基于多层感知机的轻量级遥感影像语义分割方法研究
2024-02-21吕文琪简夜明
吕文琪,马 骁,简夜明,向 毅
(重庆科技学院 智能技术与工程学院,重庆 401331)
0 引言
图像分割是遥感影像建筑物检测中的一项主要任务,对于在分辨率较高的大型图像中提取固定建筑物至关重要。受高分辨率遥感图像的成像因素以及建筑物自身尺寸和形状特征多样性的影响,遥感图像建筑物分割一直是该领域的研究重点和难点。传统的建筑物分割方法多基于人工构造特征结合传统图像分割方式,针对特定场景实现建筑物分割,但其无法达到自动分割建筑物的目标,且分割精确度较低、鲁棒性较差。近年来,使用深度语义分割算法在固定建筑物提取中效果良好,UNet[3]是一项具有里程碑意义的研究成果,其展示了如何有效使用具有Skip Connection 的编码器—解码器卷积网络进行图像分割。近年来,UNet 已成为几乎所有领先的图像分割方法的标杆。继UNet 网络之后,研究者们又相继提出一些关键性的扩展方法,例如UNet++[4]、UNet3+[5]、3D UNet[6]、V-Net[7]、Y-Net[8]以及KiUNet[9]等。
随着注意力机制在图像领域的广泛应用,研究者们提出许多基于Transformer 的网络结构用于医学图像分割,如Transfromer[10]可以使模型更加倾向于关注图像的全局特征,对分割任务有着较大帮助。TranUNet[11]将ViT 架构修改为用于2D 医学图像分割的UNet。其他的一些基于Transformer 的模型,如MedT[12]、TransBTS[13]和UNETR[14]也相继被提出。但是之前的工作大多关注于如何提高网络性能,而忽略了关键的运行时间与效率问题。较复杂的模型虽然性能较好,但是复杂的结构在带来较高准确率的同时也会产生大量计算参数,所需推理时间较长,导致模型训练速度与效率降低。而往往在实际应用中,效率是必须考量的因素。在实验室进行实验时,通常会使用具有较强计算能力的机器(GPU)来辅助计算,以提高训练速度,但这些辅助计算工具在实际应用中很难进行部署,导致一些模型往往只是停留在实验阶段,而没有真正应用于实际。
当发生地震等自然灾害时,如果破坏程度较高,建筑物会发生很大变化,通过遥感图像对灾区建筑物进行图像分割有助于救援工作的开展。但现有图像分割模型庞大,难以在实际工程中得到应用,所以对遥感图像分割提取模型的轻量化具有重要的应用价值。然而,现有基于深度学习的模型均未考虑深度卷积网络的轻量化与可移植性。模型从实验室到落地实际工程应用,如何将模型进行轻量化处理是近几年的研究热点,2017 年,Howard 等[15]提出深度可分离卷积并构建了MobileNet 网络,该网络具有较高的分类精度,并在一定程度上减少了网络的参数量。Tan等[16]提出在MobileNet 等相关网络基础上,对网络深度、宽度及特征图分辨率3 个维度以及图像分类精度、效率之间的关系进行研究,并设置合适的约束条件,通过NAS 搜索得到一系列精度和效率兼优的网络模型。
有研究发现,一种基于MLP(Multi-Layer Perception)的网络被发现可以胜任计算机视觉任务。特别是MLPMixer[17],一个完全基于MLP 的网络,其在性能上与Transformer 相同,但是相比Transformer,MLP 采用更少的参数与资源。MLP-Mixer 使用两种类型的MLP 层,channel-mixing MLP 和token-mixing MLPs。channel-mixing MLP 用 来提取不同的token 特征,token-mixing MLPs 用来获取局部空间信息。Graham 等[18]提出了类似的体系结构,并用更简单的仿射变换取代了层归一化。为了保存输入图像的位置信息,Hou 等[19]保持了输入2D 图像,并分别沿宽度和高度排列来提取特征。基于MLP-Mixer,Yu 等[20]使用空间移位操作代替token-mixing MLPs 层来捕获局部空间信息,同样实现了很高的效率。近年来,Lian 等[21]提出沿两个正交方向移动标记,以获得轴向感受野;Chen 等[22]提出一个循环全连接层,其可以同时沿着空间维度和通道维度混合信息,并能够处理不同尺度的输入图像;Diakogiannis等[23]在ResUnet 的基础上,定义了新的损失函数Dice,可以加速模型分割速率,但是存在极大的不平衡性;Valanarasu 等[24]基于MLP 和Unet 网络设计出一种新的Unext网络结构,但Unext只是使用了MLP 和卷积操作,并没有在连接过程中考虑图像的细粒度特征,忽略了一些通道上的感受野。
1 本文方法简介
本文提出一种结合卷积模块与MLP 模块的网络结构,遵循U-Net 网络结构的5 层深度编码器—解码器体系,但在每个模块的设计上作出了改变。将整个网络分为两个阶段,减少卷积模块的过滤器数量,在MLP 模块中加入了移位操作,以提取不同移位对应的局部信息。同时,在跳跃连接过程中加入高效的通道注意力模块,使用通道注意力强化网络的多尺度特征信息,提高模型对于建筑物特征的灵敏度。并且,本文方法能够在减少参数和计算复杂度的基础上保持良好性能。
1.1 U-Net网络结构
U-Net[3]是一种被广泛应用于图像分割的全卷积神经网络。对于遥感图像分割任务来说,研究者们对于各类遥感图像中建筑物的位置分布更感兴趣。U-Net网络的工作原理如下:遍历图像的每一个像素,然后进行像素级分类,并根据分类后的像素种类进行图像分割。其结构如图1所示。U-Net 网络包含编码器和解码器两部分,编码器的主要功能是提取图像特征,解码器的功能则是进行上采样工作。由图可知,左半部分为编码器,是由两个3×3 的卷积层再加上一个2×2 的池化层组成一个下采样模块;右半部分为解码器,是由一个上采样的卷积层和特征拼接concat 以及两个3×3 的卷积层叠加构成。U-Net 有较深的网络层,有更大的视野域,浅层卷积关注的是表层纹理特征,而深层网络能关注更本质的特征。通过解码器的反卷积得到更大尺寸的边缘特征,会导致在下采样过程中损失相应的边缘特征,而通过特征的拼接可以找回边缘特征。
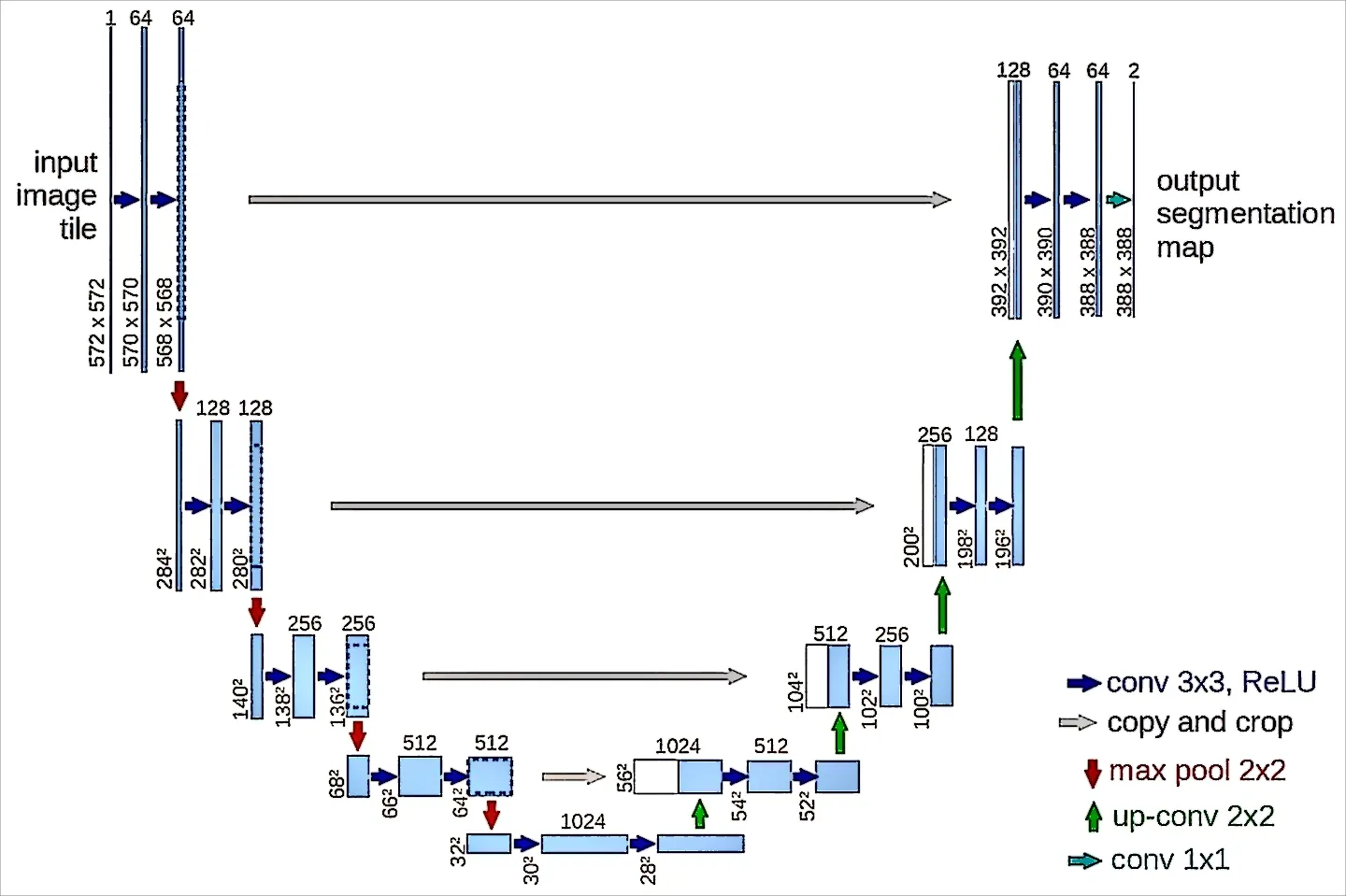
Fig.1 U-Net network structure图1 U-Net网络结构
1.2 基于Attention-MLP的U-Net网络
考虑到实际应用效率,本文专注于设计一个高效的网络,使其具有更少的参数,且运算时间更短,同时能保证计算的准确性。为此,本文在原有的U-Net 网络中引入多层感知机MLP,对原有U-Net 网络结构中的两层卷积层进行替换。同时,为了保证其具有良好性能,将注意力机制引入其中。在编码器与解码器进行跳跃连接过程中加入一个注意力控制机制。如图2 所示,本文的网络主要分为两个阶段:卷积阶段和标记多层感知机阶段。输入的图像首先通过编码器,包括前面3 个卷积模块以及2 个MLP 模块。解码器由2 个MLP 模块以及3 个卷积模块组成。每个编码器块将特征分辨率降低两倍,每个解码器块将特征分辨率提高两倍,在编码器与解码器之间会有跳跃连接。为了减少参数量,设置超参数为C1=32,C2=64,C3=128,C4=160和C5=256。与U-Net 网络相比,本文方法有效减少了参数量,有助于进行计算。
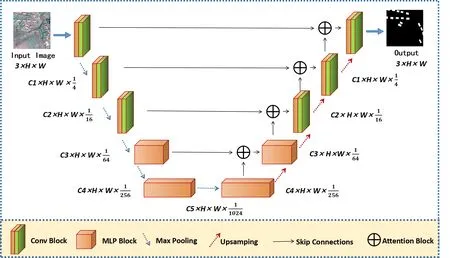
Fig.2 Network structure combining convolutional module and MLP module图2 结合卷积模块与MLP模块的网络结构
1.3 卷积模块
每一个卷积模块都含有卷积层、归一化函数以及GELU 激活函数。其使用3×3 大小的卷积核,步幅为1,填充为1。编码器中的卷积层使用具有池化作用的2×2 最大池化层。在每一次池化后,图像尺寸会变为原来的一半。在解码器中,使用双线性插值对特征图执行上采样。在UNet 网络结构中可以使用双线性插值来模拟转置卷积的操作,提供更多可学习的参数。
1.4 Shift MLP
虽然MLP-Mixer 在学习自由性方面进行了增强调整,但在局部约束方面没有提升,因此更容易导致过拟合现象,所以只有当使用具有超大规模数据量的数据集进行训练时才会展现出效果[17]。为此,本文在MLP-Mixer 结构上加入一些约束条件,以帮助模型在中小规模数据集上取得更好的训练结果。
在MLP 模块的移动过程中,本文在数据集标记之前,首先按照轴向移动卷积层产生的特征,使得MLP 仅关注由卷积层提取出的某些特征。与axial-attention 类似,一个MLP 模块有两个shiftMLP 层,一层沿着图像宽度移动,一层沿着图像高度移动。本文将特征拆分为h 个不同的分区,并根据指定的轴将其移动j 个位置,从而有助于创建随机窗口。
1.5 MLP模块
在MLP 模块(见图3)中,首先对输入特征进行移位操作,并将其送入标记模块。将特征切分为大小3×3、通道为E 的不同patch,并将这些patch 传递给第一层MLP。第一层MLP 对其按宽度进行映射,之后通过一个深度卷积层。使用深度卷积层有助于对MLP 提取出特征的位置进行信息编码,而且深度卷积层使用的参数较少,提高了效率。然后通过一个GELU 激活层。与常用的RELU 激活函数相比,GELU 有助于加速模型收敛。最近的大多数架构,例如VIT 和BERT 都成功使用GELU 函数并取得了很好的效果。通过GELU 后,再通过另一个MLP 层对特征进行高度上的映射。最后应用层归一化将输出特征传递到下一个块。

Fig.3 MLP module图3 MLP模块
1.6 Attention模块
在跳跃连接过程中通过在通道维度添加注意力机制,从而过滤无关信息,并提取具有辨别力的特征。Attention模块如图4 所示,通过卷积操作对输入特征xg和xl进行相加得到特征f,对f的每个通道使用全局平均池化(Global Average Pooling,GAP)得到1×1×C 的向量,之后通过一维卷积实现不需要降维的局部通道交互方法,该方法只涉及少量参数。
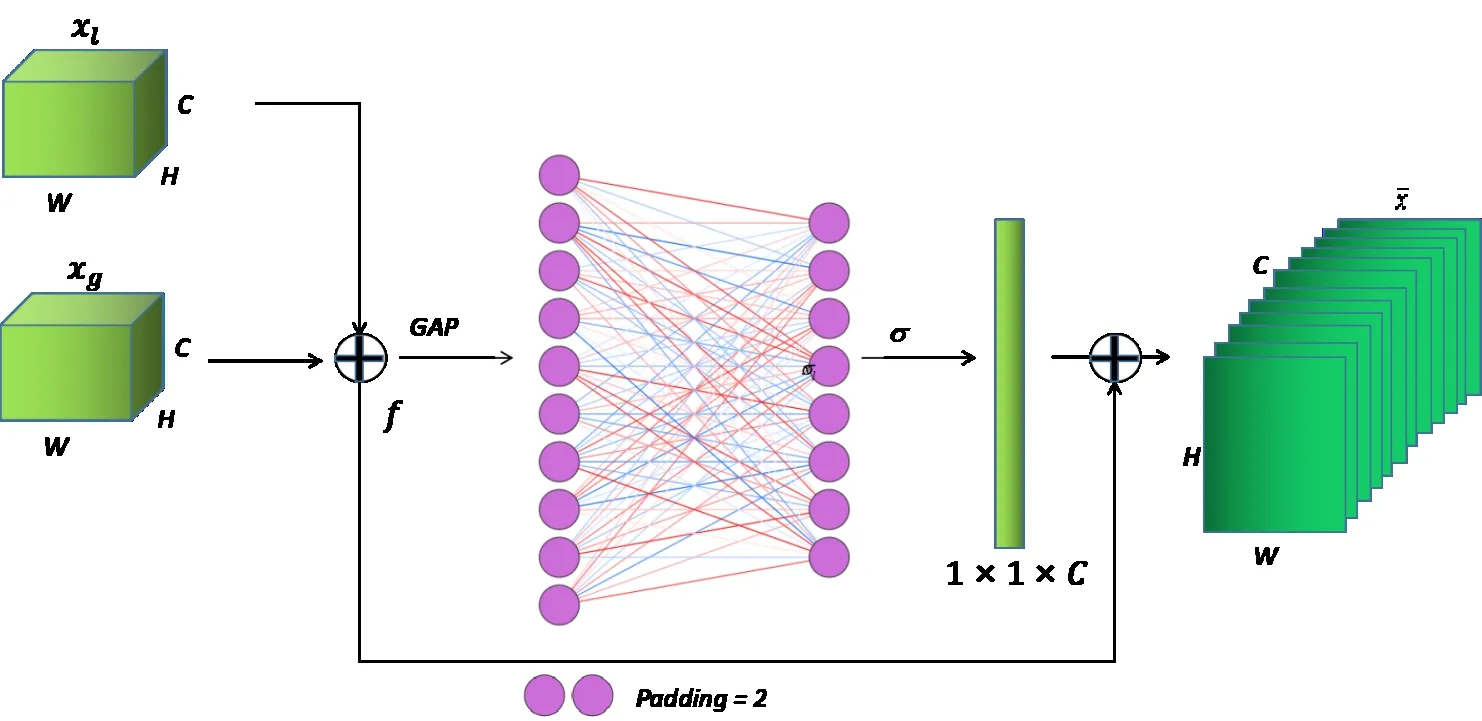
Fig.4 Attention module图4 Attention模块
根据式(1)选择一维卷积的卷积核,通过Sigmoid 函数生成每个通道的权重,最后将产生的通道权重加权到原特征f上得到新特征。
其中,Conv1 为一维卷积,k为一维卷积核大小,y为通道特征,C为通道数,λ和b 为超参数,ω为通道权重,σ为Sigmoid函数。
2 实验与分析
2.1 数据集
实验数据来自武汉大学季顺平团队基于卫星遥感影像制作并发布的WHU satellitedatasetⅠ数据集和WHU satellitedatasetⅡ数据集(数据集Ⅱ)[25]。数据集Ⅰ共有204 张512×512 遥感影像和对应的标签图像,包括来自ZY 3 号、IKONOS、Worldview 系列卫星的不同传感器与空间分辨率(0.3~2.3m)的影像,涵盖了欧洲、中国、南北美洲以及非洲的不同城市区域,能对建筑物提取算法的鲁棒性进行有效检验。数据集Ⅰ的部分示例如图5 所示。为增加样本数量,本文首先将原始数据集影像裁剪为256×256 大小的子图集,然后对子图集进行旋转、沿轴镜像处理、均值滤波、椒盐噪声增强以及高斯噪声增强处理,共得到20 094 张影像。最后将处理后的数据集按照8:1:1的比例划分成训练集、验证集与测试集,影像数量分别为1 606、2 009、2 009张。其中,训练集用于拟合模型,验证集用于调试超参数以及监控模型是否发生拟合,测试集用于最终的模型泛化能力评估。数据集Ⅱ由17 388张512×512的遥感影像与对应标签组成,包括6 个响铃的卫星图像,覆盖东亚860 km2,地面分辨率为0.45 m。数据集Ⅱ的部分示例如图6 所示。该测试区主要用于评估和开发深度学习方法,其中13 662张图像用于训练,其余3 726张用于测试。

Fig.5 Example of partial satellite image data of data setⅠ图5 数据集Ⅰ部分卫星影像数据示例

Fig.6 Example of partial satellite image data of data set Ⅱ图6 数据集Ⅱ部分卫星影像数据示例
2.2 实验环境与参数设置
本文的实验环境如表1 所示。根据实验环境、采用方法、数据集规模及反复多次的实验结果,设置数据集Ⅰ和数据集Ⅱ的batchsize 为16,共训练170 个epoch;使用Adam优化器,设置动量为0.9;使用余弦退火方法调整学习率,设置最小值为0.000 01,最大值为0.000 1。

Table 1 Experimental environment configuration表1 实验环境配置
本文所用到的网络模型均使用二元交叉熵(BCE)和Dice 系数结合的综合损失进行训练,预测值与目标y之间的损失L可表示为:
其中,二值交叉熵损失LBCE的计算公式为:
其中,N为批处理大小,i为对应的索引,y为样本真值为网络的预测值。
Dice 系数损失在类别不平衡问题上表现优异,而在一般的遥感图像中,建筑物的像素占比较少,所以可将遥感建筑物提取归为不平衡问题。Dice 系数损失的表达式为:
其中,G 为标签真值,Y 为网络最终输出的标签,N 和i分别为批处理大小及对应的索引。
2.3 实验性能比较
将本文方法与最近广泛使用的分割框架进行对比,选择了较为经典的UNet[3]、UNet++[4]和SegNet[23]等使用卷积神经网络的模型进行了比较。使用GFLOPs 来衡量计算复杂度,GFLOPs 表示每秒10 亿次的浮点运算数,理论上该数值越高越好。本文首先将参数量、计算复杂性以及运行时间等方面属性与其他模型进行比较,结果如表2所示。

Table 2 Parameters,average training time and GFLOPs of different network models表2 不同网络模型参数、平均训练时间以及GFLOPs
由表2 可知,与UNet、UNet++、SegNet 相比,本文方法的每秒浮点数最少,训练时间和计算复杂度最小,其参数量仅为1.471 93 M。
不同模型参数、平均运行时间以及计算复杂度减少百分比如表3所示。不同模型的Loss曲线如图7所示。
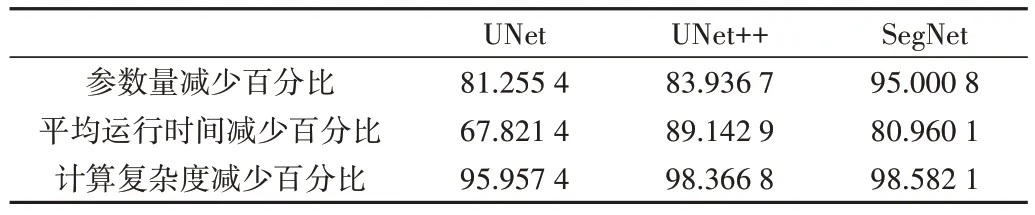
Table 3 Parameters,average running time and calculation complexity reduction percentage of different models表3 不同模型参数、平均运行时间以及计算复杂度减少百分比%
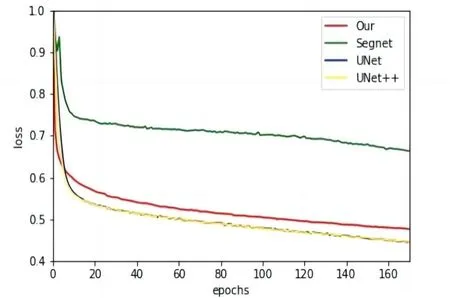
Fig.7 Loss curves for different models图7 不同模型的Loss曲线
从图7 可以看出,3 种网络随着迭代次数的增加,损失值不断减小,其中本文方法最快进入收敛状态。
本文使用交并比(Intersection over Union,IoU)对实验精度进行评价,计算公式为:
其中,TP 表示实际为正样本且预测出结果也为正样本的样本数目;FP 表示实际为负样本但预测出结果为正样本的样本数;FN 表示实际为正样本但预测出结果为负样本的样本数。分别提取数据集Ⅰ测试集遥感影像中的建筑物,选取武汉、台湾、洛杉矶、渥太华以及开罗5 个地区进行精度评价。不同地区的IoU 值如表4所示。
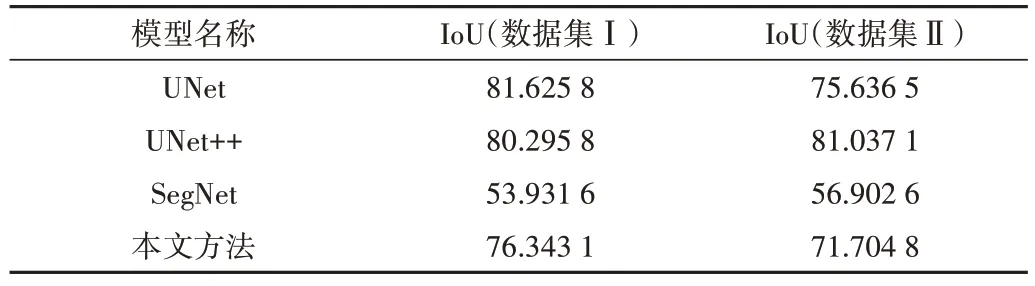
Table 4 IoU values for different regions表4 不同地区IoU值%
数据集Ⅰ提取分割结果如图8 所示,本文方法在尽可能减少损失IoU 的情况下,具有较好的分割效果。数据集Ⅱ有17 388 张遥感图像,由于可用作训练的图像较多,本文方法在数据量较多时可以有效提取不同的局部信息,并且能达到较高精度。数据集Ⅱ提取分割结果如图9所示。

Fig.8 Extraction and segmentation results of dataset Ⅰ图8 数据集Ⅰ提取分割结果

Fig.9 Extraction and segmentation results of dataset Ⅱ图9 数据集Ⅱ提取分割结果
2.4 消融实验
为了验证本文方法的有效性,将改变注意力模块和特征图输入大小,进行消融实验。
在注意力模块的消融实验中,使用数据集Ⅰ作为训练数据集,将Iou 与平均训练时间作为评价指标。训练过程使用同一实验环境,参数设置相同,研究注意力模块对实验结果的影响。以加入Attention 模块的网络作为Baseline,消融实验在数据集Ⅰ上的评价结果如表5所示。

Table 5 Evaluation results of ablation experiment on data set Ⅰ表5 消融实验在数据集Ⅰ上的评价结果
从表5 中可以看出,在没有Attention 模块的网络上,其Iou 仅为74.630 1%。在引入了Attention 模块后,Iou 指标提高了1.731%。从评价指标中可以看出,Attention 模块的引入可较好地提升遥感图像分割精度。同时,对比两种网络的参数量,Attention 模块的参数量仅增加了0.000 01 M。
在特征图输入大小的消融实验中,以Iou 和平均训练时间作为评价指标,以数据集Ⅰ作为训练集,数据集中的原始图像大小为512 × 512,采用不同的切分比率K 对原始图像进行均等切分(K 取值为1、4、16、64),实验结果如表6 所示。从表中可以看出,当切分比率为16、输入图像大小为128 × 128 时,Iou 的精度最高。这是因为当输入图像过大时,图像中存在很多噪声点,噪声点对模型产生干扰,导致模型没有学到有用的特征。而当输入图像过小时,像素之间的关联性会降低,最终影响分割精度。
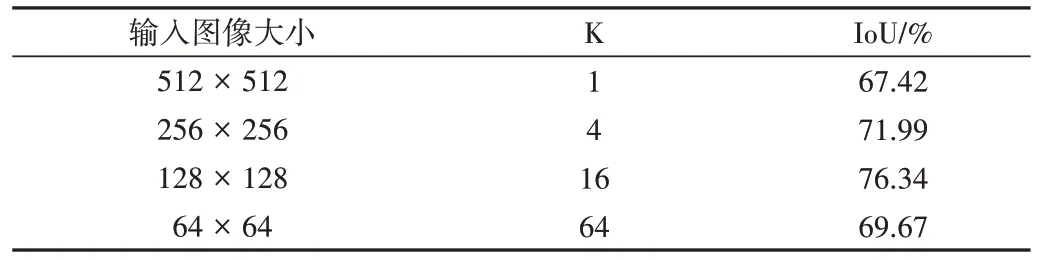
Table 6 Experimental results of different cutting ratios on data set Ⅰ表6 不同切分比率在数据集Ⅰ上的实验结果
3 结语
本文针对现有遥感影像语义分割方法的不足,提出一种新的深度网络架构用于遥感图像分割。该方法采用一种局域卷积模块与MLP 模块相结合的架构。本文提出了一种带有移位的MLP 模块,降低了计算的复杂性,并减少了模型参数。在多个数据集上验证了本文方法,并且与UNet、UNet++、SegNet 模型进行了对比实验。结果表明,本文方法在尽可能保留IoU 均值的同时,训练速度更快,复杂性更低,参数量更少,并且能够实现较好的分割效果。
