,本文随机选取5 个对目标电影作出不同评分等级的用户进行案例研究,预测结果如表7 所示。表7 详细展示了预测过程中使用的用户信息、电影信息、真实评分及预测结果。其中,ID 代表用户及电影自身;用户属性包括性别、年龄和职业;电影属性包括电影类型。

Table 7 Movie rating prediction case表7 电影评分预测案例
实验表明,对于1~5 分的5 个实例,模型预测评分分别为0.79、1.78、2.62、3.74、4.33,误差较小,表明属性能在一定程度上表现用户偏好,为预测提供参考。
5 结语
考虑到现有方法中对属性特征表示能力不足的问题,提出一种基于交互属性增强的电影评分预测模型。首先,通过分析用户和电影信息间的多种关系构建电影信息网络,使用Metapath2vec 算法向量表示网络中的属性节点,以充分挖掘属性特征在电影信息网络中的结构和语义信息。然后,使用双塔预测模型将表征用户和电影的ID 特征向量与各自的属性向量交叉融合,得到用户和电影的特征向量。最后,通过点积实现用户对电影的评分预测。
在Movielens-1m 数据集上的实验结果表明,本文模型的预测准确性相较于现有方法均存在不同程度的提升,证明了模型的有效性。
