一种基于深度学习的网络新闻分类模型
2023-01-07胡丰麟朱立忠通信作者
胡丰麟,朱立忠(通信作者)
(沈阳理工大学自动化与电气工程学院 辽宁 沈阳 110159)
0 引言
随着互联网技术的发展,新闻作为信息的重要载体呈现出爆发式的增长,深度神经网络也正在逐步取代传统算法和机器学习。与英语和其他语种的文本分类相比,中文文本分类由于汉字的独特性变得更加困难。最初的文本分类是通过建立专家规则进行分类,但由于在灵活性、可扩展性和分类效果等方面存在许多不足,并未取得过多的关注。支持向量机、K 邻近、决策树和最大熵等机器学习算法由于对文本处理的效果较好,成为常见主流算法。当数据量非常大时,这些算法在处理时成本较高。
1 相关研究
近年来,由于深度学习模型能够捕捉语义词关系,在性能上优于传统的机器学习方法,因此在文本分类中使用深度学习模型引起了广大学者极大的兴趣。使用分布式表示方法来表示单词和短语,不仅可以获得单词在语言前后的关系特征,而且避免了数据的高维和稀疏问题。Liu 等[1]提出了一种可以在中文文本中提取上下文信息的模型,这种模型主要是运用LSTM 来对文本的上下文特征提取。在2013年,谷歌公司发布的Word2vec 工具可以将文本进行向量化,从而得到文本的词向量,挖掘出更加深层的联系,而且Word2vec 输出词向量可以输入到其他的深度学习网络模型中进一步处理,极大地提升了文本分类的准确率。由于Word2vec 模块的完善,人们已经可以利用它对大量文字数据进行训练,把文字表示成低维稠密的矢量空间,从而降低了大量文字数据存储的困难度,并考虑到词语之间的关联,从而更好地描述了大量文字数据,这将极大地促进深度学习技术在文字分析上的发展和应用[2]。闫秘[3]对fastText 算法进行改进,通过改进特征向量的权重,以及替换数据集中主题词来提高模型的分类效率。肖琳等[4]都将注意力机制与CNN和RNN的结合应用到了文本分类问题中。陶文静[5]在新闻文本分类任务的研究中提出了一种改进的卷积神经网络模型,在多个数据集中取得了不错的效果。殷亚博等[6]将卷积神经网络和K 邻近算法相结合,通过卷积神经网络对文本特征进行提取,KNN 分类器进行分类。经过测试,该模型在多个数据集都有着较好的分类效果。高云龙等[7]通过在全连接层增加稀疏编码的方法来降低模型的复杂度。该模型经过反复实验,具有较好的文本分类效果。胡杰等[8]提出了一种新模型,将卷积神经网络和随机森林算法结合,通过卷积神经网络提出文本特征,随机森林对文本进行分类。陈可嘉等[9]将卷积神经网络和长短时记忆网络相结合,通过将卷积神经网络进行动态池化来提出更多的文本特征。经过实验对比,该模型比其他模型拥有更高的精度。
传统的CNN 网络不能解决由于文本分类任务中上下文之间存在很强的依赖性和连续性,导致模型精度较低的问题。本文提出了一种卷积神经网络(CNN)和长短期记忆网络(LSTM)的混合文本分类模型,通过实验,该模型与其他传统的深度学习模型相比具有更高的准确率。
2 基于CNN-LSTM模型的方法
CNN 和LSTM 的混合模型主要是保留了各自的优点,通过Word2vec 预处理所获得的词向量输入在CNN 的卷积层中,把CNN 的输出视为LSTM 第一层的输入,在每一层的输出都做归一化处理。该模型既解决了CNN 模型只能提取局部特征的问题,又能够解决上下文的依赖关系,有效地提高了模型的准确率。
2.1 Word2vec 词向量
由于神经网络需要输入的是向量,需要先对新闻文本进行预处理,将新闻文本映射成为向量,Word2vec 就是一个用来生成词向量的工具。CBOW 和Skip-gram 是Word2vec 的两个模型,CBOW 通过上下文预测目标词训练得到词向量,并在小型语料库上使用;Skip-gram 是用一个词去预测它文本序列周围的词,适合在文本预料较多时使用。Skip-gram 模型中每个单词在做中心词前,都会经过K 次的检测和微调,而这样反复的微调就会导致单词向量的变化比较精确。由于本文的新闻数据量较大,决定采用skip-gram 模型对文本进行预处理。
Skip-gram 模型,其训练复杂度为:

式(1)中,C 为Word2vec 模型输入层的窗口大小,D表示词向量维度,V 表示训练语料的词典大小。
2.2 CNN-LSTM 模型
长短时记忆网络和卷积神经网络在处理文本分类任务上都有各自的优势,CNN 虽然能够保留文字的全局度量特性,并合理地挖掘文本中所有可能的语义关联现象,但却不能处理文本上下文的相互影响现象和上下文语义关联现象。而由于LSTM 具备了对长期语境信息依赖的特点,可合理使用和记忆更大程度的长期上下文语义关联,从而有效地分析文本序列的含义。因此根据二者的结构特征,在本文中建立了一个CNN-LSTM 架构,作为对信息的分析。CNN-LSTM 的网络模型结构如图1所示。

图1 CNN-LSTM 网络模型结构
卷积层:文中利用三层一维卷积,每个输入层包含一个向量序列,并使用固定大小的滤波器进行扫描,检测文本的不同特征。在激活函数的选择上,比较常用的是Sigmoid 函数,但是这个函数的计算量比较大,在训练深度网络时容易出现梯度消失的问题,因此决定使用ReLU作为激活函数。这个函数更像一个线性函数,当神经网络的行为是线性或接近线性时会更容易优化,也是因为此特性,在使用这个激活函数进行训练的网络几乎完全避免了梯度消失的问题,训练的速度也会比前者更快。
Batch Normalization 层:和Dropout 的作用相似,都是起到了防止模型过拟合的作用,而且相比Dropout,Batch Normalization 的调参过程也相对简便一些,能够有效地提高模型的学习率,提高模型的训练速度和收敛过程,作用在每层卷积层之后。
池化层:在BN 层之后,采用max-pooling。选用最大池化层是为了捕捉最重要的特征并减少高级层中的计算。应用衰减技术来减少过拟合,衰减值为0.5,这样做能够保留全局的序列信息。
时序层:该层具有一定数量的单元,每个单元的输入都是卷积层的输出。通过LSTM 来解决在长文本中,CNN 无法捕捉上下文中存在的依赖特性关系这一问题。
输出层:采用Softmax 分类器,使用Softmax 函数对获得的特征T 进行分类。由于T 是一个向量,因此不可能基于T 直接确定文档的类别。因此,Softmax 函数用于执行规范化方法,以获得文档属于特定类别。公式如下:
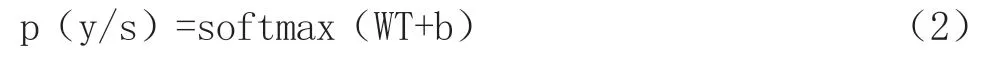
文本预测的标签公式如下:

该模型中使用的损失函数是交叉熵损失,并引入了L2正则化。公式定义如下:
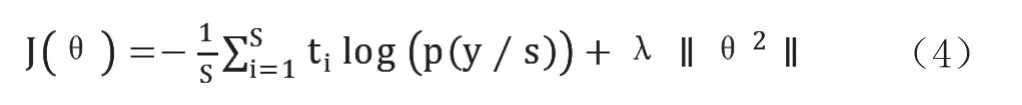
t 是文本真实标签的概率,p(y/s)是具有Softmax函数的每个类的概率,s 是目标分类数,λ 表示模型的复杂损失占总损失的比例。经过Softmax 函数得到每个类别的概率,完成文本分类的任务得到最终的分类结果。
3 实验结果分析
本实验所用的资料集为清华大学自然语言处理研究室提供的中文文本分析资料集。THUCNews 数据集包括了740 000 个新闻文本,十四种新闻类型。文本采用了其中的十种类型,并选取50 000 条新闻数据作为训练集,10 000 条新闻数据作为测试集。为了满足深度学习对于数据量的需求,将已经标注好的网络新闻文本中的词语通过同义词替换等方式来扩充数据。使用softsign 和Adam 作为Textcnn 和CNN-LSTM 的激活函数和优化函数,来测试两种算法使用相同数据集的准确率和损失函数,结果如图2和图3所示。
从图2和图3得出,CNN-LSTM 模型比Textcnn 模型拥有更加的准确率,且损失函数下降比较平稳,说明了此模型相对其他算法模型具有良好的稳定性。

图2 Textcnn 的accuracy 和loss 趋势变化
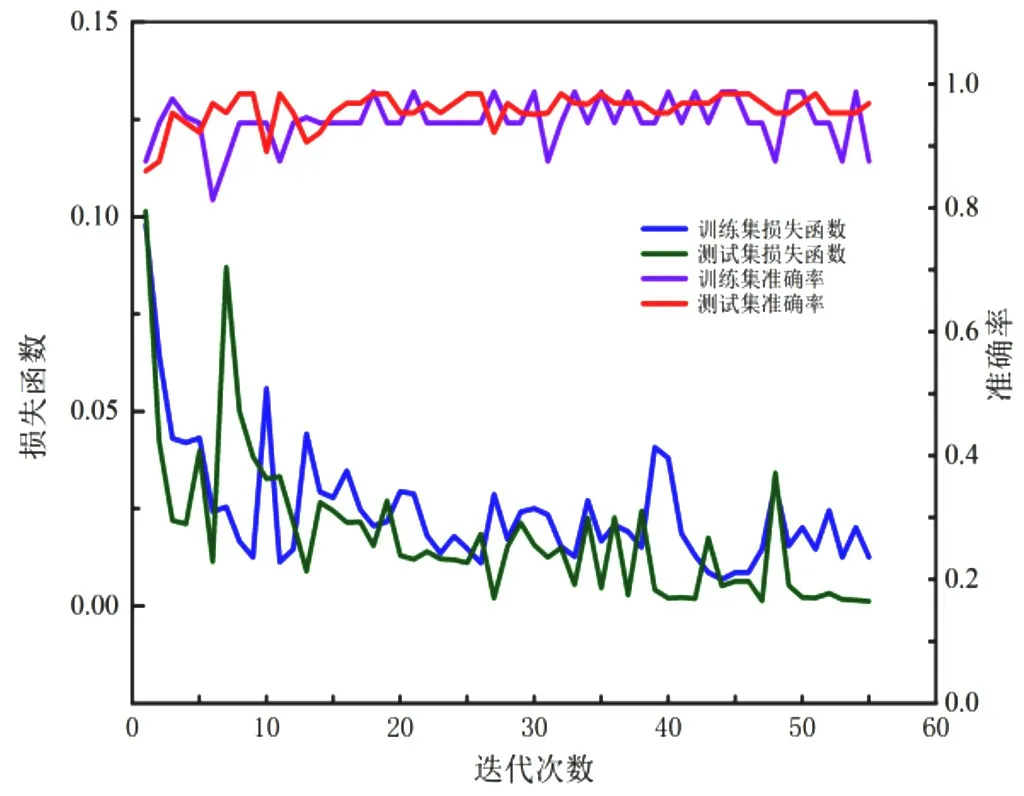
图3 CNN-LSTM 的accuracy 和loss 趋势变化
接着将Textcnn、LSTM 和CNN-LSTM 的准确率进行对比,如表1所示。

表1 分类准确率对比
从表1可以看出,三个模型的准确率分别为0.910、0.864 和0.962。其中CNN-LSTM 的准确率达到了0.962,比Textcnn 的准确率高出了0.052,与LSTM 相比准确率更是高出了0.98,说明了CNN-LSTM 模型能够进行更精确地分析,有着更高的准确率,能够有效地提高文本分类的效果。
实验数据表明,这个结构的CNN-LSTM 模型与传统的深度学习模型相比,具有较高的准确率,训练效果比传统的模型有较显著的提升。该模型在保证每条数据结构不变的情况下,挖掘出更深层的语义结构,更好地表达数据的原始特征,有助于提高文本分类的效果。
4 总结
针对传统的深度学习模型在文本分类任务上的准确率不高的问题,文中提出了一种将CNN 模型和LSTM 模型的优势相结合的混合模型,将CNN 的输出作为LSTM 的输入,并在原始的卷积神经网络的基础上,采用计算速度和收敛速度更快的ReLU 函数作为模型的激活函数,将BN 层加入到卷积神经网络中来加快网络的收敛速度。通过实验比较,在对海量的新闻信息进行分析时,混合模型的准确率达到了96.2%,说明混合模型比传统的深度学习模型拥有更高的预测精度,具有更好的分类效果,因此能适用于网络新闻的分类任务。
