基于时空注意力机制的在线教育专注度检测
2024-02-21周卓沂黄伟聪郭梓健
梁 艳,周卓沂,黄伟聪,郭梓健
(华南师范大学 软件学院,广东 广州 510006)
0 引言
近年来,随着互联网的快速发展,在线教育发展迅速,越来越多的学校以及培训机构在传统线下教学模式基础上加入在线教育这一新的教学模式。线上学习虽然方便,但学生的学习效果往往并不理想,究其原因是线上授课老师难以及时获悉学习者的学习状态并及时进行教学调整,学习者也容易因此降低学习专注程度,从而影响学习效率。长此以往,学习者也会因为学习效率不高、专注度低下而产生一定的厌学情绪,导致消极学习甚至辍学的情况发生。调查数据表明,大规模在线教育平台MOOC 的使用者辍学率高达80%~95%[1]。因此,设计一种自动的专注度检测方法对在线教育行业具有重要意义,有助于提升学习者的学习效率,辅助教师更好地完成教书育人工作,从而更好地助力在线教育的高质量发展。
考虑到利用脑电信号、心率等生理信号进行专注度检测需要使用穿戴式设备,影响学习者的学习状态,所以本文采用更为合理的计算机视觉技术实现非接触式检测。此外,考虑到人脸表情与专注程度具有密切联系,因此利用人脸特征设计一种基于时空注意力机制的方法完成在线教育场景下的专注度检测任务。
1 相关工作
早期基于计算机视觉的专注度检测研究主要采用传统机器学习方法。例如,Chun 等[2]利用Haar-like 特征检测和AdaBoost 算法学习面部特征,运用光流技术和模板匹配方法对面部特征进行跟踪;段巨力[3]根据目标人脸两眼与鼻子的位置构造一个三角形,然后利用这个三角形进行几何运算,计算出学习者的侧脸程度、低(抬)头、眼睛张合度并进行专注度判断;钟马驰等[4]选取眼睛、嘴巴等关键部位进行判断,得到头部姿态、疲劳程度等评估因素,并通过层次分析法确定这几个因素对应的权重,最后统计分析得到一个量化的专注度分数;Thomas 等[5]以通过OpenFace工具包获取得到的目标人脸的动作单元(Action Unit,AU)、头部姿态和眼睛注视方向作为特征,以将径向基函数(Radial Basis Function,RBF)作为核函数的支持向量机(Support Vector Machine,SVM)作为分类器,判断目标对象的专注情况。传统机器学习方法需要手工提取特征,部分区域变化不明显会导致特征冗余情况发生,并且大多方法均运用在特定约束条件下,鲁棒性和泛化性较差。
随着深度学习技术的快速发展,越来越多的专家学者将深度学习方法运用于专注度检测工作中。考虑到表情与专注度的相关性,Nezami 等[6]提出将表情识别任务模型迁移到专注度检测中,在自采数据集中获得72.38%的识别精度,但该模型没有在公开数据集上进行验证,实验结果缺乏说服力;沈利迪[7]重新设置卷积层与全连接层的数量,构造一个结构类似于AlexNet 的卷积神经网络(Convolutional Neural Network,CNN)模型,用以提升专注度识别的速率和精度;Tang 等[8]则直接将全连接层从整个CNN 网络中移除,达到快速识别的效果;孙绍涵等[9]利用改进后的YOLOv4网络识别学生课堂行为状态。
上述基于深度学习的方法主要针对单个图像帧进行特征提取。然而,一段视频前后连续的图像帧之间往往是存在一定联系的,因此近年来越来越多的学者研究如何对时序信息进行建模。例如,章文松[10]利用多尺度特征提取模型MS-ResNet-50 提取每帧的特征向量,并利用基于自注意力机制的分类模块提取时域特征,完成专注度检测工作;Werlang 等[11]利用C3D 网络在视频数据上进行训练,并完成二分类任务,但输出结果只包含专注、不专注2 种情况,不能细粒度地表现学习者的学习状态;Liao 等[12]提出深度时空网络(Deep Facial Spatio-Temporal Network,DFSTN)用于提取人脸序列的时空信息,该网络在DAiSEE[13]数据集的四分类任务中获得58.84%的准确率;陆玉波等[14]采用SE-ResNet-50[15]以及OpenFace 分别提取面部特征和行为特征,并利用时序卷积网络(Temporal Convolutional Network,TCN)[16]处理时序信息,在DAiSEE 数据集上的四分类准确率为61.4%。
现有方法在很大程度上促进了在线教育环境下专注度检测的研究,但部分网络模型在训练时并没有很好地提取到对分类任务更为重要的特征,并且大部分深度学习方法采用较深的网络结构,不利于在实际应用中推广。针对上述问题,本文采用轻量的ResNet18[17]作为主干网络提取空间特征,并在网络中加入空间注意力(Shuffle Attention,SA)[18]机制强化对该任务更为重要的人脸区域特征,同时利用带有时序注意力(Global Attention,GA)[19]的长短记忆周期网络(Long Short-Term Memory,LSTM)完成时序特征的提取,最后利用Softmax 函数对所得到的特征信息进行决策,得到最终的预测结果。
2 算法设计
本文方法的整体结构如图1 所示。首先对输入的序列帧进行数据预处理,获取每帧的人脸区域,然后分别利用ResNet18 和LSTM 网络提取空间特征和时序特征;同时在2 个特征提取模块中嵌入相关的注意力机制,辅助2 个模块更好地完成特征提取任务;随后利用两层全连接层将特征向量映射到4 种专注度类别,最终实现专注度的分类。
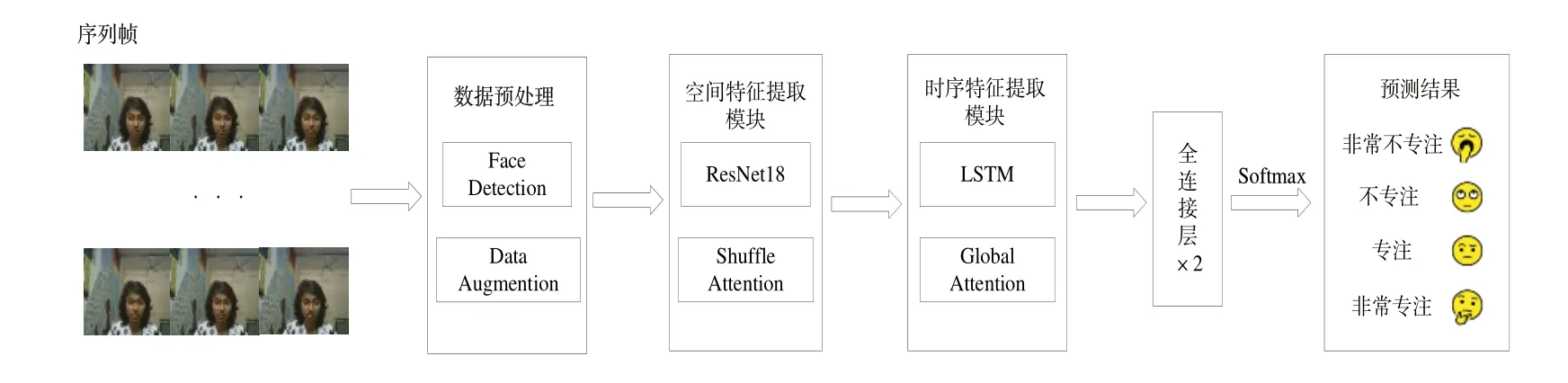
Fig.1 General structure of the proposed method图1 本文方法的整体结构
2.1 数据预处理
数据预处理过程如图2 所示。首先利用OpenCV 对学习者视频进行帧提取,获得多张连续的图像帧。这些连续的图像帧一般含有较多背景信息,不仅会增加网络的计算量,而且容易影响网络对人脸特征的提取,所以选用多任务卷积网络(Multi-task Convolutional Neural Network,MTCNN)[20]对每帧图像进行人脸检测,从原始图像帧中获取只含人脸部分的区域。MTCNN 由3 个级联的轻量级CNN PNet、RNet 和Onet 构成,其中Pnet 对图像金字塔完成特征的初步提取以及确定候选边框,Rnet 筛选经过Pnet 得到的候选边框,Onet 在继续筛选候选框的同时完成人脸关键点的定位。利用MTCNN 网络可获得大小为3×224×224的人脸图像。

Fig.2 Data preprocessing flow图2 数据预处理流程
为了增加样本数量和多样性,使用RandAugment 方法[21]对训练数据进行数据增强。该方法将最为通用的K(这里为14)种数据增强方法列举出来,并结合模型与数据集的规模,随机从这K 种数据增强操作中选用N 种进行组合,共有KN种组合方式完成对输入数据的增强处理。每种增强方式包含一个增强变形程度参数M,即在KN种组合方式情况下每种增强程度为M。通过RandAugment 数据增强,在不改变图像大小的同时随机在部分像素点位置上进行数值变化以增加数据样本的多样性,大大提高了网络模型的泛化能力。
2.2 空间特征提取模块
空间特征提取模块采用融合SA 机制的ResNet18 网络,具体层次结构如图3 所示(此处未标出残差箭头,残差连接可参考文献[17])。ResNet18 是残差网络(Residual Network,ResNet)系列网络中最为轻量级的CNN 主干网络,主要由4 个卷积层构成,每个卷积层又包含2 个卷积块。输入的特征图在每个卷积块中分别进行卷积处理、归一化处理以及激活函数的非线性映射处理,其中卷积处理选用的卷积核大小为3×3,步长分别为2 和1,零填充为1。输出特征的尺寸o可根据如式(1)所示:
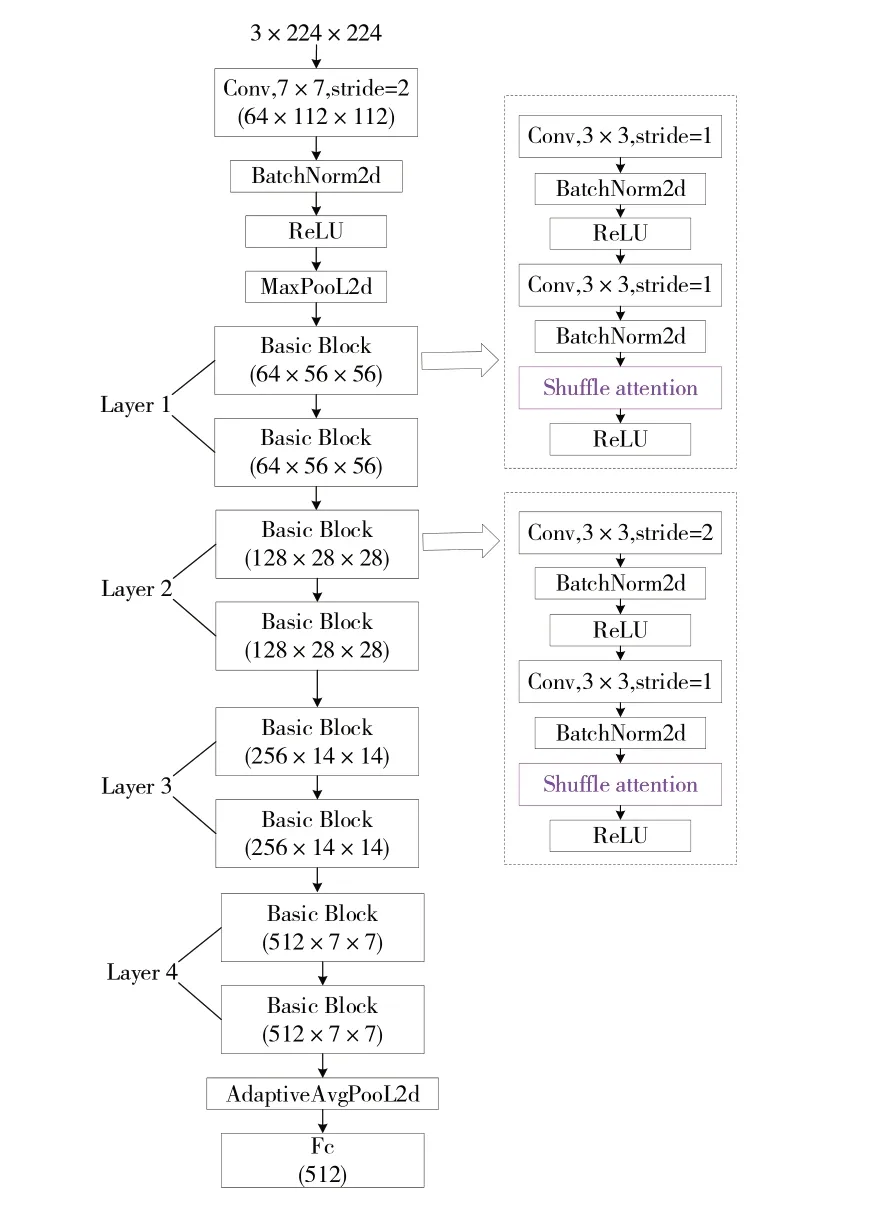
Fig.3 Structure of spatial feature extraction module图3 空间特征提取模块结构
式中:i为输入特征的尺寸,p为零填充,k为卷积核大小,s为卷积步长。
考虑到ResNet 中所有卷积块对于输入特征图的每一个像素点均进行相同的卷积运算,而在实际情况下特征图的不同区域对于任务决策的重要性是不同的,因此在每个卷积块的归一化处理后加入SA 进行优化,以提升ResNet18 在空间维度的特征提取能力,区分出不同特征区域对任务的重要程度。
SA 机制采用双分支并行的结构,一条分支处理通道维度上的特征依赖,另一条分支处理空间维度上的特征依赖,其具体结构可参见文献[18]。经过融合Shuffle Attention 机制的ResNet18 网络后,原始输入序列数据由B×T×3×224×224(B为BatchSize,批量大小;T为Time,序列帧数量)变为B×T×512的特征向量。
2.3 时序特征提取模块
时序特征提取模块由加入GA 机制的LSTM 网络构成,具体结构如图4 所示。将空间特征提取模块输出的特征向量(即上述B×T×512 的特征向量)输送至LSTM 网络中进行时序特征提取,并在LSTM 后面加入一个GA 来对特征向量间全局时序信息进行建模。
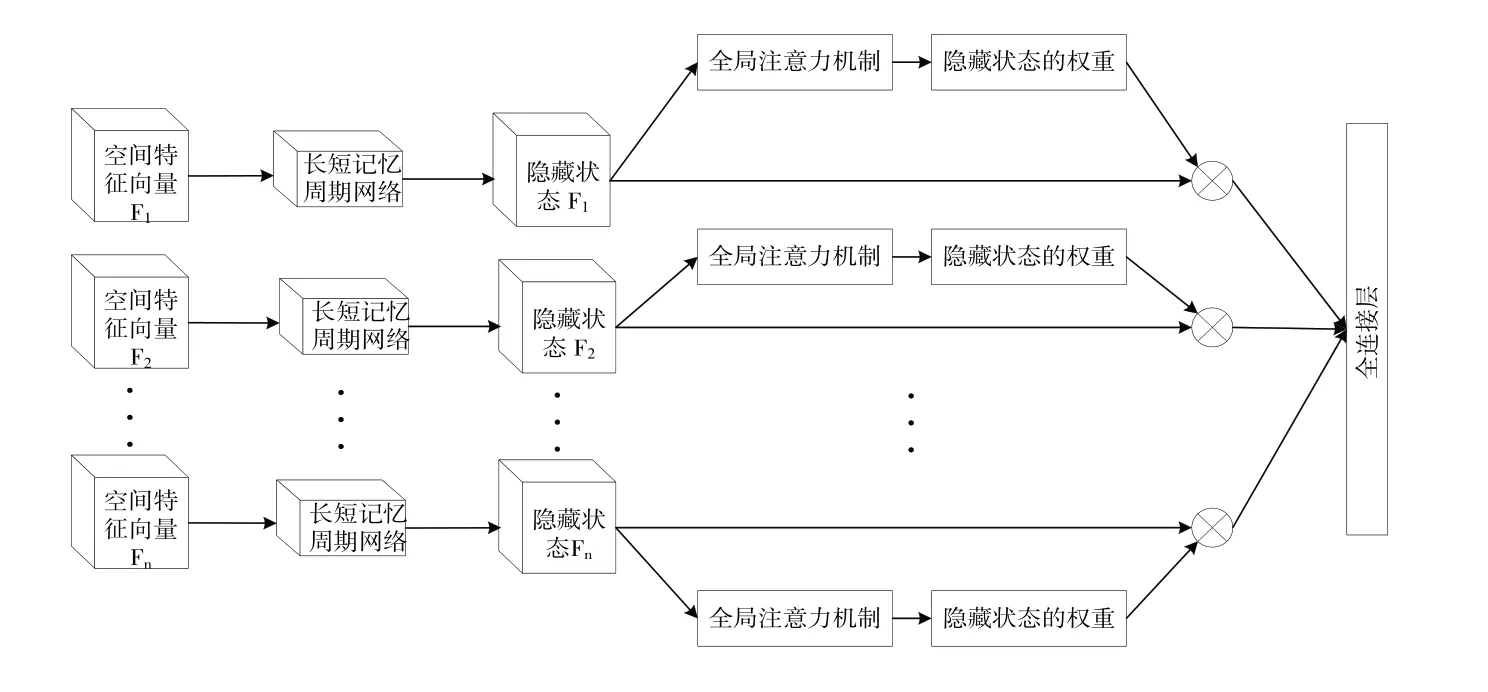
Fig.4 Time series feature extraction model图4 时序特征提取模型
传统的LSTM 由遗忘门、记忆门、输出门构成,并在输出门位置输出所有隐藏状态。利用LSTM 对时序信息建模的操作为取输出中的最后一个隐藏状态进行预测判断,但在部分情况下序列帧中可能存在一些不利于任务决策的干扰帧,如果仅根据最后一个隐藏状态进行判断,得到的结果可能并不准确。针对该问题,在输出的所有隐藏状态中将最后一个隐藏状态hs与所有隐藏状态ht一起输入到一个自定义Score 函数中进行计算。Score 函数通过一个可以训练的矩阵Ws辅助分析hs与所有隐藏状态ht之间的相关性,弱化干扰帧对时序信息建模的影响,使得LSTM 对输入特征向量的处理更具有全局性。Score 函数的定义如式(2)所示:
通过softmax 函数对Score 函数得到的所有输出进行归一化,获得每一个隐藏状态对应的重要权重系数αt,计算过程如式(3)所示:
式中:n表示隐藏状态的序号。
将归一化后的所有重要权重系数与其对应的隐藏状态进行加权求和,得到最终的状态hf作为优化后的LSTM输出。hf特征向量大小为B×256,其计算公式如式(4)所示:
3 实验结果与分析
3.1 实验环境及参数设置
本实验在Linux 系统下的PyTorch 1.7.1 版本框架中进行,显卡为24G 显存大小的GeForce RTX 3090。实验的损失函数选用交叉熵损失函数,学习率大小设定为0.001,批量大小设为32,选用16 张连续的时序帧代表每一个样本视频。
3.2 实验数据集
选用公开的在线教育情感数据集DAiSEE[13]以及自采的在线学习视频数据集(Online Learning Video,OLV)作为实验数据集。
DAiSEE 是目前专注度检测领域最大的公开数据集,一共包含9 068 个时长为10s 的印度学生在线学习时采集的视频样本。在该数据集中参与视频录制的人数总共为112 人,其中女性为32 人,男性为80 人,录制环境分别为宿舍、教室以及图书馆等室内场景。根据参与录制人员的学习专注程度,该数据集将专注度划分为非常不专注、不专注、专注以及非常专注4 个等级。在数据集的9 068 个视频中有8 925 个视频具有标签。经过人脸检测处理后,保留8 832 个具有标签的视频样本,为了进一步扩充数据,选择不同起始帧,按相同间隔对单个视频样本进行重采样,最终获得44 160 个由16 张图像帧构成的视频样本用于实验。
为了验证所提出网络模型的泛化性,利用手机录制17名20~25 岁在校大学生(男性11 人,女性6 人)在线学习时的视频。每个学生录制4 个视频,每个视频时长10s。视频录制中的刺激材料选自中国慕课大学中的在线课程,录制时手机的相机参数设置为1 920×1 080 像素,帧率为30帧/s。为了使自采数据集更具普遍性与科学性,采样环境选择学生宿舍、实验室等多种场景。自采数据集的专注度划分等级与DAiSEE 一致。按照DAiSEE 数据集的处理方式对自采数据集进行人脸检测筛选和重采样,最终获得670个由16张图像帧构成的视频样本。
3.3 实验评价指标
考虑到Gupta 等[13]在公开DAiSEE 数据集中选择了Top-1 准确率作为分类模型的评价指标,为了公平比较,本文采用相同的评价指标。Top-1 准确率是指在预测结果中选择概率值最大那个类别作为模型的预测值,并将该预测值与真实类别进行校验,如果两者相同,则预测正确,否则判定为预测失败,具体计算公式如式(5)所示:
式中:TP表示真正例,FP表示假正例。
3.4 消融实验
为了验证采用的空间注意力机制与时间注意力机制的有效性,本文在DAiSEE 数据集中进行消融实验,结果如表1 所示。从表中数据可知,当主干网络不加入任何注意力机制时,模型的准确率只有55.67%。在这基础上加入时序注意力机制GA 可以帮助网络更好地利用视频数据的时序信息进行建模,最终将模型的准确率提升至57.06%。而在时序注意力机制的基础上再增加SA,网络模型的预测结果可以达到60.27%的准确率,这说明空间维度上重要特征信息的提取对模型的决策具有较大帮助,SA 中空间注意力分支和通道注意力分支可以较好地辅助网络关注到重要特征信息。

Table 1 Results of ablation experiments on the DAiSEE dataset表1 在DAiSEE数据集上的消融实验结果
在消融实验中,将Shuffle Attention 与2 种经典的空间注意力机制Convolutional Block Attention Module(CBAM)[22]和Squeeze-and-Excitation(SE)[15]进行比较。CBAM 注意力机制以平均池化和最大池化为主要计算操作,由一个通道注意力模块和一个空间注意力模块串行构成;SE 注意力机制则是利用全局平均池化操作实现。从实验结果可以看到,3 种空间注意力机制的加入均提升了识别准确率,说明空间注意力机制有助于提升网络模型性能。其中,SA 机制效果最佳,这得益于SA 较好地将通道维度与空间维度的特征依赖综合起来进行分析,并且避免了为降低计算开销而采用多个全连接进行特征降维的操作,保证输入的特征信息能被充分利用。
为了更直观地说明在ResNet18 网络中加入SA 机制带来的帮助,利用GradCAM[23]方法对分别含有SA、CBAM 和SE 注意力机制的网络进行图像帧热力图的可视化,如图5所示。根据热力图对比可知,相较于另外2 种空间注意力机制,本文使用的SA 可以使网络关注到更大面积的人脸区域,覆盖人眼、鼻子以及嘴巴等特征区域,这些区域对专注度的预测任务尤为重要。值得注意的是,从图5 第三行可以看到,当目标对象发生较大姿态变化时,本文方法也能较好地定位到对任务有帮助的关键区域,这主要得益于SA 在通道和空间维度的特征筛选,使网络模型的性能得到保证。
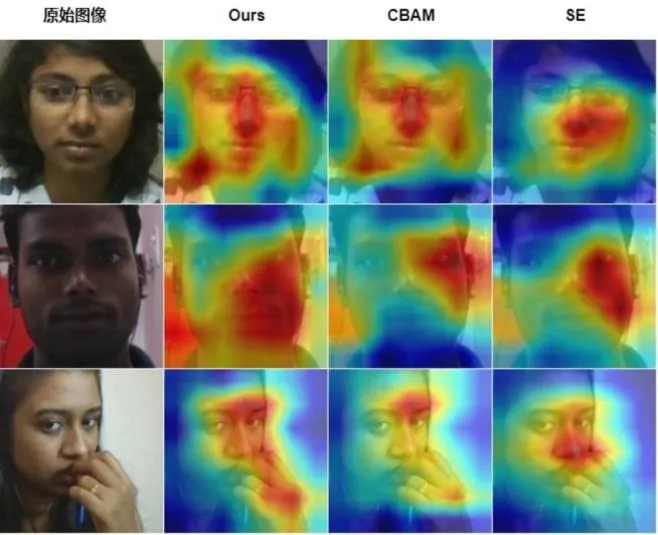
Fig.5 Visual heatmaps under different attention mechanisms图5 不同注意力机制下的可视化热力图
为了验证算法的泛化性,在自采的在线学习视频数据集OLV 中进行消融实验,结果如表2 所示。从表2 可知,该方法在OLV 数据集上也取得了很好的效果,准确率达到65.00%,且优于其他2 种空间注意力机制方法,证明了其对专注度检测的有效性。值得注意的是,在OLV 数据集上获得的准确率高于DAiSEE 数据集,这可能是由于DAiSEE数据集中存在较为严重的数据类别不平衡问题,而本实验在采集OLV 的数据时尽量避免了这个问题,因此OLV 数据集的类别分布比较均匀,对模型学习起到了积极作用。

Table 2 Results of ablation experiments on the OLV dataset表2 在OLV数据集上的消融实验结果
3.5 算法比较
在DAiSEE 数据集上进行比较,结果如表3 所示。从表中数据可知,本文方法明显优于大部分现有方法,说明该方法具有更高的精度。

Table 3 Comparison with other methods on the DAiSEE dataset表3 在DAiSEE数据集上与其他方法的比较
值得注意的是,本文方法准确率略低于文献[14]中的多模态方法,原因可能是该方法选用50 层的ResNet 作为主干网络,并且结合面部外观、眨眼频率等多模态特征。然而,采用较大深度的网络模型以及使用多模态特征时会增加计算开销,不利于在线教育场景的实际应用。
为了进一步说明这个问题,对2 种方法进行推理时间测试。其中,文献[14]的方法推理时间为(88.13±2.86)ms,而本文方法则只需(48.06±0.05)ms,这些数据证明本文方法在时间复杂度上占有优势。因此,本文方法更适合在数据量大、场景复杂多变的在线学习环境中使用。
4 结语
本文针对在线教育环境下教师难以获悉学习者专注度的问题,提出了一种基于时空注意力机制的专注度检测方法。该方法以ResNet18 和LSTM 为主干网络,加入SA 提高网络对空间特征的提取能力,获得更为重要的空间特征信息,并在时序特征提取模块中加入GA,使得网络可以结合所有时序帧的信息综合地进行决策评估。为了证明方法的有效性,自建一个在线教育环境下的学习视频数据集OLV,并将提出的方法分别在公开数据集DAiSEE 以及自采数据集OLV 上进行测试。实验结果证明,本文方法在性能方面优于大多数现有方法。由于选用的是较为轻便的主干网络,该方法具有较低的时间开销,适用于实际的在线学习场景。在未来的工作中,考虑到3D 卷积网络对视频数据具有非常低的时间开销,将尝试对3D 卷积网络结构进行优化并用于专注度检测,在保证更低时间开销的同时获得更好的检测结果。此外,由于目前采集的OLV 数据集人数有限,视频数量较少,后续将继续邀请更多学生完成录制,增加数据集的样本数量,更好地支持对模型的训练与测试。
