基于深度学习的核电设备缺陷检测算法的实现与应用
2023-07-17张力丹余方剑董婉祾
张力丹 余方剑 董婉祾 崔 宸
(中国核动力研究设计院,四川 成都 610000)
0 引言
随着全球对能源需求的不断增长,保障核电安全正面临巨大的机遇和挑战,如何高效进行核电设备缺陷检测已成为重要的研究课题,基于深度学习的机器视觉算法是该领域的关键技术[1]。与传统特征提取算法不同,基于深度学习的算法不需要手动设计特征,而是通过卷积核从图像数据中提取具有较强鲁棒性和深层语义的特征,因此其提取的特征图具有很强的表达能力[2]。卷积神经网络已经在许多计算机视觉任务中有突出表现,例如图像分类、目标检测以及图像分割等。目前,基于深度学习的目标检测算法从结构上主要分为以Fster R-CNN 为代表的两阶段网络和以单步多框目标检测(Single Shout Multibax Detector,SSD)或YOLO 为代表的一阶段网络[3]。一阶段的目标检测算法与二阶段的“选取候选框+分类验证”模式完全不同,一阶段算法直接将整张图像作为网络的输入,通过主干网络提取特征图,输入分类器进行分类和目标框的预测。Zhang C B 等[4]将最新的YOLOv3 版本应用于桥梁表面缺陷定位, 与原始YOLOv3 网络相比,其引入了预训练权重、批量归一化和Focal loss 损失函数,进一步提高了缺陷检测率。随后YOLOv4、YOLOv5 版本相继出世,进一步提高了检测精度,弥补了一阶段算法精度不足的缺点。
1 算法框架
1.1 数据采集和预处理
该文研究的数据来自某核电站2016—2021 年的缺陷检查报告和总结报告。首先,进行数据预处理,从上千份检查报告中提取图像数据,并对其进行初步的缺陷类别标注,即图像级分类。其次,对提取的图像数据进行筛选,选出仅有一类缺陷且特征较明显的图像数据。该小节研究的核电设备缺陷类型有4 个类别,分别是腐蚀、涂层脱落、起泡以及开裂。其中,起泡、开裂的特征比较微弱,在原图中所占的像素比太低,图像级的标注难以达到预期的检测效果。因此,该文进一步对数据集进行区域标注,即用区域框标注图像中的缺陷区域。由于核电设备缺陷图像样本数量十分有限,仅有5 000多张,且各类缺陷类别之间存在类别不平衡的问题。因此,需要对原图像数据进行翻转、旋转、裁剪、缩放、局部遮挡、添加噪声、随机模糊以及颜色变换等操作,对各个类别的缺陷数据进行扩充,以解决类别不平衡的问题。
1.2 算法结构
该文构建了基于YOLOv5 的目标检测模型,并利用该模型对核电设备缺陷数据集进行检测,网络结构由主干网络(Backbone)、颈部(Neck)以及头部(Head)构成,主干网络使用CSP-DarkNet+SPP 结构进行特征提取;颈部使用双向融合结构(PANet 结构)生成特征金字塔;头部使用YOLOv3 head 实现识别和回归功能。
1.2.1 主干网络:交叉融合结构(Cross Stage Partial,CSP)
CSP 基本结构为将输入特征按照比例分为2 个部分,一部分输入残差结构进行特征变换,另一部分直接使用1×1 的卷积进行特征变换,再将2 个部分的特征拼接(concat),最后进行批归一化处理,使用Leaky Relu作为激活函数,通过基础卷积层进行特征变换。YOLOv5中包括CSP 结构(如图 1 所示),采用2 种结构,分别为CSP1和CSP2,差别在于CSP2中将CSP1中的残差结构替换为普通的卷积结构。YOLOv5 中使用CSPDarkNet 作为主干网络,从输入图像中提取丰富的信息特征,解决了其他大型神经网络框架的主干网络优化的梯度信息重复问题,将梯度的变化集成到特征图中,从而减少了模型的参数量和每秒浮点运算次数,既保证了推理速度和准确率,又缩减了模型的规模。
1.2.2 颈部:双向特征融合结构(PANet 结构)
PANet 在特征金字塔的结构上添加了自底向上的特征融合结构。由于浅层特征中包括更多的边缘、形状等特征信息,自低向上的特征融合结构使顶层特征图可以共享底层带来的丰富位置信息,能充分利用网络浅层特征进行分割,因此可以提高大物体的检测效果。
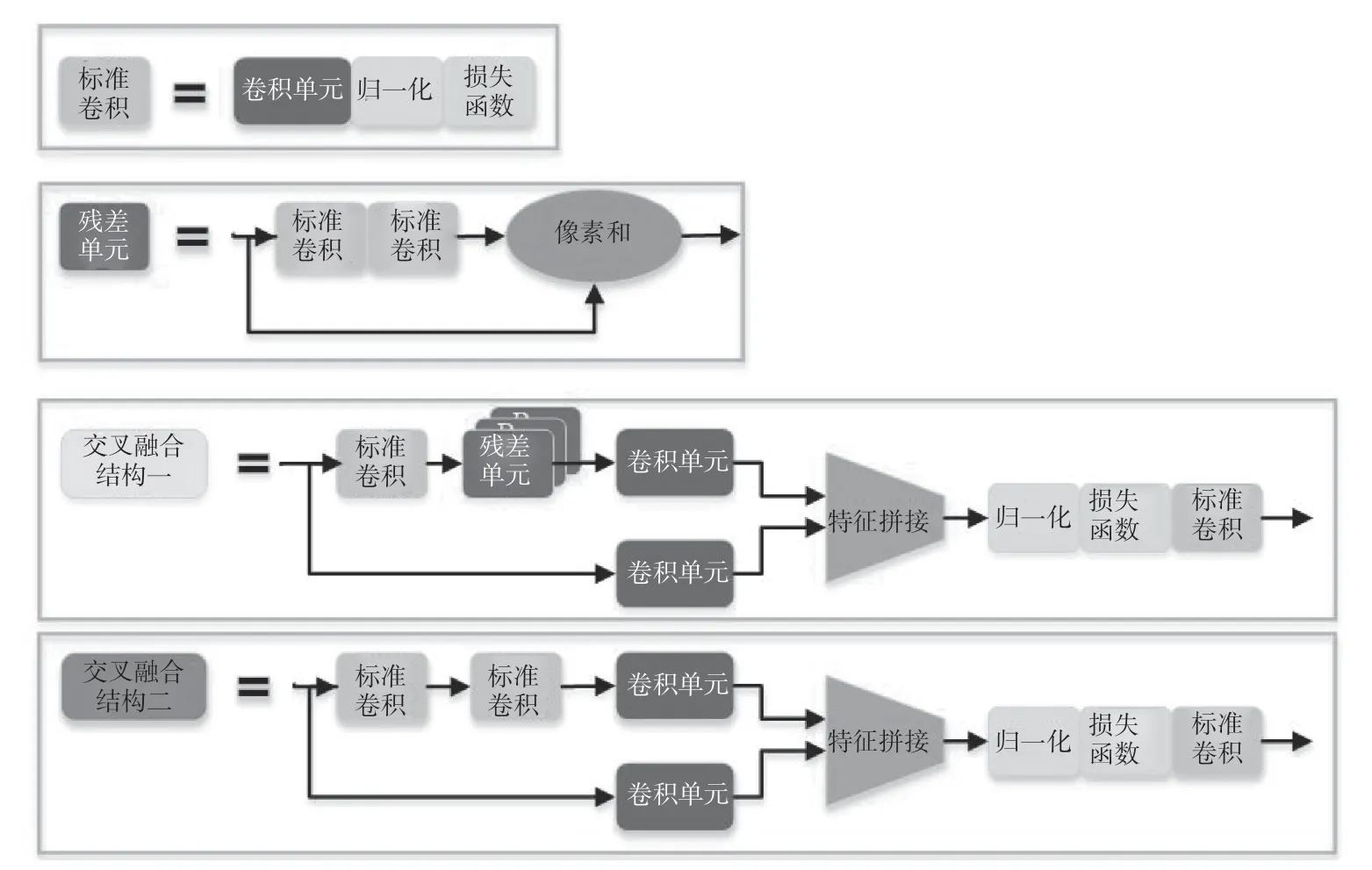
图1 交叉融合结构
1.2.3 头部结构
头部结构是网络的最终检测结构,通过主干网络和特征融合结构实现特征提取和融合,从而对特征进行检测。这部分对PANet 结构输出的3 个尺度的特征进行特征变换后实现预测,最终输出的特征图上会应用锚定框并输出张量:批量大小×(五维张量+类别总数)×特征图宽×特征图高。其中,五维张量为回归框的4 个角坐标、中心点坐标以及识别的置信度。不同的是在锚框分配方面,YOLOv5 通过跨网格匹配规则的方式来区分锚框的正、负样本,即计算标注框和当前层的锚框的宽高比,如果宽高比大于设定的阈值,就说明标注框与锚框匹配度不够,需要过滤。计算剩下的标注框属于哪个网格,利用四舍五入规则找出最近的2 个网格,将这3 个网格都认为是负责预测该标注框的网格,这样正样本数量就增加了3 倍。
1.2.4 损失函数
损失函数是为了让网络模型向检测目标不断学习而设定的目标函数,其中YOLOv5 的损失函数分为3 个部分:1) 参数化坐标框Lbox,如公式(1)所示。
式中:v为衡量长宽比一致性的参数,其比较了重叠面积、中心点距离以及长宽比(wgt、hgt为目标框转换为640×640的宽、高;wp、hp为目标框在80×80 网格中的网格坐标);IOU为2 个目标框的交并比;Distance_2 为2 个目标框中心点的欧氏距离;Distance_C为目标框对角线的距离。
置信度的损失Lobj采用BEC Logits Loss 损失函数,如公式(2)所示。
式中:yi为每轮训练的标签值;yi*为每轮训练的期望值。
类别损失Lclass采用交叉熵损失函数(BCEcls Loss),如公式(3)所示。
总损失函数Ltotal如公式(4)所示。
式中:λ1、λ2和λ3为3 个超参数,可通过试验结果调整。
2 试验设计与分析
试验在原始网络上使用预训练权重直接训练数据集,YOLOv5 模型有4 种不同宽度和深度的结构(s、m、l 和x)。由于试验的数据集规模较小,因此选用s 模型进行训练,在训练过程中设置超参数:学习率为0.003 2,学习率动量为0.843,权重衰减系数为0.000 36,预热学习迭代轮数为2,预热学习率动量为0.5,预热学习率0.05,目标框损失系数为0.029 6,分类损失系数为0.243,分类损失中正样本的权重为0.631,有无物体损失系数为0.301,有无物体损失中的正样本权重为0.911,标注框与锚框的交并比阈值为0.2。
该文选取召回率、精确率作为评价指标,在训练集、验证集上的试验结果分别如图2、图3 所示,模型在训练集上的损失不断下降,模型在验证集上的损失不断增加。在验证集上的召回率如图4 所示,训练达到一定轮次后,召回率在22%左右波动。在验证集上的精确率如图5 所示,精确率升至50%后不断下降。模型在训练集上的损失正常下降,说明模型在不断收敛,在验证集上的精确率却在下降,说明模型的泛化能力弱。
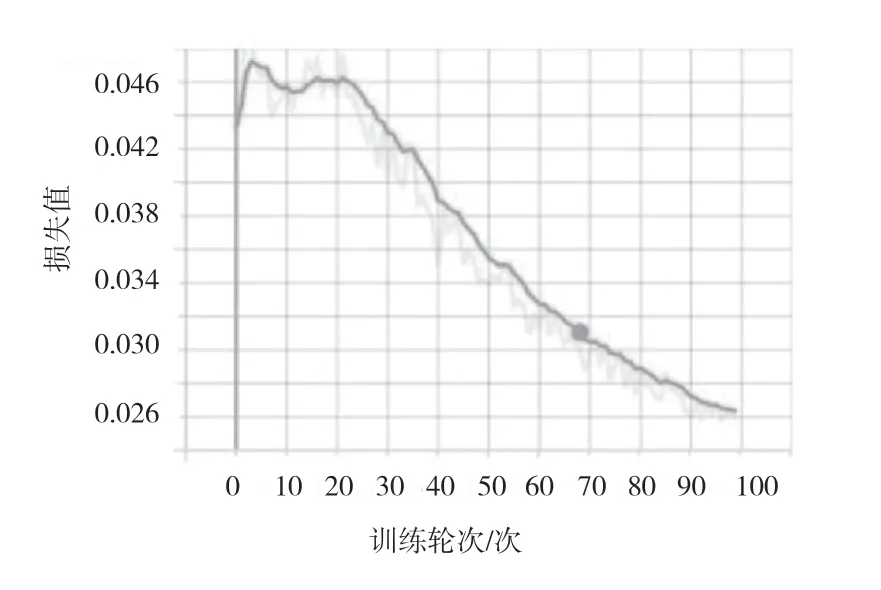
图2 训练集上的损失值

图3 验证集上的损失值
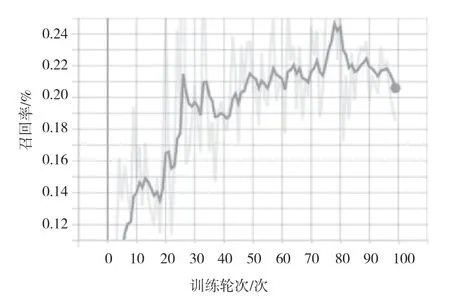
图4 验证集上的召回率指标
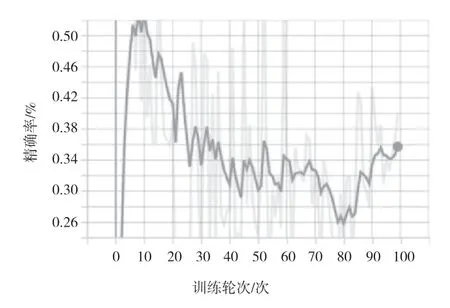
图5 验证集上的精确率指标
初步训练后,该文对训练集和验证集的数据进行分析,发现训练集和验证集的数据类别分布不均,因此重新划分训练集和验证集的比例并重新训练模型。如图6 所示,模型在训练集上的损失不断下降,收敛至0.026。如图7 所示,模型在验证集上的损失也不断下降,收敛至0.016,说明模型在验证集上不断收敛,具有较好的泛化能力。在验证集上的召回率、精确率分别如图8、图9 所示,训练达到70 轮后,召回率在90%左右波动, 精确率在95%左右波动。
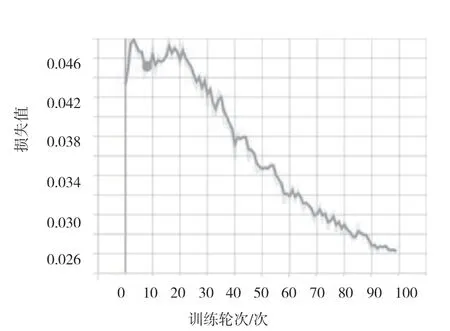
图6 训练集上的损失值
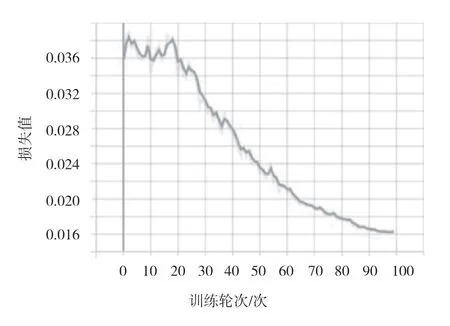
图7 验证集上的损失值
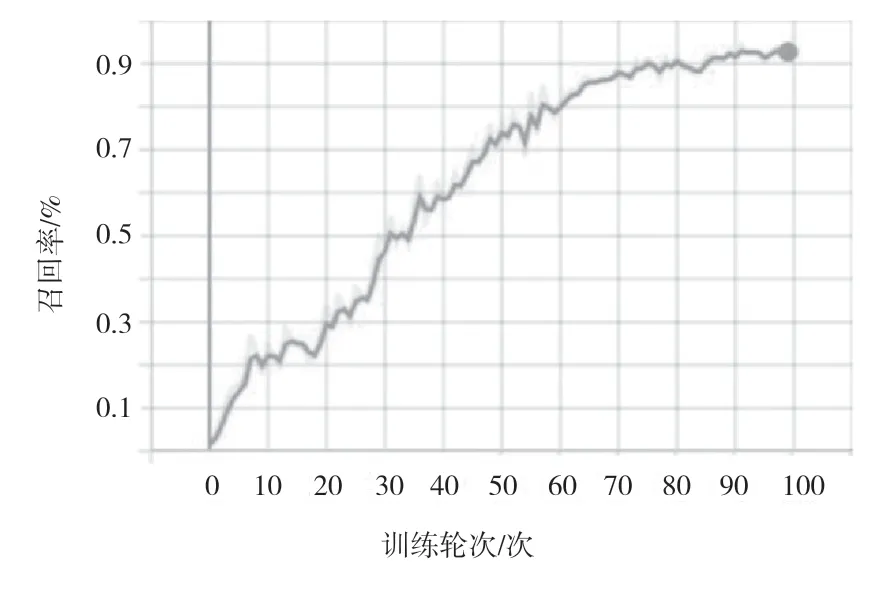
图8 验证集上的召回率指标
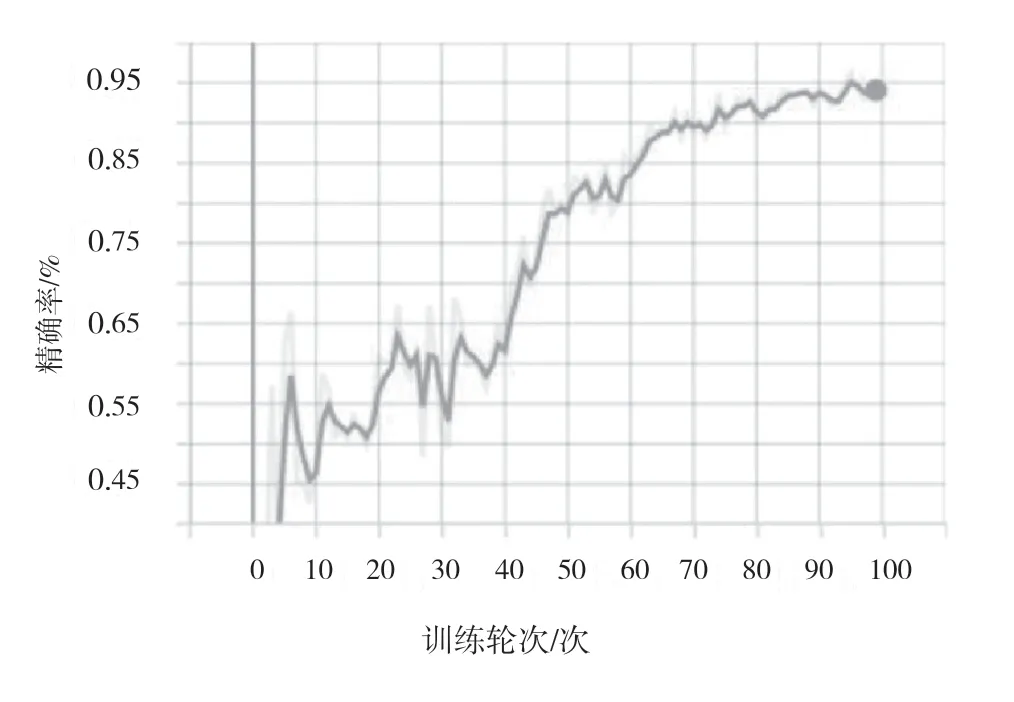
图9 验证集上的精确率指标
对比2 次试验的召回率、精确率指标,第二次训练结果明显比第一次训练结果好,说明数据集的质量对试验结果至关重要。同时,也说明YOLOv5 算法模型适用于该类数据集,可用于核电设备的缺陷检测。
通过试验发现,采用机器视觉技术对缺陷样本进行检测具有高效、节约成本的优势。当模型的鲁棒性较高时,只需要提供1 台计算服务器就可以进行缺陷检测。
3 结语
该文采用基于深度学习的目标检测算法YOLOv5 对某核电站的核电设备表面缺陷进行检测。研究结果表明,基于深度学习的目标检测算法适用于核电设备表面缺陷检测,在检测速度和检测精度方面都满足需求。目前,该数据集的数据量较少,还需要大量的数据来提高算法的鲁棒性,这样才能投入实际使用。未来可以通过更多的数据积累、数据生成等方式来形成专业领域,使算法可以投入实际的生产使用。
