改进秃鹰搜索和K均值混合迭代的点云简化算法
2024-02-20牛宏侠李富丽
牛宏侠,李富丽
(1. 兰州交通大学自动化与电气工程学院,730070,兰州;2. 兰州交通大学甘肃省高原交通信息工程及控制重点实验室,730070,兰州;3. 兰州交通大学光电技术与智能控制教育部重点实验室,730070,兰州)
随着3D目标检测技术的发展,点云的深度学习受到众多学者关注[1]。然而,点云数据无序和离散的特点对3D检测任务造成了极大的困扰,因此,三维点云简化算法的研究对点云的深度学习显得尤为重要。经典的点云简化算法主要包括包围盒法[2]、随机采样法[3]、基于特征的点云简化算法[4]等。Pauly等[5]通过计算空间二值化,提出了一种基于点样本分层分解的简化方法,但由于空间性质的原因,很难控制采样表面分布点的质量。Xuan等[6]引入信息熵和向量角,提出了一种渐进点云简化方法,该方法的基础是利用法向角的信息熵来寻找重要的点,并通过删除不相关的点来进行简化操作;然而,不相关点的选择具有极大的不确定性。Mahdaoui等[7]提出了一种基于香农熵和K均值聚类 (K-means clustering,KMC)的方法来简化三维点云,由于聚类时受点云空间形状的限制,因此聚类差异较大;同时,由于聚类中心点选取的随机性以及聚类优化路径的单一性,导致聚类结果不稳定。群智能算法在对聚类中心进行优化方面具有显著优势[8-9],结合聚类算法和信息估计为点云简化提供了一种新的思路。
秃鹰搜索算法(bald eagle search,BES)是2020年提出的一种新型优化算法[10],由于可扩展性强,在大规模全局优化问题中能够有效地跳出局部最优,与其它群智能算法相比具有更强的全局搜索能力。BES算法通过生物行为构建数学模型,主要分为选择、搜索和俯冲3个阶段,与KMC算法结合后能够实现点云的高精度聚类。由此,本文提出了一种基于改进秃鹰搜索和KMC混合迭代的点云简化算法(improved bald eagle search and KMC hybrid iteration simplification algorithm,IBESSA)。首先,对BES算法的优化和更新迭代方式进行改进,通过BES算法迭代阶段的竞争融合(competitive fusion bald eagle search,CFBES)加速收敛;然后,通过CFBES和KMC算法的混合迭代,实现点云数据的聚类;最后,引入点云信息熵概念,结合点云聚类结果实现了点云的简化。
1 CFBES算法
1.1 BES算法
BES算法通过模拟秃鹰捕食鲑鱼的过程,在搜索空间内对解进行优化。BES算法主要分为选择、搜索和俯冲3个阶段。
(1)选择阶段:秃鹰通过观察区域内猎物的多少来确定合适的搜索区域,为下一阶段搜索猎物做好准备。该阶段秃鹰位置Pi,new可用数学模型描述为
Pi,new=Pbest+αη(Pmean-Pi)
(1)
式中:Pbest为当前秃鹰确定的最佳搜索位置;α为控制位置变化的参数,α∈(1.5,2);η为随机数,η∈(0,1);Pmean为秃鹰根据所有搜索结果计算出的平均分布位置;Pi为第i只秃鹰的位置。
(2)搜索阶段:秃鹰在先前选定的搜索区域内进行螺旋运动,不断改变搜索的角度和速度以寻找最佳俯冲捕获位置,并同时向最佳位置移动。其运动行为可描述如下
θ(i)=aπη
(2)
r(i)=θ(i)+Rη
(3)
x(i)=r(i)sin(θ(i))/max(|r(i)sin(θ(i))|)
(4)
y(i)=r(i)cos(θ(i))/max(|r(i)cos(θ(i))|)
(5)
Pi,new=Pi+x(i)(Pi-Pmean)+y(i)(Pi-Pi+1)
(6)
式中:θ(i)和r(i)分别为螺旋方程的极角和极径;a和R为控制秃鹰飞行轨迹的常数,影响秃鹰搜索周期的长短,其中a∈(5,10),R∈(0.5,2);η为(0,1)内的随机数;x(i)和y(i)分别为极坐标中秃鹰个体的位置,取值均为(-1,1);Pi+1为第i只秃鹰下一次准备更新的位置。
(3)俯冲阶段:秃鹰以上一阶段搜索到的最佳位置为中心,向猎物方向的最佳点移动并对其进行捕获。仍用极坐标方式来描述秃鹰的运动状态,如下所示
θ(i)=aπη;r(i)=θ(i)
(7)
x1(i)=r(i)sinh(θ(i))/max(|r(i)sinh(θ(i))|)
(8)
y1(i)=r(i)cosh(θ(i))/max(|r(i)cosh(θ(i))|)
(9)
式中:x1(i)、y1(i)为俯冲阶段秃鹰个体在极坐标系中的位置。
秃鹰在俯冲过程中的位置更新公式可表示为
Pi,new=ηPbest+x1(i)(Pi-c1Pmean)+y1(i)(Pi-c2Pbest)
(10)
式中:c1、c2分别为秃鹰向最佳位置和中心位置运动强度的大小,取值范围为(1,2)。
1.2 改进BES算法
1.2.1 基于混沌映射的秃鹰初始化
由于秃鹰种群初始分布是随机的,生成的种群不够均匀,因此严重影响到种群的收敛速度和最终解的精度。蒋宇飞等[11]在蜉蝣算法中引入Sine混沌映射用于蜉蝣种群的初始化,使种群能够均匀分布在解空间中,从而提高了初始种群的质量,优化了随机初始化产生的缺陷,证明了混沌映射方法对元启发式算法的有效性。
本文利用混沌映射遍历性和随机性的特性,在传统Tent混沌映射中加入调节机制v/N,得到新的映射机制,如下所示
(11)
式中:Xi,j+1为映射得到的混沌值,i为种群大小,i=1, 2, …,N,j为混沌序号,j=1, 2,…,d;Xi,j为种群大小为i、混沌序号为j的混沌值;v为随机数,v∈[0,1];β为混沌参数,β∈[0,2]。图1给出了混沌映射序列分布的直方图对比,其中横坐标表示映射区间,纵坐标表示序列中落在相应取值区间内的数据个数。图1(a)为改进型Tent映射在区间[0,1]的分布图,此时β=1.2;图1(b)为经典的Logistic序列直方图。

(a)改进型Tent序列直方图

(b)经典Logistic序列直方图
通过对比两种序列直方图,发现改进后的Tent混沌序列能够使生成的初始种群较为均匀,而均匀分布的初始位置使得种群更容易从局部最优解中逃脱,从而寻找全局最优解。因此,使用改进型Tent映射生成随机序列,有利于前期的全局搜索以及种群的随机初始化。
通过不断迭代,得到一系列混沌值Xi,j,再将其映射到种群搜索空间,映射规则如下
Pi,j=Lj,min+Xi,j(Uj,max-Lj,min)
(12)
式中:Lj,min、Uj,max分别为秃鹰位置Pi,j的下边界和上边界。
1.2.2 竞争淘汰机制
秃鹰搜索算法中,位置更新主要靠个体间信息的相互交流,由于个体差异较大,导致同一区域内的秃鹰通过螺旋运动进行食物搜索时,需要多次迭代才能捕获猎物,同时,性能较弱的个体不能较快地达到最优区域,致使秃鹰在进行捕获猎物时寻优效率过慢,且在精度要求越高的场合,算法效率就越低。为进一步提高BES算法的开发能力,本文借鉴捕猎的习性,在秃鹰搜索阶段设计了竞争淘汰机制对秃鹰种群进行筛选,其基本过程主要分为个体筛选和盘旋寻优两个阶段。第一阶段以秃鹰个体的适应度函数作为筛选标准,根据种群中子代个体的适应度判断个体的优化性能,淘汰适应度较差的个体,从而获得新的秃鹰种群。第二阶段对第一阶段得到的新秃鹰种群进行增殖,以中心辐射法模拟秃鹰低空盘旋搜寻路线,获得新的秃鹰增殖种群,然后再次对新的种群进行适应度排序,按照初始种群数保留新的优秀个体,淘汰质量较差的个体,以保证种群数量不变。竞争淘汰机制具体过程如下。
首先,根据适应度设定阈值,通过优化性能差异进行个体筛选操作,保留适应度高于设定阈值的个体,淘汰适应度差的个体,同时更新秃鹰种群的数量,具体淘汰机制如下
(13)
式中:pi+1为根据筛选原则保留下来的适应度较优的个体;r为(0,1)间服从均匀分布的随机数;FSortIndex(i)为当前种群中第i个秃鹰个体对应的优化性能,表达式可写为
(14)
式中:SortIndex(i)为个体pi排序后的索引值;σ介于0和1之间,旨在任意方向形成搜索向量,提高找到最优个体的可能性;fmax、fmin分别为当前种群中最优适应度和最差适应度;f(i)为第i个秃鹰个体的适应度。
通过个体筛选策略,适应度低于阈值的个体会被淘汰,性能较优的个体会被保留,算法的寻优能力和搜索精度得到了提高。
以中心辐射法模拟上一阶段得到的秃鹰种群低空盘旋搜寻路线,进而获得新的秃鹰增殖种群,再次对新的种群进行适应度排序,按照初始种群数保留新的种群个体,以保证种群数量不变。秃鹰个体在搜索空间仍然服从均匀分布,用Ei表示通过中心辐射法得到的秃鹰数量,Oi表示以最优位置进行辐射增值的秃鹰种群半径,表达式可写为
(15)
(16)
式中:λ为辐射系数,用以决定种群中产生有效个体的能力,λ越大种群产生有效个体的数量越多;b为增值步长;N为种群数量;ζ为调节常数。
竞争淘汰机制可以通过淘汰适应度低的个体,使优质个体更容易地在搜索空间中找到更好的解,并避免过早收敛于局部极值。同时,在竞争淘汰过程中,采用中心辐射增值法会不断产生新的种群,并与原有个体进行竞争,从而保持种群多样性,避免种群陷入全局最优。通过设置适当的增值步长、辐射系数等参数,能够进一步增强算法的全局搜索能力。
2 CFBES与KMC算法的混合迭代
KMC算法[12]是一种无监督的机器学习算法,其将数据点划分为K个簇,广泛应用于数据分析和深度学习领域。KMC算法的具体流程如下。
(1)随机选取K个对象作为初始聚类中心,按照距离最近原则将数据分为K组。
(2)计算每个聚类簇各个维度的平均值,并将其作为新聚类中心用以更新聚类簇。
(3)重复过程(2),直到新的聚类中心不再变化或达到最大迭代次数,输出聚类中心。
KMC算法采用迭代方式求取各个维度的均值,但通过此方法确定聚类中心的局限性在于易陷入局部最优,导致优化精度过低。本文通过采用CFBES代替KMC的优化路径,实现CFBES与KMC的混合迭代,扩大了寻优范围,从而提升了聚类的效果。采用同一簇内聚类中心和样本点之间距离平方和,定义CFBES算法的适应度函数为
(17)
式中:μj为第j个聚类中心;x为样本点;m为该类簇中所有样本点的个数;K为聚类个数。通过适应度函数可知,当前聚类效果的好坏受该类样本数及每个类别中所有样本点到该簇聚类中心距离的影响。
聚类数目的设定会影响到最终的聚类结果,不同点云数据由于空间分布差异大,无法预先统一聚类数目。为适应不同数据空间特征,引入肘部法则(elbow method,EM)来确定点云数据的最佳聚类数目。EM法则的适用条件为:需要确定的聚类数目位于一个合理的范围内,且数据的聚类结构比较清晰,聚类簇之间的聚类有明显差异。EM法则对于点云数据同样适用,其基本思想为:随着聚类数目的增加,聚类效果会不断提高,但当聚类数目达到某一阈值时,聚类效果的提升会逐渐减缓,这个阈值即为最优聚类数目。EM法则的实现原理为:利用误差平方和SSSE画出K-SSSE曲线,通过观察图像,找到图像中出现“拐点”的位置,这个拐点对应的聚类数目即为最优聚类数目。SSSE的表达式可写为
(18)
式中:Ci为第i个簇;x为样本点;μi为Ci的质心。
图2给出了EM法则的取值示意图。其中,图2(a)表示输入点云数据散点图;图2(b)表示根据输入的数据进行聚类得到不同的簇;同时计算误差平方和确定最佳簇数,最后得到的聚类结果如图2(c)。由图可知,当聚类数目为4时,SSSE的斜率变化最大,由此可知,EM法则取值合理。

(a)散点图

(b)误差平方和与簇数量关系曲线

(c)聚类结果
CFBES-KMC算法流程如图3所示。算法的基本步骤描述如下。
步骤1输入标准点云数据集,计算误差平方和SSSE,确定初始聚类数目K。
步骤2利用混沌映射对秃鹰搜索算法进行初始化。
步骤3根据秃鹰搜索策略对种群进行更新。
步骤4利用改进的秃鹰搜索算法对种群进行寻优操作,得到新的聚类中心。若新得到的聚类中心适应度优于上次迭代的聚类中心,用新的聚类中心代替历史聚类中心。
步骤5判断当前迭代是否达到结束条件,若达到终止条件,输出寻优结果,结束程序。若未到达,则跳到步骤3,继续执行。

图3 CFBES-KMC算法流程Fig.3 CFBES-KMC algorithm flow char
3 点云信息量化
在三维点云简化任务中,需要通过信息熵对局部点云包含信息进行量化,通过计算信息熵评估点云中点的分布情况,涉及到密度评估函数[13-15],密度评估函数一般包括参数法和非参数法两种。由于点云数据的无序性,采用参数法进行密度估计存在一定的难度,因此,本文采用k近邻(k-nearest neighbors,k-NN)估计去完成点云信息熵的计算。
3.1 基于高斯核函数的k近邻密度估计
高斯核函数[16]是一种径向基核函数,常用于处理非线性数据,其基本原理是将数据映射到一个无限维的特征空间中,使数据变得线性可分,且具有很好的非线性分类能力。因此,本文结合高斯核函数提出了一种点云k-NN密度估计方法。
点云k-NN密度估计通过计算样本空间中每个点云的k近邻距离来估计该点处的概率密度,估计量的水平由k定义,它是最近邻的整数,与样本N成比例。样本对象x与其余点之间的距离关系可表示如下
Z1(x)<… (19) 式中:Zk为样本对象x到第k近邻点的距离。 d维k-NN估计定义如下 (20) 式中:G(u)为高斯核函数,可写为 (21) 将式(21)代入式(20),可得 Qk-NN(x)=N-1Zk(x)-d(2π)-(d/2)· (22) 进一步推导可得 (23) 式中:Cd为d维空间中单位球体的体积。 由上可见,k-NN密度估计方法的优点是不需要对概率密度函数进行假设,且对密度函数的局部变化具有较好的适应性。 香农熵[17]是由美国科学家克劳德香农于1948年提出的一个数学函数,其直观地对应于信息源所包含或传递的信息量。在点云簇的k-NN密度估计完成后,需要根据得到的局部密度值来计算点云的信息熵。点云的信息熵表示点云中点分布的不确定度,可以采用香农熵来计算,公式如下 (24) 式中:n为点云中的点数;Q(X=xi)为xi的密度估计值。 通过式(24),可以计算每个点云簇中各个点的贡献信息熵,并将其累加得到整个点云簇的信息熵。对于孤立的噪声点云而言,其信息熵通常为0。因此,香农熵用来表示每个点云中的信息量大小,数值越大包含的信息量越多。如果一个点云的信息熵为0,则意味着该点云的取值是确定的,不包含任何信息。基于对信息量的估计,可以准确地评估该点云簇是否包含主要特征,从而确定是否需要保留该簇。 为了评价本文所提简化方法的准确性,采用平均欧式距离(mean euclidean distance,MED)[18]指 标来评估全局误差,采用Hausdorff距离[19]测量简化后两个点集之间的局部误差。 平均欧式距离能够直观地反映简化后点云和原始点云之间的差异,其原理是计算简化后点云与原始点云之间的欧式距离,并取其平均值来评估简化误差的大小。设两个点集分别为X=x1,x2,…,xm和Y=y1,y2, …,yn,则平均欧氏距离可写为 (25) Hausdorff距离常用于评估简化后点云与原始点云之间的局部误差,其基本思想是找到一个点在两个集合之间的最短距离,然后取最大值。给定点集A和点集B,它们之间的Hausdorff距离可定义为 (26) 式中:d(a,b)为点a和点b之间的距离;inf为下确界操作;sup为上确界操作。式(26)可解释为:对于A中每个点a,计算与B中最近点b的距离d(a,b),取所有距离中的最大值;对于B中的每个点b,计算与A中最近点a的距离d(a,b),取所有距离中的最大值;将两个最大值中较大的一个作为Hausdorff距离,此值越小,说明简化后的点云越接近原始点云。 三维点云简化的目的是选择相关且具有代表性的三维点,去除冗余的数据点。本文将改进的CFBES-KMC算法用于简化密集点云,如图4所示。首先使用CFBES-KMC算法将点云细分为若干个簇,然后计算每个簇的信息熵,根据所得熵对簇进行降序排列,从而去除信息熵低的簇。这种简化方法既保留了鲜明的轮廓特征,又在简化点集中保留了细节特征,适用于简化非均匀分布的点集。 图4 主程序流程图Fig.4 Flow chart of the main program 实验硬件平台为Intel Core i7-12700KF处理器,NVIDIA GeForce RTX 3060 Ti显卡×2,32 GB内存的计算机,操作系统为Windows11,软件实现语言为python。 为验证CFBES算法的优化性能,将CFBES与BES[9]、改进秃鹰搜索(IBES)[20]、非均匀变异麻雀搜索(MSSA)[21]、改进飞蛾扑火(IMFO)[22]4种优化算法进行对比,采用单峰测试函数F1~F4测试其收敛效果,多峰测试函数F8~F10及F14测试其局部寻优及全局搜索能力。图5所示为各测试函数及收敛曲线的可视化结果,图中的x、y、z轴仅表示函数数值,量纲为1。设各种群大小均为30,迭代次数为100,维度为30,实验次数为20。CFBES算法中的辐射系数λ取30,调节常数ζ取20,增值步长b取1.5。采用平均适应度、标准差来定量评价算法的优化性能。 由图5(a)~(d)的收敛曲线可见,对于单峰测试函数,CFBES算法的收敛速度最快,即同一时刻CFBES算法获得的适应度最小,相比改进前的BES算法在搜索性能方面有较大的提升。由图5(e)~(h)的多峰测试函数迭代曲线可以看出,CFBES算法能够较早脱离局部最优,在全局寻优能力方面有着不错的表现。 (a)F1函数及收敛曲线 (b)F2函数及收敛曲线 (c)F3函数及收敛曲线 (d)F4函数及收敛曲线 (e)F8函数及收敛曲线 (f)F9函数及收敛曲线 (g)F10函数及收敛曲线 (h)F14函数及收敛曲线 表1给出了CFBES算法与其他优化算法的测试结果对比。由分析结果可知,在平均适应度方面,CFBES算法在8个测试函数中寻优得到的平均适应度更接近理论最优值,表明其收敛效果更佳,能够快速找到全局最优解。适应度标准差方面,CFBES算法在选取的8个测试函数中寻优效果较其他算法而言更加稳定。 表1 CFBES算法与其他优化算法测试结果的对比 为了评价本文提出的CFBES-KMC算法的改进效果,将其与改进飞蛾扑火K均值交叉迭代(IMFO-KMC)算法[22]、K-means++算法[23]、模糊C均值(FCM)聚类算法[24]应用到UCI数据集中,用以比较各算法的优劣性能。算法的参数设置如下:各类种群大小均为30,最大迭代次数为100,FCM聚类算法中的权重指数取2.1。标准数据集如表2所示。图6分别给出了CFBES-KMC、IMFO-KMC、K-means++、FCM 4种算法在Iris、Wine、CMC和Seeds数据集上的适应度收敛曲线。 表2 标准数据集特征 由图6可见,在Iris和Wine数据集测试中,CFBES-KMC算法均具有比IMFO-KMC算法更快的收敛速度;在CMC和Seeds数据集上,CFBES-KMC算法收敛效果明显优于参与对比的其他3种算法。由此可得,本文所改进的CFBES-KMC算法在收敛速度方面优于传统的K-means++和FCM算法。 同时,为更客观地评价CFBES-KMC算法的改进效果,分别采用YAcc、TARI、BNMI3个指标来衡量不同聚类算法的性能[25]。其中,YAcc表示聚类的准确率,即比较聚类结果和真实结果之间的一致性;TARI衡量的是两个数据分布的吻合程度,值越大意味着计算结果与真实值越相似;BNMI为归一化互信息,用来表示两组数据之间的关联程度。表3列出了4种算法在3个数据集上测试得到的评价指标以及单次迭代所需时间。由表3可知,CFBES-KMC算法在Iris数据集上测得的YAcc指标高于其他3种算法,表明CFBES-KMC算法在复杂寻优过程中具有更好的鲁棒性,其主要是由于在秃鹰搜索过程中加入了竞争淘汰机制;在Wine数据集上,CFBES-KMC算法的YAcc相较于IMFO-KMC、FCM、K-means++算法,分别提高了0.21%、2.48%和8.83%;在CMC数据集中,CFBES-KMC算法的TARI指标相较于其他算法提升了0.26%~1.94%;与此同时,CFBES-KMC算法在Seeds数据集上测得的YAcc、TARI和BNMI也均优于其他3种算法。 (a)在Iris数据集上 (b)在CMC数据集上 (c)在Wine数据集上 (d)在Seeds数据集上 表3 不同算法在4种数据集上的性能指标对比 在4种测试数据集上,K-means++和FCM算法单次迭代所需的时间均少于CFBES-KMC算法,而CFBES-KMC算法所消耗的时间相较于IMFO-KMC算法有不同程度的提升。其中,在Wine和CMC数据集上,CFBES-KMC算法的单次迭代时间相较于IMFO-KMC算法,分别节省了9.79%、6.83%。 由上述实验结果可知,KMC算法思路简单,聚类精度低,随机选取聚类中心致使算法稳定性差; FCM算法由于涉及到模糊控制,迭代曲线趋于平滑,但聚类精度不高;IMFO-KMC算法相较于CFBES-KMC算法,需要花费更多的时间才能收敛到足够精度;而CFBES-KMC算法由于采取了竞争淘汰机制,使得聚类算法不易陷入局部最优,稳定性较强,相比于其他算法聚类准确率更高。 实验采用常见的三维点云数据格式,选取兔、椅子和马作为点云数据模型进行三维点云的简化,得到原始点云、聚类结果、简化后点云的可视化图像,如图7~图9所示。由图可见,聚类结果保留了原始点云的结构特征,将模型主体结构划分为同一聚类簇,信息熵占比较大,避免了信息熵过低导致的结构性特征删除;而冗余的细节特征表现为离散的小型聚类簇,此类冗余点云数据由于信息熵过低,可在后期被过滤以达到删除非结构性特征的目的,从而实现三维点云的简化。表4给出了不同三维点云模型简化后的量化结果,统计数据为20次独立实验得到的平均值。 (a)原始点云图 (b)聚类结果 (c)简化后点云图 (a)原始点云图 (b)聚类结果 (c)简化后点云图 (a)原始点云图 (b)聚类结果 (c)简化后点云图 表4 不同三维点云模型简化结果 由表4可知,改进后的简化算法在删除点数和简化表面之间的误差方面有着较好的表现,原始表面和使用改进后方法得到的简化表面之间的全局、局部误差均较小;在运行时间方面,改进后的点云简化算法的运行速度能够满足实时性要求,且在有效滤除冗余点云的基础上保留了原始模型的纹理特性和几何特征,实现了点云数据模型的有效简化。 本文通过混沌映射对秃鹰种群的初始化进行优化,并在搜索阶段加入竞争淘汰机制对秃鹰种群进行筛选,提高了BES算法的搜索精度和全局寻优能力,然后通过CFBES-KMC算法实现点云数据的聚类,在k-NN实现点云簇密度估计的基础上,结合香农熵实现点云信息量化,删除量化值小于阈值的聚类簇,从而完成了点云数据的简化。仿真结果表明:在标准测试函数上进行优化性能分析时,CFBES算法的寻优性能优于参与比较的其它算法;与同类型的IMFO-KMC、K-means++、FCM算法的聚类效果相比,CFBES-KMC算法的聚类准确率分别提高了1.02%、12.31%、14.72%;提出的IBESSA点云简化算法在有效滤除冗余点云的基础上保留了原本点云的细节和形状特征,不失为一种高效的点云简化算法。3.2 信息熵定义
3.3 简化误差评估
3.4 基于CFBES-KMC算法和信息熵的三维点云简化

4 实验与结果分析
4.1 CFBES算法性能测试
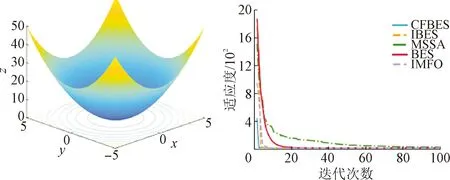








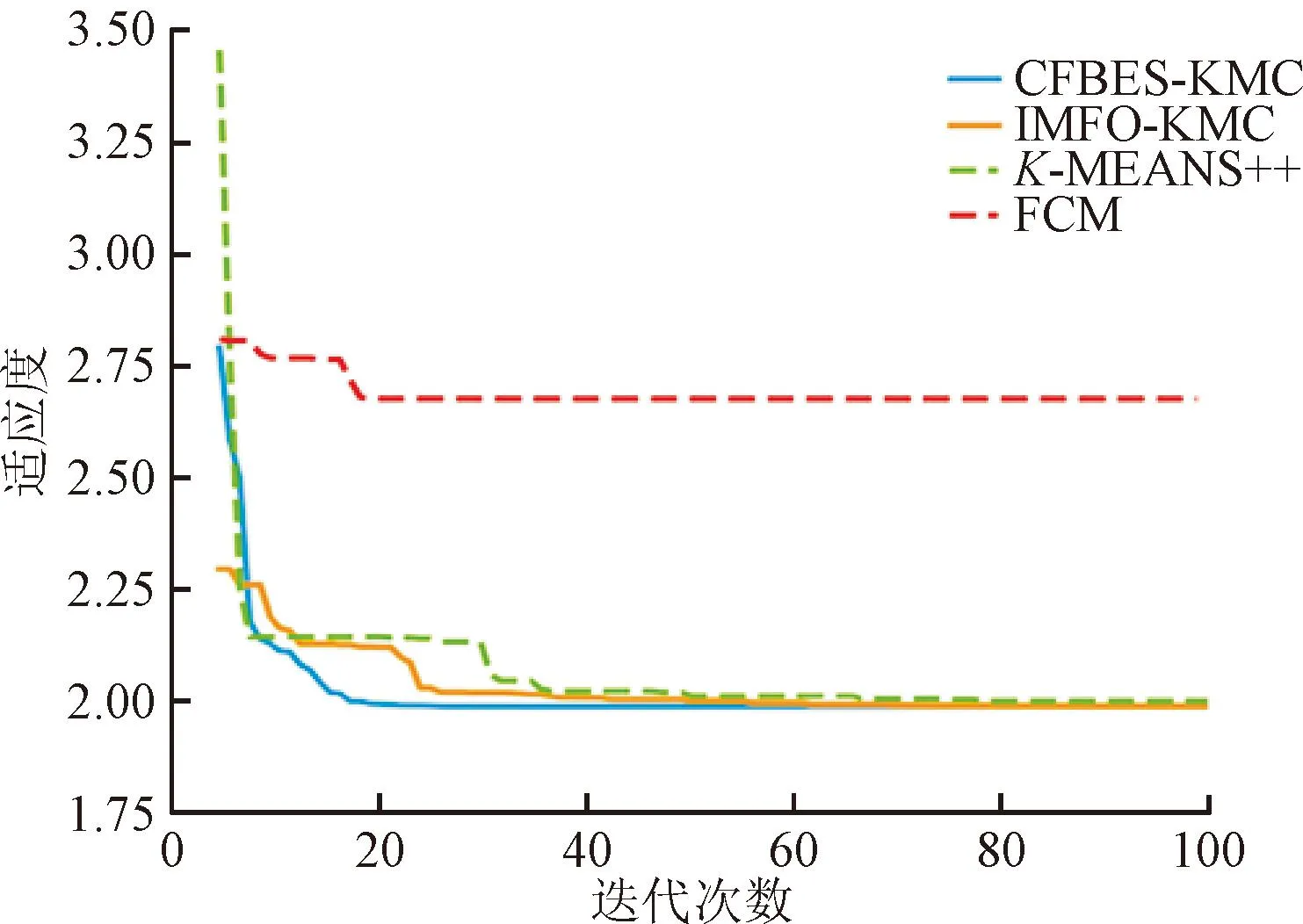
4.2 CFBES-KMC算法总体效果评价




4.3 基于信息熵的CFBES-KMC聚类三维点云简化结果分析










5 结 论
