大数据百科条目多语种翻译的工作理念和方法
2023-09-26杜家利于屏方黄建华牛子牧
杜家利 于屏方 黄建华 杨 可 吴 凡 牛子牧
(1. 广东外语外贸大学外国语言学及应用语言学研究中心,广东广州 510420;2. 广东外语外贸大学中国语言文化学院广东广州 510420;3.广东外语外贸大学西方语言文化学院,广东广州 510420;4. 广东外语外贸大学亚非语言文化学院,广东广州 510420)
0 引言
与时俱进地推动科技名词规范化工作具有重要意义[1]。大数据发展的特殊性决定了其研究的高标准性。全国科学技术名词审定委员会(以下简称“名词委”)作为代表国家审定和公布科技名词的权威性机构,与北京国际城市发展研究院合作,及时审定公布了国内权威的大数据百科条目,并制定了相关的大数据研究标准。大数据百科条目框架包括大数据理论、大数据战略、大数据技术、数字经济、数字金融、数据治理、大数据安全、数权法、大数据史九个部分。
大数据研究具有促进科技发展的重要性。作为术语研究的新兴领域,大数据研究是在蒸汽技术革命、电力技术革命和计算机信息技术革命之后的第四次革命。新兴的大数据百科条目往往承载着特定领域的专业概念,并具有高度浓缩的胶囊化特点。作为全球第二大经济体的中国,大数据条目的中国元素也得到越来越广泛的关注。大数据领域的深入研究可进一步完善我国相关领域的学科知识体系建设,更好地实现大数据技术在各领域的应用。因其具有新兴科技领域的前沿性和前瞻性,可为我国在科技应用方面赶超或保持国际前沿奠定基础。
人工智能方面,得语言者得天下[2]。大数据研究的目标在于推动人工智能发展,并在国际化进程中争夺我国在大数据领域的国际话语权。名词委积极推动大数据百科条目的多语化进程,并在“十三五”阶段实现了大数据百科条目的英语翻译、法语翻译、俄语翻译、西班牙语翻译和阿拉伯语翻译,相关研究已经纳入“术语在线”知识库体系中。我们团队受名词委的委托,完成了大数据百科条目联合国工作语言的翻译实践,形成了较为有效的多语种翻译工作理念和研究方法。本研究将分析这些工作理念和方法的得失,增强其在指导实践方面的价值。
1 百科条目研究现状
大数据百科条目多语种翻译是跨学科研究,属于术语和翻译相交叉的范畴。百科条目的词条审定、释义、示例等均具有明显的术语学特点。从汉语条目到英语、法语、俄语、西班牙语和阿拉伯语的平行翻译则属于翻译学范畴。我们的研究主要关注的是大数据百科条目的多语种翻译。
大数据百科条目分类是在条目分类目录下采用简注方式展开的。专业百科全书设置条目分类目录,是编纂者导引读者打开百科全书知识宝库的锁钥[3]。大数据发展的新兴特点决定了很多条目虽未发展到术语命名的严格程度,但与普通名词有显著区别。
百科条目通常分为自然科学条目(习称科技条目)和社会科学条目(习称哲社条目)两部分[4]。名词委审定的大数据百科条目涉及这两部分内容。自然科学条目和社会科学条目在同一框架中出现,是一个事物的两个方面,而不是对立的。就像语文词典可能收录一些百科条目或百科词典可能收录一些语词条目一样[5]。在立目方面,名词委根据大数据复杂词汇单位的自身特点采取了适当的立目策略,将词目与释文的左右项关系较好地融合在一起[6-7]。更为重要的是,名词委在大数据百科条目审定中既关注了国际性,又融入了民族性,将大数据中国元素纳入大数据百科条目分类框架,较好地平衡了大数据百科条目的国际性和民族性,为研究者提供了研究大数据条目的社会和历史线索[8-11]。
新兴领域的百科条目需要给予关注。大数据等新兴领域的百科条目对国内知识文化将产生强烈冲击[12]。这些新兴百科知识提升了读者的认知,推动了语言发展的增词和增义[13],提高了新兴领域百科条目在词典中的收词概率,进而推动词典编纂与时俱进[14]。新增大数据百科条目体现了术语审定和辞书编撰的前沿性,在百科条目研究中占据前沿地位。
我们对中国知网(CNKI)中的“百科条目”主题进行了综述性回顾。在系统提供的265条检索项中,“百科条目”的讨论主要分为两大类:定量类和定性类。
定量类集中在信息工程领域,从量化视角对百科条目的收词、评价、描述、聚类等给予关注。例如,季一木等[15]基于百度百科数据验证了多决策模型的质量评价方法,为百科词条的可行性、合理性和有效性进行了质量评价,取得了较好的效果。李明泽等[16]在“线索利用理论”框架下验证了词条内容质量和词条描述质量均可正向影响词条感知质量的判断;用户对百科词条的知识熟悉度比较高的时候,词条内容质量将显著影响词条感知质量。温田田[17]从网络百科词条编辑冲突角度入手,分析了百科词条编纂者的价值期望,讨论了主观倾向对合作动机的影响。黄令贺等[18]对百科词条质量评价进行了信息分析。于娟和曹晓[19]验证了本体概念聚类方法,进一步探讨了百科词条的领域概念之间的语义关系。尹坤等[20]利用SimRank算法计算了百科词条的语义相似度,并借此准确地反映词语之间的语义关系。
定性类集中在词典编纂、图书出版、百科收词、条目审查等领域。例如,中国百科条目“老子”在维基百科全书的协同编纂中实现了跨文化的域外传播和视域融合[21]。《英汉大词典》(第2版)的百科条目从微观结构、语义与概念的关联、宏观结构三个层面实现了增补修订[22]。在词条编撰的著作权认定方面,网络百科词条在编纂模式、独创性判定、著作权归属及侵权规则方面呈现了不同于传统模式的特点,其中,作者认为独创性编辑者而非平台拥有著作权[23],平台对百科词条要履行“中等程度”的审查义务[24]。
我们对1980年以来国内“百科条目”的265篇论文进行了可视化分析,包括发表年度统计、主题分布、学科分布、文献来源、作者分布、作者机构分布、关键词聚类等(如图1和图2)。

图1 CNKI中“百科条目”主题的发文量趋势
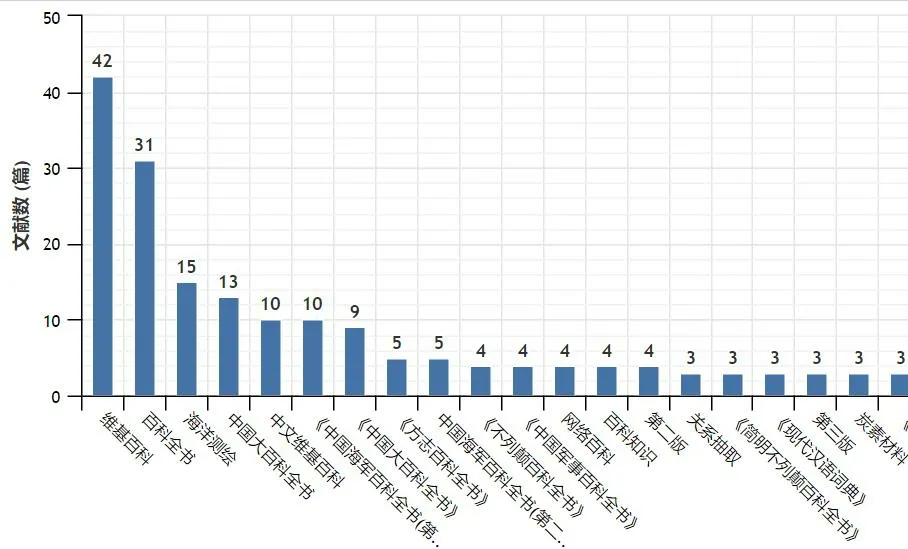
图2 CNKI中“百科条目”下的发文主题分布
从图1可以看出,“百科条目”的研究趋势具有两个增长期。在改革开放初期的20世纪80年代初,经济发展需要百科知识的支撑,百科研究出现了第一次高潮。随着我国经济的快速发展,2010年我国超过日本成为全球第二大经济体,这个时期百科研究出现了第二次热潮。经济发展与百科研究具有一定的关联性,其主要原因在于很多科技领域涉及百科知识。科技发展需要全领域知识的支撑,并最终推动经济前行。
从图2可以看出,“百科条目”的研究主题集中在维基百科、百科全书、海洋测绘、中国大百科全书、中文维基百科等方面。主题的集中性体现出国内研究者关注的焦点。研究的广度和深度在各主题中都得到了很好的展现。
从图3、图4可以看出,“百科条目”研究涉及学科较为广泛,排在前列的是计算机软件及计算机应用、出版、中国语言文字、图书情报与数字图书馆、新闻与传播、自然地理学和测绘学等。《辞书研究》是发表百科条目相关研究最多的刊物。很多计算机领域的学者充分利用自己的学科所长,对百科条目的自动提取、质量评估、文本聚类等进行了深度研究。出版业在“百科条目”方面的研究集中在大百科全书的编纂方面,推动了我国大百科全书的发展。中国语言文字领域的研究则从本体角度对百科条目的收词、释义、示例等进行了讨论。华中师范大学、西南交通大学的学位论文中,百科条目的研究占有较高比例。
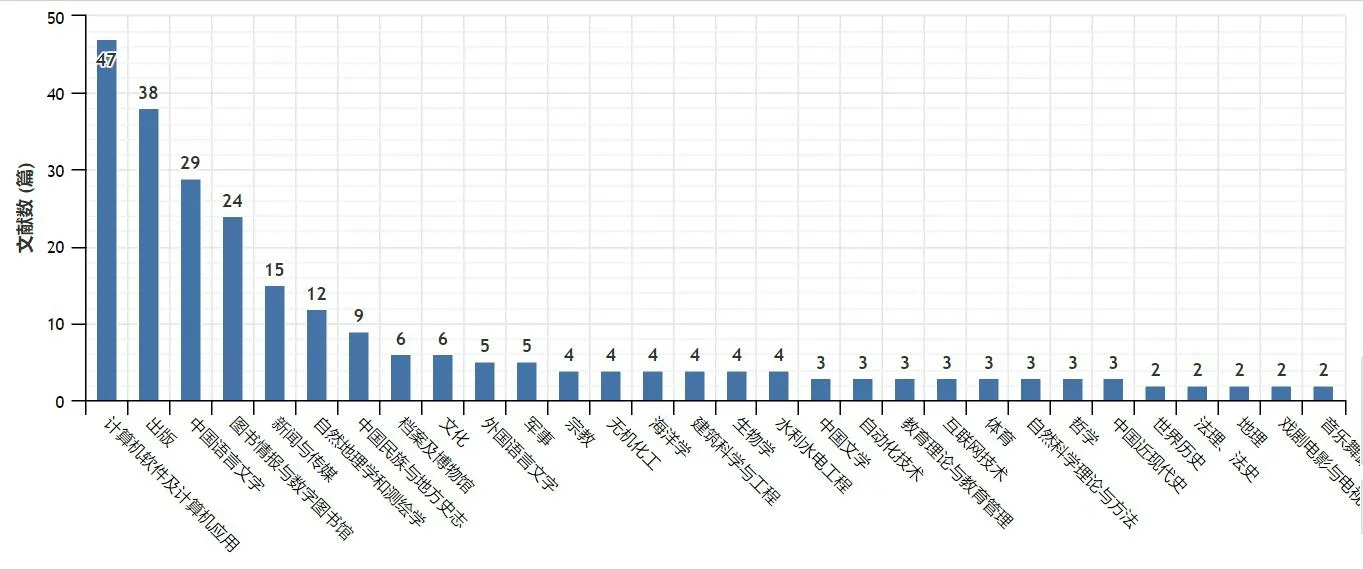
图3 CNKI中“百科条目”研究的学科分布
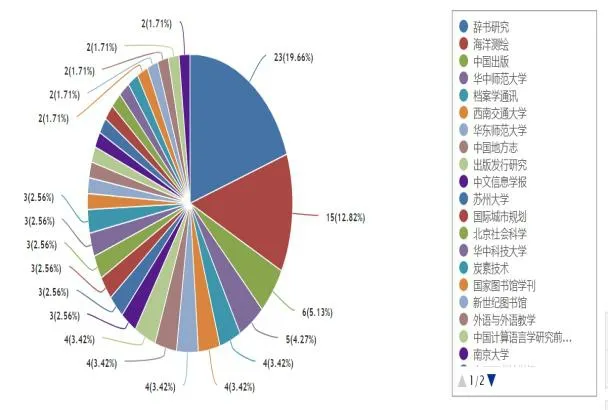
图4 CNKI中“百科条目”研究的文献来源
在图5中,排在前面的作者分别是甘莅豪(华东师范大学)、贾真(西南交通大学)、付巧(陕西师范大学)、尹红风(西南交通大学)、杨宇飞(西南交通大学)、关泠(解放军军事科学院)和王锦(东北大学)。其中,西南交通大学的三位作者在“百科条目”主题研究中具有高显示度。从图6可以看出,排在前六位的研究机构是中国大百科全书出版社、武汉大学、西南交通大学、华中师范大学、华东师范大学、苏州大学。中国大百科全书出版社的学者发文量占到总发文量的15.74%。
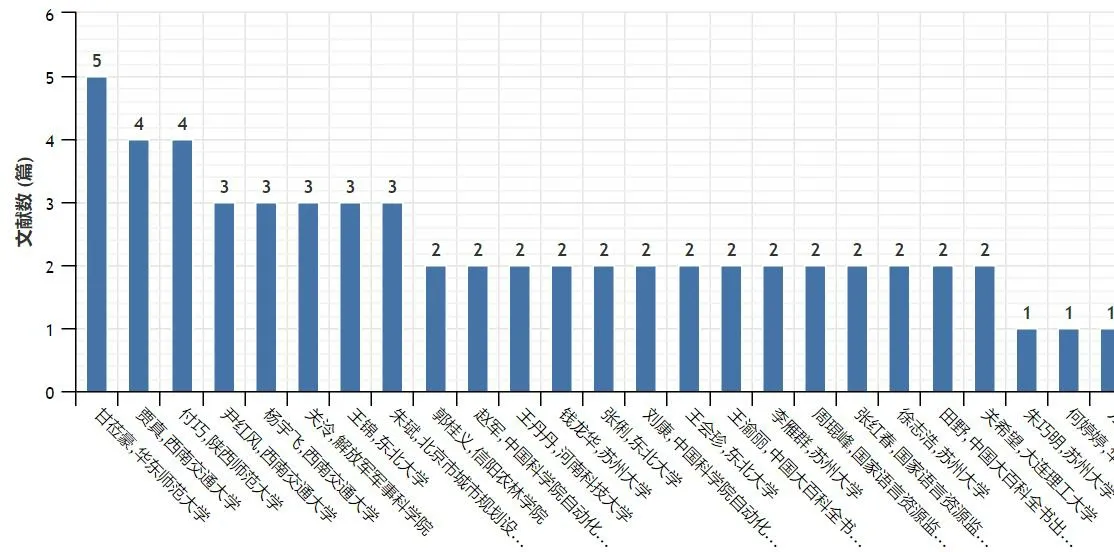
图5 CNKI“百科条目”研究的作者分布
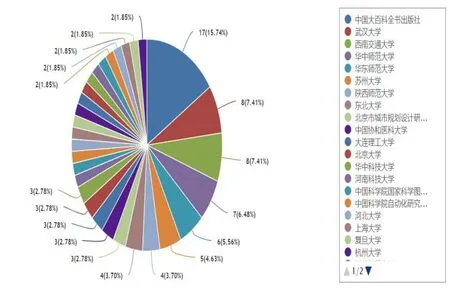
图6 CNKI中“百科条目”研究的机构分布
使用CiteSpace进行关键词聚类研究(结果如下图7),可见与“百科条目”关联度最大的是维基百科,其后是百科全书、百度百科、条目、网络百科、众源方式、知识传播、知识库、检索系统、知识获取、关系抽取、协同编辑、数字社区等。

图7 “百科条目”CNKI研究的CiteSpace关键词聚类
从以上对中国知网265篇论文的封闭域研究可以发现:(1)“百科条目”是文理兼容的研究领域,体现了定量和定性的特点。定量研究集中在对“百科条目”的计算机处理和统计分析等方面,定性研究则更多关注命名实体、知识获取、概念特征分析等方面。(2)在条目翻译研究方面,发表了4篇文章,分别讨论了外国文学条目的翻译[25]、埃博拉病毒条目的汉译[26]、机械条目的中日翻译与传播[27]、百科全书条目的翻译策略[28]。大数据百科条目多语种外译的研究鲜有学者涉及。(3)在整个“百科条目”研究封闭域中,尚没有对大数据相关条目的研究。
2 大数据百科条目多语种翻译的工作理念和方法
在大数据百科条目的多语种翻译中,汉语是源语,以其为放射原点的特性决定了汉语的锚定属性;英语是汉语之外与其他语种关联最为紧密的语种,显著的国际性特征和语系特征也决定了英语的锚定属性。
2.1 百科条目的范畴化
条目分类处理可提高多语种翻译的效率。多语种团队需要全面了解汉语词条释义,并参照条目分类进行各语种的预处理。汉语分析和英语翻译,对其他语种翻译有指导性作用。大数据百科条目具有词源的差异性,不同类别的条目应采用不同的翻译模式。我们将条目分为3类,并通过特殊字符标识进行区分,以便在6个语种的平行翻译中达到最大限度的对应。在实践中,这种大数据百科条目的范畴化为多语种翻译提供了便利。
2.1.1 一级标记
一级标记“*”为专有名词符号。大数据百科条目中的专有名词在多语种翻译时需保持原译,不进行修改。这种星号标记的目的是在多语种平行翻译时保持体例的一致性。例如,区块链(block chain,chane de bloc,цепочка блоков,Cadena de bloques,)。又如,大数据百科条目中的书名,在多语种翻译中就属于一级标记,其他语种平行翻译时需要找到对等的书名,如《零边际成本社会》在英语中的书名是TheZeroMarginalCostSociety,而在俄语中书名是Обществе с нулевыми предельными издержками。其他语种在各自语言中找寻对应的书名,如果有约定俗成的翻译则直接借来使用,如果没有实现各语种的本土化翻译,则需要进行对应翻译,如法语Société à cot marginal zéro,西班牙语La sociedad de coste marginal cero,阿拉伯语()。除了常规的专名和书名可认定为本系统的专有名词外,为保证多语种翻译的一致性,以下两种情况也认定为专有名词:
2.1.2 二级标记
二级标记“#”为有限翻译符号。在大数据百科条目中,如果条目构件是组合形式的,一部分是确定的翻译构件,而另一部分是不确定的构件,为保证翻译的准确性,把此类条目进行“#”二级标记标注,目的是将我们的译文向人们更为熟悉和可接受的译文靠拢。
例如,“天使汇”是确定的专有名词,而“运作模式”是相对而言不确定的构件,这样就形成了二级标记符号条目。



2.1.3 三级标记

从以上大数据百科条目范畴化可以看出,一级条目是专有名词,翻译模式是约定俗成的;二级条目是有限的约定俗成,翻译模式通常采用组合模式;三级条目是一级和二级之外的自主翻译条目,需要综合考虑频率、语域、语体等指标。
2.2 百科条目多语翻译的系统性
大数据百科条目多语种翻译是系统性的翻译实践。在汉语条目外译到英语、法语、俄语、西班牙语、阿拉伯语的过程中,我们总结了“以锚为准、轴为两翼;规范为主、兼顾描写”的系统性翻译工作理念,采用了独特的多语种翻译方法。
2.2.1 以锚为准
翻译锚的选定至关重要。术语的溯源锚应该是一个恒定的知识库。由于大数据百科条目多具有不同于普通词汇的知识集约性,而汉语术语这种浓缩的胶囊化特征在多语种翻译时必须进行显性化,因此,能否找到一个能将术语的集约性转变成外显性且具有权威稳定释义的知识库是成功翻译的关键。这个知识库应具有权威性、百科性、详释性、单一性、国际性、便利性等特征。
(1)权威性: 知识库要具有能使人信服的权威性地位,让受众对术语的溯源结果不产生怀疑,而且知识库内收录词条的准确性要符合国家标准。
(2)百科性:知识库要涵括术语翻译过程中所需的天文地理、自然人文、宗教信仰等学科知识,以便给译者提供充足的释义和名词溯源信息,为准确有效的翻译提供知识保障。
(3)详释性:知识库应对所收录的词条分类阐释,分类项包括中文名、英文名、术语起源、术语命名、术语历史、术语特征等模块。而且知识库提供的术语条目要达到一定的规模。也就是说,知识库要实现质和量的双合。
(4)单一性:知识库中对术语有明确的指称,不存在歧义且有清晰的区分度。单一术语对应多个指称的情况较少出现。这种单一性为术语的有效传播提供了可能。
(5)国际性:知识库中的术语最好能提供多语种翻译,如果无法实现多语种,至少要有英语对应词,跨语种模块的存在体现了知识库的国际性。
(6)便利性:知识库最好具有网络检索的便利性和可复制性,这样可以加快研究的速度和验证审校的效率。
“术语在线”可作为知识库的锚。“术语在线”是全国科学技术名词审定委员会的术语查询平台,涵括了大量的规范名词、名词对照、工具书资源等。“总数据量近百万条,术语在线已成为全球中文术语资源最全、数据质量最高、功能系统性最强的一站式知识服务平台。”①“术语在线”的学科覆盖也很广泛,自然科学、人文社会科学、工程技术、医学、生命科学、军事等学科术语均有涉及。从权威性来说,“术语在线”是规范术语的“数据中心”,具有绝对的权威性。从国际性来说,“术语在线”实现了尽可能多的中英文对译,具有很好的国际性。从便利性来说,“术语在线”查询方便,更新速度快,具有热词榜、术语标注、新词征集、微信小程序等网络模块,丰富了查询内容,提高了查询速度。同时,该平台审定的词条数量在不断增加。所以,“术语在线”是我们确定的最重要的锚。
百科类网站可作为锚的补充。除了“术语在线”知识库之外,百度百科、搜狗百科、互动百科、好搜百科、MBA智库百科、百科在线等网络百科可作为翻译锚的补充。例如,从权威性来说,百度百科与中国科协、最高人民法院,全国知名博物馆、书法家协会、卫计委、艺术院校、学术期刊、全国所有本科和专科院校等进行合作,具有较好的权威性。从百科性来说,百度百科是百度公司推出的一部内容开放、自由的网络百科全书,涵括了知识检索的各个领域。从详释性来说,百度百科收词量达到1700万条,每个词条均提供了详细的释义模块,具有较好的释义特征。从单一性来说,百度百科提供的英语翻译多数情况下符合单义特征,鲜有多义情况出现。从国际性来说,2007年4月19日,百度百科词条页面改版,在词条页面的底部增加了汉英词典解释,为百科词条的国际性传播铺平了道路。从便利性来说,百度百科依托百度搜索引擎,具有网络检索的便利性。所以,百度百科适合作为“术语在线”翻译锚的补充。
以上分析可以看出,国务院授权、代表国家审定和公布科技名词的权威性机构推出的“术语在线”适合作为大数据百科条目多语种翻译的锚,百度百科等百科类网站可对其进行补充。
2.2.2 轴为两翼
大数据百科条目的多语种翻译需要确定汉语为第一标准轴。我们的研究是汉外翻译,即将汉语内容对应翻译为英语、法语、俄语、西班牙语和阿拉伯语。原始的大数据名词也是通过汉语的形式提供的。这就要求译者对汉语的语言体系和特征有较为深入的了解,同时对汉语的文字系统和语义具有较为敏锐的分析能力。译者必须在汉语使用方面没有障碍,对汉语的理解保持顺畅性。因此,邀请的外国专家都是在国内专家的引领下进行多语种翻译的,国内专家要保持与外国专家的有效沟通,这样翻译出来的名词才能更好地实现“信达雅”的初衷。
例如,“脱贫攻坚”是汉语独有的词条,也只有母语是汉语的专家才能明白这个词的意义。在对“《脱贫攻坚大数据平台建设实施方案》(广西)”的翻译过程中,每个语种团队都需要对词条进行切分,形成翻译模块,即形成“脱贫攻坚”“大数据”“平台建设”“实施方案”等关键词。“脱贫攻坚”有明确的英语翻译。在《中国日报》(ChinaDaily)中“脱贫攻坚”作为一个统一的语义模块,翻译为“poverty alleviation”,准确表达了“脱贫攻坚”的汉语语义,所以,我们在后续的术语翻译中以此为准。
从图8可以看出,“脱贫攻坚”在2016年之前搜索量接近零,从2016年5月某个时点开始不断攀升,目前达到了搜索指数的高位。说明该名词的使用不断得到群体认可。因此,处理此类名词时,要找到具有规范表达的权威机构的翻译用法(采用的是ChinaDaily的权威翻译),避免出现杜撰和强译。

图8 “脱贫攻坚”的百度搜索指数
“《脱贫攻坚大数据平台建设实施方案》(广西)”的名词翻译还需要处理好其他模块的翻译。“大数据平台建设”多采用名词“construction of big data platform”,“实施方案”译为“implementation program”。经过汉语语义分析,可知核心成分“实施方案”需要在英译时提前到词首,后续的关键词需要通过不同的介词进行引领。这样,“《脱贫攻坚大数据平台建设实施方案》(广西)”可英译为“ImplementationProgramforConstructionofBigDataPlatformforPovertyAlleviation(Guangxi) ”,其他语种对应性翻译为:
法语:Programmed’implémentationpourlaconstructiond’uneplate-formedeBigDatavisantà éradiquerlapauvreté (Guangxi)。
西班牙语:Programa de Implementación para la Construcción de la Plataforma de Macrodatos para el Alivio de la Pobreza (Guangxi)。
在汉语作为第一标准轴外,多语种翻译标准轴的另一翼为英语。作为联合国工作语言之一,英语在国际交流中充当了非常重要的角色。英语不仅与欧洲的法语、西班牙语具有语系亲缘关系,而且与俄语和阿拉伯语有着较为密切的语言接触。这种全景式的语言特点,决定了英语可以作为汉语之外的第二标准轴。这样,在法语、俄语、西班牙语、阿拉伯语翻译时,需要同时参照汉语和英语这两个轴,为多语种翻译提供更为准确的参照系。尤其对源自英语且译入中国的大数据名词,再次译出时,需要搜寻原来的英语表达并搜寻英语对应的其他语种表达,以求得多语种之间的翻译对应性,减少语际偏差。
为了提高英语翻译的准确度,我们在英语翻译中引入回译制度,并通过国内外成熟的翻译软件进行重复验证,提高术语翻译的可重复性,减少不同译者对词条翻译的负影响。鉴于存在汉英两个标准轴,我们选择国内外各两个翻译软件,以平衡两个轴的翻译结果。国外选定的翻译软件为Google翻译(https://translate.google.cn)和DeepL翻译(https://www.deepl.com/translator),国内选定的翻译软件为百度翻译(https://fanyi.baidu.com/translate)及有道翻译(http://fanyi.youdao.com)。如此,具有英语知识库背景的国外翻译软件与具有汉语知识库背景的国内翻译软件相互结合,形成较为坚实有效的汉英翻译标准轴回译体系,为高质量翻译术语奠定了基础。汉语和英语作为标准轴的两翼,为法语、俄语、西班牙语、阿拉伯语的顺利翻译提供了汉英双语的结构性和系统性,为其他语种提供借鉴功能和预处理功能,最大程度地减少了术语的内生歧义,并将语际误差率控制在较小范围。
2.2.3 规范为主
术语的规范是科学技术发展所要遵循的基本要求。在科学研究过程中,术语的产生过程是随科学工作者的认知不断提升而不断完善的动态过程,这个过程是符合科学发展观的。术语规范是学术规范的重要一环,对形成和完善良好的学术氛围具有重要意义。
加强规范,既要贯彻国家相关语言文字规范,也要遵从国家的科技术语规范[29]。术语应用的时代特征为我国术语规范化工作带来更多挑战,术语翻译规范化的重要性愈加凸显。条目的设定,既要使读者能正确理解,还要使读者能正确地运用,这是规范性词典的两项重要任务,缺一不可[30-31]。
大数据领域的名词需要进行规范化研究。虽然该领域的术语多为新兴词汇,但其数量增长却是爆发性的。不同的译者从不同角度对大数据名词表达了不同的观点,这就形成了对同一事物的不同翻译模式。这对术语的发展是不利的,容易产生语内歧义和语际偏差,也不利于科技健康发展和相关术语的知识普及。所以,在汉外翻译大数据百科条目时,也需要进行规范性研究。
例如,我们在系统中对“大纲/纲要”的翻译就进行了规范。从图9可以看出,“大纲”和“纲要”的搜索量比较接近,“大纲”略高于“纲要”,但尚未达到区别特征的程度,这说明两个名词是同义词。在翻译处理时,我们既要关注两个名词的同义特征,也要在译词的选择上保持一定的区分度。

图9 “纲要”和“大纲”近10年的百度搜索指数趋势
英语翻译时需要尽量区分“大纲”和“纲要”。通过广泛的网络查询以及翻译软件的对比分析,我们发现“大纲”和“纲要”的主流翻译都是“outline”。这个结果与百度搜索指数提供的搜索量比较接近的描述是一致的。为区别这两者,我们把单复数形式作为区别性特征,即“纲要”多侧重不可数状态,译为“outline”单数模式;“大纲”多强调可数状态,采用“outlines”的复数模式。这样,我们就可以在保留两者同义关系的基础上,通过单复数形态变化对它们进行区分。
“大纲”和“纲要”的翻译体现了“如无必要,勿增实体”的翻译原则。根据前面的分析,“《个人数据保护基本法制大纲》”翻译为“OutlinesofBasicLegalSystemforPersonalDataProtection”。“《促进大数据发展行动纲要》”翻译为“*ActionOutlineonPromotingtheDevelopmentofBigData”。前面的条目没有约定俗成,所以确定为三级标记,后一个条目是由相关部门提供的确切英语翻译,所以确定为一级标记。这样,通过采用单复数形式区分“大纲”(outlines)和“纲要”(outline),我们在系统内对同义关键词进行了规范性研究。各语种的语义颗粒度不同,可通过具体分析汉英两种语言的表述来确定自己的翻译模式。形成的多语种对应性翻译如下:
从以上分析可以看出,规范性研究是术语研究的主流,这种区别性的排他研究确保了术语语义传递的非歧义性。
2.2.4 兼顾描写
大数据名词的汉外翻译是术语的跨语言再次命名,具有明显的语言特征,这一特点也决定了在研究方法上,将无可避免地出现语言的描写特性。
科学的研究方法可以产生科学的研究结果。研究方法的应用水平和综合程度会产生不同的研究效果和效能。从某种程度上说,术语理论的研究很多是依托研究方法展开,坚实有效的研究方法会推进术语学的发展。因此,在对大数据百科条目进行汉外翻译时,需要在关注“规范为主”的研究方法同时,也关注“兼顾描写”的语言特征,使我们对大数据术语的描述更加清晰,翻译更加准确,逻辑分析更加严密,最终让术语研究的内容更广泛,研究视角更新颖,研究思想更有深度。
术语翻译的描写特性通常是对约定俗成的语言特例的尊重。这种描写性研究方法是对现有语言现象的描述和叙述,具有从语言特例中解释语言共时和历时变化的特点,能更好地为语言系统服务。
综上分析可以看出,研究方法的创新与否及创新综合程度高低,都会影响研究的效果、效率和效能。我们提出的“以锚为准、轴为两翼;规范为主、兼顾描写”的翻译理念和方法,是大数据百科条目汉外翻译的一种创新。这种方法既关注了释义锚的选定,也关注了标准轴的规划;既强调了术语规范的重要性,也强调了规范之外描写特性的合理性。从对“以锚为准、轴为两翼;规范为主、兼顾描写”研究方法的分析可知:术语研究是兼跨自然科学和人文科学的研究;充分释义是准确翻译的前提;汉英双轴对应可避免语际偏差。在术语单义性的主流规范模式之下,我们也难以避免语言描写特性的存在。期待这种研究方法能够推动大数据领域的发展,为科技进步和学术规范做出贡献。
3 不足和展望
翻译锚、大数据百科条目、多语种翻译均存在提升的空间。(1)“术语在线”(及补充信息的百度百科等)作为我们多语种翻译的锚具有溯源清晰、知识丰富、英语自附等特点,很好地实现了翻译锚所需的权威性、百科性、详释性、单一性、国际性和便利性。但是,翻译锚随着新知识的涌入还有提升的空间。(2)在大数据百科条目的遴选中,大数据百科条目由于源自新兴领域,条目的数量与传统研究领域的条目相比还处于弱势阶段,后续还需要深化对大数据领域的研究,编写和审定更多的大数据百科条目[32]。(3)因为各语种间语义颗粒度的大小不均,6个语种的平行翻译会出现语义不对等的情况。例如,“中华人民共和国国家互联网信息办公室”作为专有名词,约定俗成翻译为“*Cyberspace Administration of China”,这种既定模式的汉英对应有时本身就是不对称的,但已经约定俗成。这种语义颗粒度不均匀导致的多语种翻译的不对称问题为后续提高条目的多语种翻译质量预留了空间。
4 结语
大数据百科条目多语种翻译是对大数据新兴领域的研究。大数据研究被称为继蒸汽技术革命、电力技术革命和信息技术革命之后的第四次革命。在大数据百科条目联合国工作语言的多语种翻译中,我们形成了独有的工作理念和方法。
首先,大数据百科条目具有范畴化特征。约定俗成的汉语专有名词条目可作为一级标记条目(*标注),提示我们在多语种翻译时关注其约定俗成的特性。同时具有约定俗成和组合构件特点的条目可作为二级标记条目(#标注),提示我们在多语种平行翻译时聚焦条目的组合性。其他类条目为三级标记条目(默认无标注),此为团队的创新性翻译。
其次,大数据百科条目翻译具有系统性。“以锚为准、轴为两翼、规范为主、兼顾描写”是我们在大数据百科条目多语种翻译中总结形成的工作理念和方法。“以锚为准”指作为新兴领域的大数据研究,其百科条目的翻译首先要确定权威的知识库作为翻译锚,全国科学技术名词审定委员会推出的“术语在线”适合作为翻译锚,百度百科等百科类知识库适合作为翻译锚的补充。“轴为两翼”指在多语种翻译中,汉语因其源语特点适合作为第一标准轴,英语因其国际性特点适合作为第二标准轴,其他语种平行翻译时将参照汉英标准轴进行翻译。“规范为主”指大数据百科条目多语种翻译时,要强调规范的重要性,以国际标准、国家标准、部委标准、省市标准等规范为主,相关条目需要遵守规范。“兼顾描写”指语言的描写特性及语际的语义颗粒度不均衡等原因会影响多语种翻译理想状态的实现,各语种在平行翻译过程中存在一定的语言描写空间。
由于我们团队的大数据百科条目多语种翻译涉及英语、法语、俄语、西班牙语、阿拉伯语等联合国工作语言,译者的翻译素养和大数据素养难以保持一致,一定程度上制约了多语种翻译的质量。而且,新兴大数据百科条目的语言认知还在发展中,命名规则的不断调整、语言共同体的深度认可以及社会约定的深入变化都可能带来大数据百科条目多语种翻译结果的变化。所以,我们的研究更多是“抛砖引玉”,希望成为大数据研究领域、术语审定领域、辞书编撰领域和翻译领域研究的基石,为后续发展奠定基础。
注释
① https://www.termonline.cn/about
② http://language.chinadaily.com.cn/a/201907/04/WS5d1d4f5ca3105895c2e7b94f.html
