基于因果分析的能源系统缺失值补充研究
2024-02-21房旭
房 旭
(浙江理工大学 计算机科学与技术学院,浙江 杭州 310018)
0 引言
能源系统中,外部设备如传感器和采集器所处的环境错综复杂,电磁、湿度、温度等外界因素的干扰,系统运行中通讯网络的波动以及一些人为的错误操作,都可能导致监测数据出现不可预测的缺失现象[1-3]。自然界的数据分布通常不均衡,能源系统中采集器和传感器的数据经过消除趋势及差分后所形成的数据往往也不均衡,对于跨度很大的两组时序数据而言,其收集成本高,可能需要一些极端的数据进行学习。本文利用因果分析优化LSTM 的优化器,尝试解决该问题,以达到精度更高的优化结果。
因果分析理论的研究现状主要集中在Pearl 等[4]出版的《Causal Inference in Statistics:A Primer》,该文主要解决了传统统计语言中如何定义数据中的因果问题。Pearl等[4]提出认知因果包含3 个层级,事物之间的关联为第1层级,在此之上还需要对过程进行有目的的干预,第3 层级为反事实推理。传统的机器学习最擅长的是根据数据中呈现出来的相关性学习函数去拟合条件概率,这种机器学习模型只学习到了认知因果的第1个层级。
文献[1]提出因果图和结构因果模型的概念,因果图是在贝叶斯网络的基础上定义,通过有向无环图(DAG)的形式并遵从马尔可夫性和忠实性假设,抓住图与数据交互的关键,实现了图的连接性和变量独立性之间的联结。相比因果图,结构因果模型包含了更多信息,其不仅蕴含了一个观测分布,还蕴含了干预分布和反事实分布,可以在因果图干预的基础上,进一步支持反事实推理。后门准则和前门准则可以帮助识别并消除因果图中的混淆变量,将do 算子表示的干预分布转化成条件分布,在此基础上利用统计方法进行因果推断,从而去除混淆因子[5-7]。本文将结合LSTM 模型中的优化器[8-15]进行因果分析及优化,通过尝试消除因果分析生成的混淆因子,对优化器进行改进,从而达到更加收敛的预测结果,并将其用于能源系统缺失值补充。
1 因果分析消除混淆因子
1.1 不均衡数据预处理
本文针对能源系统中的不均衡数据选用BBN[16]框架,假设一对训练样本描述为x,y∈{1,2,…,C},其中C表示类别的数量。卷积学习分支和重平衡分支分别采用均匀采样和逆采样,采样的样本分别表示为(xc,yc)和(xr,yr),两类样本分别加入各自的分支产生特征向量fc∈RD和fr∈RD。而后通过累计学习策略综合两个分支的输出,该过程可表示如下:
其中,z∈RC为对每个类别的预测,每一个类别i∈{1,2,…,C}的预测表示为[z1,z2,…,zC]T,通过Softmax函数可以得到每一个类别的预测概率。
再通过交叉熵损失函数E(·,·)计算对于预测概率=[,…]T的损失值。最终损失函数可表示如下:
Pytorch 中SGD Momentum 的定义为:
μ·vt-1为定义的Momentum,深度学习出现过拟合和欠拟合的问题是因为某些优化器,如SGD Momentum、Adam 优化器引入了Moving Average Momentum,其将过去所有的训练集拿过来进行加权求和,使训练的方向更加稳定。当数据分布不均匀时,优化器会倾向于选择捷径进行学习训练,产生偏见从而影响最终优化方向。
如图1 所示,相对平衡的数据进行深度学习时的学习曲线相对正常,但如果是比较极端的数据,学习的曲线会出现提前收敛的情况,这会造成预测出现较大误差。本文针对这种走捷径问题进行分析,尝试通过因果分析找出因走捷径问题产生的深度学习偏见问题并削弱其对学习过程的影响。将影响训练时产生的不被期望偏见的因素称为混淆因子,使得LSTM 模型在训练过程中按照预先设计的学习路线进行,避免捷径学习问题的产生,从而达到更加精确的收敛。
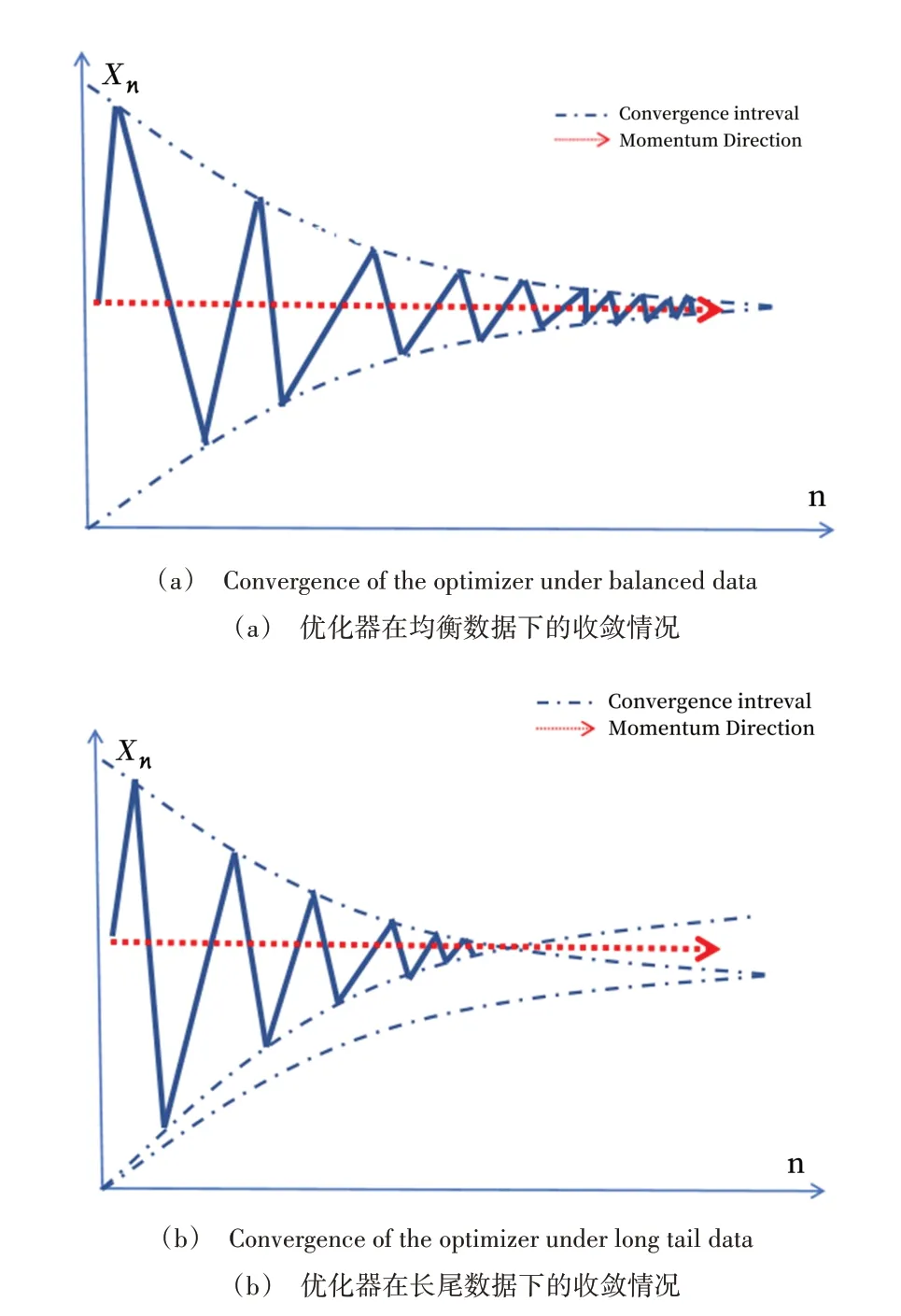
Fig.1 Convergence direction of optimizer in different data distributions图1 优化器在不同数据分布中的收敛方向
1.2 模型优化器因果分析
优化器在优化模型学习时会产生一些不被期望的偏移。图2 中Deflection 被认为是影响优化器产生偏见的主要因素,SGD+Momentum 本身也会产生一定程度上的偏转,Feature 和Deflection 都与研究的主要因素SGD+Momentum 有着正相关关系,但两者在深度学习过程中会产生一种伪相关,这是不期望产生的,这种伪相关在因果分析理论中[1]称作Backdoor Shortcut。因果分析理论中方法Backdoor Adjustment 被用来去除Feature 和其产生的Deflection之间的关系,公式如下:

Fig.2 Impact of learning bias in Momentum causal analysis on the results图2 因果分析Momentum产生学习偏移对结果的影响
假设头部偏转方向Deflection 是与动量相似的特征指数移动平均值的单位向量。
T是总的训练迭代次数Deflection 代表对主方向的偏转,由主干参数偏差引起,偏差Deflection 公式表示为:
解决M的未知分布问题采用Backdoor Adjustment,将其中公式的变形取到一个近似值。当M的分布无法确认,且M的可能值无限大时,如果给定一个特定值,则只能观察一个样本变量(i,x,d);当M的数量与(i,x,d)的数量都比较大时,便可以假设M的数量等于样本(i,x,d)的数量,即生成的特征值X与算法项Momentum 有1∶1的关系,可以通过对X进行采样从而近似地获取到M的分布。
其中,f(xk,dk;)为定义的特征值X到Prediction 的预测函数,g(xk,dk;)为定义的Propensity Score 函数。
De-confounded训练阶段P(Y=i|do(X=x))的logit为:
利用因果分析消除混淆因子主要解决的问题是当数据的分布未知,样本的数据呈现长尾分布时,利用因果分析对Momentum 算法进行改进,可去除其特征值产生的直接影响从而提取出有害因子在某一方向上的固定偏转,进而优化模型。
2 实验方法与结果分析
2.1 数据集
多变量预测中涉及到除电量以外的其他相关数据,比如温度、湿度、压强等,将这些变量也加入到训练中。本文选取2017 年1 月1 日至2021 年12 月31 日5 年内的 多变量数据,电力在夏天随着气温的升高会有一定量的增加,湿度会呈现出下降趋势,压强与湿度几乎呈现出同样趋势,到了冬季这3 种变量又呈现出完全相反趋势,在多变量数据中有着极为紧密的关联性,如图3所示。

Fig.3 Multivariate data of a steelmaking plant in 5 years图3 某炼钢厂5年内的多变量数据
2.2 评估标准
采用均方根误差作为评估标准,也称作标准误差,将其定义为i=1,2,3...n。在有限的观测次数中,均方根误差常用以下公式表示:
其中,i表示第i个数据,N为数据长度。均方根误差是在预测值和真实值差的平方和与观测样本数据N的比,再将其求平方根。
2.3 实验方法
首先加载数据集,然后对其进行标准化缩放,特征值在(0,1)之间,用3 个小时数据预测1 小时数据,再构建一个3 到1 的监督学习型数据,选择5 年中的前3 年进行学习,将前12 列作为X进行训练,倒数第4 列作为Y。测试数据也同样,将数据转换为3D 输入,步长为3,基于此搭建LSTM 模型,优化器选择SGD+Momentum,并进行实验。
拟合网络中,预测过程中将数据格式化成n*12 列,将预测列和后3 列数据进行拼接,因为后续逆缩放时,数据形状要符合n*4 的要求,然后对拼接好的数据进行逆缩放,观测值与真实值都要重复拼接缩放和逆缩放的过程。输入训练集和验证集同时不断调参进行训练,对比每次的拟合图,直到达到一个相对理想的拟合曲线。
以图3 所示的数据为数据集,按照上述方法对标准化后的能源系统多变量时间序列训练集建立LSTM 模型。因为本数据集的样本采集是以每小时为单位收集,用n_hours个数据预测一条数据,后续的输入和输出都与其有关,将数据由2D 转换成3D 时作为维度参数,构造监督学习模型时作为参数,设置时间步长,即timestep=n_hours等。n_features代表特征数量,特征值构成多变量进行预测,同时影响训练和测试集的输入输出由2D 转换成3D 时也会作为维度参数。
2.4 实验结果分析
本文提出基于因果分析的LSTM 模型(CALSTM),基于LSTM 利用因果分析预测的结果拟合曲线图与其他流行模型比较结果如图4 所示。可以看出,CALSTM 模型的拟合精度高于其他模型,特别是函数极值处;本文提出的方法拟合曲线平滑拟合度高,而传统LSTM 拟合呈现出偏高的情况且波动较大,Transformer 模型效果也较为理想,但在函数极值处仍出现个别拟合差的情况。其原因在于,本文提出的模型类似于Transformer 的编码器和解码器架构,该架构有利于充分学习数据之间的相关联系及潜在的分布规律,从而保证模型收敛时误差率相对较小,通过对比证明本文模型表现出更高的鲁棒性和精度。
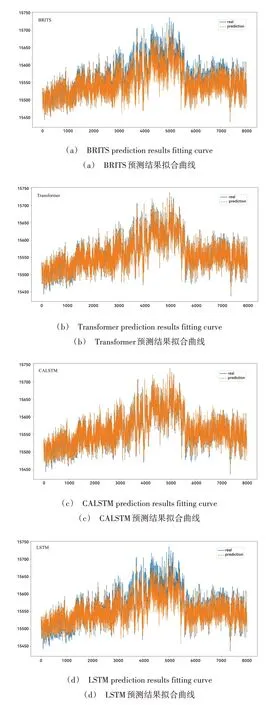
Fig.4 Fitting curve of prediction results图4 预测结果拟合曲线
为了证明该模型有效性,将其与当前流行的时间序列预测方法进行比较,评价指标为MAE、RMSE、MSE,如表1所示。首先将本文提出的CALSTM 模型与LSTM 模型做消融实验,两者均在相同的训练集上进行训练,均选择SGD+Momentum 作为优化器,并在同一测试集上进行误差分析。可以看出,CALSTM 在3 项评估标准中均优于传统LSTM 模型,本文模型RMSE 降低2.04,MAE 降低1.65,MSE 降低54.10,这些指标证明CALSTM 可有效避免因走捷径产生的学习偏见,有效降低长尾分布数据在深度学习中的误差率。

Table 1 Statistical of time series interpolation efficiency evaluation表1 时间序列插补效率评估统计
CALSTM 相比传统的平均值(Mean)算法预测精度明显提升,相比ARIMA 与BRITS,本文模型也有明显优势,相比ARIMA,RMSE 为评估标准降低0.1,本文提出的方法没有对时间序列进行假设拟合操作,而是将数据集进行训练,由机器进行输出降低了误差率。相比BRITS,在MAE标准下降低近0.05,BRITS 对比本文方法相当于只有编码器部分,本文模型的解码器会对输入进行学习从而降低误差率。相比流行的Transformer 在各项数值中也表现优异,因为本文模型中也有类似的编码解码器模型结构,是在其优点基础上又改进了优化器。由图5 可以看出,本文提出的模型在样本数据量较少和较多的情况下均可以获得很高的预测精度,本文模型消除偏见及再均衡策略可以达到明显高于其他模型的预测精度。综上所述,本文所用方法在该炼钢厂能源系统的数据集中以LSTM 为基础通过因果分析去除偏见可以有效降低误差率,使得预测精度更高。

Fig.5 Comparison of model training sample data and prediction accuracy图5 模型训练样本数据与预测精度比较
通过比较实验,本文改进的LSTM 模型使用因果分析去除模型在学习过程中的混淆因子,切断机器学习走捷径的问题,在多变量复杂的能源系统环境下,取得了较好的预测结果,这证明因果分析出的混淆因子能够降低模型预测效率与鲁棒性,优化器消除影响后具有更好的学习性能。
3 结语
本文提出基于LSTM 模型,通过因果分析得出混淆因子,该混淆因子会在深度学习时产生学习偏见,影响LSTM在输出时的误差率。本文在消除混淆因子的情况下进行预测,并通过对比实验证明了其有效性,该模型在未知数据分布情况下仍可以提高预测精度。将改进的优化器用于能源系统中多变量数据的预测,对于生产环境多样且复杂的工程应用具有直接积极作用。实验结果表明,本文提出的方法可以更加精确地进行缺失值插补,有利于基于基础数据作进一步分析及监测后续操作,对于复杂能源系统整体性能有较大提升作用。后续研究将致力于提高预测准确率并确保数据波动较大时的稳定性,以更好地服务于智慧能源系统。
