自然场景盲文图像数据集及盲文段检测方法
2023-10-17卢利琼陈长江吴东熊建芳
卢利琼,陈长江,吴东,熊建芳
(1.岭南师范学院 计算机与智能教育学院,广东 湛江 524048;2.广东省特殊儿童发展与教育重点实验室,广东 湛江 524048)
0 概述
据中国残联数据显示,目前中国视障群体超过1 800万,人数位居全球第一[1]。盲人和视障人士通过盲文来学习和交流,盲文是路易斯·布莱叶于1824 年在法国的一所盲人学校里所发明,通过触觉获取信息。盲文由盲文字符(也叫盲方)组成,盲文字符由6 个固定位置的盲点按一定出现顺序组成,一共有63 种组合方式[2]。
盲文是盲人朋友用来学习技能、了解世界以及与人沟通交流的重要媒介[3]。但是,正常人对盲文的了解很少,导致他们与盲人朋友的沟通和交流非常困难。盲文检测是利用人工智能技术从图像中读取盲文位置,是盲文识别的前置步骤。盲文检测方法可以直接应用于盲文书籍电子化、盲文自动阅卷等方面,也可以帮助正常人和盲人进行无障碍交流,如特殊教育工作者检查盲人学生的作业、盲人的父母和朋友查看盲人的读书笔记等。
盲文属于小众语言,现有对盲文检测的研究并不多,且主要集中在扫描文档图像上[4-5]。盲文检测技术按研究对象的不同可以分为盲点检测方法和盲文字符检测方法。扫描图像中检测盲点的方法主要分为两类,一类是基于图像分割的盲点检测方法,另一类是将挖掘盲点特性与机器学习分类方法相结合的盲点检测方法。
基于图像分割的方法首先使用局部自适应阈值将盲文图像的像素分割成阴影、光线和背景这3 个部分,然后通过3 个部分的组合规则来检测盲文点[6-7]。此类盲文点检测方法对阈值较为敏感,且通过多个步骤才能得到检测目标,容易产生累计错误[8]。
为了避免上述问题,第二类盲文点检测方法通过挖掘盲点特征和分类算法来直接检测盲点,常见的盲点特征挖掘和分类算法有Haar+SVM(Support Vector Machines)[9]、HOG(Histogram of Oriented Gradient)+SVM[10-11]、(Haar,LBP(Local Binary Pattern),HOG)+Adaboost[12]等。另外,MORGAVI等[13]使用简单的神经网络来检测盲点,VENUGOPAL-WAIRAGADE[14]使用Hough 变换进行圆形检测以找到盲点。这些方法虽然能直接检出盲点,但是需要将多个盲点进行组合得到盲文字符,依然存在多步骤导致累计错误的问题。近年来开始出现直接检测盲文字符的方法,RONNEBERGER等[15]使用改进U-Net 架构的分割神经网络从像素级别检验某像素是否属于盲文字符,随后聚合相邻像素后得到盲文字符区域[16]。
现有盲文检测方法只针对扫描文档图像,但是随时随地扫描文档图像非常困难,而使用智能摄像设备(如智能手机)随时随地拍摄盲文图像则极为便利。因此,自然场景图像中的盲文检测会成为一个更主流的应用场景。另外,从盲文语义识别的角度来看,盲文字符在识别过程中需要参考其前后的字符,而现有的盲文检测方法多是针对盲点和盲文字符,如果检测的盲文字符不连续,就会导致识别过程出错,而盲文段检测是一个更好的选择。
本文构造一个自然场景盲文图像数据集,该数据集中的所有图像都是使用智能设备拍摄而来,并对数据集中的图像在亮度、对比度和柔和度方面进行增强处理,扩充数据集以提高卷积神经网络(Convolutional Neural Network,CNN)训练模型的普适性。随后基于CNN 技术,以ResNet50[17]作为主干网络,分析自然场景图像中盲文的特点,通过设计多尺寸特征融合策略和锚框相关参数来检测不同尺寸的盲文段,基于Faster R-CNN[18]的基本框架提出一种自然场景图像中的盲文段检测方法。在所提自然场景盲文图像数据集上对该盲文段检测方法进行性能测试,并将其与经典的自然场景目标检测算法Faster R-CNN 和SSD[19]进行对比。
1 自然场景盲文图像数据集
本文构造的自然场景盲文图像数据集的图像来源主要有2种,一是从网络上下载,二是使用智能拍摄设备进行拍摄。该数据集中共有图像554幅,其中80%用于训练集,20%用于测试集。
由于所有图像均在自然场景下拍摄,图像的背景、颜色、盲文尺寸以及光线等差异较大,特别是有些图像中盲文与背景混杂在一起,导致盲文检测极其困难。图1 所示为该数据集中的部分盲文图像。

图1 自然场景盲文图像Fig.1 Natural scene Braille images
从图1 可以看出:自然场景中的盲文可以出现在不同颜色、不同材质、不同光线和不同形式的背景上,如广告牌、电梯指示牌、水管和货币等;盲文在图像中的位置、盲文尺寸、排列和呈现形式的变化也较大。除此之外,图像中的盲文往往以段的方式隔开,这与盲文书写和识别形式基本一致。为了推进自然场景盲文识别工作,本文将该自然场景盲文图像数据集共享在百度网盘上,对应的链接为https://pan.baidu.com/s/1WyLDJKfJb0f884FiIi12Gw?pwd=wqan,以供有兴趣的研究人员免费使用。
由于自然场景中的图像在光线、模糊度、对比度以及柔和度方面存在较大差异,因此自然场景中的盲文图像可能出现光照过强或过弱、明暗反差不足或严重以及拍摄模糊等情况。为了增强盲文段检测的容错性、健壮性和抗干扰性,本文对数据集的图像进行增强处理,以对数据集进行扩充,满足CNN 训练需求,提升数据集的普适性。图2 所示为样例图像经过数据增强后生成的6 幅图像,在图像增强后,554 张原始采集盲文图像加上数据增强后生成的图像,数据集中的盲文图像共有554+554×6=3 878张,满足CNN 训练的需求。

图2 图像增强效果Fig.2 Images enhancement effect
盲文图像数据集文件夹的目录结构如图3 所示。Braille_img 中存放所有自然场景盲文图像,Braille_img_augment 中存放数据增强后的所有图像。Braille_img_xml 和Braille_img_augment_xml 分别对应VOC 格式的原图像标签文件和数据增强后图像的标签文件。train.txt 和test.txt 中分别记录了用做训练集和测试集的图像名称。

图3 自然场景盲文图像数据集目录结构Fig.3 Directory structure of natural scene Braille image dataset
2 自然场景盲文段检测方法
自然场景图像中的盲文与其他对象类似,都有较复杂的背景、不均匀的光线以及颜色和尺寸变化大等特点[20-21]。近年来,CNN 在自然场景对象检测领域取得了优异的成绩[22-23],因此,可以尝试用CNN来挖掘自然场景图像中的盲文特征[24-25]。本文进一步分析自然场景盲文段与其他对象的不同之处,特别是在书写形式和结构方面,发现自然场景盲文段在呈现形式上多为狭长形状,盲文段在高度上变化较小,但是在宽度上变化较大,且有不同尺寸盲文段出现在各类背景上。因此,如何较好地检测出自然场景中多尺寸、狭长状的盲文段是本文需要解决的关键问题。
本文受Faster R-CNN 算法的启发,以ResNet50作为主干网络,首先提出多尺寸CNN 特征融合策略和锚框参数来挖掘多尺寸盲文特征,然后设计盲文分类、位置回归损失函数来训练CNN 得到自然场景盲文段检测模型,最后根据训练得到的模型设计盲文段预测方法。
2.1 总体框架
图4 所示为本文盲文段检测方法的总体框架示意图。

图4 本文方法总体框架Fig.4 Overall framework of the method in this paper
首先以ResNet50 作为CNN 主干网络,利用式(1)对不同大小的特征层fi进行特征融合后变成hi,然后在大小为(W/4×H/4)的特征层后添加RPN 网络获取初步的建议框(Proposals),将建议框和特征层h4经过RoI Pooling 处理后形成建议框特征层(Proposal feature maps),最后在建议框特征层上预测盲文段文本框的精确位置信息(bbox_pred)和分类信息(cls_prob)。在本文盲文段检测方法中,盲文段的位置使用矩形框来表示,采用矩形框中心点的坐标、宽和高来进行几何表示。盲文段的分类结果则分为两类,即盲文段和非盲文段。
2.2 锚框参数设计
与Faster R-CNN 类似,本文算法也在CNN 特征层的每个像素上设置不同大小、不同宽高比的锚框来模拟多尺寸盲文段的位置,然后利用CNN 来预测真实盲文段矩形框与锚框在中心点坐标、宽和高方面的差异。本文分析自然场景图像中的盲文在呈现形式上多为狭长形状,且盲文段在高度上变化较小,但是在宽度上变化较大。另外,有部分小尺寸盲文段只由1 或2 个盲文字符组成,在整幅图像中所占像素点极少。根据目标检测领域通用数据集COCO 对物体大小的定义[26],在图像中小于32×32 个像素点的物体被称为小尺寸目标,且小尺寸目标存在难以分辨、携带特征少等问题,容易被CNN 模型忽略,从而造成漏检情况。在自然场景盲文图像中,有多尺寸目标同时存在于一幅图像中的情况,如图5 所示,该图中左侧电梯按钮中的盲文所占面积均小于32×32 像素,属于小尺寸目标,而右侧按钮上的盲文段尺寸相对大很多。

图5 包含小尺寸盲文段的自然场景图像Fig.5 Natural scene image containing small Braille segments
本文根据自然场景盲文段的特点来设计锚框参数:首先将锚框的基本尺寸设计为32×32、64×64、128×128、256×256、512×512 这5 种;然后基本尺寸的锚框都按照面积不变以及长宽比分别为1∶1、2∶1 和3∶1 的方式再生成3 种锚框;最后在RPN 网络特征层的每一个像素点上都生成重新设计的15 种锚框。这些不同尺寸的锚框对应到原始图像上,基本上可以包含所有盲文段目标。后续实验结果证明,本文设计的锚框参数能够有效地从图像中检测出不同尺寸的盲文段目标。
2.3 损失函数设计
本文方法根据建议框特征层的输出来设计损失函数。损失函数主要包括2 个方面:
1)盲文段分类损失。盲文段分成0 和1 两类,0表示非盲文段,1 表示盲文段,在计算损失函数时先使用Softmax 函数计算出目标是盲文段的概率,随后针对概率计算交叉熵损失。
2)盲文段矩形框位置回归损失,该损失采用SmoothL1函数。与Faster R-CNN 类似,本文使用矩形框中心点坐标、宽和高(x,y,w,h)来表示盲文段位置,并利用预测框和锚框位置的参数化差值、真实盲文段矩形框和锚框位置的参数化差值来计算回归损失。
本文方法总的损失函数如式(2)所示:
其中:Lcls和Lreg分别表示分类和回归损失;pi和pi*分别表示目标是盲文段的预测概率和实际概率;ti和ti*参数的含义与Faster R-CNN 相同,分别表示盲文段位置预测向量(x,y,w,h)与锚框位置向量的参数化差值、真实盲文段矩形框位置向量与锚框位置向量的参数化差值;Ncls和Nreg分别表示预测盲文段矩形框分类和位置回归的总数目;λ用来平衡分类损失和回归损失,取值为Nreg/Ncls。
式(3)~式(5)表示Lcls和Lreg的具体计算方法,分别对应交叉熵损失函数和SmoothL1函数的具体计算方法:
2.4 盲文段预测
在盲文图像预测阶段,首先使用Resize 函数将输入图像调整到600×600 像素,随后将调整后的图像送入已经训练好的CNN 网络模型,得到cls_prob和bbox_prd,其中,cls_prob 存放的是预测矩形框分类的概率,box_pred 存放的是预测矩形框的位置信息和对应的置信度。对于所有盲文分类概率大于0.5 的预测矩形框,采用NMS 算法[27]过滤掉面积重叠的矩形框后得到最终的预测结果。在本文算法中,设置NMS 算法IOU 阈值为0.4,预测矩形框置信度的阈值设置为0.5,详细预测过程如算法1 所示。
算法1盲文段预测阶段处理过程
输入ImageI,CNN_trained_model
输出the list of Braille character rectanglesR
1.R=[]
R_predict=[]//参数初始化
2.cls_prob,bbox_pred=CNN_trained_model(Resize(I,(600,600)))
//根据训练的模型得到预测初始值
3.for each cls_value,bbox_value in range(cls_prob,bbox_pred)//循环处理
4.if cls_value >0.5 then
//获取预测分类概率大于0.5 对应的矩形框位置信息
5.R_predict.append(bbox_value)
6.end if
7.R=NMS(R_predict,IOU_thresholed=0.4,Score_threshold=0.5)
//调 用NMS 算法后处理
8.return R
3 实验验证
本文采用深度学习框架TensorFlow[28]并基于GPU 2080ti 实现所有算法。在训练过程中,所有CNN 均采用SGD(Stochastic Gradient Descent)进行优化,学习率设置为1×10-4,batch size 设置为8,训练总次数设置为100 epoch。在所提自然场景盲文图像数据集上,对本文盲文段检测算法与目标检测领域经典的算法SSD 和Faster R-CNN 进行比较和分析。
3.1 盲文段检测性能评估方法
采用文本检测领域经典的准确率(P)、回归率(R)和综合指标(Hmean 值)来评价盲文段检测性能。准确率表示正确预测的盲文段矩形框个数占所有预测出来的盲文段矩形框个数的百分比,如果某个盲文段检测框与真实框面积的IOU 大于0.5,就认为该盲文段矩形框是被正确检测的。回归率表示盲文段真实框被正确预测的百分比,其值为正确预测盲文段个数除以所有盲文段真实框的个数。Hmean 是一个综合指标,其值由P和R计算而来。P、R和Hmean的计算方法如下:
其中:TTP表示正确预测盲文段文本框的个数;FFP表示错误预测的个数;FFN表示检测方法漏检的个数。
3.2 盲文段检测性能比较分析
将本文自然场景盲文段检测算法与目标识别领域经典检测算法SSD 和Faster R-CNN 在所提自然场景盲文图像数据集上进行比较和分析,实验结果如表1 所示,最优结果加粗标注。从表1 可以看出,本文检测算法的准确率为0.839 7,回归率为0.941 9,综合指标Hmean 值为0.887 9。与SSD 和Faster R-CNN 相比,本文自然场景盲文段检测算法在准确率、回归率和Hmean 值上均较优,特别是在回归率指标上,本文算法提升效果尤为明显。本文同时也使用VGG16 作为主干网络进行实验对比,从表1 也可以看出,与使用ResNet50 作为主干网络相比,使用VGG16 作为主干网络时检测性能稍差一点,但是也远高于SSD 和Faster R-CNN 的检测性能。
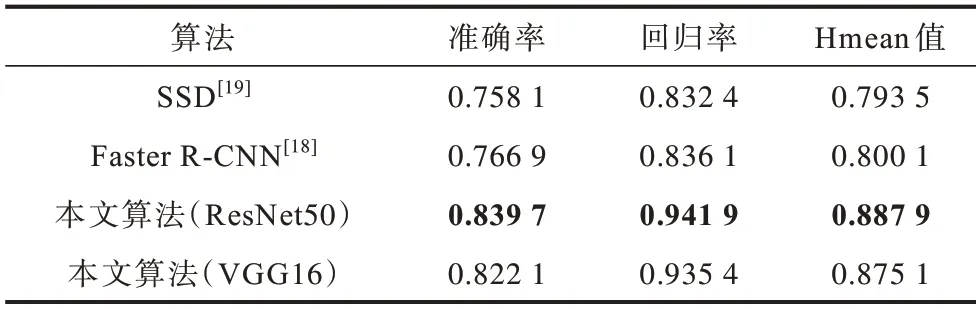
表1 3 种算法的检测性能对比Table 1 Comparison of detection performance of three algorithms
本文盲文段检测算法是根据自然场景盲文的特点和Faster R-CNN 的基本框架而提出,与Faster R-CNN 相比,本文检测算法主要有3 个方面的改进:一是使用ResNet50 作为主干网络,并设计不同尺寸特征层融合策略,以有效挖掘多尺寸盲文段的特征;二是与自然场景盲文特点相结合后设计合理的锚框大小和宽高比;三是设计针对亮度、对比度和柔和度的图像增强方法,增强盲文段检测的容错性、健壮性和抗干扰性,以应对自然场景光线、背景和场景多变的情况。图6 所示为Faster R-CNN 和本文算法针对同一幅图像的检测结果。从图6 可以看出,本文检测算法能够检测出更多的盲文段,特别是小尺寸盲文段,这也说明本文针对自然场景盲文特点而引入的以上设计思想是正确且有效的。

图6 2 种算法针对同一幅图像的检测结果Fig.6 Detection results of two algorithms for the same image
3.3 盲文段检测样例分析
为了更加直观地呈现本文算法的检测效果,图7和图8 分别列出本文算法正确检测图像样例和检测不完整的图像样例,其中,用矩形框标记出了盲文段矩形框的检测位置和置信度。从图7 标记的检测结果可以看出,本文算法在光线不均、盲文尺寸和盲文段颜色变化大、图像背景复杂甚至盲文点与背景融合在一起时,都能准确有效地检测出盲文段所在的位置。从图8 的检测结果可以看出,本文检测算法还存在一些不足的地方,当盲文段特别长时,会遗漏一部分检测结果,当图像中的盲文呈非水平方向时,使用水平矩形框去识别位置会导致后续盲文识别出现错误,还有一些特别小的盲文段存在漏检的情况。后续拟针对这些情况进一步改进算法。

图7 本文算法正确检测的图像样例Fig.7 Sample images correctly detected by the algorithm in this paper

图8 盲文段检测不完整的图像样例Fig.8 Sample images with incomplete Braille segment detection
4 结束语
现有盲文检测方法应用场景单一且只针对盲文扫描图像,对于自然场景图像中的盲文检测相关研究较少。此外,现有大多数盲文检测方法都是针对盲文点和盲文字符,难以给后续盲文识别阶段提供有效输入。本文首先通过Internet、手机和智能拍摄设备获得554 幅自然场景盲文图像,构成自然场景盲文图像数据集,并通过labelme 工具对图像中的盲文段位置进行标记。随后分析自然场景盲文段的特点,基于Faster R-CNN 的基本框架,以ResNet50 作为主干网络,设计多尺度特征融合策略、锚框参数和图像增强策略,提出一种自然场景盲文段检测算法。在所提自然场景盲文图像数据集上进行实验,结果表明,与目标识别领域经典算法SSD和Faster R-CNN相比,该算法检测性能提升明显,Hmean 值达到0.887 9。进一步分析盲文段图像检测样例,发现本文所提算法在盲文段特别长、尺寸特别小、盲文段非水平时存在漏检和检测不完整的情况。后续将结合注意力机制进一步挖掘自然场景图像中盲文段的特征,设计与盲文段尺寸相关的损失函数以及多方向矩形框,对盲文段进行几何表示,以检测出更多的多尺寸和非水平方向的盲文段。
