基于区块链技术的公共图书馆线上数据库信息检索方法
2023-01-07刘家材
刘家材
(武汉职业技术学院 湖北 武汉 430000)
0 引言
互联网技术的发展以及网络技术的兴起在极大程度上加速了数字化建设的进程,以此为基础的线上图书馆在应用方面表现出的便捷性使用户群体在短时间内实现了大幅增加[1-2]。但是值得注意的是,由于公共图书馆线上数据库信息的规模较大,且资源之间的关联关系较为复杂,导致在信息检索阶段的时间开销较长,用户检索结果的满意度较低[3]。针对该问题,部分学者以线上数据库信息检索为目标,展开了对应的研究。其中,苏珂等[4]提出在对排序学习与预训练模型进行融合的基础上,设计了一种检索排序方法。在一定程度上提高了检索结果与用户检索目标的一致性,用户的满意度实现了有效提升。但是其在排序阶段的时间开销较长,难以满足现阶段高效的检索需求。梁少博等[5]以公共数字文化资源为研究对象,通过联合实体识别与翻译机制,实现了信息的跨语言检索,提高了检索的执行效率。在一定程度上缩短了对目标信息的检索时间,但是由于对实体的识别需要借助额外的辅助结构,因此在应用方面存在一定的局限性。结合上述信息检索的研究情况可以看出,进一步深化对信息检索方法的研究是十分必要的。
为此,本文提出基于区块链技术的公共图书馆线上数据库信息检索方法研究,借助区块链技术的优势,建立数据库信息资源之间的关联关系,确保检索阶段能够根据输入的内容在数据库内实现对目标资源的快速、准确定位。
1 公共图书馆线上数据库信息检索方法设计
公共图书馆线上数据库信息检索,有利于提高信息数据挖掘效果,为线上数据资源整合提供技术支撑。根据公共图书馆线上数据关联属性,将工作量证明机制作为区块链的共识协议,构建信息存储结构,降低线上资源数据重复搜索概率。采用相似度计算方式,提高公共图书馆线上数据库信息最终检索结果的可靠性,以偏差系数为依据得到满足检索目标的寻优结果,实现公共图书馆线上资源检索,有效降低了检索时间开销,增强公共图书馆线上数据库信息交互处理能力。
1.1 基于区块链技术的数据库信息结构构建
在信息检索阶段,由于基于公共图书馆线上数据库中包含的资源规模总量较大,且资源的种类较多,这就导致在以检索内容为基准在数据库内匹配目标资源时需要进行大量的重复计算[6-7]。这不仅增加了检索的时间开销,同时也降低检索结果的可靠性。为此,本文首先借助区块链技术构建了具有关联属性的信息存储结构。结合区块链技术的运行机制,本文对公共图书馆线上数据的存储交易建立在数字签名验证的基础上,并以当前区块为基准,对数据属性进行证明,确认满足要求后,将当前区块添加到对应区块链的尾部。在具体的设置过程中,本文将工作量证明机制作为区块链的共识协议,对应的公共图书馆线上数据区块链结构如图1所示。

图1 区块链技术的数据库信息结构
按照图1所示的方式,利用工作量作为区块加入的判断标准,以此确保整个数据结构中各个节点信息的共识程度保持一致。当公共图书馆中的任意数据存储在区块上时,表明该数据资源与对应的数据链中所有区块节点均有相同的属性,并且这一属性具有不可更改和持久的特点[8]。在此基础上,当数据成功存储到区块链上后,则对应数据为元数据,也就是具体的公共图书馆资源也存储到了该区块链。通过图1中的数据库信息结构可以看出,本文为区块链上公共图书馆资源构建的标签包括记录号、关键词以及数据签名。通过这样的方式降低在检索阶段对海量可连接数据重复搜索的问题,利用关键词可以最快速度确定目标信息的检索范围。对于数据签名的设置,本文以公共图书馆资源的特定属性为基础,具体的计算方式可以表示为:

其中,k表示数据签名的设置结果,x表示经过某规则检索后的属性参数,Q表示某公共图书馆资源中包含的所有属性信息。
通过这样的方式,构建以区块链技术为基础的公共图书馆线上数据资源库。通常将数据集(水平划分)作为一个域,将其元数据作为公共图书馆线上数据库信息结构,为后续的检索机制执行提供可靠基础。
1.2 基于相似度的信息检索
研究人员在完成对公共图书馆线上数据库信息结构的构建后,为了提高最终检索结果的可靠性,降低检索过程的重复操作。本文以检索内容为基准,与区块链结构下的公共图书馆线上数据库信息进行相似度计算[9-10]。
假设检索栏输入的检索内容为y1,首先借助工作量证明机制计算与其对应资源链,在此基础上,匹配其与当前区块的相似度。具体地方计算方式可以表示为:
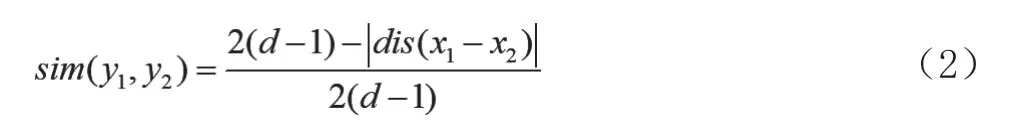
其中,sim(y1,y2)表示检索内容与当前区块y2资源的相似度,d表示区块链结构下数据库的最大深度参数,x1和x2分别表示y1和y2的经过规则检索后的属性参数,dis(x1-x2)表示x1和x2之间的偏差系数。根据式(2)可以看出,dis(x1-x2)的取值结果越小,则资源y2与检索内容y1的相似度sim(y1,y2)越大。对应资源y2与检索内容y1的匹配程度越高。也就是说,链上信息资源与检索内容的属性偏差系数越小,二者之间的拟合度越高,对应资源与检索目标越接近。结合这一理论基础,对于目标信息检索问题就转换为了对最小dis(x1-x2)的寻优问题。
对于具体的寻优方式,本文设计了如图2所示的执行方案。

图2 检索信息匹配结果寻优方式
如图2所示,在对检索信息匹配结果寻优的过程中,本文根据y2资源的记录号对具体的寻优方向进行控制。当dis(x1-x2)为负值时,则沿数据链向前与对应区块上的资源进行相似度计算;当dis(x1-x2)为正值时,则沿数据链向后与对应区块上的资源进行相似度计算。直至计算结果满足
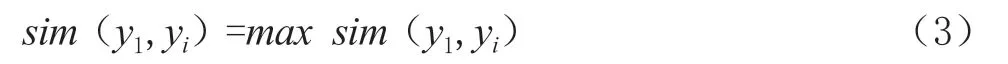
将对于区块上的资源作为最终的检索结果,输出的交互页面。由此完成对信息的检索。
2 测试与分析
2.1 测试环境设计
在对本文设计的基于区块链技术的公共图书馆线上数据库信息检索方法应用效果进行测试阶段,分别采用苏珂等[4]方法和梁少博等[5]方法作为测试的对照组,通过对比上述三种方法的检索结果,对本文设计方法的应用价值进行分析。
2.2 测试方法
本文以某数字图书馆数据库内的资源子集作为基础测试环境,对应的信息规模总量分别为10.0 T、20.0 T、30.0 T、40.0 T、50.0 T。在此基础上,分别设置了10 条不同的固定检索内容作为检索信息,采用三种方法实施检索。考虑到除了检索结果的可靠性外,信息检索的执行效率也是评价检索方法的重要指标之一。因此,本文对不同检索方法的响应时间进行约束,根据现阶段检索方法的平均响应时间,以30 s 作为临界标准,当信息检索方法未能在30 s 内针对检索内容做出反馈,则判定对应的测试失败,测试结果取0。
对于测试结果的评价,本文结合信息检索的实际需求,分别设置召回率、查准率作为评价指标。其中,利用召回率对检索结果的查全情况进行分析,利用查准率对检索结果的精准情况进行分析。
2.3 测试结果与分析
首先,统计了三种方法在不同规模数据子集下的召回率,得到的数据结果如表1所示。

表1 不同检索方法召回率统计表
通过对比表1中的检索结果可以看出,随着测试数据库子集规模的不断增大,三种方法的召回率测试结果均出现一定程度的下降。其中,苏珂等[4]方法的下降幅度最大,当检索数据子集的规模由10.0T 增加到50.0 T 时,召回率降低了4.22%。相比之下,梁少博等[5]方法的下降程度与之相比幅度较小,但是也达到了3.77%。而在本文设计方法的检索结果中,召回率的下降程度仅为1.86%,与对照组的两种方法相比表现出了更高的稳定性。不仅如此,通过对具体的召回率进行分析可以发现,苏珂等[4]方法的召回率最大值仅为84.44%,梁少博等[5]方法的召回率最大值也仅为86.02%。而在本文设计方法的测试结果中,召回率的最大值达到了88.45%,分别高于苏珂等[4]方法和梁少博等[5]方法4.01%和2.43%。测试结果表明本文设计的基于区块链技术的公共图书馆线上数据库信息检索方法能够实现对信息的全面检索。
其次,统计了三种方法在不同规模数据子集下的查准率,得到的数据结果如图3所示。

图3 不同检索方法查准率对比图
通过观察图3中的测试结果可以看出,在三种检索方法中,苏珂等[4]方法和梁少博等[5]方法对应的查准率表现出明显的下降趋势。随着测试数据子集规模的增加,两种方法查准率的整体下降程度基本相同,当测试数据子集的规模达到50.0T 时,对应的查准率分别为80.44%和79.62%。但是相比之下,本文设计方法的检索结果查准率虽然也呈现出了一定程度的下降,但是下降程度明显低于苏珂等[4]方法和梁少博等[5]方法。当测试数据子集的规模达到50.0 T 时,对应的查准率也达到了88.60%,分别高于对照组8.16%和8.89%。不仅如此,从整体角度分析,本文设计方法的查准率也始终明显高于另外两组测试结果,表明本文设计的基于区块链技术的公共图书馆线上数据库信息检索方法能够实现对目标信息的精准检索,在线上公共图书馆中具有一定的应用价值。
3 结语
为了提高用户对线上图书馆的使用感受,本文从信息检索的角度出发,设计了一种基于区块链技术的公共图书馆线上数据库信息检索方法,通过建立数据之间的关联关系,提高了检索信息与数据库资源之间的匹配效果,使得检索过程更加高效,检索结果也更加准确。通过本文的研究,希望能够为实际的线上数据库信息检索机制构建提供参考价值,提高公共图书馆资源的利用率。
