MSA-Net:一种基于多阶段注意力机制的少样本目标检测方法
2024-01-05汤应薇张荣福
汤应薇,张荣福,丁 然,张 杰
(上海理工大学 光电信息与计算机工程学院,上海 200093)
引言
随着计算机计算性能的提高和深度学习技术的发展,基于传统图像算法进行目标检测的方法逐渐被取代,利用深度卷积网络的框架开始成为主流。但目前深度学习框架过度依赖大量有标注的数据集和迭代次数、学习率等超参数的调节。在现实中,也受各种客观条件的限制,获取大量标签[1]的实验样本数据需要耗费大量的人力物力[2]。鉴于以上难题,研究模型通过少量样本数据训练,能实现快速收敛并在大量样本数据中具有高度泛化性能显得尤为重要。根据对人类认知模式的观察与研究,人类可以通过极少量的图像样本来准确识别一个新物体的所属类别。受这种快速学习方式[3]的启发,基于少样本学习概念的图像处理方法被提出。但目前大部分少样本问题的相关工作集中在图像分类问题上[4–7],对于少样本目标检测问题的研究工作相对较少。由于目标检测问题不仅包括对图像类别的预测,还涉及到对目标的定位问题,这使该任务与少样本分类任务相比复杂度更高。
目前少样本目标检测任务主要采用少样本学习方法结合成熟的深度学习目标检测框架。在少样本学习方法研究初期,大多数模型采用两阶段微调方法提升少量新样本的检测精度。Chen等[8]采用多层深度卷积设计边界框回归策略,抑制在基类训练过程中的过度拟合现象。Wang等[9]在少样本微调阶段,固定特征提取层权重参数,仅微调检测模型的最后一层参数,提高少样本的检测精度和准确率(5%~10%)。但由于在基类训练过程中过度拟合,两阶段微调的方法在微调阶段对新类的检测精度欠佳。因此,后续的少样本目标检测研究融入元学习框架[9–11],将元学习器加入现有的目标检测网络,提高后续特征提取层的有效性。但由于少样本目标检测任务的挑战性,文献[9–11]采用的元学习方式,只是对支持集特征进行全局池化,丢失了局部特征的详细上下文信息,导致无法学习到预测分类和定位的关键特征。因此,后续的研究将两阶段微调和元学习方式结合,提出了Meta-SSD 模型[12]。该模型通过一系列的少样本目标检测任务学习得到一个元学习器,来指导检测器在新任务中快速且准确地更新参数。Meta RCNN 模型[11]将元学习方法和Faster RCNN 框架结合,利用元学习器学习到的可共享参数,帮助新类检测器高效提取特征。
但Faster RCNN 作为一种两阶段检测体系,类无关的区域建议网络(RPN)和类相关的区域卷积神经网络(RCNN)通过共享主干交换优化信息时,可能会因为优化目标的不同产生冲突,导致检测能力下降。文献[13]提出,分类网络注重类间差异的特征,定位网络注重类内差异的特征。不匹配的特征可能会影响RPN 产生许多低质量的目标分数,导致分类能力下降。文献[14–16]研究了特征尺度变化对模型检测精度的影响,由于锚匹配机制,经过特征金字塔后负样本会增加。少量的标注样本也会导致特征提取网络只能提取单一的特征尺度,使得模型对多尺度图像的检测性能下降。在基类训练过程中,丰富的数据可以降低负样本产生的负面影响,但在元微调过程中,新类样本量小,负样本会导致模型对新类学习能力下降。
为解决以上问题,本文基于Faster RCNN 架构,提出了MSA-Net 模型,这一模型对Faster RCNN 进行了3 个方面的改进。(1)加入梯度反传解耦机制:在反向传播过程中,同时对RPN 和RCNN 进行梯度解耦,缓解在反向传播过程中RPN 和RCNN 的冲突对主干网络的负面影响。(2)加入注意力蒸馏模块,利用键–值映射方式,提取支持集和查询集之间的关联信息,过滤掉大多数背景框或类别无关特征。(3)在ROI 池化阶段提出多尺度注意力模块,提取3 种不同尺寸的细粒度特征,并对特征采用自主意力机制,使模型对不同尺度的特征具备更好的泛化能力,便于后续的分类器和回归器工作。大量的实验证明,在k= 1, 2, 3, 5, 10 的设置下,改进后的模型在Pascal VOC[17]的新类上,分别达到21.8%,34.7%,40.9%,44.5%,51.7% 平均精度(mAP)(AP50)。在k= 10, 30 设置下,改进后的模型在COCO[18]数据集的新类上,分别达到25.1%,27.6% mAP(AP50)。
1 相关定义
如图1 所示,遵循文献[11, 19, 20]中的训练范式,基于元学习的少样本目标检测训练包括元训练和元微调阶段。结合文献[21]对元特征学习器 D 的设计,对于一张输入的查询图像q,通过抽样构建对应的支持集S,支持集S包括所有类别的图像–掩膜对,,其中Ii∈Rh×w×3是RGB 图像,Mi∈Rh×w是根据标注边界框生成的掩码图像,N表示类的数量。具体地说,在元训练阶段,先利用有规范标注的基类数据Dbase通过元特征学习器生成查询集–支持集图像对,来训练设计的模型。在元微调阶段,加入样本量少的新类并随机抽选K个样本形成新数据集Dnovel,再采用相同的元特征学习器方式构建训练数据集。元微调训练过程与元训练阶段相同,但微调过程模型收敛速度快,训练次数相对很少。
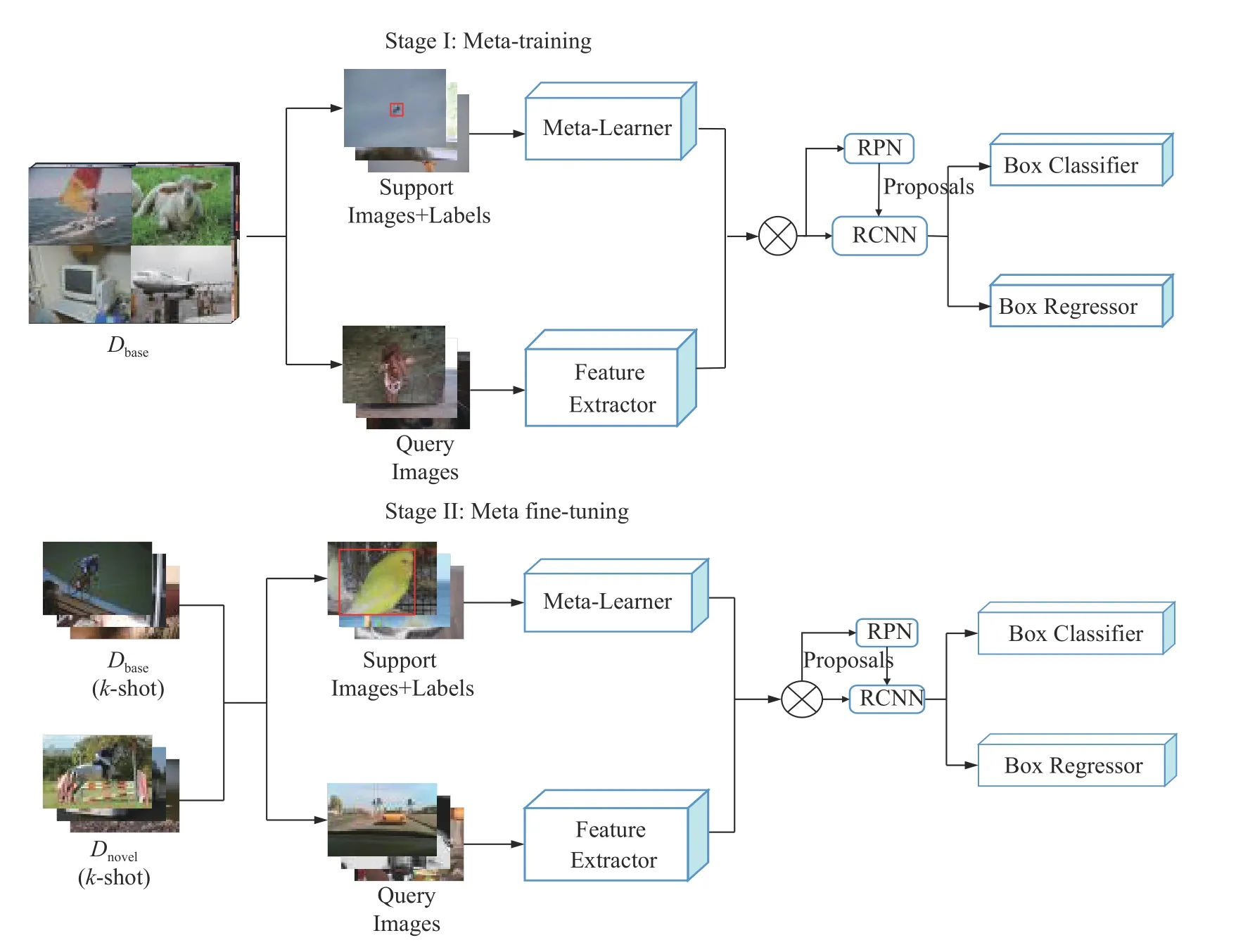
图1 基于元学习的少样本目标检测框架的学习策略Fig. 1 Learning strategy for a few-shot object detection framework based on meta-learning
总体来说,整体模型的输入是一张查询集图像q和从训练集随机抽样得到的支持对,输出是对查询集图像的检测预测。与文献[20]不同,本文并不采用特征重加权模块,而是借鉴文献[11]的方法,采用共享主干网络参数的形式对支持对进行特征提取。
2 MSA-Net
图2 介绍了MSA-Net 模型的体系结构。首先,数据被分为支持集和查询集两部分输入特征提取层,特征提取层采用多尺度特征金字塔结构和ResNet-101 网络。MSA-Net 基于Faster RCNN结构框架,加入梯度反传解耦机制、注意力蒸馏模块以及多尺度注意力模块。
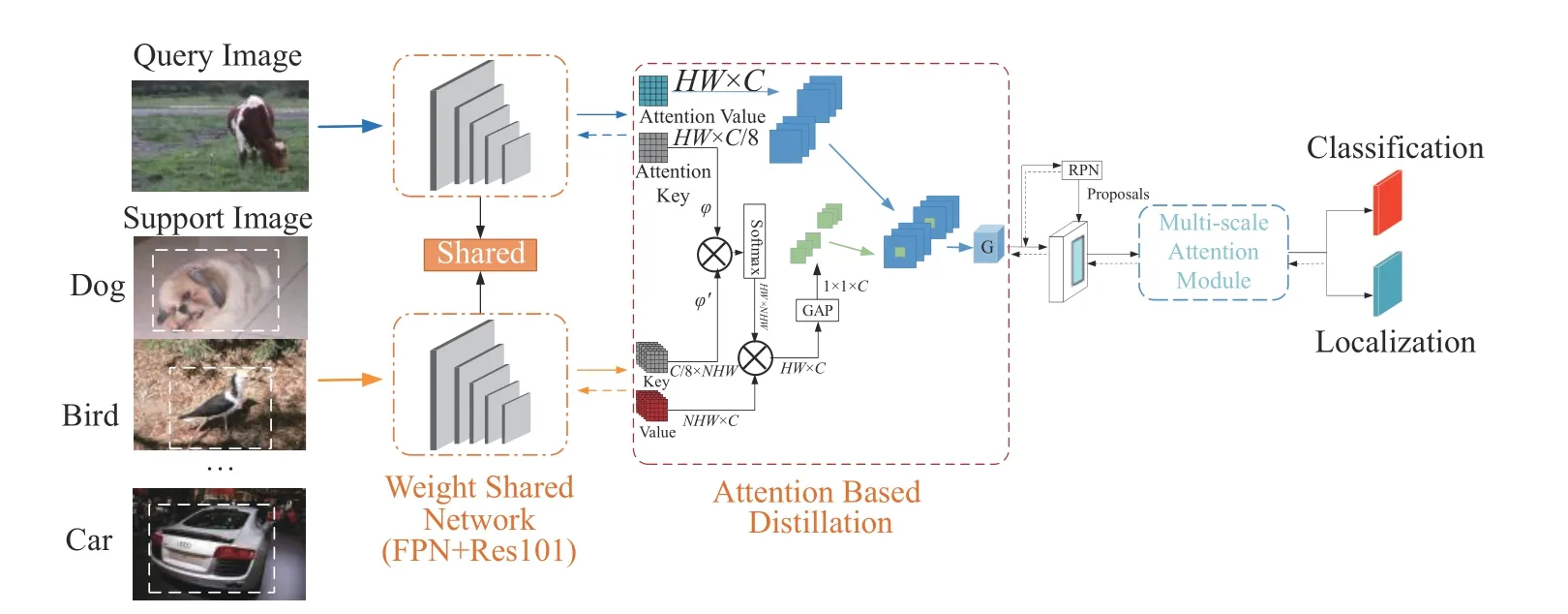
图2 MSA 模型的总体框架Fig. 2 General framework of the MSA model
2.1 梯度反传解耦机制
Faster RCNN 作为一种两阶段检测结构,根据功能可分为3 个组成部分,即提取广义特征的主干网络,用于生成类无关建议的高效RPN,和执行类相关分类和定位任务的RCNN 头。输入图像经过主干网络生成特征映射后,被并行输入RPN 和RCNN。如图3 的梯度流所示,在传统的Faster RCNN 中,RPN 与RCNN 在反向传播过程中,通过共享的主干网络的梯度流,交换优化信息。但RPN 在类不可知的前提下,优化目标是产生定位准确的目标框。RCNN 的优化目标是在已知类相关的前提下,进行目标的定位。这与RPN 的优化目标存在潜在的矛盾,会导致在少样本情况下,模型检测能力下降。受梯度反传过程的启发,本文设计在梯度反传过程中对RPN 和RCNN模块进行解耦(Decoupled-layer),如图4 所示。首先在前向传播过程中,对两个模块分别添加线性变换层A,该线性变换层由权重ω 和偏移b两个可学习变量组成,目的是通过可学习参数的调节,增强特征表示并进行前向解耦。
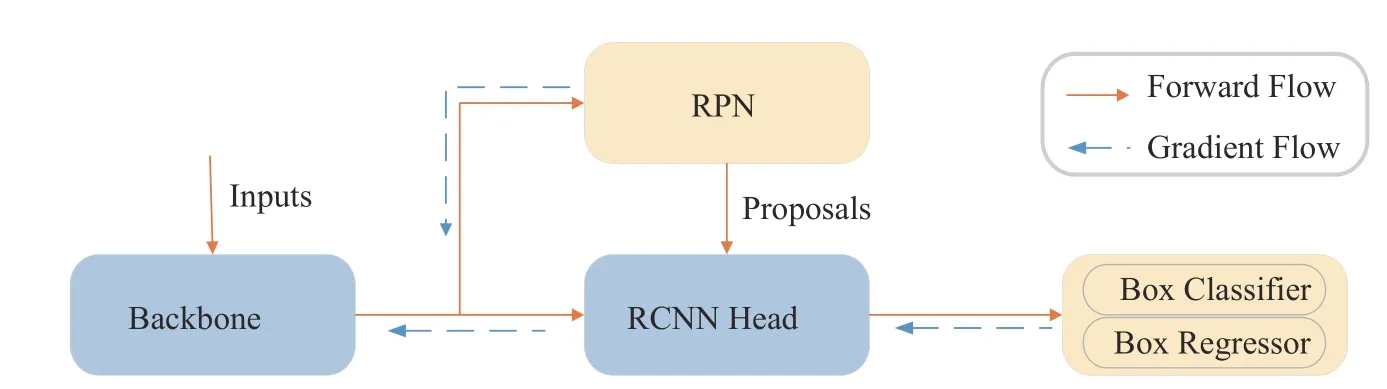
图3 传统的Faster RCNN 架构[22]Fig. 3 Traditional Faster RCNN architecture [22]

图4 梯度反传解耦机制Fig. 4 Gradient backpropagation decoupling mechanism
在梯度反传过程中,为调节3 个模块之间的解耦程度,将RPN 和RCNN 反传的梯度 Grpn和Grcnn,分别乘以解耦系数λrpn,λrcnn向前一层传播。
因此,模型的总优化目标为
式中:N是训练样本的数量; LRPN和 LRCNN是RPN 和RCNN 的网络损失函数; θb,θRPN和θRCNN分别是主干网络、RPN 和RCNN 的学习参数;η 为平衡 LRPN和 LRCNN的超参数,一般设置为1。具体地说,添加的解耦机制并不会影响到RPN 和RCNN 的优化,但主干网络的梯度下降会受机制的影响,可描述为
式中:γ表示学习率;λrpn和λrcnn的取值对主干网络参数 θb的更新有深刻影响。
2.2 注意力蒸馏模块
先前的工作[12,20]采用元学习的方式,对支持集特征进行平均池化操作,抽取类向量来指导查询集元特征学习。但即使是同一类别的样本,输入的查询集和对应的支持集样本,也存在巨大差异(如:尺寸、外观、位置等)。这会对后续的特征学习产生负面影响。面对以上这些问题,本文采用了基于注意力机制的蒸馏模块,从支持集特征中尽量提取足够的细节并通过支持集信息过滤掉无关的背景和负面信息,帮助后续的RPN 和RCNN 进行预测。
键–值对嵌入:在查询集和对应的支持集图像通过共享参数的特征提取器提取特征后,支持集和查询集特征进入注意力蒸馏模块。首先,支持集和查询集样本通过特征提取层提取特征,再分别通过设计的深度编码器生成各自的键–值对。深度编码器由两个并行的 3×3 卷积层组成,对输入特征分别生成键和值的特征映射。虽然两部分的深度编码器采用相同的参数结构,但并不共享参数。键映射应用于检测支持集和查询集特征之间的相似性,而值映射储存了特征的全部信息。通过键的编码和得到的相似性权重,帮助查询集特征和支持集值映射进行匹配和识别。因此,对于查询特征,输出为键–值对特征映射:,其中,C为特征的维数,W和H分别为特征的长和高。对于支持集特征,每个类的特征都独立生成键–值对映射,输出是:,其中N是支持集中类的数量。随后,生成的键–值对被送入关系蒸馏部分,在这一部分中,支持集和查询集的键–值对将被密集匹配,以找到目标对象。
键–值关系蒸馏:在获取映射后,执行键–值关系蒸馏。如图5 所示,通过计算支持集和查询集键-值的相似度来评估支持集特征的软权重,对特征映射的每一像素执行相似度计算,公式为

图5 注意力蒸馏模块Fig. 5 Attention based distillation module
式中:i和j表示查询集和支持集特征的索引号;φ,φ′表示查询集和支持集因训练过程不断变化的参数而形成的动态学习线性相似函数。对像素级特征相似度通过softmax 函数进行归一化来计算匹配权重 W 。
然后,对支持集特征通过生成的软权重进行加权。
式中 ∗ 表示矩阵内积。值得注意的是,支持集包含N个特征,因此产生了N个键–值对,在这里对N个输出的结果进行求和获得最终结果。通过平均池化层(GAP),x∈RH×W×C变为1×1×C的向量。最终,查询集特征y∈RH×W×C与支持集池化后的特征x通过深度交叉相关(Depth-wise Cross Correlation)模块生成最终的注意力特征图。因此,最终的输出公式为
式中G表示最终的注意力特征图。对于支持集最终得到的特征x,被用作内核以深度交叉相关方式在查询集特征y上滑动。
2.3 多尺度注意力机制模块
RCNN 以RPN 的区域建议和特征作为输入,经过ROI 对齐后进行特征池化,用于最后的分类和边界框回归。大部分研究[9–12,20]使用固定的分辨率8 来进行特征池化操作,但这一方式会导致部分关键信息的丢失。传统的目标检测方法往往有大量数据进行基础训练,这种方式可以弥补关键信息的丢失。但少样本条件下,由于每一类的样本只有几张图像,这导致尺度变化对模型检测效果有很大的影响。模型因为泛化能力不够,无法适应新类不同尺度的特征。因此,本文提出多尺度注意力模块(图6),选择4,8,12三种分辨率能帮助模型对不同尺寸的特征具有更好的泛化能力。较大的分辨率通过放大特征,可以捕捉特征详细的上下文语义信息,便于对小目标的识别和检测,而较小的分辨率通过缩放特征尺寸,能捕捉特征的全局信息,有利于识别较大的目标。

图6 多尺度注意力模块Fig. 6 Multi-scale attention module
除此以外,添加了1 种自注意力机制(SEAttetion)[23]对提取的不同分辨率的特征进行特征增强,再进行有效的聚合。SE-Attention 为每个尺度的特征建立注意力分支。对于每一分支,首先进行冻结操作,利用全局池化层获得全局的感受野,然后利用两个全连接层和ReLU 函数进行激活操作,为每个特征通道生成权重,再利用Sigmoid 函数获得0~1 之间的归一化权重,进行重加权,将通道权重加权到先前的特征上。最终,这一模块的输出是不同尺寸特征的加权和。
3 实 验
在本节中,对提出的MSA-Net 模型进行了全面的实验评估来检测模型在少样本目标检测方面的作用。3.1 节介绍了数据集的详细设计和训练策略。3.2 节对MSA-Net 模型在Pascal VOC数据集和COCO 数据集上的表现进行了详细的实验分析。3.3 节对提出的创新模块进行消融实验结果分析。
3.1 数据集和学习策略介绍
数据集:为与其他先进的方法进行公平比较,根据文献[9]的方式构建少样本数据集。对于Pascal VOC 数据集,将VOC 2007trainval set和VOC 2012trainval set 作为训练集,VOC2007test set 作为测试集。评估指标为平均精度(mAP)。具体地,数据集根据目标类型将20 个类随机分为15 个基类和5 个新类。首先在元训练阶段,对基类所有数据进行训练,再在元微调阶段,对每一类别从训练集中随机采样k(k= 1, 2, 3, 5,10)个目标。为保证结果的公平性,对类别进行了3 次随机分组。对于COCO 数据集,将与Pascal VOC 数据集不相交的60 个类作为基类,剩余的20 个类作为新类。使用验证集中标记为minival 的数据作为测试集,其余的验证集和训练集数据作为模型的训练集。训练阶段的设置和Pascal VOC 数据集训练阶段相同,k设置为10, 30。
学习策略:首先,使用Faster RCNN 框架[22]作为基本网络架构,采用具有特征金字塔网络[14]的ResNet-101 作为特征提取器。主干网络的权重在ImageNet [24]上进行预训练。本文使用一块24G 显存的3090 GPU 对模型进行训练,最小批处理大小设置为4。所有模型都使用SGD优化器,动量设置为0.9,权重衰减为0.000 1。在Pascal VOC 数据集的基类训练期间,对模型分别进行240 000、120 000 和80 000 次迭代的训练,学习率分别为0.001、0.000 1 和0.000 01。在元微调阶段,模型分别经过2 000、1 600 和800 次迭代的训练,学习率分别为0.001、0.000 1和0.000 01。对于MS COCO 数据集,在训练期间,模型分别进行56 000、36 000 和12 000 次迭代的训练,学习率与VOC 训练设计相同。在元微调过程中,对模型进行3 000、1 000 和500 次迭代的微调训练。除此以外,对于引入的参数λ,根据文献[12]的实验结果,在RPN 和RCNN 的梯度反传过程中分别设置为0 和0.75,元微调训练期间分别设置为0 和0.01。
3.2 实验结果及对比
在本节中,将在PASCAL VOC 和COCO 数据集上进行实验,并将本文的方法与最先进的方法进行比较。
经过多次随机运行,在表1中给出了3 种不同数据分割的VOC 数据集在新类上的平均评估结果。其中k-shot 检测是根据3 种不同的数据拆分设置k= 1, 2, 3, 5, 10 进行的。本文给出了新类在不同拆分下IoU 阈值为0.5(AP50)的mAP。具体来说,在k=1 设置下,本文的方法表现远优于FRCN 和LSTD这类模型,也优于Meta RCNN和TFA 模型的表现。虽然MSA-Net 在split 2 和split 3 中分别低于FSDet(2021)和Repmet,但在k= 2, 3 设置下,在3 种不同的分类中,其表现远优于两阶段微调方法,也优于其他加入元学习框架的模型。在k= 5, 10 设置下的表现也优于其他模型,虽然检测精度提升没有k=2, 3 设置下明显。可以看出,在同样的评估体系下,本文提出的MSA-Net 在PASCAL VOC 数据集的新类上表现均优于目前的一些先进方法,这证明了改进方法的有效性。但由于PASCAL VOC数据集的数据量仅包括大约5 000 张图像数据,对于目标检测任务来说,该数据集图像数量过少,仅能作为其中一个评估维度来评估模型,并不具有绝对性。
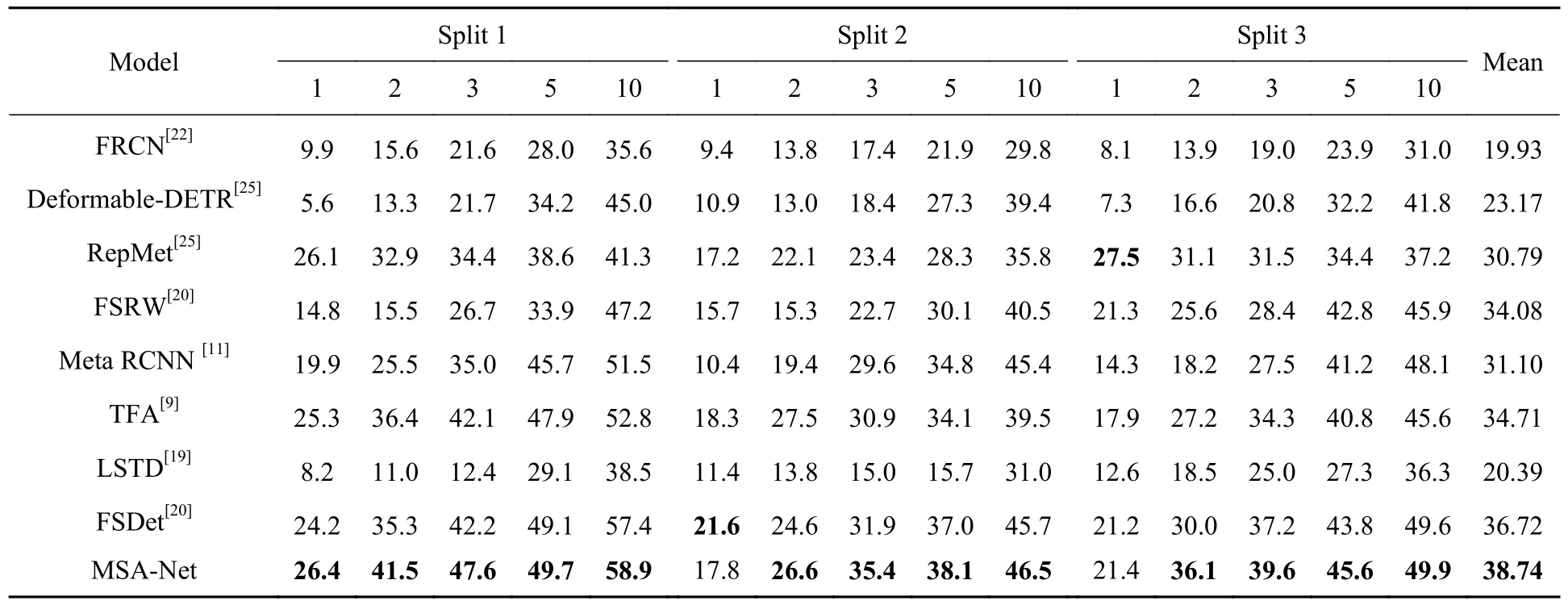
表1 在VOC 2007 测试集上的少样本目标检测表现Tab. 1 Few-shot object detection performance on VOC 2007 test set
MS COCO 数据集包括80 个类别,大约12 万张图像,与Pascal VOC 数据集相比,检测的图像更加复杂多样,因此实验结果也更具说服力。表2 展示了MSA-Net 在MS COCO数据集的表现。可以看出,在k= 10 设置下,MSA-Net模型的所有度量标准均优于其他方法。在k=30 设置下,虽然基于文字和图像的多模态模型SRR-FSD 在AP50 的度量标准下检测精度更高,但在更严格的度量标准AP75 下,检测精度远低于MSA-Net。这表明MSA-Net 模型通过改进的模块,可以有效地缓解RPN 错误的区域建议的问题,从而产生更准确的检测结果。在k=30 设置下,采用Transformer架构的Deformable DETR[28]在度量标准 AP 下检测精度略高于MSANet,但其他度量标准以及最终的平均检测精度远低于MSA-Net。除此以外,MSA-Net 的平均检测精度在所有指标上都高于其他现有的方法如FSCE 和MPSR 模型,这意味着MSA-Net 在少样本情况下具有很强的鲁棒性和泛化能力。

表2 在MS COCO 测试集上的少样本目标检测表现Tab. 2 Few-shot object detection performance on MS COCO test set
4 消融实验
模块的有效性:对提出的模块在VOC 2007 test set split 1 数据集上进行全面的消融研究,以验证设计的有效性。所有结果均为5 次随机运行的平均值。表3 列出了所有的结果。可以看出,由于缺少数据,原始的FRCN 模型严重过拟合。具体地,采用逐步渐进的方式探索每一个模块的效果。(1)在加入梯度反传解耦机制后,模型效果在基类上提升了12.3%,在新类上有4.0%的提升,这表明RPN 和RCNN 模块的解耦,提高了模型的泛化能力,这一结果与我们提出的观点一致。(2)在加入注意力蒸馏模块后,模型在新类的效果有显著的提升(7.3%~11.5% mAP),这表明这一蒸馏模块利用了有限的数据中的有效信息,缓解了过拟合现象。(3)在单独加入多尺度注意力机制后,模型相较于单独加入注意力蒸馏模块的提升较小(5.1%~9.8% mAP),但同时加入注意力蒸馏模块和多尺度注意力机制模块对模型的提升十分显著,将近20% mAP,这表明模型可以通过学习不同尺寸的相同特征,增强对特征细节的学习,提升检测精度。(4)从总体上看,加入改进的模块后,模型在新类上的检测精度达到平均22.6%的提升,在k= 2, 3 的设置下,提升接近26%,可以看出,在少样本设置下,改进的模型泛化能力显著增强,且3 个改进模块之间的交互并不会对模型检测精度产生负面影响。
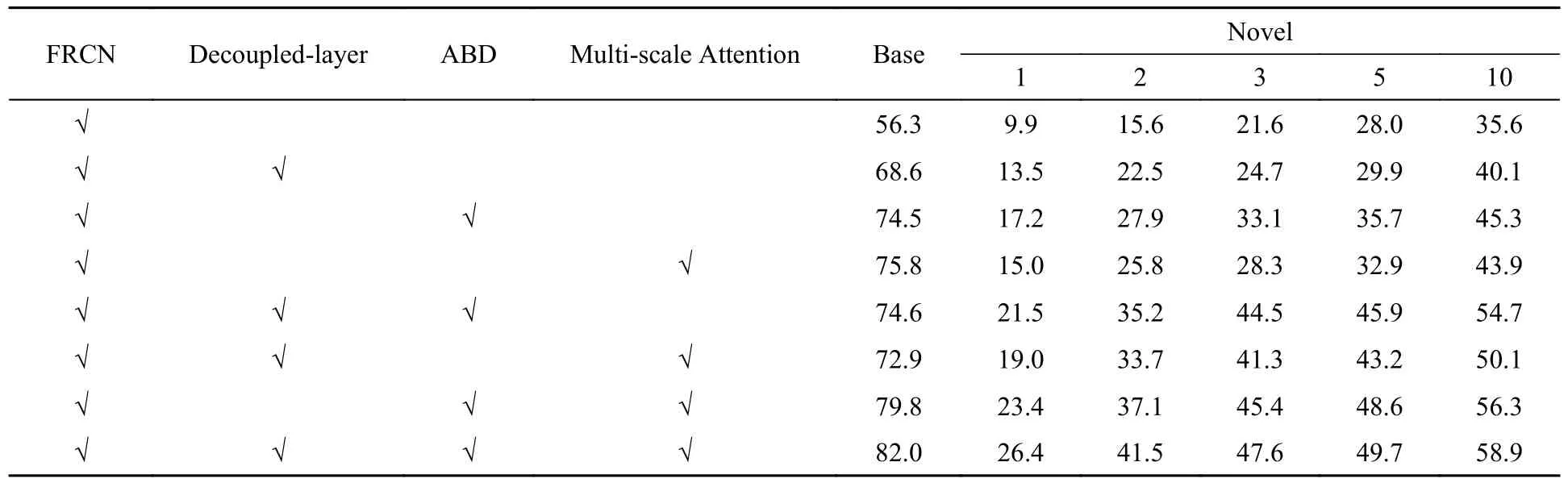
表3 改进的模块对模型mAP(AP50)的影响Tab. 3 Effect of improved modules on mAP (AP50)
图7 所示为采用MS COCO 数据集训练后的模型在PASCAL VOC 部分样例图像上测试的结果。可以看出MSA-Net 模型的检测效果明显优于原始FRCN 模型两阶段微调后的结果,能够检测出部分小目标物体,检测新类的置信度也有一定程度的提高。

图7 MS COCO 10-shot 设置下训练的模型在VOC 2007 数据集上的示例Fig. 7 Example of a model trained under MS COCO 10-shot setting on VOC 2007 dataset
5 结束语
本文对少样本目标检测任务进行了探索,提出了基于多阶段注意力机制的少样本目标检测模型MSA-Net。模型引进了梯度解耦模块缓解RPN 和RCNN 潜在的矛盾,此外,ABD 模块和Multi-scale 模块充分利用查询集和支持集的特征信息提高模型的泛化性能。尽管简单,但本文的方法在少样本目标检测的各种基准上达到了先进水平,并通过消融实验验证了模型的有效性。
