基于注意力机制的时频域语音增强模型
2024-02-21何儒汉
林 攀,何儒汉
(1.武汉纺织大学 计算机与人工智能学院;2.湖北省服装信息化工程技术研究中心,湖北 武汉 430200)
0 引言
各种类型的环境噪声会极大地降低通信、自动语音识别以及助听器的效果[1-2]。语音增强的目的是提升语音质量和清晰度,从部分被噪声污染的混合语音中恢复干净语音。随着深度神经网络(Deep Neural Networks,DNN)的发展,研究人员提出大量基于DNN 的方法以提升语音增强效果。在低信噪比(Signal-to-Noise Ratio,SNR)条件下,基于DNN 的方法相较于基于统计信号处理的传统方法,能够更好地抑制非平稳噪声[4-5]。
基于深度学习的单通道语音增强方法按照其工作的信号域可分为频域、时域方法。频域方法对频谱图进行研究,认为经过短时傅里叶变换后的频谱图能更精确地分离背景噪声和干净语音[6]。在通常情况下,频域方法的训练目标包括理想二进制掩模(Ideal Binary Mask,IBM)[7]、理想比率掩码(Ideal Ratio Mask,IRM)[8]与最优比掩模(Optimal ratio mask,ORM)[9]。但所有上述掩膜都仅考虑了幅度谱而忽视了相位信息,只是简单地将估计的幅度谱与带噪语音相位相结合来重新合成增强语音[10]。文献[11]指出相位与语音的质量及清晰度有很强的关系。为解决相位失配问题,时域方法可以对语音原始波形进行处理。时域方法可以分为直接回归方法和自适应前端方法两类。直接回归方法从带噪语音波形直接学习到目标语音的回归函数,其通常采用某种形式的一维卷积神经网络。自适应前端方法在编解码框架中插入语音增强网络,如时间卷积网络(Temporal Convolutional Network,TCN)[12]和长短期记忆网络(Long Short-term Memory Networks,LSTM)[13]等具有时间建模能力的网络。文献[14]指出采用长短期记忆(LSTM)层的递归神经网络进行语音增强,效果明显优于多层感知器。递归网络要对所有频率的串联特征向量序列进行建模,具有相对较高的状态向量维度,因而会产生大量参数,严重限制了其适用范围。残差时间卷积网络(Residual Network-Temporal Convolutional Network,ResTCN)利用膨胀卷积和残差跳跃连接,在建模长期相关性方面表现出令人印象深刻的性能,并在语音增强方面取得了巨大成功。然而,语音和噪声在频谱表示上更容易区分,时域方法无法有效利用频谱表示中的声学信息。
现有模型主要关注如何有效地对长期依赖关系进行建模,而通常忽略了语音在T-F 表示中的能量分布特征,这对于语音增强同样重要。受注意力概念的启发[15-16],本文提出一种新的架构单元,称为时频注意力模块,用于模拟语音的能量分布。具体而言,注意力模块由两个平行的注意力分支组成,即时间维度注意力和频率维度注意力。其生成两个一维注意力图,引导模型分别关注“哪里”(哪些时间帧)和“什么”(哪些频率信道),使得模型能够捕获语音分布。
针对时域、频域方法的不足,本文在文献[17]基础上作出以下贡献:
(1)为了实现时域、频域两个领域的优势互补,进一步提取来自两个不同领域特征之间共享的信息,本文通过连接时域与频域的特征来构建时间和频率特征图。
(2)提出时频注意力模块,使得模型能够捕获时频域特征中的语音分布情况。
(3)联合时域、频域损失函数,提升语音增强模型的性能。
1 相关工作
1.1 基于深度学习的语音增强算法
在单通道语音增强中,带噪语音信号可由公式(1)表示。其中,x(t)为干净语音,n(t)为背景噪声,语音增强从带噪语音y(t)中估计增强语音信号x(t),使得x(t)与x(t)的差异尽可能小。干净语音中叠加了不同类型的噪声和各种信噪比变化,因此需要提高增强模型的泛化性,并提高其去除不同类型噪声的能力。
基于深度学习的语音增强模型如图1 所示,神经网络从已知的带噪语音数据中学习到干净语音特征空间的函数映射。网络的输入可以是音频原始波形,也可以是频谱特征。网络的输出是时频掩码估计值,利用得到的掩码与输入进行掩膜操作,得到增强语音的估计。
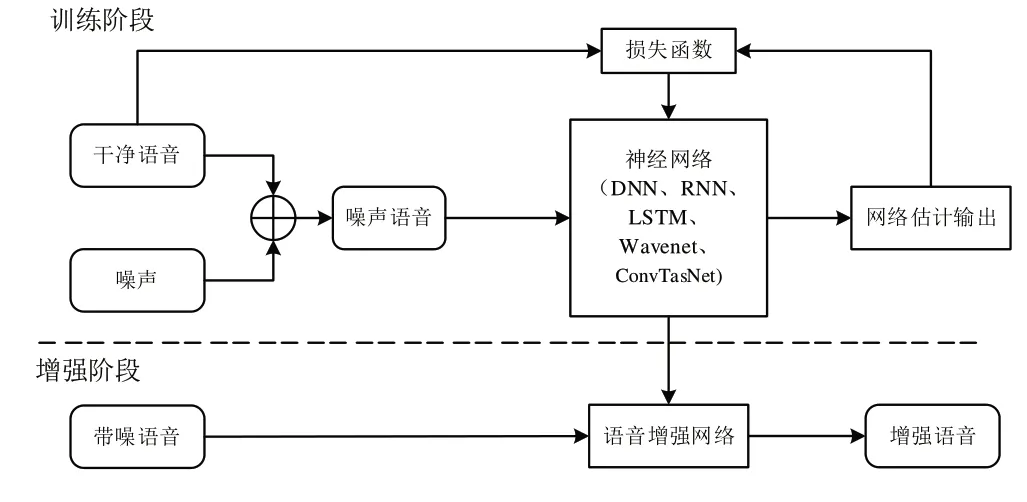
Fig.1 Voice enhancement flow图1 语音增强流程
为了提升模型在不同信噪比条件下的去噪性能,研究人员提出了大量改进算法。语音信号作为一种时序信号,具有很强的上下文关联性。卷积神经网络不具备直接利用上下文的能力,常常通过拼接相邻帧的方法扩大上下文窗口。循环神经网络(Recurrent Netural Network,RNN)按照顺序处理时序信号,不能大规模并行处理时间序列。上述方法通常会引入大量无关信息或存在不能充分关联上下文信息的弊端。因此,可使用时间卷积神经网络(TCN)维护语音信号中的时间信息。TCN 具有大规模并行处理的能力,降低了空间复杂度,提升了学习效率,其结合了因果层和膨胀卷积层来加强因果约束。与传统的卷积神经网络不同,因果卷积是一种只看到历史信息的单向模型,但其时间建模长度受到卷积核大小限制。为了解决该问题,膨胀的卷积可通过间隔采样来增加接受野。此外,TCN 使用残差学习以避免深度网络中的梯度消失或爆炸问题。
1.2 注意力模块在语音增强中的应用
基于Transformer 的语音增强模型可以有效对语音上下文信息进行编码,学习语音序列中的相互依赖关系。TST-NN 模型[18]在编码器、解码器中使用双路径Transformer 以扩大网络注意范围,可用于语音信息聚合。TU-NET在Transformer 基础上结合UNET 多尺度特征融合,以提升语音增强性能。然而,现有模型更多关注对长时间依赖关系的建模,忽视了语音在频域中的能量分布特征,而能量分布特征对预测掩膜具有重要意义。本文使用时频注意力模块对特征图进行加权处理,利用两个并行分支得到语音能量分布的两个描述符,用来突出相关特征,弱化噪声特征。
2 系统描述
本文提出一种新颖的单通道语音增强模型,对应的框架如图2 所示。其由混合域编码器、掩码估计网络和解码器组成。该框架可以同时利用语音信号的时、频域特征来协同提高语音序列的性能。因为噪声在频域上更具有区分性,而时域可以避免频域方法相位失配的问题。为了有效捕获时间信息并考虑输入信号中的长期依赖关系,使用残差时间卷积(ResTCNs)来创建掩码估计网络。同时使用时频注意力模块模拟语音的能量分布,其由两个平行的注意力分支组成,即时间注意力维度和频率注意力维度,使得模型能够捕获长程时间和频率相关性。下面将详细介绍相关工作。
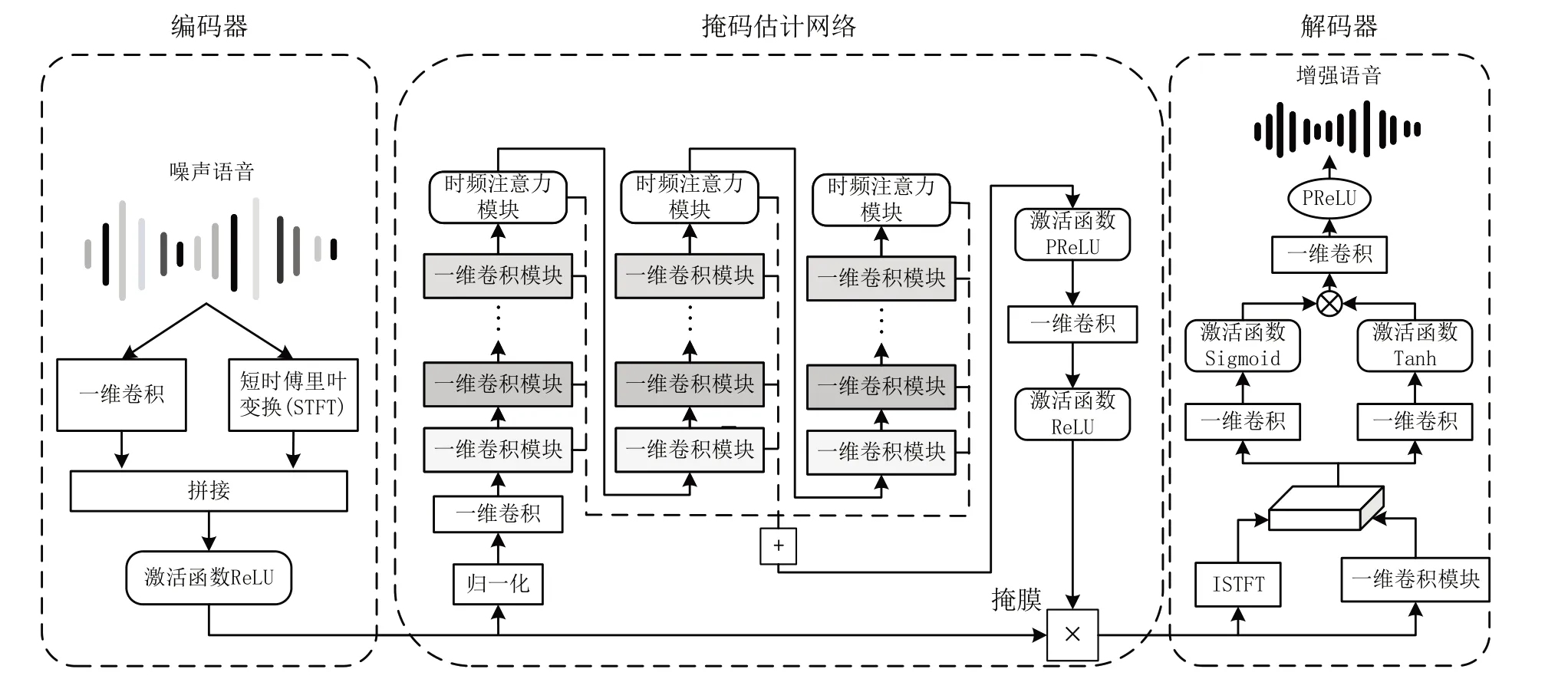
Fig.2 Model structure图2 模型结构
2.1 编码器
如图2 左侧所示,编码器结构由两个并行过程组成:一维卷积和短时傅里叶变换。将输入的噪声语音信号分别转换为时域和频域特征,时域特征要经过如图3 所示的分割操作后与频谱特征进行拼接,时域特征分割与双路径递归神经网络(DUAL-PATH RNN,DPRNN)[19]中的操作相似。将长度为T、宽度为N 的时域特征分割出S 个长度为2P、宽度为N 的数据块,片段间的重叠率为50%。为了正确地集成来自不同域的两个特征,本文为两个域设置了相同的窗口大小和跨距。将频谱特征与分割后的数据块时间帧对齐进行拼接。
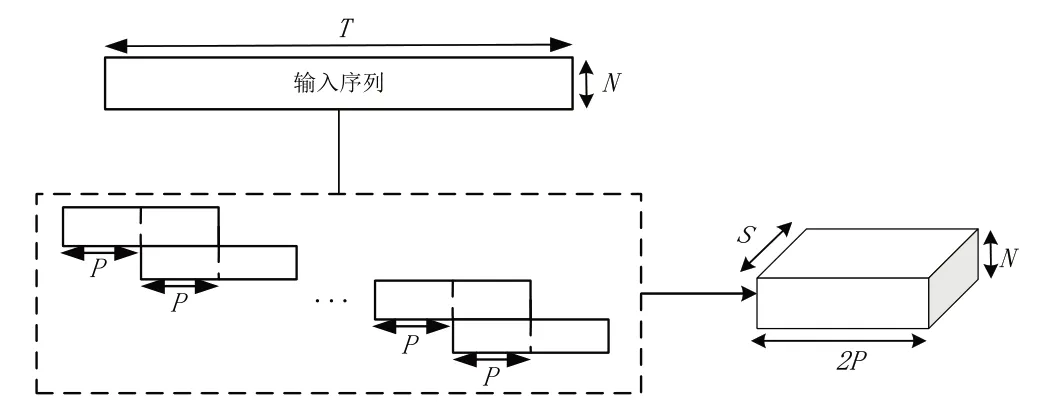
Fig.3 Speech sequence segmentation图3 语音序列分割
2.2 掩码估计网络
掩码估计网络输出权重掩膜,以实现去除噪声、提取干净语音的目的。为了有效地捕获时间信息,并考虑语音信号中帧的长期依赖性,可以通过堆叠BiLSTM[20]或膨胀卷积层(如时间卷积网络TCN)来创建掩码估计网络。膨胀卷积通过间隔采样来扩大感受野,能看到的输入层信息更多。图4 展示了膨胀因果卷积结构,图中输出层可以看到输入层前15 结点的信息。伴随着膨胀因子d 的增大,输出层的感受野也越来越大。本文在TCN 的基础上嵌入一维残差网络,以增强模型对局部语音特征的学习能力。

Fig.4 Expanded causal convolution structure图4 膨胀因果卷积结构
2.3 时频注意力模块
本文提出新的注意力模块用来捕获时间和频率相关性,如图5所示。
该模块由两个注意力分支组成,即时间维度和频率维度。每个注意力分支通过两个步骤生成注意力图:全局信息聚合和注意力生成。注意力图能准确反映语音在时间维度和频率维度上的能量分布。对给定的输入Y∈RM×N沿着时间帧维度和频率维度进行全局平均池化,生成频率统计信息ZF∈R1×N和时间帧上的统计信息ZT∈R1×M。具体公式为:
由此得到时间帧与频率维度上语音能量分布的两个描述符ZT和ZF,同时使用两个堆叠的一维卷积层作为非线性变换函数来准确地生成注意力权重。其计算公式如下:
将得到的分支注意力图相乘,得到时频注意力图:
2.4 解码器
将混合域特征映射乘以掩码之后,本文将掩蔽的编码特征分解为其原始分量:卷积特征图和频域谱图。本文从每个单独的域重构原始信号波形,时域特征通过一个反卷积层,然后采用重叠相加的方法来重构信号。频域特征用傅立叶逆变换导出,将具有权重参数α 的两个分量加权和作为估计的增强信号。
2.5 损失函数
为了提高语音的清晰度和感知质量,本文的损失函数结合了时域和频域信息,可以监督模型学习时频域中的更多信息。其中,频谱图的损失函数定义为:
式中,X、分别代表干净语音和增强语音的频谱图,r、i 分别代表STFT 变换后的实部和虚部,T、F 分别代表时间帧和频率段数量。时域损失可定义为去噪语音与干净语音之间的均方误差(Mean Squared Error,MSE)。具体公式为:
式中,Xi分别表示干净语音和增强语音,N 表示语音序列长度。本文采取的损失函数结合了时域和频域信息,公式如下:
式中,α是一个可调参数,本文将其设置为0.2。
2.6 数据增强
研究表明,在训练阶段增加数据的多样性可以增强模型学习不同特征的能力。因此,本文采用3 种数据增强方案:
(1)改变速度。针对原始输入语音波形,通过速度函数SOX 改变其输入信号的速度,并改变语音的音调。其是一种简单、有效的声学建模技术,被广泛应用于语音增强中。
(2)时移。时移是一种简单的音频数据增强方法,其将音频数据向左或向右移动f 秒。本文实验统一选择向右移随机移动0~0.625 s。
(3)样本掩蔽。将语音样本的掩码部分置零,从而使得被掩蔽的语音保持静音。该方法鼓励模型通过考虑上下文信息来预测干净的波形。样本掩蔽中有两个超参数:每个掩码的长度(t)和最大掩码数量(m)。通过实验,本文将t设置为固定值10,m 的取值区间为[0,150]。
3 实验与分析
3.1 数据集
为验证本文语音增强系统的有效性,采用公开、标准的语音语料库。干净语音从VoiceBank[21]中选取,根据说话者数量建立了两个子数据库:一个包含28 名说话者(14名男性,14 名女性),具有相同的英式口音;另一个包含56名说话者(28 名男性,28 名女性),具有不同口音(英式,美式)。从DEMAND[22]语料库中选取10 种不同噪声类型合成带噪语音,噪声包括8 种真实噪声和2 种人工产生的噪声。具体而言,8 种真实噪声类型包括家庭厨房噪声、会议室噪声,以及3 种公共空间噪声(包括食堂、餐厅和地铁站)、2 种交通工具噪声(包括汽车和地铁)与繁忙的交通十字路口噪声。2 种人工产生的噪声分别是通过增加白噪声产生的语音型噪声和通过增加语音产生的干扰噪声。在训练集中选取每位说话者10 条干净语音,将信噪比(SNR)值分别设置为15 dB、10 dB、5 dB 和0 dB。因此,每位说话者能产生400 条噪声语音。每一个干净的语音波形都会被归一化,当无声片段在开始和结束时超过200 ms 时,将被修剪掉。测试集选取两位说话者(一名男性,一名女性),从DEMAND 数据库中选择了另外5 种噪声类型,包括1 种家庭客厅的噪声、1 种办公室噪声、1 种公共汽车的交通噪声和2 种街道噪声。信噪比分别为2.5 dB、7.5 dB、12.5 dB 和17.5 dB。
3.2 实验设置
本实验中语音采样率均为16 kHz,编码器中使用短时傅里叶变换时,利用汉宁窗函数,设置FFT 大小为512,帧大小与帧移位分别为64 和32。对于增强网络,混合特征图首先经过具有256 个滤波器的一维卷积块,然后是8 个残差一维卷积模块(膨胀率为1,2,…,128),重复3 次。在训练过程中,设置模型学习率为0.000 5,Epoch 总数为100,选取Adam 作为参数更新的优化器。在评估方面,采用的指标为语音质量感知(PESQ)[23]、信号失真比(SISDR)[24]、扩展短时目标可懂度(ESTOI)[25]与噪声失真测度(CBAK)[26],上述指标数值越大,效果越好。
3.3 实验结果分析
表1、表2 展现了不同SNR 条件下STOI、PESQ 的得分情况。实验结果表明,本文采用的ResTCN+时频注意力的方法性能最好,证实了注意力模块的有效性。在3 种基线模型中,多头自注意力网络(MHANet)的性能最好。同时,ResTCN+频域注意力和ResTCN+时域注意力相比ResTCN也有了实质性改进。
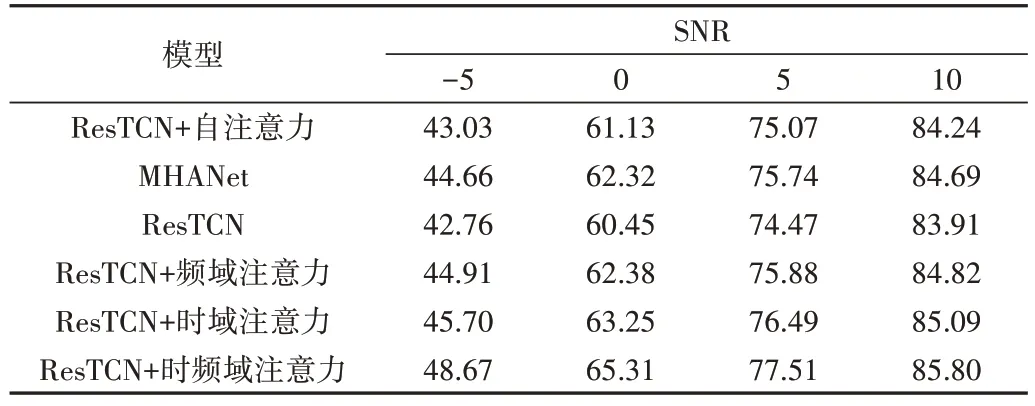
Table 1 Average ESTOI scores under different SNRs表1 不同信噪比下的STOI平均得分
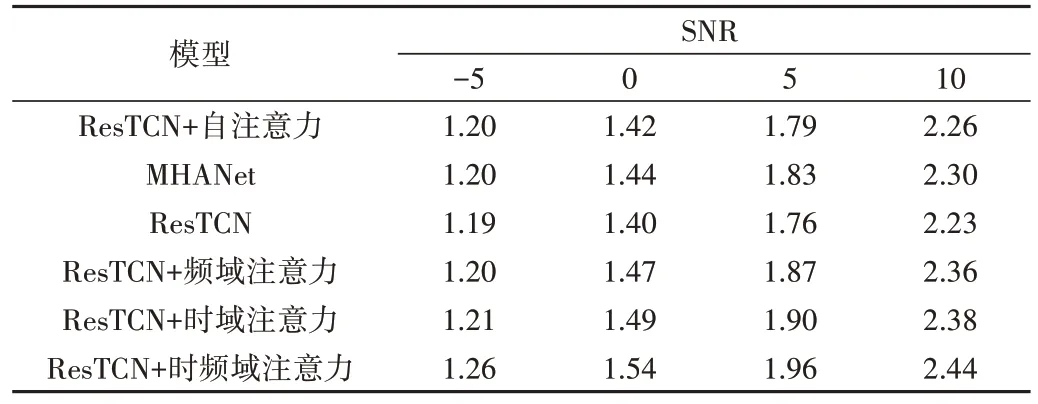
Table 2 Average PESQ scores under differenent SNRs表2 不同信噪比下的PESQ平均得分
图6 可进一步验证上述结果,图中红圈标记表明,使用时频注意力模块后的局部去噪效果更好。本文提出的方法去除了大部分低频噪声,增强后的语音十分接近干净语音。
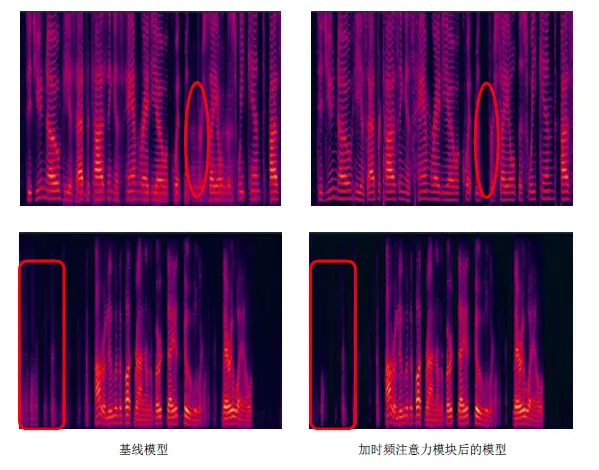
Fig.6 Spectrogram of noise reduction results图6 降噪结果频谱图
为验证数据增强对实验性能的影响,消融实验结果如表3 所示。结果表明,样本掩蔽方法对结果的影响最大,对实验性能的提升最为显著。
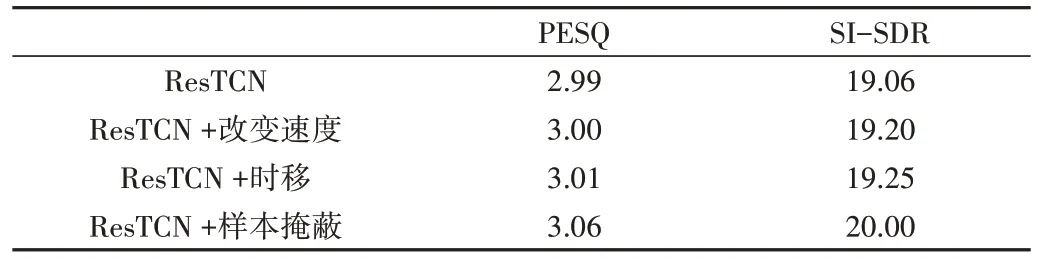
Table 3 Results of ablation experiment表3 消融实验结果
为进一步验证本文方法的有效性,与SEGAN[27]、ConvTasNet[28]、PHASE[29]、TCN 方法进行比较,结果如表4 所示。其中,SEGAN、ConvTasNet 是时域方法,编码器用一维卷积提取时域特征;PHASE、TCN 是频域方法,编码器用短时傅里叶变换提取频谱图。结果表明,本文方法在PESQ、SI-SDR、CBAK 上的得分优于上述方法,表明在编码器中融合特征能提高语音增强效果。

Table 4 Comparison of experimental results of different methods表4 不同方法实验结果比较
4 结语
本文将时域与频域特征相结合,利用两个领域的不同优势提升语音增强性能,同时提出一种轻量级时频注意力模块,可在T-F 表示中模拟语音的能量分布。在基线模型上进行了广泛实验,结果表明,本文提出的ResTCN+时频注意力方法始终表现最佳。未来还可以研究不同训练目标和损失函数对语音增强任务的影响,将语音增强技术扩展到真实语音噪声环境中,如去混响、多目标语音自动识别等任务上。
