基于混合注意力机制与C2f的行人检测算法研究
2024-02-21王志新王如刚王媛媛郭乃宏
王志新,王如刚,王媛媛,周 锋,郭乃宏
(1.盐城工学院 信息工程学院,江苏 盐城 224051;2.盐城雄鹰精密机械有限公司,江苏 盐城 224006)
0 引言
行人检测技术已成为目标检测领域的一个重要组成部分,它不仅有助于自动驾驶,还可以为智慧城市提供支持,因此受到了学术界的高度重视和广泛关注[1-2]。行人是社会场景中最为重要的部分,随着无人驾驶不断发展和智慧城市加快构建,其对行人检测的要求也有了进一步提高[3-5]。同时,因为行人的尺度变换、遮挡、密集等问题,行人检测精度仍有提升需求。此外,行人检测效率也是学术界高度关注的一个方面。
针对行人检测时行人目标会出现漏检、误检等问题,研究人员提出各种方法以解决这一问题。通常做法是在特征提取阶段加以改进,既可以在Backbone 层利用浅层网络和深层网络的交互帮助浅层和深层网络分别获取细粒度特征和语义信息,进而提高特征提取能力,也可以在Neck 层通过融合不同层级的特征图提高表征能力。2017年,Lin 等[6]设计出特征金字塔网络,其采用自上而下的方式实现浅层和深层等各不同层次特征图之间的信息流动,能够确保每一层特征图都有相应的语义信息和合适的分辨率。2018 年,Hu 等[7]为了提高检测精度,通过引入注意力机制获取周边信息以帮助网络识别检测目标。2019 年,侯帅鹏等[8]开发出一种新型的Top-Down 融合单元,它能够实现高层语义信息与低层细节信息的融合,从而提高了小尺度行人的检测精度。此外,该技术还利用Mobile-NetV2 及深度可分离卷积,极大增强了识别的及时性。2020 年,王丹峰等[9]采用深度可分离卷积和Inception 网络结构,将其融入到YOLOv3,实现检测精确度和速率提升。2021 年,冯宇平等[10]通过融合通道注意力机制,引导网络关注行人,实现检测精度提升。2021 年,Yan 等[11]将SE Block 模块嵌入至YOLOv5的Backbone 中,以突出特征图中的重要特征,抑制不相关特征,使mAP 提升1.44%,从而提高网络检测性能。2021 年,许虞俊等[12]将ECA 和Ghost 技术引入YOLONano,以减小模型计算复杂度,同时针对原有算法检测框定位出错的问题,采取D-IoU loss 替换原有损失函数,从而实现轻量化和模型性能提升。2023 年,陈勇等[13]提出融合多个注意力机制,实现了小尺度行人检测精度提升。
从现有研究成果看,通过融合注意力机制和不同层次特征图可以有效提升精确度,并且采用各种轻量化卷积操作和改进网络结构有效提升检测速度。但是,由于在现实场景中背景信息复杂,行人目标的像素相对不足,且因为行人目标多会受到外界影响,例如出现遮挡、阴影覆盖等状况从而导致行人检测出现漏检、误检等情况[14-15]。以上方法都未能有效利用浅层特征图中丰富的小尺度行人特征,故本文提出一种基于混合注意力机制和C2f(Client to Front)的YoloX 改进算法。通过交互浅层与深层行人特征信息,再以此进行特征增强可有效提升行人检测精度并降低漏检率,同时采用自注意力机制抑制背景信息对行人特征的干扰。此外,使用ECA 注意力机制解决因自注意力机制导致的中小尺度检测精度降低的问题,且采用C2f 模块与混合域注意力机制BAM 融合以实现行人目标检测精度和运行效率提升。
1 算法设计结构
基于YoloX 算法改进后的模型如图1 所示。该模型由4 个模块构成,特征提取模块提取浅层和深层包含不同特征信息的特征图,相较于YoloX 原有的C3 模块,C2f少了一层卷积的同时更多地使用跳层连接,可以获取更为丰富的梯度流信息;特征金字塔模块融合各层次的特征图,通过浅层和深层特征图之间的信息交互,以便利用不同特征层的特征信息,引入注意力机制和C2f模块,提取丰富的行人特征,可以有效处理因网络加深导致行人特征减少的问题;在YoloX 算法中设计一个特征增强模块,通过特征融合策略促使不同层次的特征图获取其他特征图的相同信息并引入注意力机制以增强行人特征;基于特征增强模块设计一个检测模块以完成行人目标预测,获取预测边界框。

Fig.1 Model structure图1 模型结构
1.1 特征提取模块
YoloX 的特征提取模块采用CSPDarknet 网络实现特征提取,其主要由CBS 模块、C3 模块和SPP 模块组成。首先通过Focus 模块获取没有信息丢失的特征图,然后依次通过4 个C3 模块获取不同分辨率的特征图,最后加入空间金字塔池化(Spatial Pyramid Pooling,SPP),扩大网络的感受野。本文改进之处是采用C2f 模块替换原本的C3 模块,并使用SPPF 模块扩大网络的感受野。图2 中的(a)和(b)图分别表示C3模块和C2f模块。
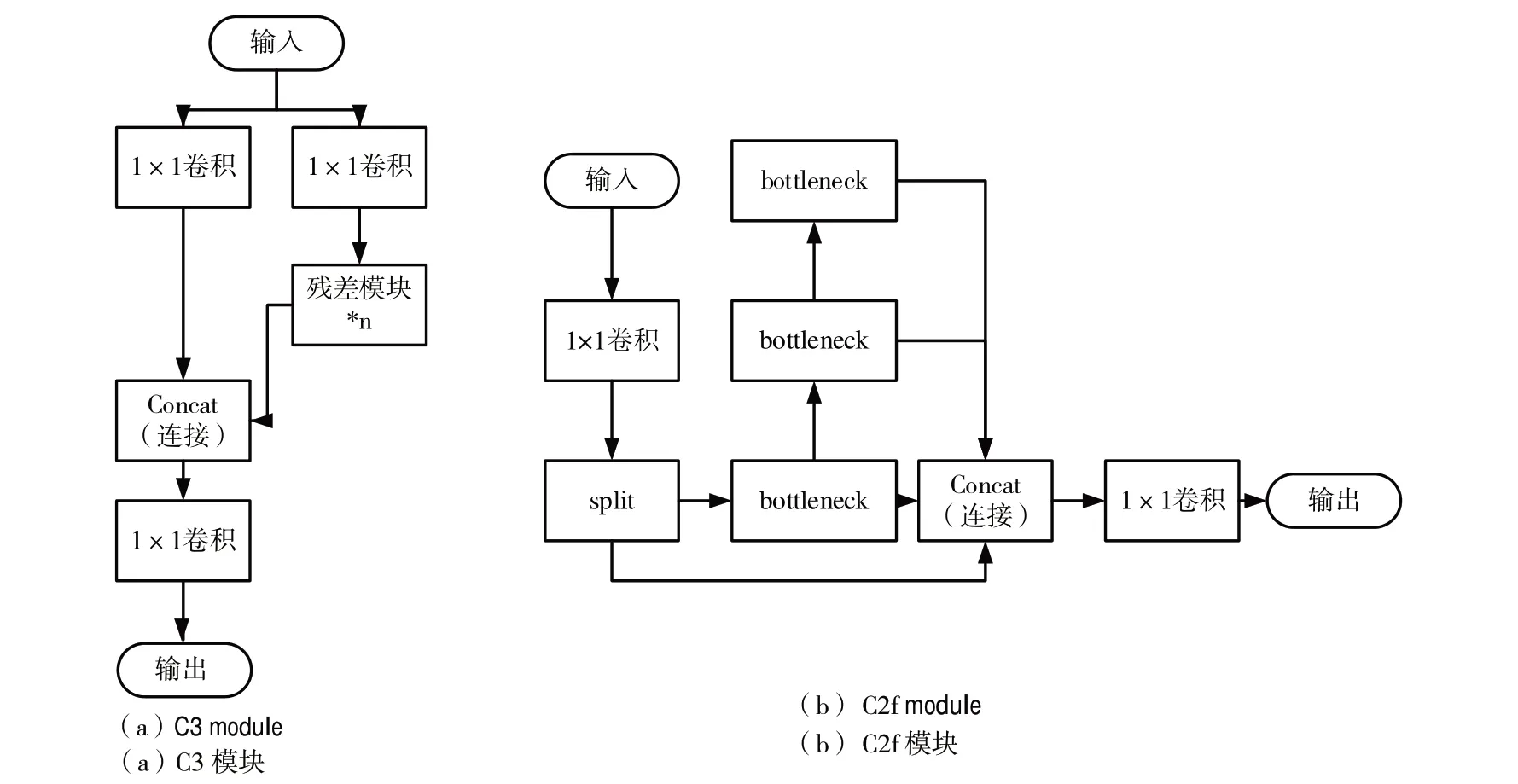
Fig.2 C3 module and C2f module图2 C3模块与C2f模块
C2f模块参考了C3 模块和ELAN(Efficient Layer Aggregation Network)的设计思想,相对于原本的C3 模块少了一层卷积,并且采用Split 进行特征分层,并使用了更多的跳层连接,以便在进行特征提取时保证轻量化并获得更为丰富的梯度流信息。相对于SPP 模块,SPPF 模块采用了多个小尺寸池化核级联,可以在扩大感受野的同时进一步提高运行速度,节省了计算成本。
1.2 特征金字塔模块
特征金字塔是通过自上而下对特征信息进行多尺度融合,由于是单向传递特征信息,故容易在特征增强过程中丢失细节信息。因此,本模块采用双向特征金字塔通过浅层和深层特征图之间的信息交互,针对浅层特征图具有的丰富细节信息和深层特征图具有的丰富语义信息这一特点,上采样深层特征层{C4}与浅层特征层融合传递丰富语义信息的同时,下采样浅层特征层{C2}与深层特征层融合以确保浅层特征层中丰富的细节信息能够向深层特征层传递。这种方法尽可能地保留了行人信息,避免丢失细节信息,一定程度上解决了信息流单向传递的问题。
通过卷积神经网络获取的行人特征拥有两个关键点:①行人特征主要留存在浅层特征图,也即{C2,C3}特征图含有相关的行人特征,虽然特征金字塔可以实现不同层次特征图之间的信息流动,但依然会抑制一定的行人特征;②行人特征不明显,特征图中包含许多背景信息,因此如何增强行人特征,抑制无用特征尤为重要。
因此,为了实现行人检测速度和精度提升,将双向特征金字塔模块中的C3 模块替换为C2f-BAM 模块。C2f-BAM 模块通过引入注意力机制可以有效地增强行人特征以提升检测效果,且由于采用了空洞卷积,故可以在不增加过多参数量的同时获取更为丰富的感受野。C2f-BAM模块如图3所示。

Fig.3 C2f-BAM module图3 C2f-BAM 模块
1.2.1 C2f-BAM模块
通过利用注意力机制,可以从特征图中提取出有价值的信息,将注意力机制应用于行人检测可以更好地突出行人特征。其中,空间注意力机制、通道注意力机制和混合域注意力机制[16-18]都具有多种优势,因而被广泛应用于各种目标检测,尤其是在行人检测中,它们的作用更加显著。此外,由于混合域注意力机制融合了多种注意力机制,兼顾了不同注意力机制的优点,因而混合域注意力机制的使用范围尤为广泛,特别是在目标检测中应用颇多。
相对于通道注意力,混合域注意力不仅仅对特征图的各通道进行了权重提取,还考虑了空间各部分的权重参数和空间部分的特征信息。常见的混合域注意力机制主要是BAM 和CBAM,二者设计思路相似,不同之处在于BAM将通道注意力与空间注意力并联,获得的权重结果按元素相加的方式进行结合,而CBAM 则依次添加通道注意力和空间注意力[20]。
C2f-BAM 模块通过C2f 模块与通道注意力模块(ACAM)和空间注意力模块(MSAM)相结合。可以通过ACAM 抑制特征图中的噪声等无用信息,并且使用MSAM保留所需的行人信息。同时,采用并行结构,进一步提升了运行速度。BAM 模块结构如图4 所示,BAM 计算表达式如式(1)—式(3)所示。
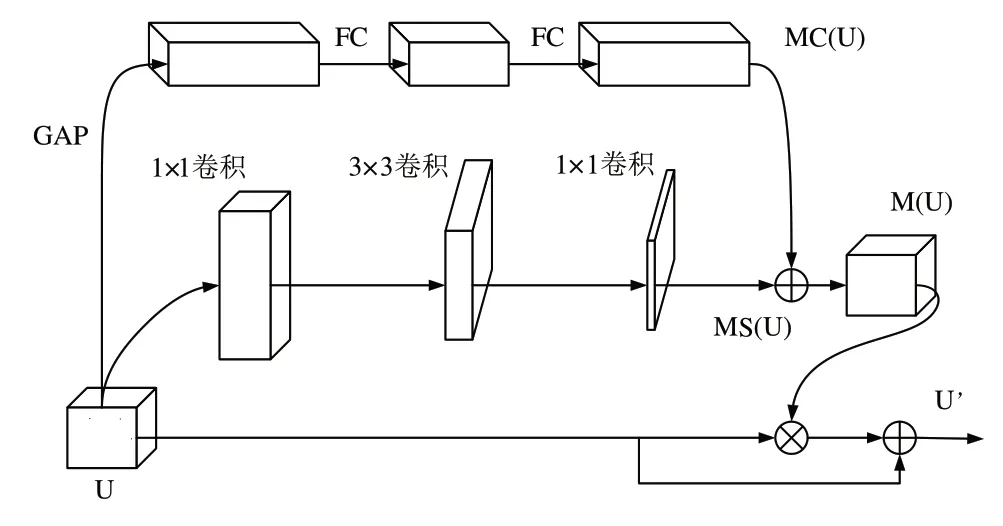
Fig.4 BAM module图4 BAM模块
输入的特征图分别使用通道注意力与空间注意力加以处理。在通道注意力中,为了聚合特征图的通道维度,采用全局平均池化;同时为了评估通道效果,使用一个多层感知(MLP),且在MLP 之后,增加BN 以调整规模和空间分支一样的输出。在空间注意力中,利用上下文信息选择性增强或者抑制特征,同时采用空洞卷积,相对于普通卷积,空洞卷积可以更有效地增大感受野。
1.3 特征增强模块
通过特征金字塔获取的3 个特征图,实现了行人特征部分增强,并抑制了背景信息等无效特征。此外,因为特征金字塔可以实现多层次特征图的交互,导致行人特征与背景信息等无用特征相交互。因此,可以通过在特征金字塔和预测网络中间插入一个特征增强模块以实现行人特征增强[21]。特征增强模块如图5 所示,首先通过融合之前获取到的不同层次的特征图,使得特征图获取相互之间的共有信息,从而突破特征金字塔的层级结构,尽可能地保留浅层特征图中的行人特征;然后,使用自注意力模块获取特征图中特征点之间的关联性,利用全局信息引导网络关注行人特征,从而实现目标特征增强并抑制噪声等无用特征的目的;再通过上采样、最大池化、卷积操作将特征图大小恢复到和原始特征图一致后,再使用ECA 模块获取不同通道的权重系数,从而引导网络关注行人目标;最后,使用3 个相同检测模块分别对实现特征增强效果的{P2'',P3'',P4''}3 个特征图进行对应目标类别、回归、位置等信息的预测。
1.3.1 特征融合
通过融合不同层次的特征图,使得各特征图可以获取其他不同分辨率的特征图中的共有信息。将获取的特征图{P2,P4}大小进行处理以便与特征图{P3}保持一致,从而实现特征融合。特征融合策略的计算表达式如式(4)所示。
其中,Fm、Fu和Conv 分别是最大池化、上采样和卷积操作,作用是调整特征金字塔输出特征图的分辨率以保持一致,并通过卷积操作调整特征图的通道数,以进行特征融合从而获取一个新的特征图。
1.3.2 自注意力机制
利用卷积神经网络进行特征提取时,采用卷积层和池化层进行特征提取并扩大感受野,从而导致提取行人特征时会忽略全局信息。自注意力模块可以通过对像素之间建立相互关系从而获得较为密集的全局信息。其模块结构如图6所示。

Fig.6 Self-attention module图6 自注意力模块
首先,使用自注意力模块将先前获取的兼具浅层特征图中丰富细节信息和深层特征图中丰富空间信息的特征图的大小建立为C×HW;接着,使用1×1 卷积对{Pm}特征图进行线性映射操作,获取g(Pm),θ(Pm),ϕ(Pm);然后,对进行矩阵相乘,从而获得特征图空间关联性矩阵;最后,对上一步获取的空间关联性矩阵进行归一化处理,再与初始的映射矩阵相乘,获取自注意力响应,其表达式为:
其中,Wϕ、Wg、Wθ分别是1×1 卷积核中的可学习参数,利用1×1 卷积实现特征图的线性映射。其计算可用式(10)表示。
其中,Wz表示1×1卷积核中的可学习参数。
1.3.3 ECA注意力机制
神经网络通常通过标注的全局信息获取行人特征,但如果行人被遮挡,且因为被遮挡部分对于预测值的计算十分重要,导致提取的特征与预测的不匹配,从而出现漏检情况。为了解决该问题,可以添加通道注意力机制,对通道权重进行重标以减缓遮挡问题对行人检测的干扰,从而确保网络关注行人目标。SENet(Squeeze-and-Excitation Networks)通道注意力机制[22]可以建立特征图中的空间相关性,但是SENet 因为采用降维操作会降低获取依赖关系效率,从而导致预测通道注意力方面产生不足。因为卷积具有良好的跨通道信息获取能力,WANG 等[23]通过在SENet 中使用一维卷积替换掉全连接层FC,从而成功地避免了降维,并且有效地获取了跨通道交互的信息,在提升性能的同时减少了计算量,实现了一种轻量级的高效通道注意力模块(Efficient Channel Attention Module,ECA)设计。ECA 结构如图7 所示,首先将特征图通过全局平均池化,将其维度从C·H·W 压缩到1×1×C 的规格;然后使用1×1 卷积,通过通道特征学习从而获取相对应的权重系数,此时输出维度为1×1×C[24];最后,将处理后的特征图与原始的特征图逐通道相乘,获取结合了通道注意力的特征图。

Fig.7 ECA module图7 ECA模块
k与C的关系如式(11)所示。
其中,C表示通道数,k表示1×1 卷积的卷积核数,表示距离最近的奇数,γ和b分别设为2和1。
1.4 预测模块
最后的预测网络分为3 个部分,通过类别预测、位置预测、回归预测这3 个部分获取预测边界框。位置预测和类别预测采用交叉熵损失为损失函数,回归部分的损失函数采用IoU 损失。类别部分的损失函数计算如式(12)所示,位置部分的损失函数计算如式(13)所示,回归部分的损失函数计算如式(14)所示,IoU的计算如式(15)所示。
其中,N、M、Z依次为类别、位置、回归部分的样本总数;gti和gtj依次为类别、位置和部分真实框的类;pi是类别部分的特征点类别预测结果,pj为位置部分的特征点是否包含物体的预测结果;(xl,xt,xr,xb)和则是预测框和真实框左上角与右下角的坐标。最终损失函数公式由类别、位置、回归这3 个损失函数以不同的权重系数组合而成,如式(20)表示。
其中,θ为网络学习参数,λc为权重因子,参照文献[25]设置为5。
2 实验与结果分析
2.1 实验数据与评价指标
实验所用数据集为CrowdHuman,该数据集是由旷世提供的一个用于行人检测的数据集,包含训练集15 000张,测试集5 000 张,验证集4 370 张,每张图片大约包含23个人,同时这些图片包含了各种情况下的行人图,例如遮挡、小目标等状况[23]。该数据集下行人所处的环境多种多样,面临的挑战较多,能够很好地检验模型性能。评价指标采用平均准确率(Average Precision,AP)和帧率(Frames Per Second,FPS),可以更加清晰地反映出实验模型在识别行人时的精确程度和效果。AP 和FPS 的提升将有助于提升系统整体效果,从而更有效地完成任务。其中,AP 值越高表示实验模型检测行人目标的性能越好;FPS 值越高表示实验模型的运行速度越快。本文依据COCO 数据集对不同尺度目标的划分标准如表1所示。

Table 1 Criteria for dividing targets at different scales表1 不同尺度目标的划分标准
本文实验使用Pytorch 深度学习框架进行模型改进,硬件配置为Intel(R)Core(TM)i7-12700H CPU,NVIDIA Ge-Force RTX3090 和64GB 内存。软件环境为Python3.6、Cuda10.1、Pytorch3.6和Numpy 1.17.0。
2.2 实验结果与分析
2.2.1 实验设置
在训练阶段,将CrowdHuman 数据集图片分辨率设置为640×640,每个训练批次大小设置为4 张图,迭代次数设置为150。通过色域扭曲、翻转图像、缩放图像等操作随机预处理输入图像,使用自适应片矩估计(Adaptive Moment Estimation,Adam)优化器,初始学习率为0.000 1。
2.2.1 实验比较
为了验证改进模型的效果,将改进后的模型分别与Yolov4[26]、RetinaNet[27]、CenterNet[29]、YoloX、YoloX-SA-SE等5 种模型进行对比。实验结果如表2 所示,检测效果比较如图8所示。
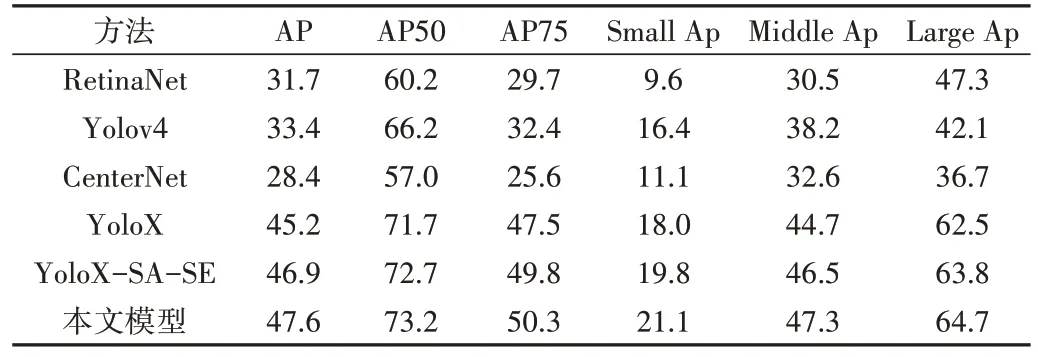
Table 2 Comparison of the experimental results表2 实验结果比较(%)

Fig.8 Comparison of experimental results图8 实验结果比较
从表2 可以看出,改进后的模型在IoU 阈值为0.5 时(对应AP50),检测准确率达73.2%,提升了1.5%。此外,小尺度行人检测准确率提升了3.1%,中尺度行人检测准确率提升了2.6%,大尺度行人检测准确率提升了2.2%。与几种常用目标检测算法(RetinaNet,Yolov4 和CenterNet)相比,检测精度分别提高了13%、9%、3.2%。相较于最新的一种基于YoloX 改进的YoloX-SA-SE 行人检测算法,检测精度也提高了0.5%。可以看出,YoloX 算法相比一些经典算法,无论是何种尺度的行人目标,其检测精度都有所提升。其中,最新的一个YoloX-SA-SE 的改进算法利用CSP模块和双向特征金字塔网络以及注意力机制保留浅层特征信息,利用残差结构、信息流动避免行人信息缺失从而实现了检测精度提升。本文模型相较于对比算法,性能均有一定提升。一方面,特征金字塔模块与特征增强模块通过浅层与深层之间的信息流动,有效地融合不同尺度特征层地的语义信息,避免了网络深度造成的信息缺失或特征变弱问题,实现了特征增强的目标;另一方面,C2f 模块与混合域注意力机制融合,可以借由BAM 提取丰富的行人特征,同时利用C2f 模块的跳层结构可以有效地获取更加丰富的梯度流信息,并实现了一定的轻量化目标。
2.2.2 模块验证实验
依次引入不同的模块进行实验,模块验证结果如表3所示。从实验结果可以看出,在YoloX 算法引入特征增强模块可以有效地提升模型检测精度。①特征增强模块可以通过特征融合有效利用浅层特征层中的小尺度行人特征,避免小尺度行人特征因网络加深而丢失的问题;②自注意力机制通过提取特征的上下文信息获取密集的全局信息,从而抑制背景信息对行人检测的干扰,但这一操作也会抑制中小尺度行人特征;③针对自注意力机制在抑制背景信息的同时也会抑制小尺度行人特征,采用ECA 注意力机制通过通道关联性的非线性建模增强行人特征。C2f-BAM 模块也可以基于C2f模块采用更多的跳层连接以获取更加丰富的梯度流信息,并通过减少卷积层和采用Split 分层实现检测速度提升。此外,通过C2f 模块与混合域注意力机制BAM 结合,可以保存更多的行人特征从而提升行人检测精度。综上,各模块有效提升了行人检测精度。实验结果表明,当IoU 阈值设置为0.5 时,相对于原本算法,改进模型的检测精度分别提升了0.5%和1.5%,说明本文模型各模块能够提升行人检测精度。

Table 3 Verification results of modules表3 模块验证结果(%)
2.2.3 运行效率
为了测试本文模型运行效率,在CrowdHuman 数据集上进行相关实验。评价指标采用FPS 指标,FPS 值表示算法每秒钟处理的图片数量。FPS 值不仅与算法模型有关,还与硬件配置有关,FPS 值越大,意味着模型运行速度越快,效率越高。本文选取Yolov4、Faster R-CNN[30]、YoloXSA-SE 这3 种对比算法,实验结果如表4 所示。可以看出,本文算法模型的检测速度为24.3 FPS(帧/s),本文模型的检测速度相较于其他相关算法具有一定优势。

Table 4 Operational efficiency results表4 运行效率结果
3 结语
为了提高行人检测精确度,降低其误检率、漏检率等,本文提出了一种基于混合注意力机制和C2f的行人检测算法。在YoloX 算法基础上,设计了一个特征增强模块,并且引入了注意力机制和C2f模块。通过在特征提取模块引入C2f 模块,可以获取丰富的梯度流信息并实现一定的轻量化;在特征金字塔模块采用C2f 模块融合BAM 注意力机制可以有效地保留行人特征;通过设计特征增强模块,可以通过特征融合策略尽可能保留足够的中小尺度行人特征,同时引入自注意力机制结合特征的上下文信息以增强行人特征并抑制背景细节信息。此外,通过ECA 注意力机制引导网络关注行人目标,解决因为自注意力机制导致的中小尺度行人特征被抑制的问题。本文通过设计一个特征增强模块并采用C2f 模块与混合域注意力机制BAM 相结合可以有效增强行人特征,并抑制背景信息等无用特征,从而实现提升行人目标检测准确度和检测速度的目的。下一步将对行人检测遮挡问题进行研究,进一步提升模型性能。
