基于机器学习的乳腺癌预测研究
2022-11-20张浪张星钱佳怡杨霜玲
张浪 张星 钱佳怡 杨霜玲

摘要:通过对kaggle官网关于乳腺癌的相关数据集的分析,文章选取了数据集中相关性较强的10个指标,对各个指标进行数据处理,使用随机森林、XGBoost、相关性分析进行模型建立分析。通过机器学习,得到相关结果以及准确率、精准率、召回率和F1,并通过比较不同算法之间准确率、精确率的差异,得出最优的预测研究方案机制。通过模型对比评价,XGBoost算法的准确率、精确率等均在93.5%以上,随机森林算法的准确率、精确率等均为92.4%。相比之下,XGBoost模型预测效果较佳。利用机器学习研究乳腺癌的预防预测,并应用于实践,对乳腺癌早期诊断有着十分重要的意义。
关键词:机器学习;乳腺癌;随机森林;XGBoost;相关性
中图法分类号:TP181文献标识码:A
Breast cancer prediction research based on machine learning
ZHANG Lang,ZHANGXing,QIANJiayi,YANGShuangling
(Guizhou Medical University,Guiyang 550025,China)
Abstract:Based on the analysis of the data set related to breast cancer on kaggle official website,10 indicators with strong correlation in the data set were selected for data processing.Random forest, XGBoost and correlation analysis were used for model establishment and analysis.Relevant results, accuracy,accuracy,recall and F1 were obtained through machine learning,andtheoptimal prediction research scheme mechanism was obtained by comparingthe difference of accuracy and accuracy among different algorithms. According to the evaluation of model comparison,the accuracy and accuracy of XGBoost algorithm are above 93.5%,and those of random forest algorithm are both 92.4%.XGBoost model has better prediction effect in comparison.It is of great significance for the early diagnosis of breast cancer to study the prevention and prediction of breast cancer with machine learnig and apply it into practice.
Key words: machine learning, breast cancer,randomforests,XGBoost,dependency
1 研究背景
乳腺癌是乳腺細胞在内外环境因素影响下发生了异常细胞增殖反应而最终失控导致癌变的临床现象。其病变初期常表现出的症状为出现乳房肿块、乳头溢液、腋窝淋巴结的明显充血肿大或压痛感等各种局部症状,晚期患者也可能因淋巴结被癌细胞直接感染,导致发生了肿瘤及远处组织淋巴性转移,出现了乳腺周围多部位淋巴器官良性增生及病变,甚至可能威胁乳腺患者的生命[1]。根据医疗数据显示,全球乳腺癌的发病率逐年升高,这对社会经济发展造成严重影响,乳腺癌的早期诊断,尤其是当病灶尚不能被触及时,若能及时发现,可以明显改善预后。人工智能的发展可以协助医生工作,帮助组织、理顺和简化诊断程序或其他医疗决策过程。利用数学模型以及统计方法分析数据资料,能够依据乳腺癌的相关特征对乳腺癌进行细致分类,从而应用于临床,实现对不同个体的诊断和预测。机器学习算法在乳腺癌预测的应用,有利于乳腺癌的风险评估,从而帮助患者了解自身疾病特征,达到预防疾病的目的;对乳腺癌进行分级诊断,从而根据特征施行相对应的治疗方案,这对乳腺癌的“对症下药”、分级诊断和预防有着特别重要的意义。
2 研究现状
在以计算机学科为研究对象的背景下,很多学者应用理论与技术的结合,以提高乳腺癌预测的检测水平。乳腺癌是乳腺上皮细胞在多种致病因子的作用下,发生增殖失控的现象。刘宇等[2]将聚类算法与XGBoost算法结合在一起,应用K?means算法对所收集的数据按照其各自的特征进行了区分,并且利用XGBoost算法对乳腺癌进行了预测和分析。国内外专家学者针对乳腺癌的研究已经取得了一定的成果,随着医疗信息化的发展,人们开始使用信息技术解决乳腺癌诊断治疗中的问题,目前利用特征因素对乳腺癌进行预测是该领域研究的热门。并且,随着乳腺癌研究的深入,人们意识到单一的生理指标并不能对乳腺癌做出很好的预测,所以开始基于大量数据来分析、挖掘各种指标之间的联系以及对结果的影响,从而建立起一些常见的乳腺癌的预警模型[3]。比如,DL 模型帮助患者提前五年预测乳腺癌,实现及早确诊、及早治疗;我国自主研发的治疗乳腺癌抗 HER2单抗创新药伊尼妥单抗打破进口药垄断。
3 数据及可视化
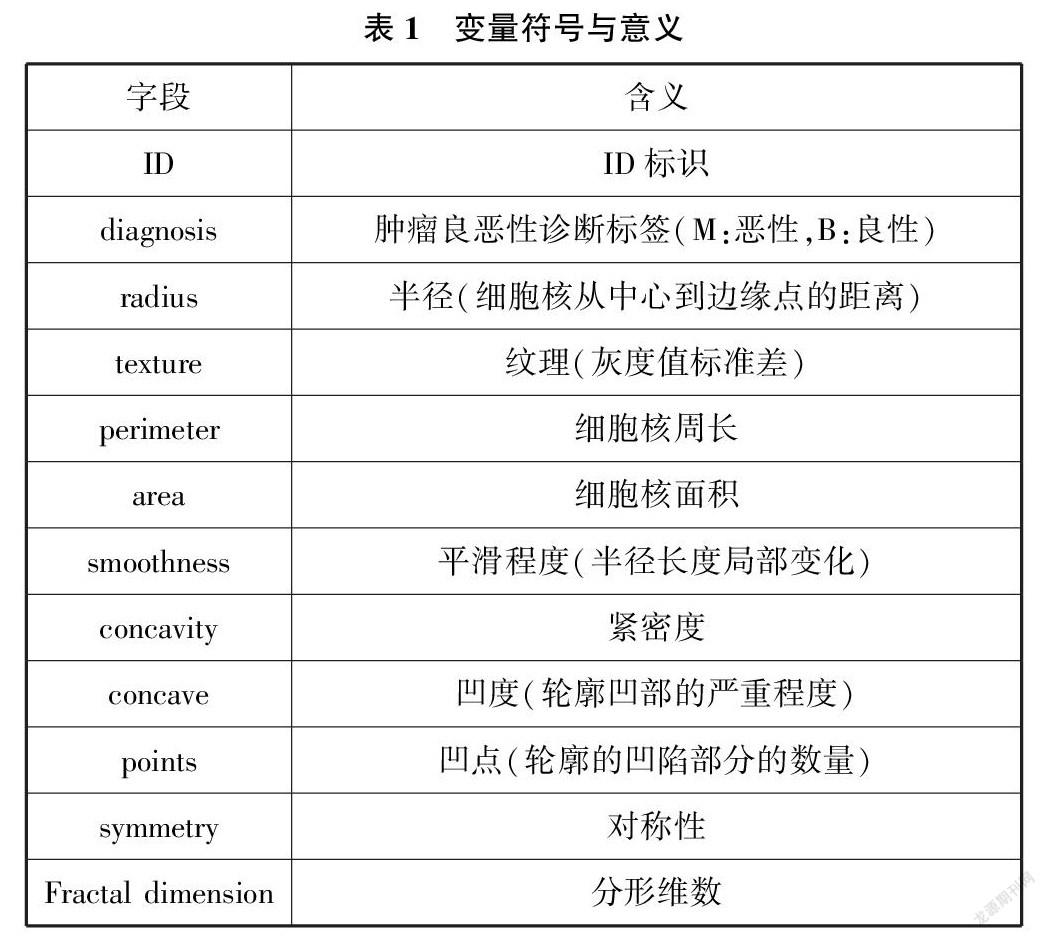
本文数据来源于kaggle官网关于乳腺癌的公开数据。样本数据共569条,包括10类影响指标,即半径、纹理、细胞核周长、细胞核面积、平滑程度、紧密度、凹度、凹点、对称性、分形维数。通过对不同类型数据的整理,使用机器学习算法对数据进行定量和定类分析及训练。数据变量如表1所列。
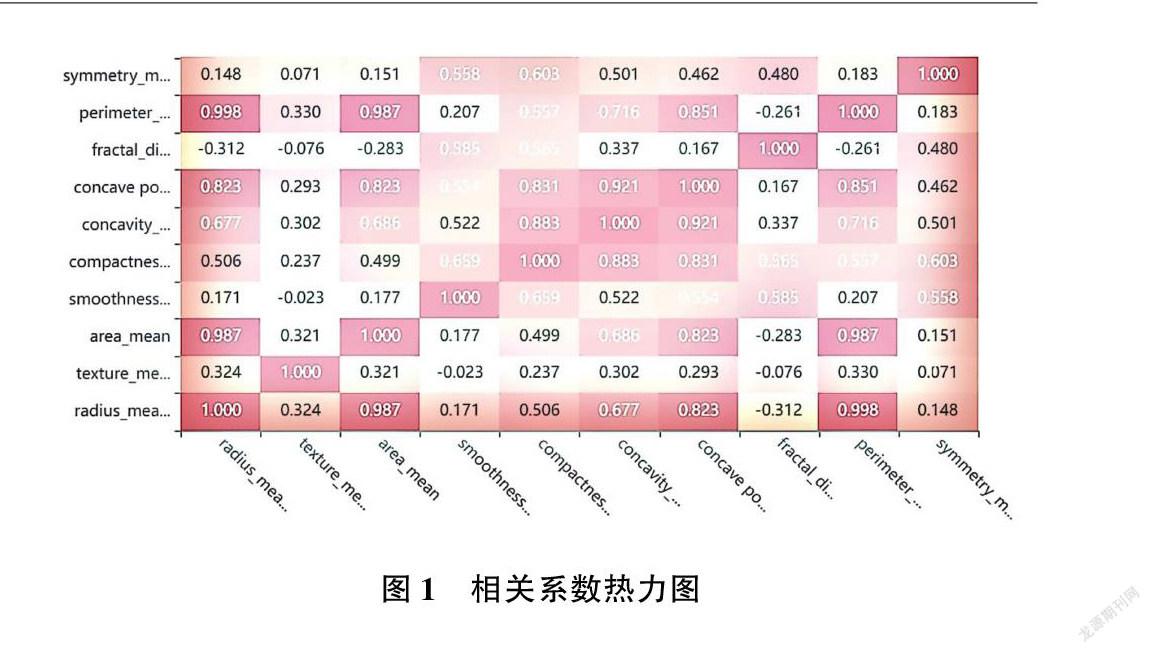
图1为利用各类指标数据构建相的关系数热力图,样本呈现正太分布状态。组织核的平均面积与半径和参数的均值呈强正相关;一些参数中度正相关( r 在0.5~0.75之间)的是凹度和面积,凹度和周长等;同样,可以看到 fractal_ dimension 与半径、纹理、参数平均值之间存在一些强烈的负相关。由此可以推断,乳腺肿块的细针抽吸物(FNA)半径、周长、面积、紧密度、凹度和凹点的平均值可用于癌症的分类。这些参数的较大值倾向于显示与恶性肿瘤的相关性。质地、平滑度、对称性或分维数的平均值并未显示出较好的诊断偏好。
4 实验过程和结果分析
本文选取相关性分析、随机森林、XGBoost三种机器学习方法对乳腺癌吸针抽物相关特征进行对比分析,以实现对乳腺癌的早期预测。通过统计产品与服务解决方案软件 SPSS 进行算法分析,建立测试集和训练集;以预测分析结果中的预测准确度、精确率、召回率、F1为主要评判参考指标;同时,通过建立混淆矩阵,对预测分析模型中的实际可用于预测对象的预测能力水平等进行综合量化与评判。通过统计产品与服务解决方案软件 SPSS 进行算法分析可得随机森林和XGBoost特征重要性的结果分析,结果如图2所示。
图2展示了各特征(自变量)的重要性比例。通常情况下,特征越多分类效果就越好。但是,使用过多的特征会大幅增加模型运算量和模型运算的时间、费用等成本,降低整个模型的平均运算效率。因此,本文对相关数据进行了特征选择,随机森林和XGBoost按照数值大小呈正比,表现出重要性程度高低,计算出特征重要性。通过随机森林特征重要性排名进行结果比较,对特征进行分析可知,面积、周长、半径能够较为直接衡量细胞核的相关特征,同时凹缝、凹度也属于重要的特征值,有较强的区分度;对比XGBoost特征可知,凹度、周长、半径能够较为直接衡量细胞核的相关特征,同时凹缝、面积也属于重要的特征值,有较强的区分度。对特征值取平均值,在统计上平均值反映出的是更加普遍的情况,具有更强的可用性。
训练数据集是指构建模型时使用的样本集,而测试数据集是指对最终模型进行性能评估的数据集,通过矩阵工厂 MATLAB、统计产品与服务解决方案 SPSS 进行混淆矩阵热力图分析。
混淆矩阵利用了准确率 A( Accuracy)、精确率 P (Precision)、召回率 R(Recall)和 F1四个评价指标来进行定量和评估分类器系统的分类效果与性能。准确率表示分类正确的样本数在整个样本中所占的比例,准确率越高,则预测越准确;精确率表示分类正确的正类样本数占分类为正类样本总数的比例;召回率表示分类正确的正类样本数占原正类样本数的比例; F1是精确率和召回率之间的折中,F1测度值越高,则分类效果越好。各指标的计算公式如表2所列。
其中,TP =真正例,TN =真负例,FP =假正例,FN =假负例,ncorrect=TP+TN,ntotal=TP+TN+FP+FN
由表3可知,在相同的数据集下,XGBoost分类的准确率为93.6%,而随机森林的准确率为92.4%,其准确率越高说明算法越好。由此可见,XGBoost算法比随机森林精准。F1值综合了精確率与灵敏度的大小,由表3可知,在 F1值方面,XGBoost分类模型的 F1高于随机森林分类模型1.2%,精确率高1.1%,召回率高1.2%。本文认为,通过对准确率、F1值、召回率、精确率的对比,XGBoost分类模型比随机森林分类模型有所提高,因此可以认为该模型对辅助医生诊断乳腺癌,对乳腺癌分类预测研究具有较大的意义,有较强的可行性。
5 结论
本文着重对乳腺癌的分类预测进行研究,通过对数据的处理,建立相关预测模型,并对模型准确度进行对比评价。模型显示,乳腺吸针抽物的凹度、周长、半径、面积对乳腺癌早期监测有较好的指标作用,这对如何实现低成本、检测快、无副作用的乳腺癌患者的分类预测非常重要。同时,对于慢性疾病管理也具有重要意义,但是由于收集资料和时间有限,未来的研究中,需要从以下方向进行改进:(1)慢性疾病是一类疾病的总称,本文仅构建了乳腺癌疾病预测和预测系统,接下来可以对其他慢性疾病的预测进行研究:在建模时选取 UCI 公开数据库里相关数据,一方面在区域性和时限性存在缺陷,另一方面数据量有限,在建立模型时可能导致模型欠拟合,未来可以采用不同的数据集对模型进行修正,以提高预测的准确性;(2)对于慢性疾病患者而言,做好康复和护理是必不可少的一步,这也是医护人员所关注的重点之一,所以未来可以在该系统上进行功能完善,建立“医护康”一体化信息平台,实现对慢性疾病患者的全生命周期管理。
参考文献:
[1] 祝江涛.分析乳腺癌患者术后睡眠质量及相关影响因素[J].世界睡眠医学杂志,2021,8(8):1330?1331.
[2]刘宇,乔木.基于聚类和XGboost算法的心脏病预测[J].计算机系统应用,2019,28(1):228?232.
[3]刘亮.机器学习算法在疾病诊断中的应用研究[ D].贵阳:贵州大学,2020.
作者简介:
张浪(2001—),本科,研究方向:数据分析与图像处理。
张星(2001—),本科,研究方向:XGBoost与相关性分析。
钱佳怡(2003—),本科,研究方向:随机森林。
杨霜玲(2001—),本科,研究方向:数据挖掘。
