基于预训练语义编码的判断句答案推理
2024-02-21王颜颜黄友志
李 飞,王颜颜,王 超,黄友志
(1.中国科学技术大学 计算机科学与技术学院,安徽 合肥 230026;2.科大国创云网科技有限公司,安徽 合肥 230088)
0 引言
智能问答旨在为用户问题提供精准的答案。当答案检索范围是大规模文档时,即为开放域问答[1]。该技术是一种对语言的理解和推理,是由感知智能向认知智能迈进的关键,被广泛应用于搜索引擎中,以实现更精准的搜索反馈。早期问答采用流式结构,包括问题分析、文档检索与答案提取[2-4]。这种级联组合的问答形式导致误差传递积累,问答效果难以保证,已有研究表明问题类型分类错误导致问答不准的情况占比高达36.4%[5]。
随着神经网络的发展,以“检索器—阅读器”为主的两段式开放域问答算法开始流行[6]。2017 年,文献[7]使用维基百科作为知识来源,用于解决开放域问题,该任务结合了文档检索和机器理解文本两个模块。后续研究者们提出了一系列改进方案,例如针对检索器的研究,提出了基于表示的检索器[8-9]、基于交互的检索器[10-11]以及将二者结合的检索器[12-13]。检索器是获取正确答案的第一步,对于问答的精度至关重要,但将其应用于大规模文档将存在严重的计算压力。因此,同期也有一些学者研究通过离线方法构建检索器[14-15],在牺牲语义表征精度的同时,一定程度上提升了计算效率。针对阅读器的研究侧重于从检索获取的相关文档中找到答案片段[16-18],演进方向主要是以联合的方式检索答案段落跨度,比如联合文本词性[7]、命名实体识别[7]、外部知识[19]等信息进行答案检索。
由于判断句问答仅依靠“检索器—阅读器”难以获取精准答案,因此一种面向判断句的答案推理方法被提出。研究重点分为4 部分,首先通过语义编码器对问题和依据进行编码表征;其次在答案生成器模块中,通过问题与依据组合训练一个判断句答案生成器;之后在答案依据获取器中,针对仅有问题没有依据的测试数据,通过使用Faiss大规模语义匹配工具进行依据获取;最终将判断句问题与答案依据组合输入到答案生成器中推理出问题答案。经过实验验证,基于大规模语料的判断句问答准确率高达96.58 %。
1 相关工作
基于大规模文本的问答研究与以往工作的不同之处在于问答中的问题类型是判断题,需要从大规模文本中抽取判断依据,对问题进行答复。这项工作通过从大规模文本中抽取与问题语义最相关的依据,然后结合问题和依据给出对应答案,可以看作开放域问答。
传统开放域问答[4]分为3 个阶段,包括问题分析、文档检索和答案提取。问题分析用于理解问题,便于后续进行基于语义的文档查找和答案提取。近期受到阅读理解模型的启发,基于检索器和阅读器组合的开放域问答被提出。首先通过检索器将查询范围从全文档定位到相关文档,然后通过阅读器进一步将答案锁定在某一篇文档段落[6]。文献[7]在问答检索阶段,先基于TF-IDF 加权的词和二元组进行问题表示,再使用信息检索方法召回最相关的N 篇文档。然后在文档阅读阶段,基于文档段落和问题训练两个分类器预测答案的起始与结束位置。由于文献[7]提出的基于TF-IDF 的稀疏检索器语义表征维度高、计算量大,后续稠密的检索器不断被提出:首先是表示检索器[8-9],也被称为双塔编码器,采用两个相同的独立编码分别对问题和文档进行编码,并计算表征相似度。文献[8]使用基于BERT[20]的预训练模型进行问题和文档的语义表征。但在这种方法中,文档和答案独立表征获取,无法获取文档和答案语义层面的深层关联含义。为了解决以上问题,基于交互的检索器[10-11]被提出,其将问题和文档同时作为输入,通过二者token 之间的交互构建检索器。但该方法通常需要进行大量计算,不适用于大规模文本。因此,结合基于表示和基于交互的检索器[12-13]被提出。文献[12]提出ColBERT-QA 问答模型,其不仅在问题与段落之间创建了细粒度的交互,而且可以迭代地使用ColBERT创建自己的训练数据,从而极大地提升了开放域问答的检索性能。
开放域问答的另一个核心是阅读器,一般通过神经机器阅读理解模型来实现,用于从一组细分到段落级的文档中提取出问题对应的答案。许多研究按照包含答案的概率对检索到的文档进行排序,并将问题与相关文档拼接作为阅读器的输入提取答案跨度[16-18]。文献[16]提出使用段落选择器过滤掉一些噪声,用于更好地提取文档段落中的正确答案跨度。还有一些研究以联合的方式基于所有检索到的文档提取答案跨度[7,19]。文献[19]提出一个端到端的问答系统,以整合BERT 和开放资源信息,实验结果显示该方法在答案跨度提取上具有很高的准确率。
以上研究基本都是通过问题直接从文档中提取答案片段。针对判断题,从文档中只能提取答案的判断依据,还需进一步推理答案。
2 判断句问答推理方法
针对目前大规模文本问答方法大多从候选文本中检索答案,而忽略了有些答案无法直接提取原文内容,需要作进一步推理。为了解决以上问题,一个面向大规模文本的判断问句答案生成方法被提出。具体研究框架如图1所示,包括语义编码器、答案生成分类器、答案依据获取器以及答案预测4 个模块。在语义编码器中通过对大规模文本使用RoBERTa 模型[21]继续进行预训练获取丰富的文本语义信息,实现问题和依据语义编码;在答案生成器中通过对比学习构造训练数据,捕捉文本语义特性并进行答案推理;在答案依据获取器中通过Faiss[22]向量化可以快速检索答案依据,并拼接到对应问题进行答案预测。

Fig.1 Full flow of the model图1 模型全流程
2.1 问题描述
给定一个自然语言的问题q,基于大规模文本语料给出对应的答案a。其中,所有问题类型为判断题,因此候选答案为Yes/No。首先设置大规模语料D中共有N篇文档,再将N篇文档分为Mc个段落,其中第i个段落pi包含L个字,即。QC是一系列问题,这些问题在大规模语料D中对应存在依据C与答案标签A,组合表示为训练数据集DC=(QC,C,A)。QU也是一系列问题,但这些问题没有对应依据和答案标签。
本文主要工作是对给定问题q,先从Mc个候选文本段落中找到问题最匹配的段落pi作为答案依据c,最终结合答案依据c和问题q,给出推理的答案a。a有两个值Yes和No。
2.2 基于预训练模型的语义编码器
为了能精准地回答问题,一个良好的语义编码器是必不可少的。因此,基于预训练模型的语义编码器被提出。使用RoBERTa 架构在原有模型基础上继续预训练领域语料C,不仅可以实现已有语言知识的迁移,而且可以捕捉更多领域知识。由于RoBERTa 方法相比BERT 方法采用了动态编码,而且使用了大的batch size,可以捕捉更多语义信息,因此以Roberta 预训练模型框架作为语义编码器继续预训练大规模语料。
将大规模语料和全部问题文本都作为预训练语义编码器输入,记为CAll。预训练的关键是获取训练词汇表,具体过程是先统计CAll中的词汇,设置词汇阈值TW,选择词频大于TW的存入词汇表V中。之后基于RoBERTa 进行领域语义编码器训练,训练后的RoBERTa 模型记为语义编码器(Semantic Encoder Based on Pre-training Model,SEPM),主要是通过语料进一步训练词汇表V 中词汇,使其包含更丰富的语义信息。
2.3 问题生成分类器
本部分的重点是构建领域问题、依据以及答案三者组合的(q,a,c)数据集,用于答案生成分类器训练。基于SEPM模型,通过输入问题q和对应依据c,输出答案a,并训练答案生成的分类模型。领域任务微调的关键是构造微调数据集,由于DC数据集中只包含正确依据和答案的数据对,如果不进行扩充,会导致模型训练结果的适应性差。为此,基于对比学习的数据集增强策略被提出。
针对训练数据集DC中的第j个问题qj,可以找到对应的答案aj以及依据cj。将问题qj与依据cj进行拼接作为一条正样本数据,记为,将答案aj量化为1,作为训练标签。然后基于问题qj从其他问题对应的依据中随机选择K个组成CK,将CK中第k条ck与qj结合。由于这些选择的CK与问题qj并不一致,因此可以构造K条负训练数据。将答案标签全部设为0,其中第k条负样本数据为。最终每一个batch size 里包含K+1 条数据DB=,其中包含1 条正样本,K条负样本。通过微调分类任务,针对K+1 条数据模型输出分类概率为:
其中,第i条正样本的概率为,K 条负样本的概率为。优化该对比学习的损失函数,定义如下:
其中,θ是训练数据集中的正样本数。
2.4 基于Faiss快速匹配的答案依据获取器
由于在上一节分类器中训练的模型是将问题与对应依据拼接,然后进行答案分类预测,这里重点介绍如何基于领域语义编码器获取QU中每一个问题对应的答案依据。待检索语料库D分为Mc个段落,通过SEPM模型获取Mc个段落的表征矩阵AD,矩阵大小为Mc×d,其中d表示向量维度。对于问题集中的NQ个问题,通过SEPM模型获得问题的表征矩阵AQ,矩阵大小为NQ×d。然后,建立基于Mc个段落表征矩阵AC的搜索索引Index。由于Faiss 存在多种不同的索引特性,因此实验中根据不同索引进行训练。最终针对问题表征AQ中的每一个问题,检索最接近的Nk个段落作为依据候选。
其中,P表示AQ中最接近的Nk个段落id,I 表示每一个段落与问题AQ的距离,将其作为问题AQ与文本语料不同段落相似的重要程度衡量指标。
通过以上方法获得问题的依据,再与问题语义相结合来预测问题的答案分类标签。
2.5 答案预测
通过以上部分,针对第j个问题qj,通过2.2 节的SEPM模型获取问题的语义表征ej,通过2.4节获取问题回答的相关依据cj,最终将ej和cj拼接输入到2.3 节的答案生成分类器中,预测输出分类标签的概率分布,再转换为对应标签Yes或No作为判断句答案输出。
3 实验与分析
3.1 实验设置
实验数据为新闻领域的英文问答数据,其中检索的语料库为英文新闻语料,共计200 万条,每条新闻语料的平均长度为713 个字。判断句共有1 万条,平均每条10.93 个字。将1 万条数据按8:1:1 的比例分为训练集、验证集和测试集,8 000 条训练集数据属于正样本数据,通过对每一条正样本构造多条负样本进行数据增强,K 取值为63,新增负样本训练数据50.4万条,共计训练数据51.2万条。
本文的实验环境为Linux 系统,torch 版本为1.11.0,torch-geometric 版本为2.0.4,GPU 型号为Tesla V100。实验中设词汇阈值TW为3 000,即选择词汇词频大于3 000 的词作为预训练词汇,共计22 573 个词汇。在对比学习中K+1的取值对应batch size 的大小,在敏感性分析中设置batch size 的大小为16、32、64、128 等值,并确定最优的batch size为64。对比实验中学习率选择2*10-5,最大序列长度为128。
精准度、召回率以及F1值3 个指标被用于评估模型表现,也即评估判断句答案生成效果。具体计算公式如下:
其中,x1为使用研究模型得到的判断句正样本的正确答案数,x2为通过模型获取的判断句问答任务中的正样本数据,x3为原始数据中判断句的正样本数据。
3.2 实验结果及分析
为了验证本文方法对大规模问答检索的有效性,实验中与多种已有方法进行比较。BERT[20]方法是Google 于2019 年提出的大规模预训练语言模型的基础架构,采用Transformer[23]的编码器建模语言表征。BERT-base 的参数规模较小,BERT-large 的参数规模较大。由于BERT 参数量巨大,为了减少模型参数,Google 在2020 年提出了Albert 模型[24],其是A Lite BERT 的简称,意为精简的BERT。其减少了整体的参数量,加快了训练速度。RoBERTa 模型[21]沿用BERT 架构,但改进了很多BERT 的预训练策略,可以更充分地学习到语言中的知识。
表1 展示了基于预训练语言编码的判断句问答推理模型与其他已有模型的精准率、召回率以及F1值的实验结果比较。可以看出,相比目前已有的多种基于预训练进行问答判断的方法,基于预训练语言编码的判断句问答推理模型具有更佳的效果,F1指标高达96.58%。在已有方法中,Albert 方法在BERT 基础上减少了参数量,并没有使效果得到提升。RoBERTa 方法由于使用了多种预训练策略,可以更好地学习数据中的语言知识,因此相比于BERT 和Albert 具有更佳的效果。本文使用的预训练模型是基于RoBERTa 框架,并在此基础上进行语义编码,最终在问答推理中取得了最佳效果。
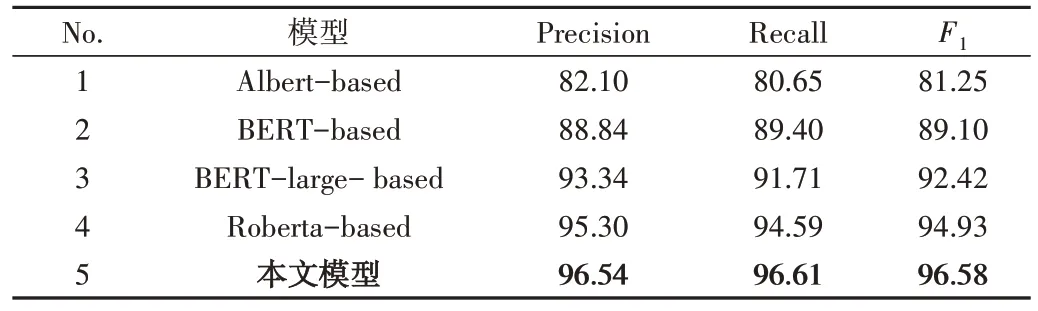
Table 1 Comparison of experimental results of different models表1 不同模型实验结果比较 %
3.3 敏感性分析
为进一步评估模型的效果,模型训练损失Loss 和模型整体评估指标F1被用于探究模型不同参数的影响。首先在相同参数下,对比不同batch size 对验证集损失以及F1的影响,batch size 的取值包括16、32、64以及128。
从图2 可以看出,在不同batch size 下,模型表现的差异性较大。图2(a)中的每一条线段展示了在固定batch size 时,随着训练轮次的改变模型的损失变化。可以看出随着batch size 的增大,验证集上模型的损失呈先下降后上升的趋势。说明由于训练数据并不多,训练轮次较多时会导致模型过拟合。因此,考虑到时间效率和准确性,模型训练轮次不宜太多。同时对比不同batch size 下的影响可以看出,整体上batch size 取值越大,损失越小,说明模型性能越好。图2(b)中的每一条线段展示了在固定batch size 时,随着训练轮次的改变模型准确性指标F1的变化。可以看出,该指标与损失具有相反的表现,整体上随着轮次增加,模型准确性指标F1曲折上升。同时对比不同batch size 下的影响可以看出,随着batch size 取值增加,模型的性能表现先有所提升,当batch size 等于64 时模型表现最佳。之后随着batch size 继续增加,模型性能开始下降。原因在于模型训练的batch size 并非越大越好,batch size 取值为64 较为适中。如果batch size 持续增大,会陷入局部最优,导致泛化能力差,因此在测试集上效果变差。综上所述,训练轮次选择一个适中的值5,batch size 取64。

Fig.2 Model performances under different batch sizes图2 不同batch size下的模型表现
此外,为了验证模型的稳定性,在相同参数下,基于模型整体评估指标F1开展了不同学习率对模型准确率影响的实验。图3 展示了在不同学习率下模型的性能表现。可以看出,随着学习率降低,模型表现逐渐提升。当学习率为0.001 时,模型效果非常差,当学习率逐渐下降,到达0.000 1 时,模型表现显著提升,之后继续降低学习率,模型表现略有提升。最终,当学习率为1*10-5时模型效果最佳。因此,最终实验选择学习率为1*10-5。

Fig.3 Model accuracy performance under different learning rates图3 不同学习率下的模型准确率表现
3.4 案例分析
为更好地阐述本文模型的表现,实验选择5 个不同的问题进行案例分析,通过模型查找相关依据以及最终对应的推理答案如表2 所示。由表2 的实验结果可以看出,本文提出的方法在大部分情况下都可以得到较好的结果。具体表现为,示例中所有查询到的依据都包含与问题相关的内容。例如第4 个问题是询问“埃玛·拉杜卡努”的信息,而通过模型在大规模语料中查询即明确搜索出关于此人的相关信息,而且该条信息对于问题判断至关重要。可以说明两点:一是本文方法提出的继续预训练语义表征可以丰富问题的语义信息,让其在依据获取阶段获得非常相关的依据;二是使用依据与问题相结合共同进行答案推断,使得依据可以对问题语义进行补充,从而提升答案的准确性。

Table 2 Results analysis of five specific problems表2 5个具体问题的结果分析
4 结语
为了解决开放域判断句答案生成问题,本文提出一个面向大规模文本的判断句答案生成方法,并在基于大规模新闻语料的判断句答案生成任务上验证了该方法的有效性,表明先生成依据,再将问题与依据结合推理答案的方法,相比传统直接将其作为分类问题的方法效果有明显提升。当然该方法中对依据的选取还是较为粗糙,下一步将对依据的划分采用更细粒度的方法,以期进一步提升模型的表现。
