结合提示学习和自注意力的预训练语言模型①
2023-05-30汪辉,于瓅
汪 辉, 于 瓅
(安徽理工大学计算机科学与工程学院,安徽 淮南 232001)
0 引 言
近年来,以BERT(Bidirectional Encoder Representations from Transformers)为首的预训练语言模型在语言理解上表现得出类拔萃[1]。预训练语言模型通过复杂的预训练任务和大规模的模型参数从海量无标注的语料获取上下文的语言信息。尽管预训练模型在预训练阶段学习了词语之间,字之间的联系,但是由于预训练模型的预训练阶段任务和下游任务之间相差甚远,导致了掩盖语言模型的性能无法完全表现。针对这样的问题目前主要有两种解决方法:第一种是微调(Fine Tune)[2],主要将目标任务的损失函数和预训练模型结合继续训练,在很多任务上有着不错的效果[3]。但在微调过程中会损失预训练已经学到的知识。第二种是提示学习(Prompt Tune)[4],通过加入语言模板,对于不同的文本任务进行语句重构。例如在文本分类句子“中国队获得冠军”重构成“中国队获得冠军,这是体育新闻”。以此适配预训练模型的任务。这样的训练过程不仅非常耗时,而且重构文本的要求损害了原数据的结构性。因此,将提示学习和自注意力机制的思想结合,使用自注意力和掩盖机制构建出新的预训练任务在BERT模型基础上进行促进训练的模型(PSAmBERT)。研究发现,通过PASmBERT模型可以有效提高预训练模型知识的应用效率。
1 相关的预训练模型
1.1 BERT
已有研究表明,BERT在广泛自然语言处理任务上具有出色效果[1]。BERT的设计的理念是通过所有Transformer层双向训练得到上下文信息。其中最重要的环节是BERT的预训练任务,主要包括掩盖语言模型和预测下一个句子。掩盖语言模型是预测被令牌随机替换的词;预测下一个句子是通过上句预测下句。由于英文和中文的词性结构不同,这种单词掩盖模式在中文语料的应用中效果表现一般,后来研究者提出了全词掩盖模式[5],是把相关的字全部掩盖,而不是单个随机掩盖。相关研究表明[6],在文本分类、阅读理解等文本理解任务上,全词掩盖模式的效果更实用于中文语料的训练,研究也应用了这种掩盖策略。
1.2 RoBERTa-wwm
Zhuang等人[7]提出了RoBERTa (Robustly Optimized BERT Pretraining Approach),并比较了BERT的各个组成部分,包括掩盖策略、输入形式、训练步骤等,在原始的BERT架构做出一些修改,使得其效果更好。优化主要包括:1)移除预测下一个句子的任务。在实验过程中发现,此任务对模型效果提升不明显,并且耗时。2)使用动态的掩盖;3)更多数据以及更大批次的训练。应用了全词掩盖模型的RoBERTa在命名体识别[8]、情感分析[9]等任务上表现出色。在研究过程中,使用RoBERTa-wwm进行实验对比。
2 本文模型
基于提示学习的模板思想,将原文本嵌入文本分类任务的语言模板。通过自注意力机制计算得到文本词与模板中关键标签词的权重,其目的是将掩盖权重词替换随机掩盖词,进而进行有效训练,增加预训练模型的预训练阶段任务和下游任务之间关联性。图1是模型框架。

图1 PSAmBERT模型架构
2.1 注意力掩盖模块
研究表明,提示学习在文本分类任务效果明显提高[4]。我们将提示学习的模板嵌入到原始句子中,通过语言技术平台(Language Technology Platform, LTP)[10]的分词工具实现全词掩盖。表1是文本分类句子处理的例子,其中深色背景表示提示学习添加的模板,空格表示分词结果。

表1 文本处理
原数据分词之后,需要通过自注意力机制获取和体育相关的权重词。通过公式(1)进行计算,其中K为输入的向量线性变化如公式(2)所示,V和K相等,Q为权重,dk表示词向量维度。
(1)
K=Wkh+b
(2)
计算过后的分词权重对于分类标签“体育”各不相同,如图2所示,颜色的深浅和线的粗细表示权重的高低。将权重前百分之四十的词进行掩盖,并去掉前面提示学习所加入的模板短句即“这是体育新闻”。最后获得“去年 今天 [mask] 同样 [mask] [mask] 金牌”的文本输入。

图2 自注意力机制的权重关系
2.2 促进训练模块
输入文本序列S={x1,x2,x3,…,xn。经过词嵌入后得到词向量e,通过Self-Attention Mask替换原BERT的掩盖机制。研究表明[11],被掩盖的词之间的联系也不能忽略,将被掩盖词组成向量e1和被掩盖后的输入文本向量e2拼接,得到输入向量H0作为BERT的输入向量,其中包括词向量、位置向量和类型向量。H0向量经过连续的L层Transformer得到最后的输出向量Hl。
E=AttentionMask(S)
(3)
H0=Embedding(E)
(4)
Hi=Transformer(Hi-1),i∈{1,…,L}
(5)
2.3 输 出
使用权重Wlab∈lab·d表示权重到标签的映射,其中的lab表示标签数量,最后使用SoftMax函数取最大概率为预测值输出。
pi=HlWlab+b
(6)
p(y|S)=softmax(pi)
(7)
output=argmaxp(y|S)
(8)
在训练的整个过程中,使用标准交叉熵函数优化训练任务。
(9)
3 实验结果及分析
3.1 数据集及数据处理
采用了THUCNews[12], TNEWS[13]两种数据集。虽然这两种数据集都是新闻类别,但是前者的文章长度较长,后者是短文本。所以在序列长度上前者设置为512,后者为128。详细数据如表2所示。

表2 数据集参数
为了实现全词掩盖,借助LTP工具进行文本分词。对特征提取不明显且有负面作用的高频率文本和特殊符号都会进行停用,例如“是”、“@#~”等。最后基于THUCNews和TNEWS分别构建相应的词库。
3.2 超参设置
为了更好的从已经存在的预训练模型中获取知识,实验中使用继承官方的中文BERT基准模型(12层Transformer,768的词向量维度)。不同大小、批次使用不同优化器可以提升训练速度。在训练THUCNews这类较大的批次时使用LAMB[14]优化器;在训练TNEWS这类较小的批次使用ADAM[15]优化器。详细模型参数见表3。

表3 模型参数设置
实验环境在Linux系统和NVIDIA A30 GPU上进行,实验所得数据使用结合精确率(Precision)和召回率(Recall)的F1值作为评判标准。具体公式如式(10):
(10)
3.3 对比实验设置及结果分析
实验中对比目前主流的预训练模型BERT,以及其变体RoBERTa。其中BERT,BERT-w和RoBERTa-w都是基准BERT模型,即12层的Transformer,词向量维度为768。“-w”表示全词掩盖。详细实验数据如表4。

图3 各模型在数据集THUCNews的Loss趋势图
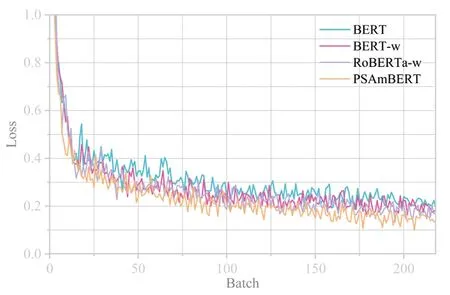
图4 各模型在数据集TNEWS的Loss趋势图

表4 不同模型在THUCNews和TNEWS 数据集结果对比
实验结果表明,无论是验证集还是测试集,PSAmBERT在THUCNews和TNEWS两种数据集上表现性能均优于现在流行的其他模型。图4和图5是不同模型在两种数据集上训练批次的Loss值变化细节。
从图3的loss趋势图中可以看出,各模型在在较大批次数据集THUCNews上的loss值在20批次左右已经开始趋近收敛,PSAmBERT相较其他模型在20批次之前的收敛速度更快,并且在20批次之后的整体loss值更低。从图4的loss趋势图中可以看出,在较小批次数据集TNEWS上,PSAmBERT相较其他模型的loss值更趋向稳定,并且平均loss值更低。实验结果可以看出,PSAmBERT在收敛的速度和模型的稳定性相比其他模型更优。
4 结 语
由于预训练任务和下游任务毫不相干,又舍弃不掉的问题。很难将预训练的大量知识应用到下游任务。研究者们提出的代表性解决方案有提示学习和微调,前者需要在原数据中加入标签化的模板,损害了原数据的结构和词数;后者微调的过程中易遗漏预训练模型在预训练阶段已学习到的大量知识。提出的模型基于提示学习需要添加模板的思想,在不改变原文本输入的情况下,利用自注意力机制进行掩盖高权重词,之后进行促进训练。研究中发现在数据集THUCNews和TNEWS上通过这样的模型训练,相较其他模型提升效果明显,准确度较高。在下一步工作中,希望将结合提示学习和自注意力的机制应用到更多任务,而不仅仅在文本分类上。
