基于改进SAE 和双向LSTM 的滚动轴承RUL 预测方法
2022-09-30康守强王玉静谢金宝MIKULOVICHVladimirIvanovich
康守强 周 月 王玉静 谢金宝 MIKULOVICH Vladimir Ivanovich
滚动轴承是旋转机械设备的重要组成部件,如果在轴承失效前可准确地预测出剩余使用寿命(Remaining useful life,RUL),便可及时采取预防措施,从而可以避免造成重大经济损失和人员伤亡事故[1-2].
特征提取是进行滚动轴承RUL 预测的重要前提.近年来,深度学习凭借其卓越的非线性函数自动映射能力在滚动轴承特征提取领域得到广泛应用[3].文献[4]提出一种改进的深度信念网络,直接以滚动轴承原始振动信号作为网络输入,经过逐层抽象表示,挖掘出原始振动信号深层本质特征.文献[5-7]利用卷积神经网络特有的局部卷积、权值共享和降采样等结构特性直接从滚动轴承振动信号中自动提取数据局部抽象信息,实现对振动信号特征的深层挖掘.上述研究虽利用深度学习方法简化了复杂的特征提取过程且挖掘出了振动信号深层本质特征,但是网络模型仍需大量标签数据进行有监督微调,而实际应用中标签数据匮乏且难以获取.
稀疏自动编码器(Sparse auto-encoder,SAE)作为深度学习模型的一种,因其独特的无监督特征学习能力,可实现大量无标签数据特征的有效表达[8],为滚动轴承特征提取提供了新的解决思路.目前稀疏自动编码器已被成功推广到各种标记数据有限的应用场合[9].然而传统的SAE 采用sigmoid 作为激活函数容易造成梯度消失问题,且采用Kullback-Leibler (KL)散度[10]进行稀疏性约束在滚动轴承特征提取方面存在局限性.
在特征提取的基础上,进行滚动轴承RUL 预测是最终目标.由于循环神经网络在时间序列处理方面具有优越性,因此本文在获取轴承性能退化特征值的基础上,将长短时记忆网络(Long shortterm memory,LSTM)作为轴承性能退化曲线构建方法.利用LSTM 构建轴承性能退化曲线的方法是整合 “ 过去”的信息,辅助处理当前信息.然而,本文考虑到滚动轴承的衰退过程实际上是一个在时间上具有前后依赖关系的连续变化过程,当前信息的处理也有必要整合 “未来”的信息[11].文献[11]将双向长短时记忆网络(Bi-directional long short-term memory,Bi-LSTM)用于负荷的短期预测并取得很好的实验效果.文献[12]将Bi-LSTM 应用于视频描述,用以全面保留全局时间和视觉信息.由此可以证实Bi-LSTM 在时间序列处理上具有可行性和优越性.
综上,本文对SAE 的激活函数进行改进,提出一种新的Tan 函数替代原有的sigmoid 激活函数,并采用dropout 机制对网络进行稀疏性约束.利用改进SAE 对滚动轴承振动信号进行无监督自适应特征提取,并将提取出的深层特征作为滚动轴承的性能退化特征.同时,通过引入Bi-LSTM 以实现滚动轴承过去和未来信息的充分利用从而完成滚动轴承当前寿命预测.最后利用一次函数对当前寿命进行拟合,实现对滚动轴承的RUL 预测.
1 改进SAE 模型
自动编码器(Auto-encoder,AE)是一种通过无监督学习算法尝试学习一个函数,使得输出值近似等于输入值的三层特征表达网络,由一个输入层、一个隐藏层和一个输出层组成[13],其网络结构如图1所示.

图1 AE 结构Fig.1 The structure of AE
输入层与隐藏层构成编码网络,编码过程为将n维输入数据X={x1,x2,···,xn}转换成m维拥有高级特征的隐藏层表达H={h1,h2,···,hm};隐藏层与输出层构成解码网络,解码过程为隐藏层向量重构n维输出数据集Y={y1,y2,···,yn}.
编码过程和解码过程可表示为:

式(1)和式(2)中的激活函数Sf与Sg一般采用sigmoid 函数,sigmoid 函数及其导函数的数学形式分别为:

由图2 的sigmoid 函数及其导函数图像可以看出,当神经元的输入距离零值点较远时,sigmoid 导数值会变得非常小,几乎为0,导致网络模型收敛很慢,即梯度消失.

图2 Sigmoid 函数及其导函数曲线Fig.2 The curves of sigmoid function and its derivative
为解决这个问题,本文采用一种新的激活函数,称为Tan 函数,Tan 函数及其导函数的数学形式为:
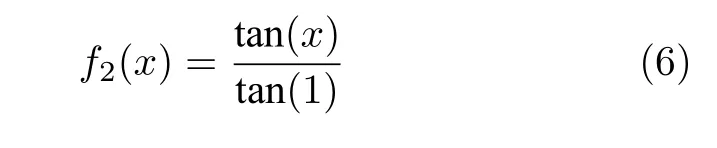
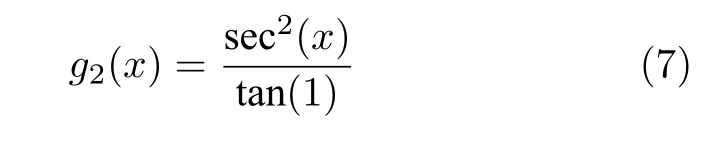
由图3 的Tan 函数及其导数图像可以看出,Tan导数的最小值约为0.64,不会出现为0 从而导致梯度消失的现象,使得网络模型收敛更加快速.

图3 Tan 函数及其导函数曲线Fig.3 The curves of Tan function and its derivative
KL 散度又称相对熵,用来衡量两种不同概率分布之间的偏离程度,在深度学习中,常用来衡量真实值与预测值之间的偏差.传统的SAE 就是借鉴了这种思想,在AE 的损失函数基础上添加了KL散度作为稀疏惩罚项,使网络变得 “稀疏”,从而优化网络模型,稀疏惩罚项定义为:
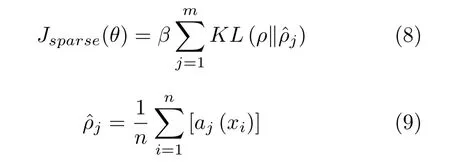

然而,以上采用KL 散度作为SAE 的稀疏约束项仅适用真实值为0 或1 的分类问题,对于滚动轴承所需提取的深层特征为 [ 0,1] 之间某个值这样的回归问题,无法将作为依据,对网络进行惩罚.因此,本文采用dropout 机制实现SAE 的稀疏性.
具体做法是在编码与解码过程中的激活函数前引入dropout 层,在进行编码、解码时进行掩模处理,使得AE 中的部分神经元激活值以一定的概率q(通常为0.5)被置为0[14],公式为:

式中,z表示原始激活函数的输入,z′表示经dropout 层稀疏化后的激活函数的输入.
当神经元被置为0,只是意味着相应的神经元的权重和偏置在本次学习中得不到更新,对原始的编码和解码过程不产生影响.
2 Bi-LSTM 模型
LSTM 模型由输入门it、遗忘门ft、输出门ot及记忆单元ct构成.通过it、ft和ot对网络中的信息进行选择性的输入、输出以及遗忘操作,能够有效克服一般神经网络所存在的梯度消失问题.LSTM单个单元的内部结构如图4 所示.
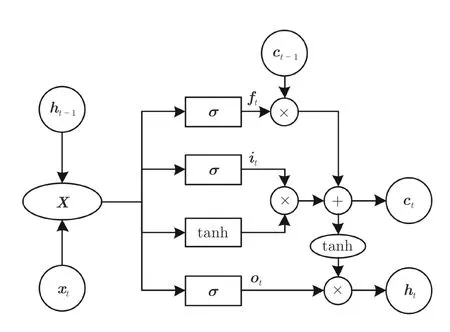
图4 LSTM 单元内部结构Fig.4 Internal structure of the LSTM cell
一个完整的LSTM 可表示为:

式中,xt表示t时刻的输入向量;ht是时间t的隐藏层状态;W和b分别是LSTM 的权值和偏置,均为模型训练参数;σ是激活函数sigmoid;⊗为逐点乘积.
虽然LSTM 能够解决长期依赖问题,但是它并没有利用未来的信息.因此本文采用Bi-LSTM 模型同时考虑数据的过去和未来信息,将其展开如图5所示.其工作原理是: 通过前向LSTM 和后向LSTM 得到两个时间序列相反的隐藏层状态,然后将其连接得到同一个输出.前向LSTM 和后向LSTM可以分别获取输入序列的过去信息和未来信息[11].Bi-LSTM 在t时刻的隐藏层状态Ht包含前向的和后向的:

图5 Bi-LSTM 网络展开图Fig.5 Unfolded Bi-LSTM network

式中,T为序列长度.
3 滚动轴承RUL 预测方法及流程
基于改进SAE 和Bi-LSTM 滚动轴承RUL 预测方法流程如图6 所示.具体步骤为:

图6 滚动轴承RUL 预测流程Fig.6 Flow chart of RUL prediction for rolling bearings
步骤1.数据预处理: 先对滚动轴承原始时域振动信号进行傅里叶变换(Fast Fourier transform,FFT),将其转换到频域;然后对其进行线性函数归一化处理,得到归一化后的频域幅值信号.然后对其进行线性函数归一化处理,得到归一化后的频域幅值信号.
步骤2.深层特征提取: 将归一化后的频域幅值信号作为改进SAE 的输入,进行无监督深层特征提取,主要包括预训练和微调2 个阶段: 预训练阶段通过无监督的逐层预训练初始化网络参数;微调阶段以原始输入为标签,通过反向传播和梯度下降算法对网络参数进行微调,从而得到最优的网络模型,最终提取能够表征轴承退化趋势的特征,并划分训练集和测试集.
步骤3.构建Bi-LSTM 模型: 以训练集特征作为Bi-LSTM 网络的输入,当前使用寿命特征点数与全寿命特征点数的比值p,即寿命百分比作为网络的标签输出[15],设置相关网络参数后进行训练.
步骤4.模型优化: 通过计算训练模型的均方误差(Mean Squared Error,MSE)、平均绝对误差(Mean absolute error,MAE)、平均绝对百分误差(Mean absolute percentage error,MAPE)、均方百分比误差(Mean square percentage error,MAPE)、均方根误差(Root mean square error,RMSE)以及上述5 种误差之和作为评价标准,比较文献[16]的3 种常用优化算法Adaptive moment estimation (Adam)、Root mean square prop (RMSProp)和带动量的随机梯度下降算法(Stochastic gradient descent with momentum,SGDM),训练得到最优的Bi-LSTM 模型参数,并应用Dropout 技术防止过拟合.
步骤5.测试集验证: 将测试集特征输入到训练好的Bi-LSTM 网络模型中,预测已知数据的p值.
步骤6.RUL 预测: 由于p值为寿命百分比标签,在轴承的衰退过程中,满足一次函数模型,因此对预测出的已知数据的p值曲线进行一次函数线性拟合,得到未来各个点的p值趋势.由步骤3 中p值的设定可知,当p=1 时,轴承失效,即达到全寿命.利用全寿命Lq减去当前寿命Ld可求得第i个轴承的RUL:
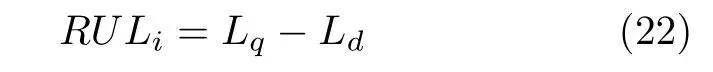
通过预测的剩余寿命RULi与 真实寿命ActRULi之间的误差Eri来反映模型剩余寿命预测性能的好坏:
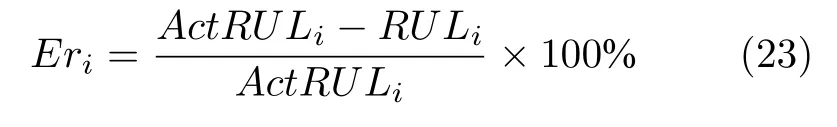
4 实验与分析
为验证本文提出的基于改进SAE 和Bi-LSTM的滚动轴承RUL 预测方法,选取PHM2012 轴承数据集[17]作为实验数据进行验证.该数据集由水平方向和垂直方向两个加速度传感器采集得到,每隔10 s 记录一次,每次记录时间为0.1 s,采样频率为25.6 kHz.本文采用水平方向的振动数据.
本文选取轴承1_1、1_2、2_1、2_2、3_1 和3_2 共6 个轴承的全寿命数据(滚动轴承从运行开始到完全失效的所有数据) 作为训练集进行训练,如表1 所示.剩余轴承1_3、1_4、1_5、1_6、1_7、2_3、2_4、2_5、2_6、2_7 和3_3 共11 个轴承的非全寿数据(滚动轴承从运行开始到某个时间点的数据)作为测试集进行RUL 预测实验.
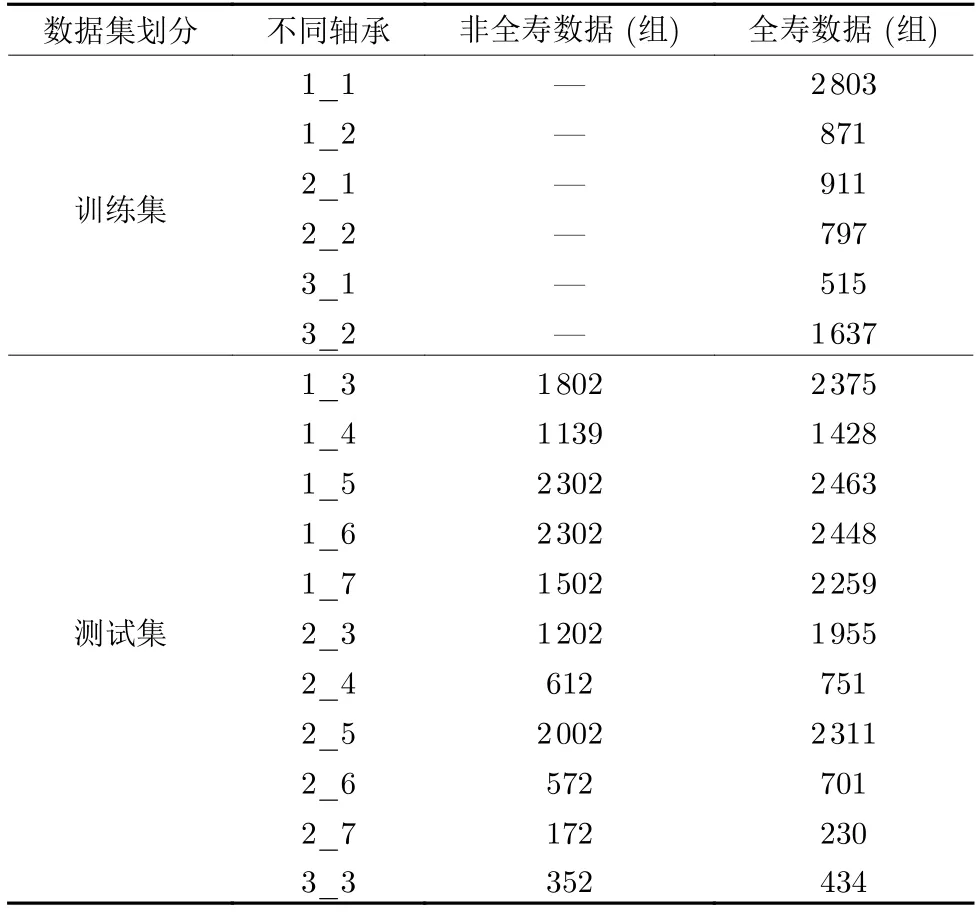
表1 实验数据(PHM2012 轴承数据集)Table 1 Experimental data (PHM2012 bearing datasets)
实验对训练集和测试集共17 个轴承的原始时域信号进行预处理.以轴承1_1 为例,0.1 s 采集时间段内的单个样本时域信号及预处理后的归一化频域信号如图7 所示.

图7 轴承1_1 时域振动信号及归一化后的频域幅值谱Fig.7 The time domain vibration signal and normalized amplitude spectrum of the bearing1_1
将归一化后的轴承频域信号输入到改进SAE中进行无监督自适应特征提取.经大量实验,改进SAE 网络结构选择为2 048-200-2 048,其中输入层节点数对应归一化后的轴承频域幅值信号的2 048个点,隐藏层节点数200 对应最终提取出的特征数.为消除振荡对健康指标的影响,保证原有特征曲线特性不变,对获得的特征曲线进行平滑滤波处理[18].从轴承1_1 提取出的200 维特征中任意选取某10个特征,其趋势曲线如图8 所示.
由图8 可以看出,在轴承整个生命周期内,由改进SAE 提取出的深层特征,大部分呈单调状,小部分呈非单调状,但从整体上看,由改进SAE 提取出的深层特征总体上具有良好的单调趋势性,能较好地表征轴承整个生命周期的衰退过程.
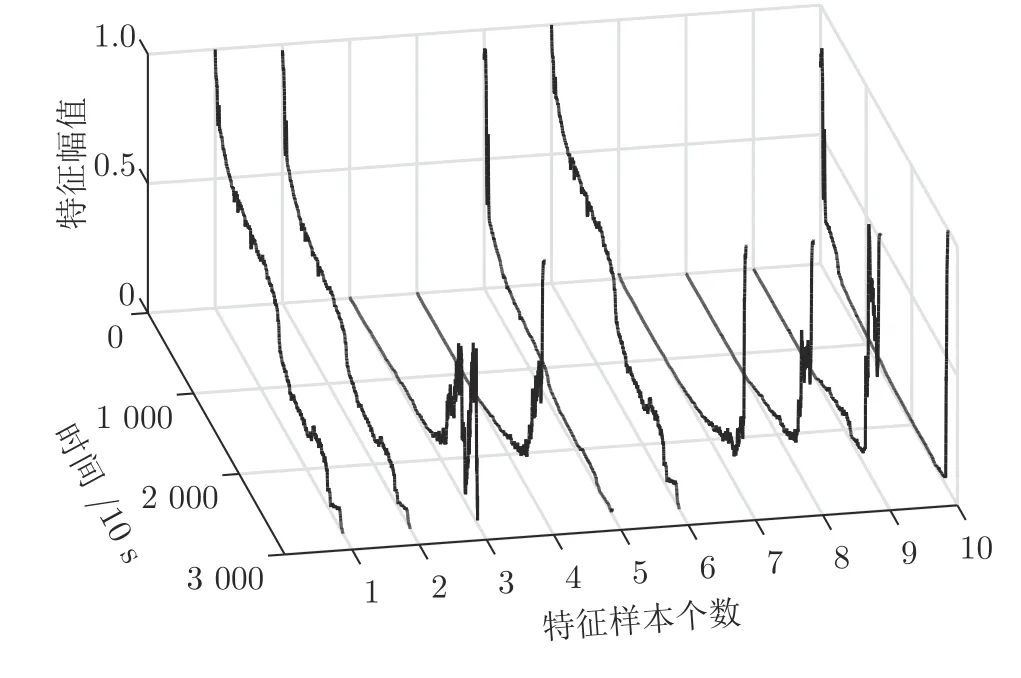
图8 轴承1_1 部分特征趋势曲线Fig.8 The trend curve of partial features of the bearing1_1
训练阶段: 将轴承1_2、2_1、2_2、3_1 和3_2 经过改进SAE 提取的深层特征输入到Bi-LSTM 网络模型中,以真实p值作为模型的输出,训练Bi-LSTM 预测模型.Bi-LSTM 网络由一个隐藏层组成,经迭代实验,网络的隐藏层状态数被选择为150.使用均方根误差(RMSE) 作为其损失函数,初始学习率设置为0.01 并随机初始化权重矩阵W和偏置b.计算3 种优化算法Adam、RMSProp 和SGDM 之下训练模型的各误差及误差之和,见表2.由表2 可知,Adam 作为自适应优化算法可使模型误差最小,同时Adam 算法能够动态地更新学习率,因此,本文使用Adam 优化器进行梯度优化.此外,本文还利用dropout 技术,防止过度拟合并提高模型的性能.经过实验,dropout值设置为0.1.
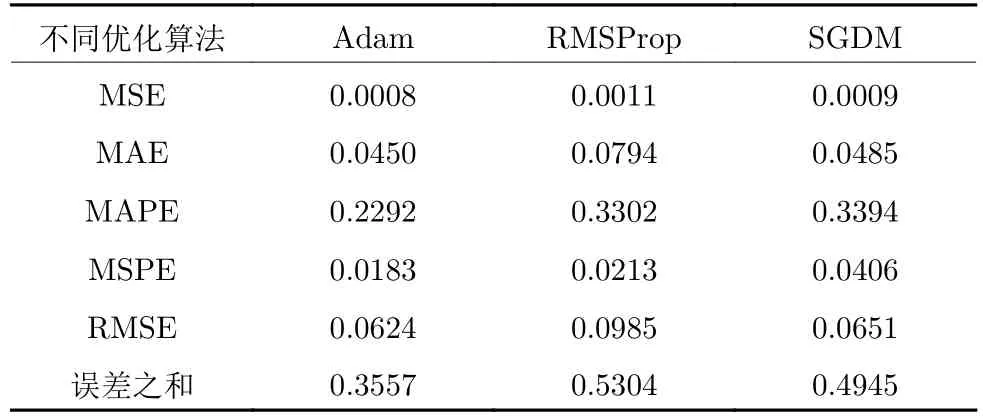
表2 3 种优化算法的训练误差Table 2 Training error of three optimization algorithms
测试阶段: 以测试轴承1_7 为例,与训练阶段相同,将轴承1_7 经过改进SAE 提取的深层特征输入到已训练好的Bi-LSTM 预测模型中,预测出当前p值.预测值与实际值的拟合结果如图9(a)所示,图9(b)为相应的拟合误差.

图9 本文方法预测轴承1_7 的当前p 值Fig.9 The current p value of bearing 1_7 predicted by the proposed method
将预测出的轴承1_7 当前p值运用一次函数拟合,得到未来p值的趋势,从而可得到滚动轴承1_7 的RUL 预测结果,如图10 所示.

图10 本文方法对轴承1_7 的RUL 预测结果Fig.10 RUL prediction result of bearing 1_7 by the proposed method
根据轴承的实际采样数据特点,每个轴承的每个特征点表示的寿命时间是10 s.已知轴承1_7 非全寿数据共1 502 个点,全寿命数据共2 259 点,又由图10 可以看出,当轴承达到失效阈值,即p=1时,对应预测的全寿命数据共2 282 点.由式(22)计算得到预测RUL 为(2 282 -1 502)×10 s=7 800 s,实际ActRUL 为(2 259 -1 520)×10 s=7 570 s,则实际ActRUL 与预测RUL 的差值为 |7 570 -7 800|=2 30 s,进而由式(23)得预测误差为((-230)/7 570)×100%=-3.04%.
为评估RUL 预测的不确定性,采用文献[19]的方法对RUL 进行区间估计,在预测值附近设置95%置信水平的置信区间提取上限和下限.与上述RUL 预测类似,预测值也可以外推到失效阈值,获得RUL 预测的上限和下限置信区间[7 530 s,8 070 s].
为验证改进SAE 相比于SAE 在收敛速度方面所获得的优势,分别利用SAE 和改进SAE 对滚动轴承进行深层特征提取,所消耗的时间如图11所示.

图11 特征提取所消耗时间的对比(PHM2012 轴承数据集)Fig.11 Comparison of the time consuming of feature extraction (PHM2012 bearing datasets)
由图11 可以看出,在17 个轴承特征提取实验中,改进SAE 特征提取所消耗的时间均比SAE 特征提取所消耗的时间要短,可证明改进SAE 相比于SAE 有更快的收敛速度.
为验证本文提出的基于改进SAE 和Bi-LSTM预测方法的有效性,设置了另外3 种方案与本文预测方法进行对比实验,如表3 所示.

表3 本文预测方法与其他3 种方案的构成Table 3 The composition of the proposed prediction method and other three schemes
按照本文方法对轴承1_7 进行RUL 预测的实验过程,同理可得到另外3 种方案对轴承1_7的RUL 预测结果,如图12 所示,具体预测误差如表4所示.

图12 3 种方案对轴承1_7 的RUL 预测结果Fig.12 RUL prediction results of bearing 1_7 by three schemes
为进一步验证本文方法的有效性,利用PHM2012轴承数据集的RUL 预测准确度评分式(24),对滚动轴承RUL 预测进行评价,平均得分结果如表4所示.

表4 不同轴承RUL 预测误差结果对比(PHM2012 轴承数据集) (%)Table 4 Comparison of RUL prediction results of different bearings (PHM2012 bearing datasets) (%)

式中,Ai定义为:

同理,表4 给出了数据库中其他10 个轴承的RUL预测误差和平均得分,并给出了与文献[20]和文献[21]的对比结果.
由本文提出的基于改进SAE 和Bi-LSTM 预测方法与其他3 种方案的对比实 验结果可以看出:
1)在相同的LSTM 和Bi-LSTM 预测模型情况下,改进SAE 特征提取模型较SAE 特征提取模型获得的平均预测误差分别降低5.56%和1.25%,平均得分分别提高了0.052 和0.054,由此可以证明改进SAE 特征提取模型更具优越性.
2) 在相同的改进SAE 特征提取模型情况下,Bi-LSTM 预测模型较LSTM 预测模型平均误差降低了3.32 %,平均得分提高了0.099,可证明Bi-LSTM预测模型具有较大优越性.
3)总体看,本文方法相比方案1、方案2 和方案3 都具有更低的误差和更高的得分.同时,本文提出方法相较于文献[20]和文献[21]平均预测误差分别降低了25.99%和46.75%,平均得分分别提高了0.313 和0.511.由此进一步证明了本文方法在滚动轴承RUL 预测方面的有效性.
为验证本文出的基于改进SAE 和Bi-LSTM模型的泛化能力,使用西安交通大学XJTU-SY 轴承数据集[22]作为新的实验数据.该数据集由水平方向和垂直方向两个加速度传感器采集得到,每隔1 min 记录一次,每次记录时间为1.28 s,采样频率为25.6 kHz,利用水平方向的振动数据.仿照PHM2012 轴承数据集对轴承进行非全寿与全寿命数据的划分,如表5 所示.选取轴承1_1、1_2、2_1、2_2、3_1 和3_2 共6 个轴承的全寿命数据作为训练集进行训练,剩余轴承1_3、1_4、1_5、2_3、2_4、2_5、3_3、3_4、3_5 共9 个轴承的非全寿数据作为测试集.
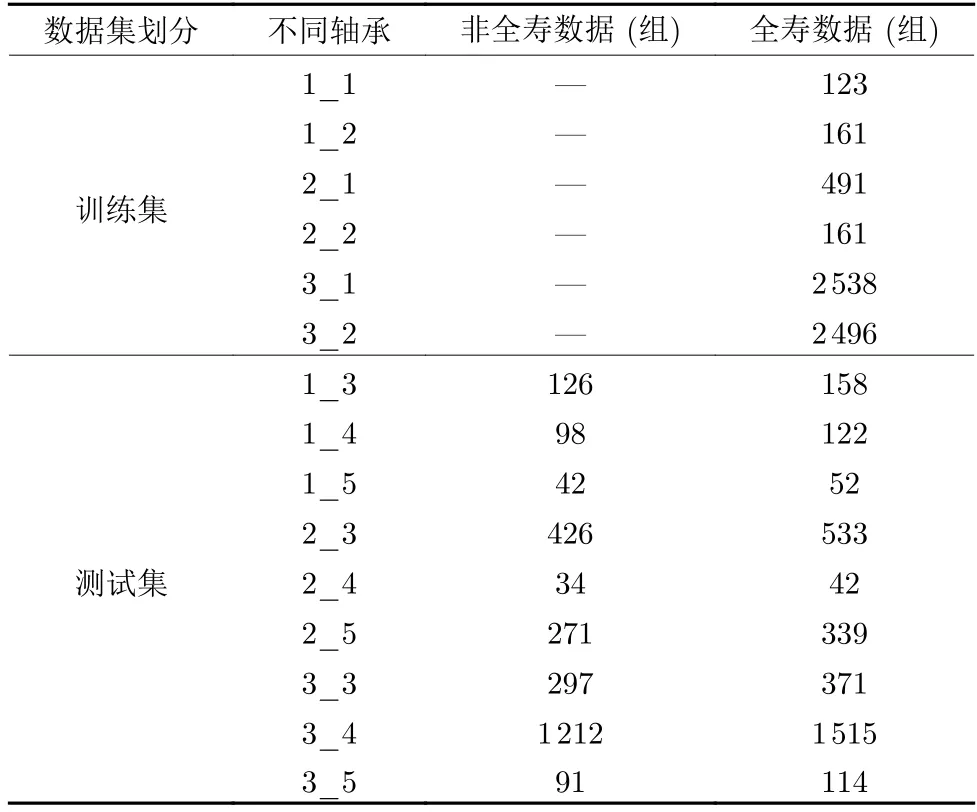
表5 实验数据(XJTU-SY 轴承数据集)Table 5 Experimental data (XJTU-SY bearing datasets)
同时,为简化实验过程,选取每个1.28 s 采集数据的中间4 096 点作为数据样本,按照PHM2012轴承数据集相同的实验方法进行改进SAE 深层特征提取、Bi-LSTM 模型构建、RUL 预测等.具体实验结果如图13 和表6 所示.

图13 特征提取所消耗时间的对比(XJTU-SY 轴承数据集)Fig.13 Comparison of the time consuming of feature extraction (XJTU-SY bearing datasets)
由图13 和表6 的实验结果对比可以看出,与PHM2012 轴承数据集相同的结论,因此可以进一步说明本文方法具有较好的泛化能力.
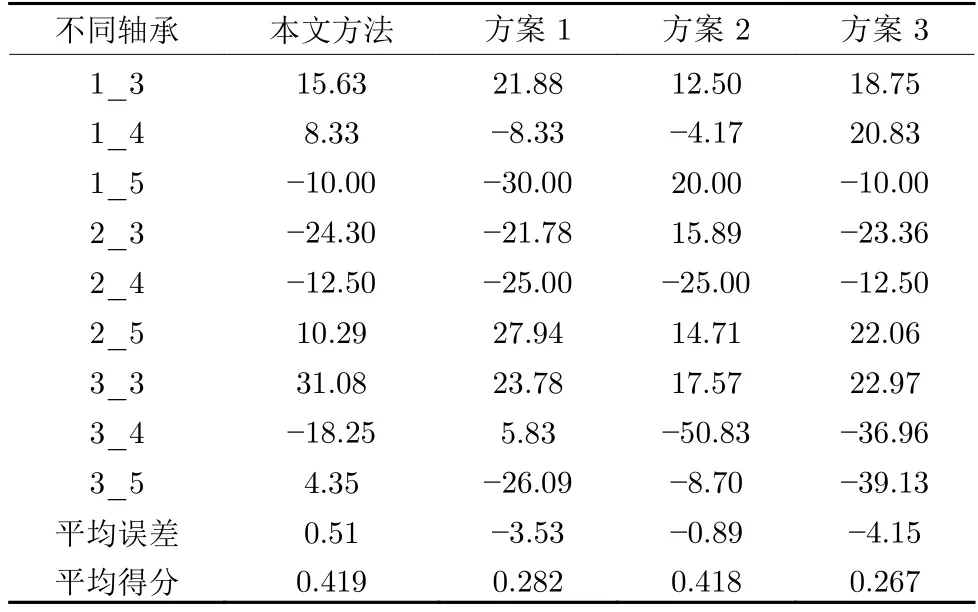
表6 不同轴承 RUL 预测误差结果对比(XJTU-SY 轴承数据集) (%)Table 6 Comparison of RUL prediction results of different bearings (XJTU-SY bearing datasets) (%)
5 结束语
本文提出一种基于改进SAE 和Bi-LSTM的滚动轴承RUL 预测方法.首先对SAE 进行改进,其次利用改进SAE 对滚动轴承振动信号进行深层特征提取,最后结合Bi-LSTM 网络实现滚动轴承的RUL 预测,得到以下结论:
1)针对传统的SAE 采用sigmoid 作为激活函数容易造成梯度消失问题,用一种新的Tan 函数替代原有的sigmoid 函数;针对SAE 采用KL 散度进行稀疏性约束在滚动轴承特征提取方面的局限性,以dropout 机制替代KL 散度实现其稀疏性.利用改进SAE 对滚动轴承振动信号进行无监督特征自适应提取,从而得到具有一定趋势能够表征轴承退化趋势的深层特征.
2)针对标准LSTM 按时间顺序处理序列,仅考虑过去信息而忽略未来信息的问题,引入Bi-LSTM网络,其同一输出连接两个具有相反时间的LSTM网络,分别获取输入序列的过去数据信息和未来数据信息.同时,为得到更好的预测结果,利用Adam算法和dropout 技术优化Bi-LSTM 预测模型.
3)本文方法经过2 个数据集实验验证,结果表明,相比传统的SAE 模型,改进SAE 模型具有更高收敛速度且提取的深层特征结合Bi-LSTM 模型在滚动轴承RUL 预测方面更具优越性,同时与其他2 个文献相比预测误差降低了25%以上,得分提高了0.313 以上.
对于滚动轴承RUL 预测有超前预测 (Eri >0)和滞后预测 (Eri <0)两种结果,在工业生产生活中对设备进行超前预测带来的风险低于滞后预测.因此,“超前预测”比 “滞后预测”更具实用意义.本文虽然在一定程度上提高了预测准确度,但是也加剧了 “滞后预测”的问题,因此,RUL 预测模型的优化将会是下一步研究工作的重点.
