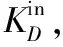基于改进K-Shell的社会网络关键节点挖掘算法
2023-08-10李蜜佳卫红权李英乐刘树新
李蜜佳 卫红权 李英乐 刘树新
(中国人民解放军战略支援部队信息工程大学 河南 郑州 450001)
0 引 言
对复杂网络进行深度挖掘和分析在理论和现实中具有重要意义[1]。社会网络是复杂网络的一个领域,包括人际关系网、Twitter网和论文合著网等。社会网络中的各个节点,由于在网络中的结构地位以及活跃度的不同,所起的作用也不同,其中有一部分节点对网络局部或者全局影响较大,这类节点就叫做关键节点。通过挖掘社会网络中的关键节点,可以满足我们的很多实际需求。比如在产品推销网络中,商家可以消耗最少的资源实现产品最高效的推广;在舆论传播网络中,政府可以使用最少的干预手段去宣传舆论或者禁止谣言;在犯罪嫌疑人关系网络中,警察可以快速锁定团伙头目,进而集中警力抓捕。
目前,在关键节点挖掘方面,研究人员已经从不同的角度探索了很多算法。在基于邻居节点中心性的方法中,度中心性的方法用节点的邻居节点数量来衡量节点重要性,计算复杂度低,但是仅考虑了节点局部重要性,没有考虑节点的网络位置及其他全局信息,准确性不高。Chen等[2]提出了一种半局部中心性方法,该方法只统计节点的四层邻居的信息,比局部中心性的方法更准确且计算复杂度低,适合于大规模网络,但是由于该方法没有考虑邻居节点所处的不同层次,影响了关键节点挖掘的准确性。之后,Chen等[3]综合考虑了度中心性与聚集系数,又提出ClusterRank中心性,该方法适用于大规模网络,但把网络视为无向的,与多数现实情况不符。赵晓晖[4]综合考虑节点的半局部中心性和聚类系数,提出了一种归一化的局部中心性节点影响力度量算法。Kitsak等[5]认为节点距离网络核心越近,所产生的影响力也就越大,由此提出K-Shell分解法,该方法计算复杂度低,在分析大规模网络方面应用较多,但是仅对节点进行粗粒度划分,准确性不高。对此,严沛[6]在K-Shell的基础上,使用双向搜索树方法提高算法准确性。
在基于路径中心性的方法中,Hage等[7]认为节点的影响力与节点到其他节点的距离有关,提出离心中心性,该算法很容易受到特殊值的影响。Freeman[8]提出接近中心性(Closeness Centrality),节点的紧密度越大,越靠近网络中心,也就越重要。Freeman[9]提出介数中心性(Betweenness Centrality),将节点的重要性由通过该节点的最短路径数目来表示,这两种算法准确度高但计算复杂度也高。与介数中心性仅考虑最短路径不同,Katz中心性[10]考虑节点对之间的所有路径,并根据路径长度对路径加权,这种算法的时间复杂度也比较高。
在基于特征向量的方法中,Bonacich[10]提出特征向量中心性(Eigenvector Centrality),认为一个节点的重要性要综合考虑其邻居节点的数量和质量。Poulin等[11]假设每个节点都在社会网络中被提名,节点的重要性与节点本身及其邻居节点被提名次数有关,由此提出一种累计提名中心性(Cumulative Nomination Centrality),该算法比特征向量中心性收敛要快。Google引擎使用的PageRank算法[12]是特征向量中心性的变体,该算法综合考虑指向该节点的邻居节点数目和邻居节点自身的重要性。Lü等[13]提出LeaderRank方法,引入背景节点使原网络变为强连通网络,从而替代了PageRank算法中的跳转概率c,性能较PageRank有较大提升。
基于路径和特征向量中心性的关键节点挖掘算法虽然准确度高,但是普遍时间复杂度高,无法在大规模网络上进行应用;度中心性、K-Shell分解法等时间复杂度低的算法虽然适用于大型网络,但是其准确度又不理想,其划分结果难以满足精细化节点重要性划分的实际需求。
基于此,本文对K-Shell分解法进行改进,在分解过程中综合考虑节点的度数与节点被删除时所处的迭代层次,以解决K-Shell划分结果粗粒化的问题。随后采用一种用微观结构去替代原有完整网络的算法,根据改进的K-Shell节点排名提取核心网络,并结合PageRank值对核心网络中所有节点做定量分析,找出影响较大的节点,最终形成分层次的重要节点划分。在三个实际网络中进行实验验证,结果表明本文方法具有较低的时间复杂度,计算结果也更准确。
1 算法设计
图G的邻接矩阵A=(aij)N×N,A=(aij)N×N是一个N阶方阵,其中:
式中:aij为节点i与j连接。
1.1 K-Shell分解法
Kitsak等[5]指出在度量节点重要性时,需要考虑节点在整个网络中的位置,他们认为处在网络核心位置的节点会产生较大的影响力,并提出了K-Shell分解法。
例如,图1是一个由15个节点和19条边组成的无权无向网络图。
图1 无向网络
针对图1所示的无向网络,具体分解过程如下:删除网络中所有度为1的节点及连边,记迭代层数为1。观察剩余网络中是否仍有度为1的节点,如果有,删除节点及连边,迭代层数记作2。循环去除,直至网络中没有度为1的节点,此时将所有被删除节点K-Shell值记作1。依次迭代,删除网络中度为2、3、4、5、…的节点,直至所有节点都被删除。图2为按照K-Shell分解法对网络中所有节点的划分结果。

图2 K-Shell分解

图3 SIR模型状态转移
对图1网络记录K-Shell分解全过程如表1所示。
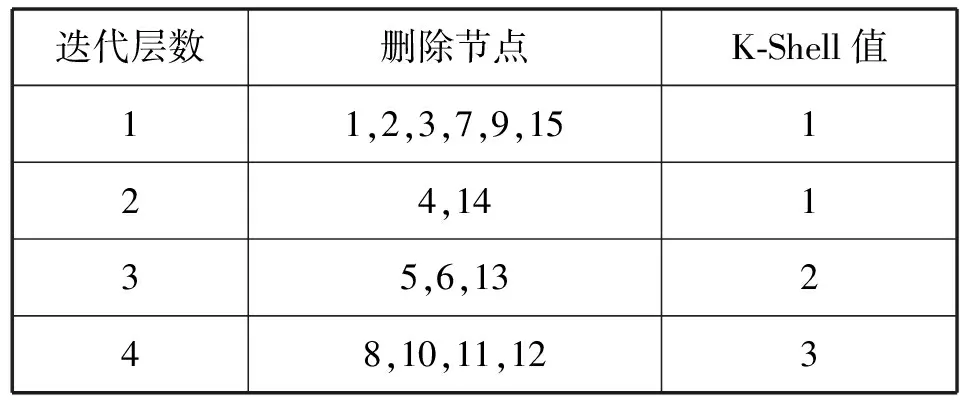
表1 K-Shell分解过程
1.2 改进的K-Shell分解法
K-Shell方法计算复杂度低,在分析大规模网络方面应用较多,但也存在不足。第一,K-Shell分解法不区分入度与出度,而社交网络基本都属于有向网络[14],节点受关注的程度由节点的入度表示,节点的合群程度由出度表示,忽略入度与出度的不同,会使一些节点以较小的代价通过建立与核心位置节点的单向连边来提高自身核数,从而导致挖掘结果出现较大偏差。第二,K-Shell分解法属于粗粒度划分,把属于同一层的节点都看作同等地位,忽略了节点度和节点被删除时所处迭代层数的影响,导致大量节点被划分到同一层。如在图2的网络中,节点1和节点4被K-Shell分解法划分到同一层,K-Shell值相同,但显然节点4比节点1重要。
对此,本文对算法作如下改进:
(1) 针对社交网络多为有向网络的特点,将传统的K-Shell在分解过程中不区分节点入度出度的做法,改为仅考虑入度对节点进行剥离。
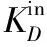
详细分解步骤为:

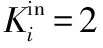
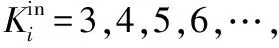
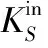
伪代码如下:
输入:nodes list V,Links list B。
Ks=1;
n=1;
while(|V|≠0)
add removal node i into set Vk-core(n);
add removal node i into set Vk-core(Ks);
end while
delete node i and related links;
update V and E;
n++;
end while
core++;
end while
1.3 inKD-Pr算法
PageRank算法[12]是谷歌搜索引擎的核心算法。它认为一个节点的重要性取决于指向它的节点的数目和质量。该算法作为有向网络节点排序最经典的算法,被广泛应用于对网页的排序、对社交网络上用户的排序等。作为全局性算法,PageRank计算结果较准确,但时间复杂度高于K-Shell分解法。由于两种算法相关性不大,本文综合了两种算法的优势,构建关键节点挖掘模型的步骤如下:
(1) 根据社会网络相关数据,构建邻接矩阵。
(2) 用改进的K-Shell分解法对网络所有节点快速打分。
(3) 按照得分高低,依次删除外围大约80%的不重要的节点及其连边,减小网络规模。
(4) 对步骤(3)中提取的核心网络,运用PageRank算法计算出每个节点的p值,并进行归一化和无量纲化处理。
本文算法框架被称作inKD-Pr算法。
2 评估标准及数据集介绍
2.1 评估标准
本文采用SIR(Susceptible-Infective-Removal)模型[15],将节点的最大传播力作为节点重要性评价标准。SIR模型是Kermack等提出的传染病模型中最经典的模型,现在普遍应用于疾病传播、谣言传播等领域。
SIR模型将网络节点分为三类:易感状态S,指个体可能会被处于感染状态的邻居节点感染;感染状态I,指节点已被感染且具备感染力;免疫状态R,指节点失去感染其他节点的能力。刚开始传播时,处在感染状态I的节点,以β的概率感染处在S状态的邻居节点,随后,处在I状态的节点以概率γ转变成为R状态,不再参与传染。重复上述步骤直至网络到达稳态。模型可用微分方程表示如下:
在SIR模型中,全部节点的数量N=S(t)+I(t)+R(t),其中S(t)、I(t)、R(t)分别为在t时刻网络中三种状态节点的数量。
不同挖掘算法的优劣可通过各算法挖掘的重要节点在SIR模型上的传播范围来衡量。设置一个(组)重要节点为S状态在SIR模型上进行传播,观察最终稳态时处于R状态的节点数量。如果一种算法的挖掘结果可使网络流传播地又快又广,即可说明该算法挖掘效果优于其他算法。
2.2 数据集
科布伦茨数据资料库是公布在网上,供从事大规模数据处理的人员用来进行网络科学及相关领域研究的工具。本文选取了该资料库三个有向无权的网络数据集作为实验网络,数据集信息如表2所示。
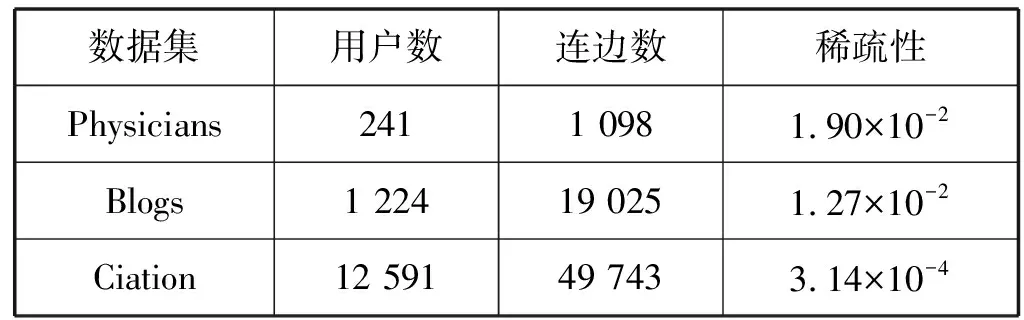
表2 数据集的基本特性
(1) Physicians社交网络数据集:节点代表医生,边表示一位医生遇到问题会向另一位医生求助。
(2) Blogs超链接数据集:节点代表用户,边表示一个用户链接了另一个用户。
(3) Ciation数据集:节点表示一个机场,边表示从一个机场到另一个机场的航班。
这三个数据集的基本情况如表2所示,稀疏性表示网络中任意两个节点间存在连边的概率,即网络中存在的连边数量占网络中所有可能连边数的比例。在有向无环网络中,网络的稀疏性=m/[n(n-1)],其中:m为网络中边的数目;n为网络中节点数。
3 仿真验证
3.1 实验设计
为了验证本文方法的有效性,选取3种排序方法对比分析,分别是度中心性、PageRank算法、LeaderRank算法。
本文采用单一节点传播的方式,分别对排名前k(为了分析方便,设置k=10)的节点进行SIR模型检测,每个节点都作为单一感染源进行传播,运行300次取均值,每种算法的有效性由该算法挖掘出的排名前10的节点传播能力总和来表示。这里将免疫率γ取为0.5。对于感染概率β,如该值太小,很难在一个较小的网络区域中区分开不同算法[16]。当β非常高,不管是从哪个节点开始传播,最后传播范围都将覆盖几乎整个网络,导致无法区分节点的作用。对此,本文使用一个温和的感染概率β=0.3。
3.2 实验结果
如图4所示,将免疫状态的节点的累计数量绘制成时间的函数,累计免疫节点随时间增加,最终达到稳定状态。在网络规模较小时(如Physicians数据集),度中心性的表现要优于inKD-Pr算法和PageRank算法,但是度中心性算法的准确率与网络规模有关,当网络中节点数增多时,准确率呈现显著下降趋势。这种现象与度中心性本身的算法有关,度中心性仅以节点的局部信息作为衡量标准,而没有考虑节点所处位置、更高阶邻居等因素,这就导致一些边缘节点可以通过与大量普通节点建立连边来提高度值,而这样的算法,在inKD-Pr算法中完全占不到优势,inKD-Pr算法以节点入度为参考值去提取核心网络,既删除了大量非核心节点,同时也确保了一些节点无法通过仅仅依靠增加出度而进入到核心网络中。Blogs网络上,度中心性算法和PageRank算法、inKD-Pr算法曲线近乎一致,即由这三种算法挖掘的前10名重要节点在网络中的传播能力基本相同。
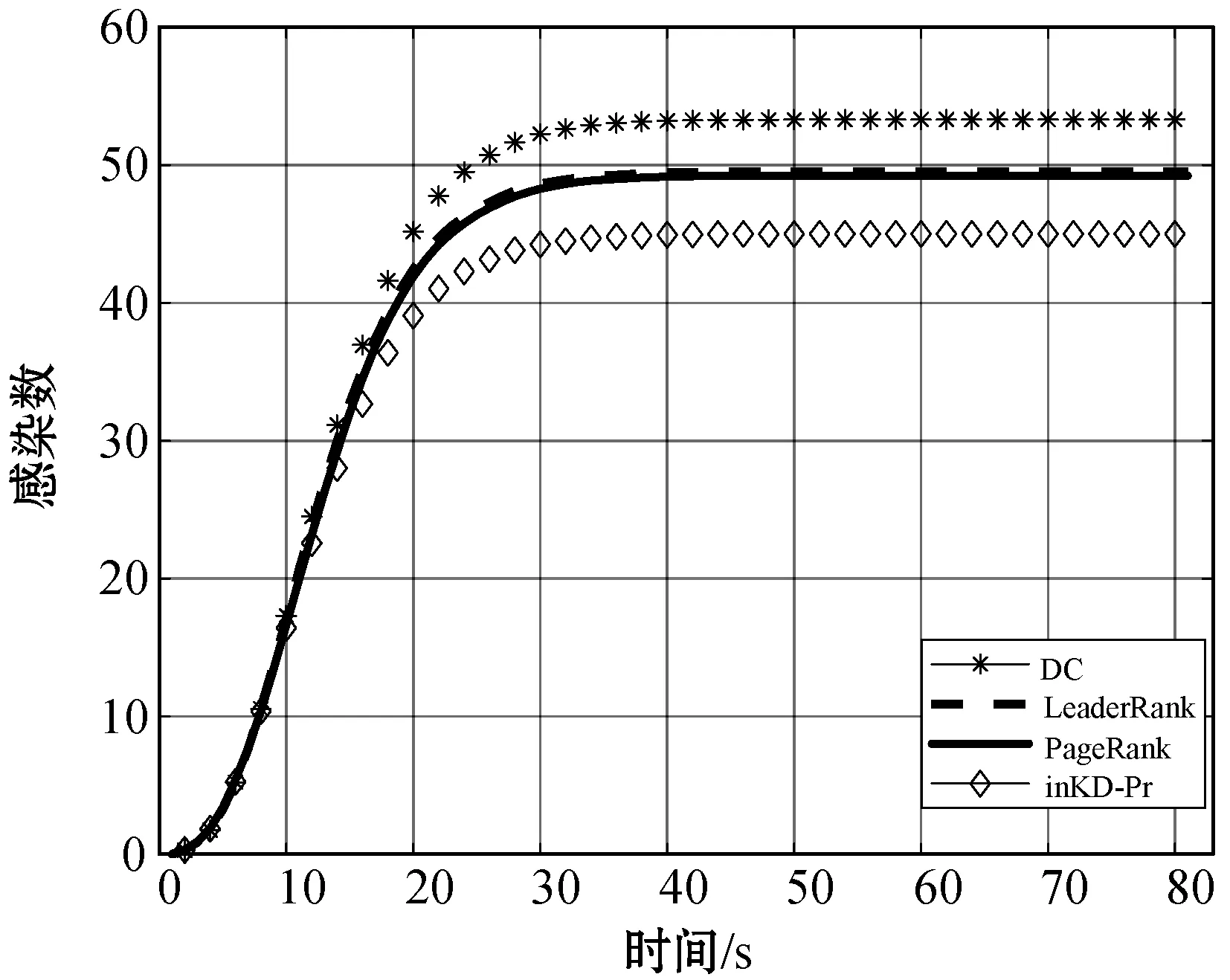
(a) Physicians网络
LeaderRank算法和PageRank算法在准确度方面的稳定性较佳但算法复杂度高。LeaderRank算法的准确率始终优于PageRank算法,这是因为需要大量实验才能获取PageRank算法中的阻尼系数s,且会改变原来的矩阵结构。而LeaderRank[17]在PageRank的基础上,加入一个与其他节点都有双向连边的节点,实现网络的强连通,以此得到一个无参数的算法。实验证明,这种算法比PageRank算法更准确。
inKD-Pr算法在网络规模小的时候准确率比较低,这是因为K-Shell算法对网络中的节点只能做粗粒度的划分。节点的K-Shell值越大,节点就越重要[5]。但具体到两个节点,只有K-Shell值相差很大,比如在10倍以上时,节点影响力才有显著差距。而在小规模网络中,节点的K-Shell值相差都不大,这就导致部分重要节点在用K-Shell分解法提取核心网络时被删除。在本文的实验中可以看到,随着网络规模变大,这种算法的准确度也越高。在Ciation网络中,inKD-Pr算法的准确率甚至优于LeaderRank算法,这是因为K-Shell分解法可以有效剔除一些大度节点的干扰。
3.3 准确率分析
本文将各算法挖掘出的Top-10节点与SIR模型挖掘出的Top-10节点进行对比,比值为各算法挖掘Top-10节点的准确率。表3的结果表明,网络规模越大,度中心性挖掘算法的准确性越低。相比,在不同规模的网络中,PageRank算法和LeaderRank算法具有更好的稳定性。本文提出的inKD-Pr算法随着网络规模增大,准确率也越高。但由于SIR模型每一次传播到达稳态需要的时间比较长,本文最大只选取节点数为12 000多的社交网络进行计算。从实验结果可以预见,网络规模越大,inKD-Pr算法挖掘重要节点的效果会更好。
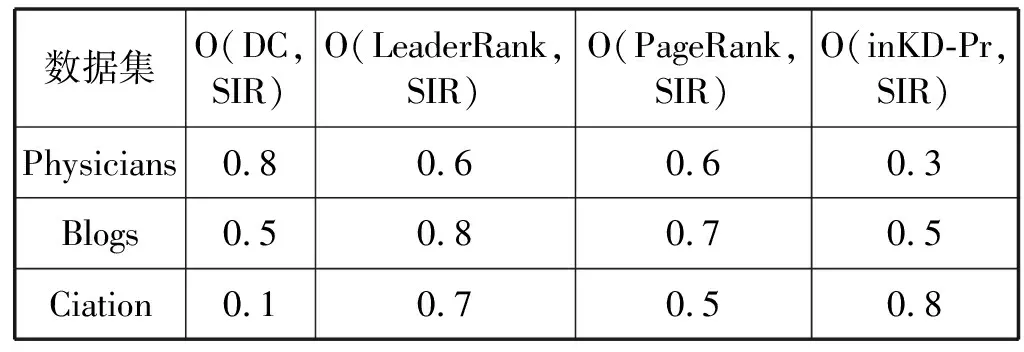
表3 各算法挖掘出的Top-10节点准确率与SIR模型对比
3.4 时间复杂度分析
本文提出的inKD-Pr算法是在K-Shell分解法的基础上进行改进的,可近似看作O(n),与K-Shell分解法相同。PageRank的计算复杂度为O(mI),度中心性的时间复杂度为O(n),介数中心性的时间复杂度为O(mn),其中:n和m分别为网络中的节点和边的数量;I为迭代次数。从表4可以看出,本文所提出的inKD-Pr算法计算复杂度相对较低。
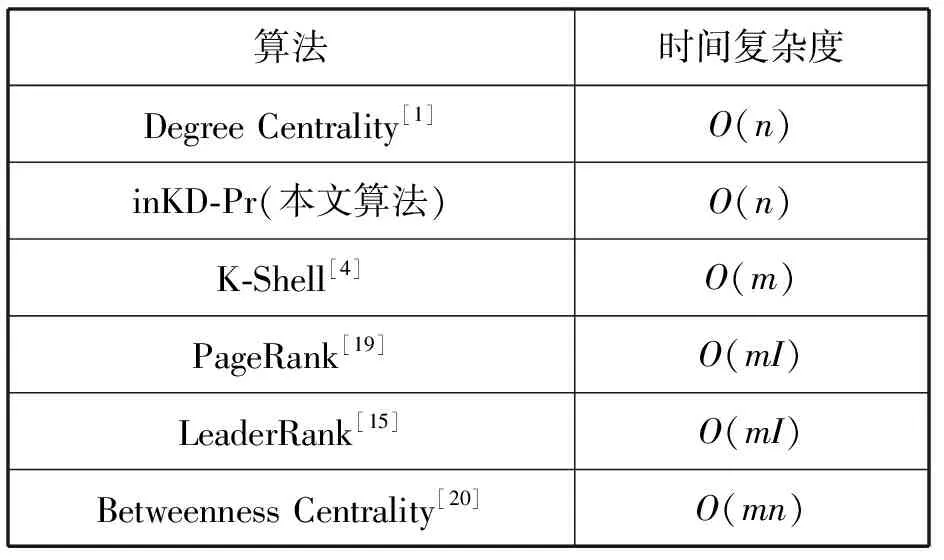
表4 部分重要节点挖掘算法时间复杂度
4 结 语