一种面向虚拟化环境的Linux TCP/IP流程优化方法
2024-02-21翁创
翁 创
(上海船舶运输科学研究所有限公司 舰船自动化系统事业部,上海 200135)
0 引言
随着互联网和大数据技术的蓬勃发展,云计算逐渐成为现代计算领域的核心技术之一。众多企业和个人纷纷将数据和应用部署在云服务器上,以便利用强大的云计算能力降低本地硬件和软件成本。云计算技术的迅速普及催生了计算资源、存储资源和网络资源的集中化管理。虚拟化技术作为云计算的关键组成部分,为用户提供了灵活、安全、易用的计算环境[1]。在云环境和大数据环境下,例如HDFS[2]和分布式文件系统[3]以及HTTP 静态资源访问等场景中,服务器经常采用虚拟机的方式进行部署。该方式有助于提高数据的可靠性和安全性,同时便于备份[4]。
然而,在虚拟化环境中,由于虚拟机资源的隔离性和数据传输过程的复杂性,云服务器的性能受到了显著影响[5]。在应对大量并发请求和大规模数据处理时,性能瓶颈问题尤为明显[6]。例如在图1 所示的KVM(Kernelbased Virtual Machine)虚拟化环境下,一个宿主机安装着多个虚拟机,不同类型的资源分别被存放在不同虚拟机里[7]。当请求资源时,请求报文首先被宿主机系统内核接收,然后宿主机解析报文并将报文发往指定的虚拟机,最后虚拟机将资源按原路返送回去。在整个过程中,TCP/IP协议经历了多层解析,每一层解析都会消耗CPU 资源[8]。同时,用户态和内核态的频繁切换也进一步增加了性能开销,可能导致CPU 利用率上升、系统响应速度降低。
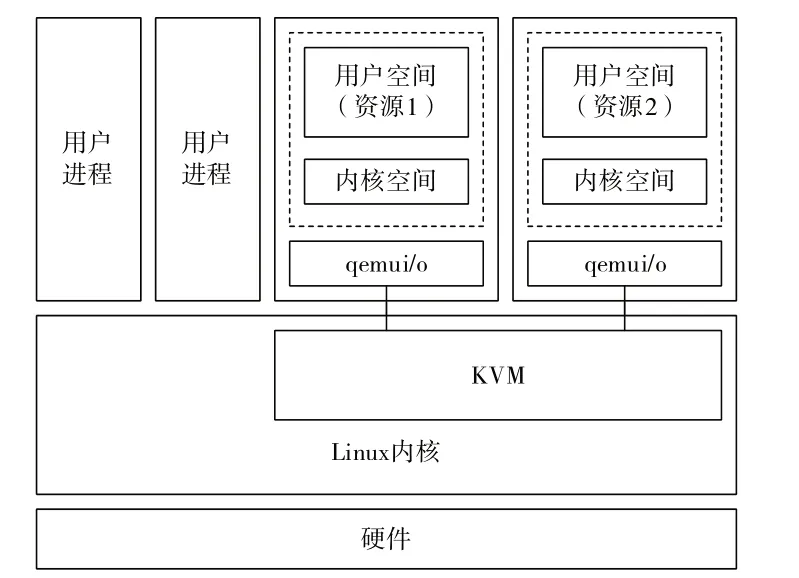
Fig.1 KVM virtualization infrastructure图1 KVM虚拟化基础架构
为了解决上述问题,本文提出一种基于Linux 内核的优化方 法(Kernel-Oriented TCP/IP Optimization Method,KOTOM)。该方法利用宿主机内核态netfilter 的挂钩函数监控发往目标服务器的TCP 请求和服务器响应,并建立被请求资源的缓存,通过LRU 算法实现热点资源的缓存替换,从而降低TCP/IP 协议处理过程中资源在内核态与用户态之间传递带来的性能开销。实验结果表明,该方法成功地节省了服务器计算资源,并缩短了请求时间,降低了服务器在虚拟化环境中的CPU 资源利用率。本文的主要创新点如下:
(1)优化了Linux TCP/IP 解析流程,实现了直接在内核态进行TCP 报文解析。
(2)建立了内核态缓存机制,减少了用户态与内核态之间的切换次数,提高了系统整体效率。
(3)提出一种根据请求热点数据变化的动态自适应缓存替换策略,实现更高效的缓存利用。
1 相关工作
本文关注的是虚拟化环境中云服务器的数据传输效率和计算资源利用效率,为介绍该领域的研究现状,以下对一些与本文主题相关的工作进行了回顾。
Yasukata 等[9]为解决操作系统内核栈和专用网卡(NICs)之间交互性能的问题,提出了StackMap 方法。该方法通过优化操作系统内核栈和专用网卡(NICs)之间的交互来降低网络延迟。其分析了现有内核栈和网卡的通信过程,发现了一系列可以优化的点。这项工作对于理解内核栈和网卡之间通信过程的优化具有重要意义。本文提出的KOTOM 方法优化了面向虚拟环境的Linux TCP/IP 解析流程,并实现了直接在内核态进行TCP 协议解析。此外,其采用了一种新型的内核态缓存机制,通过降低用户态和内核态之间的切换次数,提高了系统整体效率。与本文方法相比,StackMap 方法主要关注操作系统内核栈和专用网卡之间的交互优化,而本文方法更着重于内核态缓存机制和动态自适应缓存替换策略设计。
吕梅桂[10]详细阐述了在KVM 虚拟化环境下虚拟机网络性能优化的一般方法,特别是基于Direct IRQ 技术的优化方案。Direct IRQ 是指将网卡产生的中断直接发送到虚拟机,而不经过虚拟机监控器。与本文的研究相比,其主要是通过Direct IRQ 技术达到优化效果。该方法将网卡直接分配给虚拟机,本文方法不将网卡直接分配给虚拟机,而是通过虚拟机监控器缓存静态数据实现优化效果。KOTOM 方法针对性地解决了用户态和内核态之间频繁切换带来的资源开销问题,并且引入了红黑树和LRU 策略,进一步提高了缓存查找和使用效率,从而使性能得到显著提升。
刘禹燕等[11]详细介绍了Virtio 框架的基本原理,阐述了该框架如何实现半虚拟化环境下的高性能网络通信。通过对Virtio 框架中的数据传输和缓存策略进行优化,实现了在半虚拟化环境下更高效的网络请求处理。该项工作为提高虚拟化环境中的网络性能提供了实际的解决方案。与本文方法相比,该研究主要关注半虚拟化环境下的网络通信性能优化,而本文方法适用于全虚拟化环境,通过优化内核态TCP/IP 数据处理和缓存策略,提高云服务器在虚拟化环境中的性能。本文方法不仅针对性地解决了用户态和内核态之间频繁切换带来的资源开销问题,而且提出一种根据请求热点数据变化的动态自适应缓存替换策略,实现更高效的缓存利用和性能提升。
1.1 TCP/IP优化
在传统的数据传输模式中,服务器遵循协议层次对报文进行逐层解析。具体来说,报文从物理层开始,逐级经过数据链路层、网络层、传输层,最终达到应用层[12]。如图2 所示,实线代表服务器内核在解析请求和发送数据时的传统模式。在该模式下,当服务器收到一个TCP 请求时,请求报文首先在内核态被各个协议层进行处理,之后传输层(例如TCP 层)处理完的报文会传递给用户态的socket进行深入分析。在应用层处理完请求后,其会将响应报文再次传递给内核态,以便进行下行传输。在此过程中,内核态与用户态需要频繁切换。

Fig.2 TCP/IP protocol parsing process in Linux图2 Linux下TCP/IP协议解析流程
内核态与用户态之间的切换涉及上下文切换、内存映射及资源调度等操作,会导致显著的资源与时间开销。此外,报文在逐层解析时需多次进行封装与解封装,增大了处理过程的复杂性和附加开销[13]。因此,在传统的数据传输模式下,服务器性能往往受到用户态与内核态频繁切换以及报文逐层解析所带来的资源与时间消耗的影响。
本文提出的KOTOM 方法致力于在虚拟化环境中基于内核态进行请求报文的解析与数据传输。与传统方法相比,该方法规避了报文的逐层解析和用户态与内核态间的频繁切换问题。图2 的虚线部分揭示了KOTOM 方法对数据包的另一种处理模式。首先,内核在网络层对请求进行解析,进而确定请求报文中应用层协议的起始地址;然后,内核对应用层协议进行解析,获取请求路径,并根据此定位缓存内容;最后,系统开始构建内容报文new_skb。new_skb的构建遵循以下指定顺序:
(1)数据区。从缓存中提取请求内容,并填入new_skb的数据区。缓存包含用户态协议以及请求内容本身,使得KOTOM 方法省去了用户态协议首部的构建。
(2)TCP 层。为new_skb 构建TCP 首部,需准确设定源端口、目标端口、序列号、确认号等TCP 首部字段。事实上,源端口、目标端口及序列号对应于请求报文的目标端口、源端口及确认号与内容长度之和。
(3)IP 层。为new_skb 构建IP 首部,需准确设定源IP地址、目标IP 地址、协议类型(TCP)以及首部长度等IP 首部字段。源和目标IP 地址分别与请求报文中的目标和源IP地址相对应。
(4)MAC 层。为new_skb 构建以太网首部,需准确设定源MAC 地址、目标MAC 地址及协议类型(IPv4)等以太网首部字段。目标MAC 地址与请求报文的源MAC 地址相同,而源MAC 地址是发送端网卡的地址。
完成这些步骤后,new_skb 被发送至原先发出数据请求的主机。值得注意的是,在整个请求流程中,TCP 连接的建立与释放均遵循3 次握手和4 次挥手的原则。尽管使用KOTOM 方法传输内容,但3 次握手和4 次挥手仍按照传统模式执行,该方法仅影响内容报文的传输流程。
1.2 基于LRU的内核缓存
KOTOM 缓存区允许热点内容在内存中进行短暂存储。当后续请求发生时,相关内容能直接从内存中提取。为了合理使用服务器内存并确保其稳定性,必须对缓存区的大小进行限制。首先,确定缓存区的最大容量。当缓存区的总容量达到此上限时,低频访问的内容将被新数据所替代。为此,基于实验,本文选择了一个适宜的缓存替换策略。其次,为简化内容管理,缓存区采用一个称为obj 的内容存储对象,该对象包含内容名称、大小、实体、请求路径以及访问时间等信息。最终,为缓存区设计了一套API,实现存储对象插入和基于路径的对象检索等功能。
当API 执行对象插入或删除操作时,内核会即时更新内容缓存区的可用空间、已占用空间及当前对象数。内容缓存区采用红黑树作为其对象的存储结构。与链表或其他具有O(n)搜索时间复杂度的数据结构相比,红黑树具有O(logn)的搜索时间复杂度,是一种更加高效的搜索结构。
LRU(Least Recently Used)缓存替换算法是一种广泛应用的高效的缓存管理策略[14]。其核心思想在于:每当对象被创建或已存在于缓存中的对象被访问时,其最近访问的时间戳会被更新。当缓存容量达到上限时,缓存中最久未被访问的对象将被新对象替代。例如,在图3 中,新创建的对象7 尝试进入一个已满的缓存,因此最久未被访问的对象5 被移除,使得对象7 得以存入[15]。因为LRU 策略将最近最少使用的数据置于缓存替换的较低优先级[16],所以与其他缓存替换策略相比,LRU 策略往往能够在多数场景下提高缓存命中率。
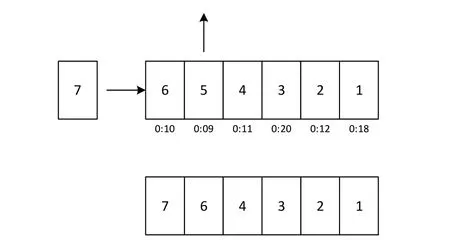
Fig.3 LRU cache replacement algorithm schematic diagram图3 LRU缓存替换算法原理图
为了有效实施LRU 策略,本文采纳了Linux 内核中的标准定时器jiffies[17]作为对象属性中“访问时间”的时间来源。jiffies 是Linux 操作系统的一个核心全局变量,记录了从系统启动到当前的时间单位数,常用于跟踪内核中各种定时器和计时器任务的执行时长。借助jiffies,本文能够精确地为LRU 算法记录访问时间,确保在缓存容量达到极限时,能够优先替换掉最近最少访问的对象。
为了高效地管理缓存区,本文需要提供API 以实现对象的插入、删除和查找功能。以插入功能为例,每当新的存储对象被创建,内核必须为其各成员(例如“对象名称”、“数据”和“路径”)以及对象本体动态分配内存。Linux 内核中的kmalloc 函数能够满足此需求,其允许动态分配连续的内存块。但值得注意的是,kmalloc 可分配的最大内存容量受到当前内核可用内存和连续内存块大小的限制,一般最大为128k 字节。为了实现缓存对象的动态创建,本文引入名为obj_create 的API,并借助kmalloc 来申请必要的内存。图4 详细展示了obj_create 的工作流程。首先,任何超过缓存区容量的数据都不能被保存;其次,如果当前的缓存空间不足,LRU_search 会遍历红黑树,定位到最近最少被使用的对象并通过node_delete 进行删除,此过程会重复,直至释放足够的空间给新对象;最后,obj_insert 会将新对象加入缓存区。
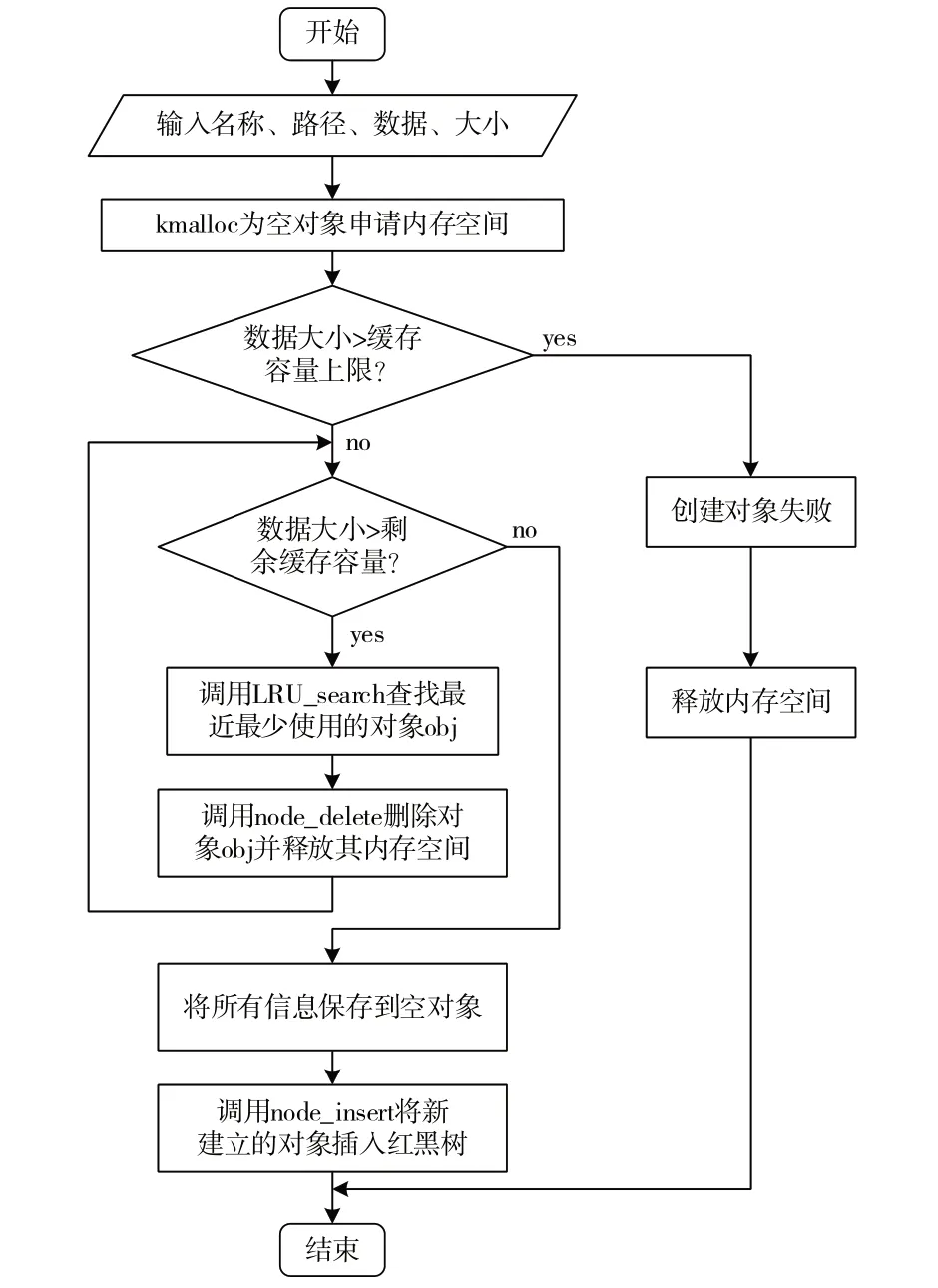
Fig.4 obj_create process flow图4 obj_create流程
在KOTOM 方法中,多个API 包括obj_create,都依赖于node_search 来查找特定的存储对象。node_search 能够仅凭请求路径高效定位和访问整个存储对象,主要归功于其使用的container_of 宏来识别存储对象的起始地址。在Linux 内核中,container_of 是一个特别设计的宏,其允许通过已知结构体中某个成员的指针以及该成员类型和名称迅速定位到该结构体的首地址。在本文的内核模块设计中,container_of 发挥了至关重要的作用,确保了高效的缓存管理和内容查询。
1.3 基于sysfs的缓存监控与配置
KOTOM 方法在内核态下处理数据,可避免冗余的内容拷贝和CPU 的额外开销,提供了一种效率极高的数据处理模式。但在实践中,实时的缓存区域管理和模块参数监视是不可或缺的。频繁地加载、卸载或调试内核模块不仅繁琐,而且可能带来潜在的系统风险。为此,本文采用sysfs 接口,以实现用户态与内核态之间顺畅的数据交互。sysfs 不仅便于对缓存区域和参数的管理监控,而且能确保所有内容处理始终在内核态下进行。这一设计平衡了实时监控与高效处理的需求,对系统的稳定性和可维护性都带来了积极影响,成为实施KOTOM 方法的关键策略。
sysfs 位于Linux 内核中,作为一种虚拟文件系统[18],其构建了一个统一通道,便于用户访问和控制设备树、内核对象、设备驱动以及其他核心组件。因此,利用其在用户空间中展示的分层目录,用户可以轻易地浏览和调整系统的各类参数。该设计巧妙地优化了Linux 内核与用户空间的互动方式,确立了其作为内核与用户交互的核心途径。
在模块的执行阶段,本文寄望于对缓存区的几个关键参数进行实时管理和监控:容量上限(cache_size)、剩余容量(free_space)、对象总数(obj_count)和已占用空间(used_space)。为实现这一目标,KOTOM 的内核模块设计了一个名为attr_group 的属性组。该属性组关联了4 个主要属性:cache_size_attr、free_space_attr、obj_count_attr 以及used_space_attr,且每一个属性都有相应函数来完成数据的读写操作。内核将此4 个关键参数以文件的形式传至用户态,使得用户可以直接通过这些文件来管理和调整参数。该设计巧妙地建立了内核与用户间的通信桥梁,大大简化了对缓存区的管理和监控。因此,用户能够便捷地访问和调整这些关键参数,从而实时了解并控制缓存区状态。
1.4 整体架构
Netfilter 是嵌入在Linux 内核中的网络过滤机制,其提供了一套灵活的工具,使得内核模块能够在网络栈的各个环节注册并对数据包进行实时拦截[19]。当请求报文在服务器内核中流动时,Netfilter 会对其进行路由调整,确保其正确地转发到虚拟机中。同样地,从虚拟机返回的数据包会被Netfilter 进行处理[20]。通过这一机制,本文得以深入地对数据包进行审查、修改或拦截,进而实现对进出请求和响应数据的精准处理。
图5 详细展示了Linux 内核中Netfilter 的核心架构[21]。在请求报文到达服务器时,服务器的网卡首先捕获这一报文,并迅速将其交付给Netfilter 进行处理。随后,Netfilter的ip_rcv 函数会介入,并对请求报文执行系列操作,如校验报文的完整性、对其进行解码,并进行必要的前期处理等。接下来,处理后的请求报文被传递给第一个路由节点(路由1)。该路由节点基于报文的目标地址信息进一步将报文导向第二路由节点(路由2),由其负责将请求报文准确地投递到预定的虚拟机中。值得注意的是,报文在传输过程中会依序经过Netfilter 的两个关键挂钩点,即NF_INET_PRE_ROUTING 和NF_INET_FORWARD。

Fig.5 Netfilter architecture图5 Netfilter架构
一旦目标虚拟机接收到请求报文,其立即生成并返回相应的内容报文。该报文首先被传递给路由2,接着路由2 将其交由ip_output 作进一步的处理和转发。完成对ip_output 及其他相关IP 层函数的处理后,内容报文进入物理层,并由dev_queue_xmit 负责进行物理封装。经过这一系列操作,内容报文最终通过服务器的网卡发送,直达客户端。值得注意的是,在整个传输和处理过程中,内容报文必然会经过Netfilter 的关键挂钩点NF_INET_POST_ROUTING。
当需要拦截请求数据包时,虽然有两个可能的挂钩点:NF_INET_PRE_ROUTING 和NF_INET_FORWARD,但本文优先选择NF_INET_FORWARD。这是因为NF_INET_PRE_ROUTING 挂钩处理的数据包的目的地也可能是本地服务器,而NF_INET_FORWARD 挂钩只关心那些需要转发至其他虚拟机的数据包。如果本文选择在NF_INET_PRE_ROUTING 位置设立挂钩,那么其将不得不处理额外、非目标性的数据包,因而可能会拖慢处理速度。所以,KOTOM 内核模块选择在NF_INET_FORWARD 位置设立了一个挂钩函数watch_in[22],专门用于捕获和转发数据包。该设计策略巧妙地避开了不必要的数据包处理过程,从而大大提升了整体的处理效率。
为了确保请求和响应的完整捕获与高效处理,本文还在NF_INET_POST_ROUTING 挂钩点设置了另一个挂钩函数,名为watch_out。该函数的主要任务是对内容进行缓存操作。具体的架构和流程可参考图6。图6 明确展示了请求和响应数据包如何被相应的挂钩函数watch_in 和watch_out 进行处理,并描述了其在整个Netfilter 框架中的位置和角色。

Fig.6 KOTOM architecture图6 KOTOM 架构
当客户端发出的请求报文通过路由1 并到达转发的挂钩点时,挂钩函数watch_in 立即捕获该报文。其首先解析报文,提取请求路径,并在缓存区查找是否存在与请求路径匹配的内容。根据查找结果,会有以下两种可能的情况:①缓存命中:如果缓存区中已有与请求路径匹配的内容,这些内容将被直接提取出来,绕过目标虚拟机,直接传递给函数dev_queue_xmit 进行打包,并快速转发给客户端。这期间原先被捕获的请求报文因为已经得到了响应,会被直接丢弃;②缓存未命中:当缓存区中没有与请求路径匹配的内容时,watch_in 不会立即作出反应,而是允许该请求报文继续通过路由2 被转发到目标虚拟机。当目标虚拟机生成响应并通过函数ip_output 处理完毕后,挂钩函数watch_out 会捕获该响应内容。在dev_queue_xmit 将响应报文转发给客户端之前,watch_out 首先将其保存到缓存区中,从而为未来的相同请求提供快速响应。需要注意的是,无论缓存是否命中,报文最后都要交给内核函数dev_queue_xmit进行处理。
图7 展示了函数watch_in 在实验环境下的详细工作流程。

Fig.7 watch_in process flow图7 watch_in流程
(1)报文过滤。watch_in 的第一步是区分并过滤掉那些非HTTP 请求的数据包,以确保只处理对缓存有意义的请求报文。在真实的网络场景下,watch_in 可以通过IP 目的地址、端口号和统一资源标识符(Uniform Resource Identifier,URI)过滤掉非HTTP 请求的数据包。
(2)路径提取。接下来watch_in 从HTTP 请求报文中提取请求路径,该路径是后续查找缓存的关键,所以会被保存在全局变量temp_path 中。需要注意的是,当Linux 内核创建数据包时,会经历组装多个数据片段的过程。该组装过程包含了大量数据拷贝工作。为了减少拷贝次数,网络接口利用分散/聚集 I/O 的方法将网络数据直接从用户空间缓冲区传输出来,实现“零拷贝”。因为KOTOM 模块在内核态执行,而内核态的数据片段存放地址是分散的,所以KOTOM 模块在提取请求的路径之前,需要利用skb_linearize 将多个数据片段合并在一起,实现数据线性化。否则,KOTOM 模块无法提取请求路径。
(3)缓存查找。通过调用函数node_path_search 并遍历红黑树,watch_in 尝试在缓存区中找到对应内容。如果在缓存中找到了匹配的内容,watch_in 首先会重置temp_path 为NULL,清除之前保存的路径。接下来,为了直接从内核态中将已缓存的数据快速返回给客户端,避免不必要的用户态和内核态之间的切换,watch_in 会构造一个新的数据包new_skb,new_skb 会将内容发送回客户端。除内容本身外,new_skb 的其他字段(如源地址、目的地址等)会根据实际需求进行填充。数据包构建完成后,使用dev_queue_xmit 函数将new_skb 从服务器的网卡发送至客户端。如果未在缓存中找到请求的数据,watch_in 直接返回NF_ACCEPT,将请求数据包交给目标虚拟机处理。
图8 描述了函数watch_out 的执行逻辑:①报文过滤:watch_out 开始时会通过条件判断来过滤掉非内容的报文;②内容保存:当确定接收到的是一个内容报文后,watch_out 会检查“temp_path”是否为空。非空状态表示当前报文与之前在watch_in 中捕获的请求报文有关。在此情况下,watch_out 会调用函数obj_create 将数据报文中的数据部分保存至缓存区,并为未来的相同请求提供快速响应。最后“temp_path”会被重新设为NULL,为处理下一个请求作好准备。

Fig.8 watch_out process flow图8 watch_out 流程
2 实验与分析
2.1 实验环境
如图9 所示,实验使用了一台Windows 主机A 作为请求客户端,一台安装了KVM 虚拟机的主机B 作为部署KOTOM 的云服务器。主机A 负责发送HTTP 请求。主机B安装一台虚拟机,使用Apache httpd 作为HTTP 服务器,负责接收客户端发出的HTTP 请求并返回相应内容。

Fig.9 Experiment environment图9 实验环境
具体配置如下:
(1)客户端(TPC-W Client 端):物理机。操作系统:Windows 7;处理器:i5-6300U,2.40GHz。
(2)服务器(TPC-W Server 端):物理机。操作系统:CentOS 7.9;内核版本:5.9。
(3)虚拟机:KVM。操作系统:CentOS 7.9;内核版本:3.10。
当需要使用KOTOM 方法时,将KOTOM 内核模块加载到主机B 的Linux 内核中。当HTTP 请求报文到达主机B时,内核会拦截并解析报文,获取请求路径并在缓存区中进行搜索。如果缓存区中已存在对应内容,内核会直接创建一个包含所需内容的报文,并将其返回给客户端,而不再继续发送拦截的请求报文至KVM 虚拟机。
若缓存区不存在对应内容,拦截的请求报文将被继续发送至KVM 虚拟机。当从KVM 虚拟机返回的内容报文经过内核时,报文会被拦截和解析,解析得到的内容将被保存在内核的缓存区中。因此,当下一次客户端发送相同的HTTP 请求时,内容将不再需要从KVM 虚拟机返回,而是直接从内核返回。通过该实验环境,能够直观地展示与验证高效缓存模块在提高数据响应速度和降低CPU 利用率方面的有效性。
2.2 实验设置
为了评估高效缓存模块在提高数据响应速度和降低CPU 利用率方面的有效性,本文采用TPC-W[23]进行实验。TPC-W(Transaction Processing Performance Council's Web Benchmark)是一个广泛应用于Web 服务器性能评估的基准测试。其通过模拟真实世界的Web 应用负载来生成一系列典型的HTTP 请求,从而为服务器性能提供一个标准化的衡量标准。
在实验中,本文分别部署了TPC-W Client 端和Server端,并采用静态数据模拟真实的HTTP 请求。在实验过程中,Client 端向Server 端发送HTTP 请求,请求次数可根据实际需求进行设定。首先,CPU 利用率可通过Linux 的top指令进行观测并记录。然后,客户端在发送请求的同时开始计时,请求结束后计时器停止计时并输出响应时间。最后通过数据量与响应时间计算响应速度,如式(1)所示。
本文在实验中测试了不同请求次数下,模块加载前后的数据响应时间和CPU 利用率。在相同的请求次数下,本文进行了10 组数据测试,以计算平均值、最高值和最低值。最后,根据实验数据绘制了CPU 利用率和响应速度的折线图,并通过正负偏差表示10 组数据中的最高值和最低值。实验指标包括数据响应速度和CPU 利用率,以此评估KOTOM 方法在不同工作负载下的性能表现。通过对比模块加载前后的实验结果,可以得出KOTOM 方法对服务器性能的影响。
此外,还对StackMap 方法、Direct IRQ 方法和本文的KOTOM 方法进行了对比测试。
2.3 实验结果
KOTOM 模块加载前后的CPU 利用率与响应速度如图10所示。

Fig.10 CPU utilization and response speed before and after KOTOM module loading图10 KOTOM 模块加载前后的CPU利用率与响应速度
由图10(a)可以看出,在请求次数小于500 次时,模块加载前后的CPU 利用率都随着请求次数的增加而上升,表明在请求次数较少时,CPU 利用率与请求次数呈正相关。同时,在相同的请求次数下,10 组数据中最高值和最低值的差异较大,说明在请求次数较少时,CPU 利用率的不确定性较大。当请求次数超过500 次后,模块加载前的CPU利用率稳定在约35%,而模块加载后的CPU 利用率稳定在约28%。总之,在不同请求次数下,模块加载前的CPU 利用率都会比模块加载后高约7%。
由图10(b)可以看出,模块加载后的响应速度在模块加载前响应速度的基础上提升了约22%。在请求次数较少时,KOTOM 方法的响应速度更快。另外,图中的正负偏差揭示了在请求次数较少时,不论在模块加载前还是加载后,响应速度的不确定性都较大;而在请求次数较多时,响应速度逐渐稳定。总体而言,无论请求次数多少,模块加载后的响应速度都明显高于加载前。
对应用不同方法的CPU 利用率与响应速度进行比较,如图11所示。
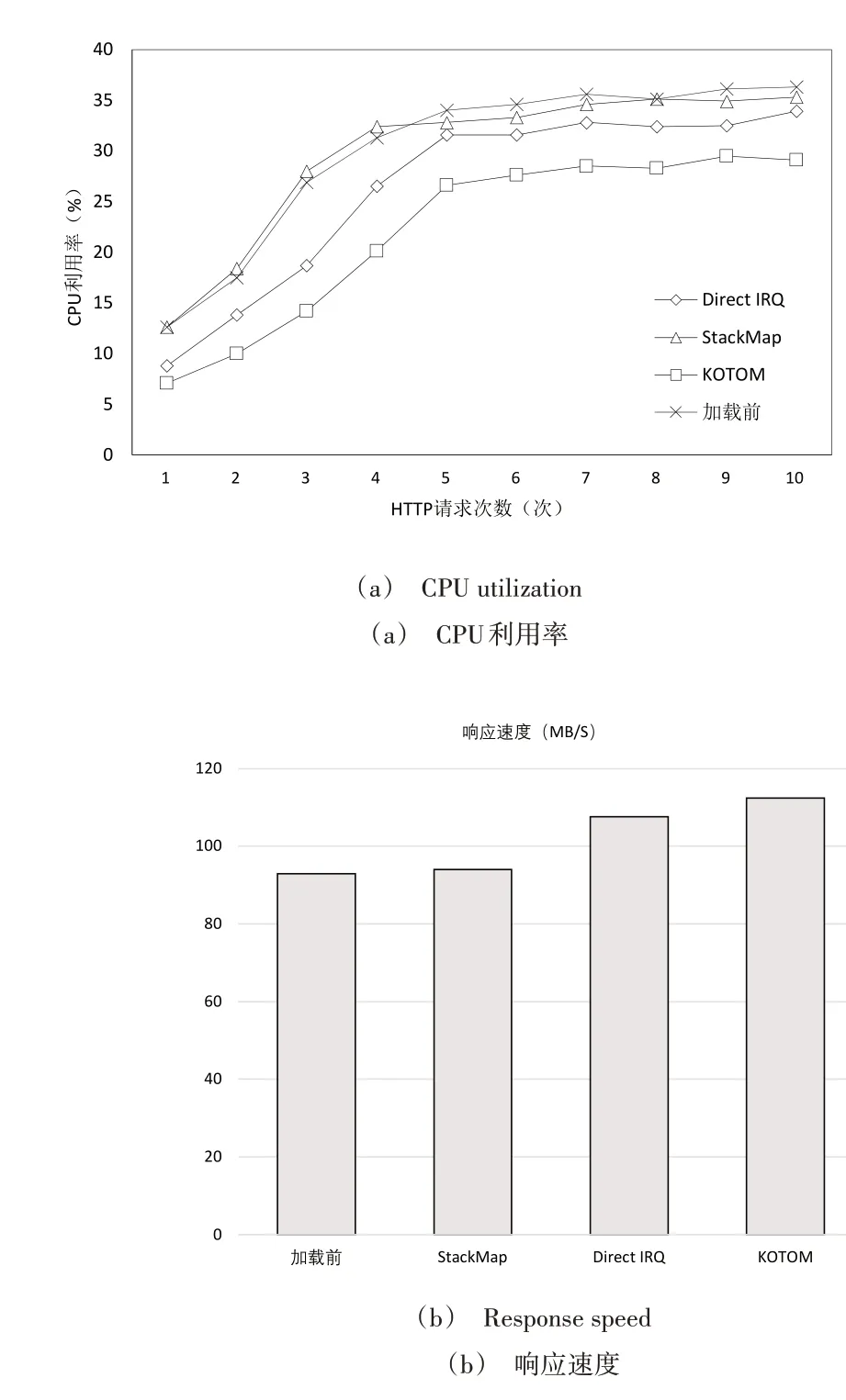
Fig.11 CPU utilization and response speed under different methods图11 应用不同方法的CPU利用率与响应速度
由图11(a)可见,应用StackMap 方法与加载前的CPU利用率区别不大。应用Direct IRQ 方法的CPU 利用率低于加载前,但当负载增加时,该差异逐渐缩小。这是因为Direct IRQ 要将网卡直接分配给虚拟机,当存在大量虚拟机且网络负载较高时,会带来较大的附加开销。StackMap 方法通过优化操作系统内核栈与专用网卡间的互动,有效降低了网络延迟,但在普通网卡上优化效果并不显著。KOTOM 方法针对性地解决了用户态与内核态之间频繁切换造成的资源损耗问题,因而具有相对较低的CPU 利用率。
图11(b)展示了应用不同方法的响应速度,可见应用3 种方法的响应速度相较于加载前都有不同程度的提升。然而,应用StackMap 方法在普通网卡下的提升效果不明显。应用Direct IRQ 方法的CPU 资源开销较大,会间接影响请求的响应速度。在CPU 利用率较低的情况下,KOTOM 方法能够使响应速度明显提升。
2.4 技术分析与讨论
本文在引言部分提出了3 个主要的创新点,其对于提高Linux 服务器在虚拟化环境中的响应速度及降低CPU 利用率起到了关键作用,在此总结这3 个创新点的技术内涵以及对实验效果的影响。
(1)Linux TCP/IP 解析流程优化。传统的Linux TCP/IP解析流程在多个网络协议层次之间需要进行多次的解析和封装操作,无疑增加了数据处理的复杂性和时间开销。KOTOM 方法对TCP/IP 解析流程进行了优化,直接在内核态实现报文的解析,从而避免了在不同协议层之间的频繁转换。这种直接的解析方式不仅加快了数据包的处理速度,而且减少了不必要的数据包复制和内存使用。
(2)内核态缓存机制。在传统的数据处理流程中,数据经常在用户态和内核态之间进行切换,这种切换带来的额外开销对系统性能有很大影响。为优化这一流程,本文建立了内核态缓存机制,将经常访问的数据直接保存在内核态,从而避免了数据在用户态和内核态之间的频繁切换。该方法降低了CPU 利用率,提高了系统整体效率。此外,这也意味着对于某些高频访问的数据,不需要再从硬盘或其他存储介质中读取,因而大大加快了数据访问速度。
(3)动态自适应缓存替换策略。KOTOM 采用经典的LRU(最近最少使用)算法作为其缓存替换策略。LRU 策略的核心是当缓存空间不足时,优先替换最长时间未被访问的数据,从而确保经常被访问的数据始终保留在缓存中,提高了缓存利用效率。
3 结语
本文提出一种基于内核态的TCP/IP 数据处理优化方法(KOTOM),目的是提高面向虚拟化环境的Linux 服务器响应速度,并降低服务器的CPU 利用率。通过对内核模块的设计与实现,以及在挂钩NF_INET_FORWARD、NF_INET_POST_ROUTING 处建立挂钩函数watch_in 和watch_out实现报文的捕获与转发,可实现在内核态中高效地处理数据。在实验部分对比了模块加载前后的响应速度和CPU利用率,结果表明,模块加载后的响应速度明显高于加载前。同时,无论请求次数多少,模块加载后的CPU 利用率都较加载前有所降低,证实了本文设计的高效缓存模块在提升服务器性能方面的有效性。
本文提出的基于Linux 内核的KOTOM 方法在提高响应速度和降低CPU 利用率方面取得了显著成果。该方法适用于虚拟化环境下的HTTP 静态资源访问场景,在此场景下对读取速度有要求时,该方法可以简化协议解析流程,减少用户态与内核态之间的切换次数,提高数据请求效率。虽然KOTOM 方法目前尚不适用于动态数据请求较多或数据写请求较多的场景,但该方法具有扩展性。通过对其进行改进和优化,比如增加其他协议类型的支持,使其不仅能服务于HTTP 请求,而且能为诸如HDFS 等系统提供支持,或者采用针对动态数据的缓存替换策略实时更新KOTOM 模块在内核保存的热点数据,从而适应动态数据请求较多的场景。通过这些改进和优化,KOTOM 可以成为一个更加全面、高效的解决方案,在更广泛的应用场景中展现其价值。
