“新基建”背景下的工程英语的词频数据分析
2022-12-20周世俊李波
◎周世俊 李波
一、研究目的
为响应国家“新基建”号召:加快推进国家规划已明确的重大工程和基础设施建设,加快5G网络、数据中心等新型基础设施建设进度,作为重要的基础产业和新兴产业,“新基建”一头连着巨大的投资与需求,一头牵着不断升级的强大消费市场,是中国经济增长的新引擎。当前,大数据产业已经成为我国数字经济发展的重要引擎。随着国家加大力度支持新基建发展,人工智能、5G、物联网、数据中心等产业有望驶上“高速路”,这对国内大数据产业来说也是一大关键利好。由之前际高速铁路和城市轨道交通、新能源汽车充电桩、大数据中心、人工智能、工业互联网这几大领域,又新增5G、超高压,对数字化、智能化的重要的程度越来越高,从而加大对外业务工程的需求,对外业务工程对英语的需要也越来越高,而工程英语多为生僻词汇且词汇量庞大,翻译起来困难是造成对外业务发展极大的不利因素,大大降低工作效率,所以对工程英语有极高的需求,进行英语词频数据分析有助于建立工程英语词库,来更好的找到所需的单词来进步对业务的交涉大大增加对外业务工程的效率,从而间接增加经济效益。
二、数据来源及处理方法
(一)数据来源
本文章所涉及的数据来自于长春工程学院的“新基建”+”一带一路”涉外工程英语应用研究的创新团队,本文所包含的据都是一些国内外所达成的工程合同,这里在本文中不支持展示。
(二)处理方法
在目前国内的对外的工程合同大部分都是用pdf的形式来进行保存,首先我们得将pdf形式转成word形式或者txt文档的形式,通过python的一些库或者自定义函数的用法来统计词频,通过python的wordcloud库来进行词云图的制作,词云图可以帮助我们更好分辨不同元素的重要性,对文本出现频率较高的文本信息进行展示。

(三)操作步骤
1.将文本转换成中文进行处理。
(1)读取文件。
①可以将PDF文件用相关软件转换成word或者txt文件来进行读取,不过因为在相关软件下转换时会发生乱码的存在就不能很好的达到想要的那种效果。
②在读取PDF文档的时候可以在python中选择安装pdfminer或者PyPDF2这个库来进行读取,不过对于PyPDF2这个库来说的话,只支持英文,对中文支持不太好,相对于PyPDF2来说,pdfminer支持多种语言、图表、图片等,功能较为强大。对于pdfminer是一个从pdf文档提取信息并且完全专注于获取和分析文本数据的工具,所以说对于要对工程合同进行数据处理的话,可以考虑这个工具包,里面有专门的模块来进行存储,获得数据、解析page内容,最为关键的是可以不去读取图片,防止工程合同中存在一些图片导致程序报错。像一般python2和python3不兼容这点也着重注意需要对应的pdfminer版本。
③对word文档进行读取的可以使用python-docx库进行读取,python-docx库可以读取表格里的内容,像word进行保存时可能是docx或者是doc形式,不同的存储格式需要不同的python库。
(2)翻译且进行保存。
可以将文档中的进行读取后,要做一个爬虫来进行翻译,像百度翻译、谷歌翻译、有道翻译等这个翻译网站来爬取或者是直接进行翻译,这里用爬取百度翻译为例:
①首先百度翻译,是使用ajax的局部的刷新技术,进入百度翻译的页面,在翻译面板中随便输入或者删除一些字比如把“吃早饭”变成“吃饭”就会出现“sug”,获得url。

②进行UA伪装,在python对网页进行请求时,会直接以一个爬虫的形式去请求网站,这样的话就会被大部分网站给禁止,所以在这进行UA伪装能帮助我们找到百度翻译的接口。
③获得数据,然后将数据存储在word、pdf、txt文件。
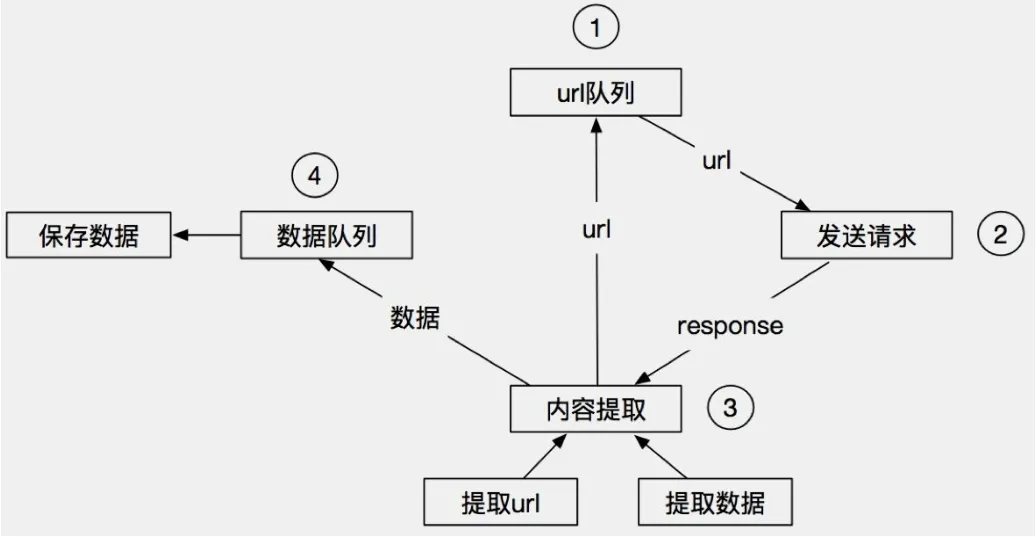
(3)进行词频分析并制作词云。
①下载jieba、wordcloud库。
第一种方法,可以去官网中寻找jieba、wordcloud库一定要找好对应自己python版本的库,不然会报错或者找不到该程序,将下载whl文件复制到自己python的Script文件下,然后在命令指示符那输入pip install+Script路径+所下载的jieba和wordcloud的文件全部名第二种方法,在python的开发工具pycharm中setting中进行下载或者直接在在命令指示符中输入pip install+库名,也可以用清华的镜像的方法来进行下载
②进行分词和数据处理。
像英文的话有空格区隔就相当于分词了,但是中文不行,中文有词语,成语这些的,这时候就需要运用到分词库了,jieba、pynlpir库都是中文分词库,本文章使用的是jieba库,它可以进行分词,命令行分词,还支持关键词提取等,同时还有jieba库分词有三种模式:第一种精确模式、第二种全模式、第三种搜索引擎模式,所以说jieba库是十分好用的。首先先import jieba再定义一个函数readfile()读取文本文档内容(像这里的读取方法。上文已经论述过了)在读取过程中要注意文本保存内容的编码,不然读取的内容会是乱码,然后给读取的文档内容返回回来,其次可以进行一个简单的预处理定义一个函数clean(),使用一个for循环对于文本中存在的标点符号去除,最后进行分词处理,在这定义一个wordcount()方法像这里本文章使用jieba。lcut()方法进行分词,这里在定义一个空的字典然后可以进行一些无用字的处理,像一些“啊,嗯”等这些无价值的词,像可以在百度上寻找停用词表,很容易就能找,像这里本文使用的是哈工大的停用词表,将停用词表进行一个分词然后以列表的形式进行存储,然后用if-else语句进行一个遍历将合同里的无价值的词给优先删除,然后在将删除完停用词的内容存入sdict字典然后将字典类型强制类型转换成列表,以词频从多到少的写入列表中,函数最后将列表返回。最后定义writeFile()函数将处理完的数据存入txt的文件。

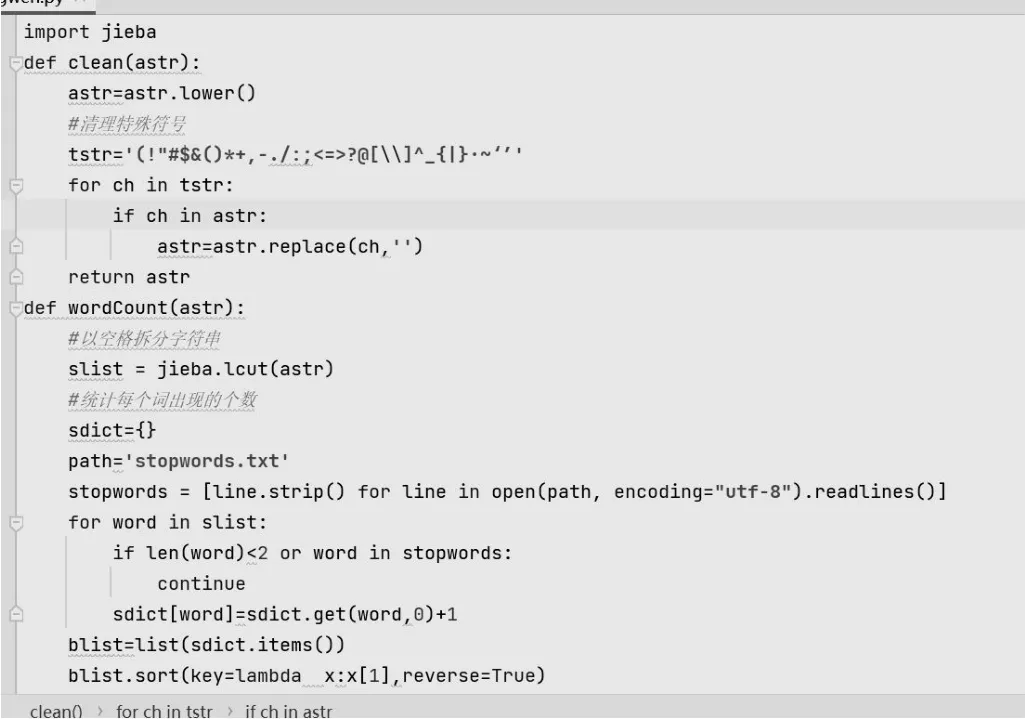
部分代码展示以部分可见内容展示
(4)进行词云图制作。
wordcloud可以对文本中出现频率较高的词语给予视觉化展示的图形,这个库的wordcloud。WordCloud()方法可以进行对画板大小的构建,背景的颜色,字体等等一系列的自定义,或者是可以自定义词云图的形状,可以选择一个图片形状来自定义词云图的形状。本文展示简单的制作云图的代码,如下图:


2.将英文文本进行处理。
读取文件文件在上文都已经进行过仔细的讲解可以去上文继续了解了解,英文文档可以直接进行处理,像前文的clean()、fenci()、wordcount()、readfile()方法几乎都是一样,就是比较注意的一点是英文分词是不需要进行分词,就是不需要像中文那样jieba库来特地的进行分词,像英文就是一个单词一个空格,所以可以用python自带的split()函数(split()函数是对指定的分隔符对字符串进行切片,并且以列表的形式返回已经分隔完成的字符串列表)进行分隔,最终进行打印存储到txt文件里面,最后进行词云图的制作,来展示合同中高频出现的关键词。


四、结束语
本项目从“新基建”下的工程合同出发进行数据分析以及词云图的制作,我们采取现在新兴的python语言来进行数据的清洗、提取等一些操作,同时本文章在读取工程合同时采取不同python库来进行读取,展示python语言的简单以及方便性,在处理数据方面也没使用过难的技术都是采取了函数的方法来进行处理,最后做出词云图。这同时也为我国涉外工程对工程合同处理提供了一个思路,也为我国涉外工程解决了一些实际的需求。
