大数据下数模联动的随机退化设备剩余寿命预测技术
2022-09-30李天梅司小胜
李天梅 司小胜 刘 翔 裴 洪
高速列车、航空航天装备、导弹武器、风电装备、工业机器人、石化装备等现代装备在功能不断提升的同时,正逐渐趋于大型化、多元化和集成化,这类装备多是由机械传动系统、电磁驱动系统、运动控制系统、信息传感系统等耦合组成的复杂系统,其服役过程受变环境、变载荷、变工况、大扰动和强冲击等因素影响,整体及关键部件性能将发生不可避免的退化,一旦因设备性能退化造成最终失效,将会造成巨大的人员伤亡和财产损失.例如,2014 年8 月2 日发生在我国江苏省昆山市的重大铝粉尘爆炸事故,共造成97 人死亡、163 人受伤,直接经济损失达到3.51 亿元,事后调查表明: 除尘器维护不足而造成集尘桶锈蚀退化破损是主要技术原因.2017 年7 月发生在美国密西西比州的美国海军陆战队KC-130 运输机坠毁事件,造成机上16 名军人全部遇难,该事故的调查结果表明发动机螺旋桨性能退化是造成飞机坠毁的主要原因.因此,若能在设备性能退化初期,尤其在尚未造成重大危害时,根据状态监测信息,及时发现异常或定量评价设备健康状态并预测其剩余寿命(Remaining useful life,RUL),据此对设备实施健康管理,对于切实保障复杂设备的运行安全性、可靠性与经济性具有重要意义.其中,剩余寿命预测是连接系统运行状态信息感知与基于运行状态实现个性化精准健康管理的纽带和关键,在过去十余年得到了长足的发展,主要技术方法包括失效机理分析方法、数据驱动的方法、机理模型和数据混合驱动方法[1-8],如图1 所示.基于失效机理分析的方法主要通过构建描述设备失效机理的数学模型,结合特定设备的经验知识和缺陷增长方程实现设备的剩余寿命预测.由于实际工程设备本身的复杂性、任务与运行环境的多样性,其健康状态演化规律通常难以物理机理建模或者获得失效机理模型的代价过高,导致失效机理方法及机理模型和数据混合驱动方法存在推广应用难的问题.因此,数据驱动的剩余寿命预测技术已成为国际上可靠性工程和自动化技术领域的研究前沿,过去十余年中得到了长足发展,在航空航天、军事、工业制造等领域具有极其重要的应用.

图1 剩余寿命预测方法体系Fig.1 The methodology of remaining useful life prediction
伴随着先进传感技术的快速发展,工程设备健康状态感知手段日益丰富,为设备运行监测大数据的获取提供了更多的可能.因此,数据驱动的剩余寿命预测技术发展迎来了新的契机,针对大数据处理的随机退化设备剩余寿命预测问题得到了大量学者的关注,相关技术蓬勃发展.在此背景下,本文的主要目的在于面向大数据背景下随机退化设备剩余寿命预测的现实需求,通过分析当前剩余寿命预测技术的发展动态,旨在探究该领域亟待解决的关键问题和新的发展方向.为此,第1 节首先结合数据特点对大数据下剩余寿命预测的研究背景、主要方法及思路、核心问题等进行了概述.第2~ 5 节分别分析了机理模型与数据混合驱动的剩余寿命预测技术、基于机器学习的剩余寿命预测技术、统计数据驱动的剩余寿命预测技术以及机器学习和统计数据驱动相结合的剩余寿命预测技术的基本研究思想和发展动态,同时结合随机退化设备监测大数据特点以及剩余寿命预测不确定性量化这一核心问题,深入剖析了当前研究存在的局限性和共性难题.第6节针对当前研究存在的局限性,提出了一种多源传感监测大数据下数模联动的随机退化设备剩余寿命预测问题解决思路(简称为数模联动,这里需要说明的是,“数”是指数据退化特征提取,“模”是指所提取退化特征时变演化过程随机建模),通过构建优化目标函数实现数据特征提取与所提取特征时变演化过程随机建模的 “联动”,并通过航空发动机多源监测数据初步验证了该思路的可行性和有效性.第7 节借鉴数模联动思路,围绕大数据背景下随机退化设备剩余寿命预测不确定性量化这一核心问题,探讨并提出了大数据背景下深度学习与随机退化建模交互联动、监测大数据与剩余寿命及其预测不确定性映射机制、非理想大数据下的剩余寿命预测等亟待解决的关键科学问题.第8 节总结全文.
1 大数据下剩余寿命预测问题概述
近年来,随着无线传感、物联网等技术快速兴起与普及,各式传感器犹如一张庞大的神经网络密布在装备内部,实时感知装备的一举一动,推动剩余寿命预测进入 “大数据” 时代.例如,军事装备在国家战略安全中具有不可替代的特殊地位,其各子系统的安全可靠运行举足轻重,必须依靠状态监测、剩余寿命预测以及预测维护等理论与方法保驾护航.由于需要监测的军事装备群规模大、每个装备需监测参量多、数据采样频率高、服役时间长,所以获取了海量监测数据: 一个现代航空发动机,每10毫秒就能生成几百个传感器信息,每次飞行能产生TB 级的运行监测数据;现代化工业制造生产线安装有数以万计的各型传感器来监测工业装备的运行过程信息及产品质量信息,比如大型工业机器人制造商利用云平台监控着百万台工业机器人,实时获取机器人每个运动关节的转速、角度、位置、温度、振动等信号,每天需要对TB 级以上的数据进行处理.然而,这些监测大数据在为设备健康状态感知及剩余寿命预测提供丰富信息的同时,由于设备工况多变、多源信号差异大、采样策略形式多、信息之间相互耦合、数据价值密度低,导致数据质量参差不齐,状态监测大数据呈现不同的统计特性.根据监测数据呈现的特点,图2 给出了完整监测大数据和非完整监测大数据(具有碎片化、分段的、稀疏性等特征)的示例.

图2 完整的、碎片化的、稀疏的监测大数据示例Fig.2 Examples of complete,fragment and sparse big data
这里完整监测大数据主要针对运行模式比较固定的随机退化设备(如轴承、齿轮等),能够实现不间断连续监测,监测大数据涵盖了设备从开始运行到失效比较完整的状态数据,而非完整监测大数据主要针对受经济条件及现实监测条件限制的随机退化设备(如航空发动机、涡轮泵、配电电池等),对这类设备进行连续监测采样是不现实的,只能间歇性地对其监测,得到的状态监测大数据表现出一定的“碎片化、分段、稀疏”等特点.因此,当剩余寿命预测进入大数据时代,如何根据监测大数据呈现出的不同特点,充分分析利用丰富的监测大数据资源,从浩如烟海的数据中进行 “沙里淘金”,深度挖掘出反映设备健康状态的信息并据此进行剩余寿命预测,是随机退化设备剩余寿命预测领域亟需解决的关键问题.
数据驱动的剩余寿命预测方法基于设备运行监测数据,通过拟合设备性能变量演化规律并外推到失效阈值,或建立监测数据与失效时间的映射关系,以实现剩余寿命预测,为大数据背景下随机退化设备剩余寿命预测提供了可行的技术思路.然而,剩余寿命指当前时刻到系统失效时刻的有效时间间隔,因此剩余寿命预测实际上是根据当前得到的监测信息,对系统将来失效事件的预测,其预测结果不可避免的具有不确定性.van Asselt 等[9]从哲学和认识论的角度讨论了预测的不确定性处理问题,指出预测结果具有不确定性是学术界的共识,也是当今时代的特征.联合攻击机F-35 项目组研究人员Hess 等[10]和Smith 等11]、寿命预测领域代表性学者马里兰大学先进生命周期工程中心Pecht 教授等[1,12]、可靠性领域知名期刊Quality and Reliability Engineering International主编Brombacher 教授[13]通过各种事例强调了预测不确定性的量化是剩余寿命预测从理论到应用转化的核心.美国国家航空航天局(National Aeronautics and Space Administration,NASA)预测与健康管理中心研究规划中也将剩余寿命预测不确定性的管理列为了中心发展路线图的重要研究内容(https://ti.arc.nasa.gov/tech/dash/groupspcoe/roadmap).由此可见,预测不确定性的量化是数据驱动随机退化设备剩余寿命预测领域的一个核心问题,也是解决 “敢用、能用” 剩余寿命预测理论技术实现实际工程设备个性化精准健康管理、保障设备长周期安全可靠运行的关键所在.
随着信息技术和传感器技术的迅猛发展,数据驱动的剩余寿命预测技术由于适用范围广、容易实现、无需深入专业机理知识等优点,作为其中典型代表的机器学习方法和统计数据驱动方法已获得了大量研究和蓬勃发展,得到了学术界和工业界的广泛关注,相关技术已经在导弹武器、航空航天、风力发电、工业制造等领域产生了重要应用[14-16].尽管以机器学习方法和统计数据驱动方法为典型代表的数据驱动随机退化设备剩余寿命预测已获得了大量研究和蓬勃发展,但已有理论与方法在大数据背景下随机退化设备剩余寿命预测及其预测不确定性量化这一核心问题上,仍然没有系统有效的解决方法,主要体现在统计数据驱动方法处理大数据能力不足,而机器学习方法量化预测不确定性能力不足.因此,通过对大数据背景下剩余寿命预测研究发展脉络的探究,深入剖析当前研究存在的瓶颈问题,对于促进随机退化设备剩余寿命预测技术的发展具有重要意义.在第2~ 5 节,将针对当前大数据背景下剩余寿命预测典型解决思路的研究动态和存在的问题进行具体的分析.
2 机理模型与数据混合驱动的剩余寿命预测
基于机理模型的方法主要是依据失效机理构建描述设备退化过程的参数化数学模型,结合设备的设计试验数据或经验知识辨识数学模型参数,进而基于状态监测数据更新机理模型参数实现设备的剩余寿命预测.典型的参数识别与更新方法包括: 卡尔曼滤波[17-19]、粒子滤波[20-21]和贝叶斯方法[22-23]等.常见的用于剩余寿命预测的机理模型包括: Paris模型、Forman 模型以及在其基础上的各种改进和扩展模型,主要用以描述裂纹扩展和层裂增长[24-25].例如,Li 等[26-27]基于Paris 模型,建立了缺陷增长率与缺陷面积及材料常数的映射关系,以预测滚动轴承的剩余寿命;Li 等[28]提出了Paris 裂纹扩展模型,根据裂纹尺寸和动态载荷预测齿轮的剩余使用寿命;Liang 等[29]研究了基于Paris 模型的滚珠轴承剩余使用寿命自适应预测方法,即使在缺乏先验信息且缺陷增长为时变的情况下,也能获得可靠的预测结果.Oppenheimer 等[30]利用线弹性断裂力学,对转轴建立了基于Forman 裂纹扩展的寿命模型;针对层裂增长故障,Marble 等[31]开发了一种涡轮发动机轴承的层裂增长预测模型,能够根据工况估计层裂增长轨迹和故障时间,并利用诊断反馈进行自调整,降低了预测不确定性;Choi 等[32]考虑了由于裂纹形成和磨粒磨损引起的层裂增长现象,提出了滚动接触的层裂增长寿命模型.在充分理解失效机理并得到准确的模型估计参数后,基于机理模型的方法能够实现对剩余使用寿命的精确预测.然而,以上现有基于机理模型的剩余寿命预测方法未能结合实际运行设备的实时监测数据,难以准确反映设备当前运行的实际状态,特别是在设备运行环境、运行工况发生变化时,若不能利用实时监测数据对模型进行更新,将产生较大的预测偏差.
为了使得机理模型能够更好地建模实际服役个体设备的性能演变过程,将设备实时运行监测数据与机理模型进行混合,将有助于实现剩余寿命预测准确性的提升.因此,机理模型与数据混合驱动的剩余寿命预测方法也得到了较多的关注和发展[4].最近该方面的研究包括Liao 等[33]、Wang 等[34]的论文,这些研究分别针对锂电池系统和旋转机械设备,提出了机理模型与数据混合驱动的剩余寿命预测方法.根据机理模型与数据混合驱动实现方式不同,可将这类混合驱动的剩余寿命预测方法分为两大类: 1)基于监测数据构建机理模型所刻画退化状态的测量模型,运用卡尔曼滤波、粒子滤波等方法估计退化状态和机理模型参数,然后通过机理模型预测设备的剩余寿命[12,35];2)首先分别基于数据和机理模型进行设备的剩余寿命预测,然后利用决策层融合方法实现集成基于数据和基于机理模型的剩余寿命预测[36-37].以上两类机理模型与数据混合驱动实现剩余寿命预测的方式各具优势: 第1 种方式能够充分考虑退化状态难以直接测量的实际,在考虑监测数据中测量噪声的情况下,可实现隐含退化状态的估计和机理模型参数的更新,使得最终的预测结果能够更准确地反映设备当前的实际状态;第2种方式实现过程相对简单独立,决策层融合的形式较为多样,如平均法、权重平均、核回归、证据组合等,能够集成多种方法的优势,有助于提升预测结果的鲁棒性.
虽然基于机理模型的方法和机理模型与数据混合驱动方法得到了一定的发展,但其成功应用的基础是可获取精确可靠的机理模型.随着当代设备逐步呈现复杂化、非线性化以及高维化等特征,其健康状态演化规律通常难以精确机理建模或者获得失效机理模型的成本过高.现有研究中通过物理机理分析、理化分析、实验分析等手段获取的机理模型主要针对特定材料或对象,这一点也可以通过当前机理模型的种类相当匮乏反映出,由此在一定程度上限制了这类方法的广泛应用.因此,在大数据背景下,通过挖掘数据中隐含的设备健康状态信息,发展数据驱动的剩余寿命预测方法成为当前的主流和研究的焦点.
3 基于机器学习的剩余寿命预测
基于机器学习的设备剩余寿命预测主要思路是通过机器学习拟合性能变量演化规律并通过滚动外推到失效阈值以预测失效时间,或直接建立监测数据与失效时间的映射关系实现端到端的预测,基于此通过预测的失效时间减去当前运行时间得到剩余寿命的预测值.裴洪等[38]和Khan 等[39]分别综述了机器学习方法和深度学习方法在剩余寿命预测与健康管理领域的研究应用现状.为区别于以上综述中介绍的工作,本文重点结合最新的研究进展和大数据下剩余寿命预测的现实需求,对基于机器学习的剩余寿命预测技术发展动态和存在的问题进行分析.根据机器学习网络模型结构特点,这类方法主要分为基于浅层机器学习的方法和基于深度学习的方法.
3.1 基于浅层机器学习的剩余寿命预测
基于浅层机器学习的剩余寿命预测方法中的典型代表为神经网络、支持向量机等,具体发展动态分述如下.
1) 神经网络
神经网络是一种模拟人类中枢神经系统组织结构与信息处理机制的学习网络,主要由输入层、隐层和输出层组成[40].神经网络具有自学习、自组织、自适应以及强非线性映射拟合能力等优点[41-42],因而在设备剩余寿命预测领域受到了学者们的广泛关注[43-45].早在2004 年,Gebraeel 等[46]就将单隐层前馈神经网络用于机械设备振动信号建模,通过外推至失效阈值实现剩余寿命预测.Mahamad 等[47]通过改进前馈神经网络训练算法,将改进后的网络用于旋转机械的寿命预测.Lim 等[48]采用特征时序直方图法从多源监测数据中提取了具有局部趋势性的退化指标,然后将这些退化指标输入到多层感知机中去预测航空发动机的剩余寿命.Drouillet 等[49]将单隐层前馈神经网络用于高速铣刀剩余寿命预测.Ahmadzadeh[50]等使用多层感知机去预测研磨机剩余寿命.Zhang 等[51]基于小波包分解、快速傅里叶变换和反向传播神经网络构建了鼓风机剩余寿命预测模型.徐东辉[52]提出了多类神经网络组合预测的方法,利用改进的Elman 神经网络和非线性自回归神经网络两个单项预测模型进行预测,并且借助于径向基函数神经网络对两个单项模型的预测值进行非线性组合,实现了剩余寿命预测.杨洋[53]研究了一种基于自回归移动平均和后向传播神经网络组合模型的锂电池寿命预测方法,有效结合了两者在短期预测方面与非线性拟合方面的优势.在最新的研究中,Bektas 等[54]通过引入传感器选择、数据归一化、特征提取等数据预处理技术,将预处理后的数据用于训练神经网络,提出了一种基于神经网络和相似性的剩余寿命预测方法.Li 等[55]利用监测数据训练了多个神经网络,基于加权平均思想提出了一种基于集成网络的剩余寿命预测方法.
2)支持向量机
支持向量机是由Cortes[56]和Vapnik[57]于1995 年首次提出的,在小样本和高维数据机器学习领域受到广泛关注,主要原理是首先通过非线性变换将多维输入向量映射到高维特征空间,然后在高维特征空间中构造最优超平面来实现样本分类或回归.由于支持向量机能够有效避免 “维数灾难”问题,且具有较好的泛化能力,因而广泛应用于设备的剩余寿命预测中[58-61].例如,Soualhi 等[62]利用Hilbert-Huang 变换构建了滚动轴承的敏感退化指标,然后将这些退化指标输入到支持向量机中实现了旋转轴承的剩余寿命预测;Sun 等[63]构建了贝叶斯最小二乘法支持向量机预测模型,并将其用于微波器件的剩余寿命预测;Nieto 等[64]将支持向量机应用到了航空发动机的剩余寿命预测中;Khelif 等[65]研究提出了一种不需要建立健康指标、故障状态等直接基于支持向量回归模型建立监测数据与设备寿命的拟合关系,进而实现了剩余寿命预测.Huang等[66]对基于支持向量机的剩余寿命预测方法研究现状、应用领域及发展趋势进行了系统地梳理和分析.
3)其他浅层模型
除了以上几种常用的浅层模型外,一些其他机器学习模型也被应用到装备的剩余寿命预测中,如极限学习机[67]、贝叶斯网络[68]、随机森林[69]、梯度提升决策树[70]、基于案例的学习方法[71]、基于案例的推理方法[72]等.文献[38]对基于浅层机器学习的剩余寿命预测方法进行了详细综述,本文不再赘述.
通过文献总结分析可以发现,虽然浅层神经网络训练相对比较容易,基于浅层机器学习方法实现设备剩余寿命预测的研究具有较长的历史,但这类方法中采用的网络结构简单、预测性能较多地依赖于专家先验知识与信号处理技术,且难于量化剩余寿命预测结果的不确定性.此外,这类研究中较多的方法需借助人工经验与知识预先提取监测数据中的关键信息并构建退化指标,因此退化指标的好坏将很大程度上决定浅层神经网络的预测性能.在大数据时代,设备退化特征愈发表现出耦合性、不确定性、非完整性等特点,浅层机器学习算法自学习能力较弱,难以自动处理和分析海量监测数据.因此,大数据下剩余寿命预测的智能学习模型由 “浅”入 “深”、势在必行.
3.2 基于深度学习的剩余寿命预测
深度学习作为一种大数据处理工具,旨在模拟大脑学习过程,构建深度模型,通过海量数据学习特征,刻画数据丰富的内在信息,最终提升建模精度.深度学习自从2006 年在Science上首次提出便掀起了学术界和工业界的研究浪潮,如雨后春笋,以其强大的海量数据处理能力在诸多领域的大数据分析中方兴未艾.经过了十余年的探索,深度学习当前已成功应用于许多工程领域,如图像识别[73]、自然语言处理[74]、语音识别[75]、故障诊断[76]等,同时在剩余寿命预测领域也崭露头角.如图1 所示,根据网络结构的不同,这类方法主要包括: 基于深度自编码器的方法、基于深度置信网络的方法、基于卷积神经网络的方法、基于循环神经网络的方法以及多种网络组合而成的混合网络方法.无论基于哪种深度网络结构形式,其基本思想都是采用现有深度学习模型建立性能测试数据与剩余寿命标签或退化标签之间的潜在关系.下面针对几种典型的深度学习网络,介绍其应用于剩余寿命预测时的研究动态并分析当前研究存在的问题.
1)深度自编码网络
深度自编码网络是由多个自编码器或降噪自编码器堆叠组成的深度神经网络.基于深度自编码网络的剩余寿命预测通过提取出原始数据的深层次特征,然后通过逻辑回归层或全连接层实现机械装备的剩余寿命预测[77-80].由于自编码器是以重构原始输入为学习目标,因而其学习到的特征对数据有更本质的刻画,有利于提高预测精度,且深度自编码网络能够以无监督学习方式逐层对网络参数进行预训练,将训练结果作为反向微调的初始值,确保了网络参数的在线更新,在剩余寿命预测领域得到了广泛的应用[81-85].例如,Xia 等[79]提出了一种基于深度自编码网络的两阶段剩余寿命预测方法,首先运用深度降噪自编码器网络对监测大数据进行阶段划分,然后训练深度自编码网络得到每个阶段的退化特征,最后通过回归方法分析各阶段特征实现剩余寿命预测.然而,深度自编码网络在处理力信号、振动信号、声发射信号、光信号等高维原始监测数据时,其仍需要借助各类信号处理技术来提取设备的退化指标.
2)深度置信网络
深度置信网络主要是由多个受限波尔兹曼机堆叠与一个分类层或回归层组合形成的深度网络,通过逐层预训练和反向精调策略解决深度模型普遍存在的训练困难问题,不仅能实现数据从浅层到深层的特征表示与提取,而且能发现输入数据的分布式特征,在深层特征提取方面获得了广泛的应用.例如,Jiao 等[86]提出了一种基于深度置信网络的健康指标构建方法用于装备的剩余寿命预测,该方法采用无监督学习的策略融合多个传感器监测数据对装备健康状态进行评估,得到描述其退化程度的健康指标用于剩余寿命预测.需要注意的是,深度置信网络在实际中的应用主要集中在深层次特征提取方面,单纯利用深度置信网络实现剩余寿命预测的研究还相当有限,需要与其他网络混合进行才能进行剩余寿命预测.
3)卷积神经网络
卷积神经网络作为一类经典的前馈神经网络,是由LeCun 等[87]首次提出并用于解决图像处理问题的,主要由若干卷积层和池化层组成,既能输入序列数据,也能处理网格化数据,在计算机视觉、语音识别等领域应用十分广泛.针对设备性能监测大数据的特点,先后发展出了多种用于剩余寿命预测的卷积神经网络,主要包括深度卷积神经网络[88]、多层可分离卷积神经网络[89]、多尺度卷积神经网络[90]、联合损失卷积神经网络[91]等.Babu 等[92]首次将深度卷积神经网络应用于剩余寿命预测领域,采用两个卷积层和两个池化层提取原始信号特征,同时结合多层感知器实现剩余寿命的预测.最近,Yang 等[93]提出了一种基于两个卷积神经网络的剩余寿命预测方法,其中一个是分类网络用于监测性能退化的初始时刻,另一个是回归网络用于预测剩余寿命.相比于其他深度学习网络,卷积神经网络能够更有效地处理力信号、振动信号、声发射信号、光信号等高维原始数据,可实现从监测数据中自动提取退化特征信息,适合处理监测大数据且具有降噪的功能,同时其网络参数量相对较少,训练更加方便高效,因此易于构建更深的网络结构.然而,随机退化设备的监测数据蕴含的健康特征往往是时序相关的,而卷积神经网络在应对大数据下时序特征提取能力不足,容易造成重要时序特征的丢失,这对于剩余寿命预测是不利的,因此卷积神经网络在应用于剩余寿命预测时经常与其他深度网络组合使用.
4)循环神经网络
循环神经网络作为一类包含前馈连接与内部反馈连接的前馈神经网络,主要用于处理具有相互依赖特性的监测向量序列,由于其特殊的网络结构,能够保留隐含层上一时刻的状态信息,目前已经在剩余寿命预测领域得到广泛的关注,被应用于锂电池系统[94]、风力发电设备[95]、航空发动机[96]等.为解决循环神经网络通常存在 “记忆衰退”进而导致预测偏差较大这一问题,学者们对循环神经网络模型进行了改进,提出了一种长短期记忆(Long short term memory,LSTM)模型,门结构作为LSTM 的独特结构,能够在最优条件下确定出所通过信息特征,在剩余寿命预测领域获得了广泛的应用[97-98].例如: 为解决运行和环境扰动引起的不确定性问题,Elsheikh 等[99]对LSTM 的结构分别进行了改进,提出了基于双向LSTM 的剩余寿命预测方法.虽然循环神经网络在随机退化设备退化过程建模方面具有先天优势,但当处理长期依赖型退化数据时,循环神经网络在训练过程中也经常面临梯度消失或爆炸问题.同时,以上基于循环神经网络的剩余寿命预测研究中都未考虑预测结果不确定性的量化问题,只能输出一个剩余寿命的点估计,难以评估预测结果的置信度.
最近,针对剩余寿命预测不确定性量化问题,Zhang 等[100]在假定退化数据服从正态分布的前提下利用Monte Carlo 方法从退化数据中随机采样,通过改变LSTM 网络输入,在不同网络输入下得到不同的剩余寿命预测值,由此构造剩余寿命的数值分布,试图量化预测不确定性.Huang 等[101]利用双向LSTM 网络预测剩余寿命输出的均方根误差构建剩余寿命预测的误差带,以区间的形式表示预测不确定性.Yu 等[102]对退化监测数据进行划分、以退化量为标签,建立了多个基于LSTM 网络的退化量预测模型,然后通过滚动预测的思想将预测值作为模型输入迭代预测至退化量超过失效预测的时刻,由此确定设备的剩余寿命预测值.进一步,为综合多个LSTM 网络预测值,引入Bayesian 模型平均方法,估计各个模型的后验概率,由此可以确定最终的剩余寿命预测值和预测置信区间,有效提高了剩余寿命预测精度的同时以置信区间的形式表示了预测不确定性.以上思路在基于机器学习方法的剩余寿命预测不确定性量化方面做出了有益的尝试,然而无论是改变输入条件构建数值分布、基于均方根误差构建误差带,还是构建多个预测模型通过Bayesian 模型平均构建置信区间,都更多地反映了网络训练的效果而不能全面反映设备性能退化固有的时变随机性和动态特性.
5)混合深度网络
基于混合深度网络的方法可看作多个深度学习网络以一定方式组合连接(如串联、并联等)用于弥补现有单一深度学习网络的不足,目前主要的混合形式包括深度置信网络+前馈神经网络[103]、受限玻尔兹曼机+LSTM 网络[104]、LSTM 网络+卷积神经网络[105]、LSTM 网络+编码-解码模型[106]、循环神经网络+自编码器[107]、多损失编码器+两阶段卷积神经网络[108]等.这类方法主要通过继承不同深度学习模型的优势,进而期望实现取长补短、改善剩余寿命预测的效果.例如: Ren 等[109]提出了一种堆栈自编码器与前馈神经网络组合的轴承剩寿命预测方法,该方法能够有效利用堆栈自编码器在特征表示方面的优势,同时将其引入至前馈神经网络可有效避免训练过程中的局部最优问题;Deutsch等[104]提出了一种融合深度置信网络与前馈神经网络的旋转设备剩余寿命预测方法,这是基于深度置信网络方法的改进和拓展,能够有效结合深度置信网络特征提取能力与前馈神经网络的预测性能.虽然通过混合深度网络进行剩余寿命预测有助于产生互补效应,但混合多种深度网络将不可避免地导致剩余寿命预测模型的训练复杂化,而且混合方式的选择基本上是启发式的,缺乏公认统一的形式.因此,发展剩余寿命预测相关性能要求牵引下的混合深度网络构建方式以提高混合方式的可解释性仍有待深入研究.
需要说明的是,基于深度学习的剩余寿命预测研究正在蓬勃发展,以上介绍到的文献仅是冰山一角.通过对当前相关研究发展动态的分析不难发现,无论是传统的基于浅层机器学习还是正在蓬勃发展的基于深度学习的剩余寿命预测研究,基本上都可以归结到两种思路,即基于退化量滚动预测和基于学习网络建立监测数据与失效时间端到端的映射.虽然在以上两种思路下的剩余寿命预测方法研究快速发展,且都属于数据驱动的方法,但当前研究面对剩余寿命预测现实需求时主要存在以下有待解决的问题:
1)目前这些基于机器学习的剩余寿命预测研究,基本上都是将其他领域应用需求驱动下提出并发展起来的各种深度网络直接应用,其网络结构和参数均是确定性的,一般只能得到确定性的剩余寿命预测值,很难得到能够量化剩余寿命预测不确定性的概率分布.正如第1 节所讨论的,剩余寿命预测针对的是设备将来的失效事件,而设备性能退化在预测区间内受到环境、负载等多重随机因素影响,导致剩余寿命预测结果不可避免地具有不确定性,因此剩余寿命预测不确定性的量化表征是该领域的一个核心问题.然而,目前基于机器学习的方法对这方面重视不够,在预测不确定性量化能力上存在不足.无法量化预测不确定性也意味着无法量化预测结果带来的风险,由此导致难以满足以最小化运行风险或最小化费用为目标的健康管理相关决策(如维护决策、备件订购等)对运行风险定量评估的应用需求[39].造成以上问题的根本原因在于所采用的学习网络并不是针对剩余寿命预测的核心需求设计的,更多的是直接采用或借鉴其他任务需求下发展起来的学习网络.因此,如何设计并发展面向剩余寿命预测及其不确定性量化需求的专用学习网络,使得其能够从监测数据中学习到反映预测不确定性的剩余寿命概率分布相关的信息,是克服现有研究发展瓶颈的根本途径和有重要价值的研究方向.
2)现有研究中通过学习网络建立监测数据与失效时间端到端映射以预测剩余寿命的思路,其成功实现的前提是能够获取充分的同类设备失效时间数据以制作训练标签.然而,在工程实际中,由于受到安全性与经济性等因素的限制,设备运行至失效状态是极其危险的,一般在失效前对设备进行替换.在该情况下,所能获取的更多的是设备在服役过程中积累的大量状态监测数据,关于设备失效时间的数据几乎没有,因而这类状态监测大数据大多属于非全寿命周期类型.尽管大数据背景下非全寿命周期数据包含了丰富的设备退化机制与寿命信息,但由于失效数据匮乏将导致现有基于机器学习的剩余寿命预测方法中所需的寿命标签难以制作(即零寿命标签问题),由此为构建监测数据与剩余寿命之间端到端的映射关系带来了极大的挑战.与此同时,基于退化量滚动预测的思路以退化量为标签构建预测模型,能够减少对寿命标签数据的依赖,但在实现过程中将本身存在误差的退化量预测值作为预测模型输入进行滚动预测,容易造成预测误差的累积,进而影响剩余寿命预测的准确性.此外,目前基于以上思路的剩余寿命预测研究主要针对完整监测数据,而对于图2 所示的 “碎片化、分段的、稀疏的”非完整监测大数据与剩余寿命之间的映射关系鲜有研究.因此,零寿命标签情形下如何通过非完整监测大数据构建随机退化设备剩余寿命预测模型,发展剩余寿命预测研究的新范式仍有待解决.
3)如前所述,剩余寿命预测是衔接设备健康状态感知与基于状态感知信息实现设备的个性化精准健康管理的桥梁,因此剩余寿命预测方法的可解释性对于将预测结果用于设备的健康管理(如预测维护、备件订购等)至关重要.然而,现有基于机器学习的剩余寿命预测方法通过学习网络建立监测数据与剩余寿命之间的映射关系,监测数据与剩余寿命之间的关系难以显式表示,呈现 “黑箱” 特点,难以解释设备退化失效机理.此外,当前的研究较多地关注了剩余寿命预测的准确性,但机器学习模型中超参数的选择对预测结果的准确性和鲁棒性具有重要影响,预测的效果对调参技巧和经验有较大的依赖,而如何合理有效地选择机器学习模型的超参数在机器学习领域本身就是一个极具挑战性的问题.综合以上两个方面可见,发展具有可解释性的基于机器学习的剩余寿命预测方法,将有助于打通当前这类方法从理论研究到推广应用于设备健康管理的最后一公里.提高基于机器学习的剩余寿命预测方法的可解释性的研究方向包括在学习网络设计中考虑设备退化失效的机理知识、基于学习网络从监测数据中提取退化特征时将特征的趋势性或单调性作为约束条件考虑、将超参数的选择问题转化为提升预测效果的优化问题纳入模型训练过程等.
4 统计数据驱动的剩余寿命预测
传统统计数据驱动的剩余寿命预测方法通过对设备失效时间数据统计分析,构造寿命T的分布函数,由此设备在t时刻的剩余寿命即为T -t|T >t,z,其中z代表该类设备的事件数据集(主要指失效时间数据),然后通过分布拟合得到寿命T的概率分布,再通过上述条件随机变量的关系实现剩余寿命预测[110].然而,随着生产制造水平的不断提升,设备的可靠性逐步提高,很难在短期内(即使是加速条件下)获得足够多的失效数据或对于昂贵的设备获取成本过高,而且这类方法没有用到设备运行过程中的监测数据,预测结果难以反映当前运行实际情况,由此导致难以实现个体服役设备的精准健康管理.
相比之下,随着信息技术和传感器技术的迅猛发展,通过设备性能退化变量的监测数据,建立描述设备性能演化过程的随机模型,便可预测设备剩余寿命[111].这类方法以概率统计理论为基础,在随机模型框架下建模性能退化变量演变规律,以概率分布的形式给出剩余寿命分布的表达式,不仅能得到剩余寿命的点估计,而且能描述预测的不确定性(方差、置信区间等各种不确定性量化指标),这对维修、替换、后勤保障等的科学决策极为重要,因而已成为国内外研究的热点.
基于随机模型建模性能退化变量监测数据的关键是选择合适的随机模型,常用的随机模型主要指各种随机过程模型,包括Wiener 过程、Gamma过程、Markov 链、隐Markov 过程和逆高斯过程等[112-115].这类方法采用随机过程描述性能退化变量的演变过程,通过监测数据实现模型参数的估计,基于此通过求解所建立的随机退化过程首达失效阈值时间的概率分布实现剩余寿命预测,在剩余寿命预测不确定性量化方面具有天然优势.从物理机制看,设备退化是其内部应力和外部环境综合作用而引起的设备老化和性能衰变,与采样时间和采样频率无关,亦即设备的退化过程应该满足无限可分性.迄今,从数学上已证明满足无限可分性的随机过程模型只有Gamma 过程、逆高斯过程和Wiener 过程[116-117].因此,利用这三类随机过程建立设备退化模型,在数学上和物理上均具有较强的可解释性,受到了国内外研究者的广泛关注[118-119].然而,前两种随机过程都是单调随机过程,只能描述单调退化,例如磨损、疲劳裂纹增长等.在实际中,由于设备内部应力的吸收与释放、使用强度、使用频率、载荷大小、外界环境等的动态变化,性能退化变量的监测信号往往呈现非单调波动的特点,而Wiener 过程是由Brownian 运动驱动的一类扩散过程,其增量独立且为高斯分布,适合刻画非单调退化过程,在退化测量信号的建模上更具灵活性,因此广泛应用于滚动轴承、液晶显示器、激光器、惯性器件等的退化建模及剩余寿命预测.2018 年,Zhang 等[120]系统全面地总结了基于Wiener 过程的各种退化建模及剩余寿命预测方法最新研究进展情况.
目前,这类基于随机过程的方法主要针对图2所示的完整监测数据,且需要能够从监测数据中提取具有一定趋势特征的性能退化变量,以确定所采用随机过程的参数化形式并基于监测数据实现随机过程模型参数辨识,最终通过求解随机过程首达失效阈值时间的概率分布达到预测剩余寿命的目的.根据建模过程中涉及的性能退化变量数目,主要分为单变量模型和多变量模型两种情况.
单变量下随机退化设备剩余寿命预测研究得到了广泛关注和深入研究.Gebraeel 等[121]以轴承振动数据为背景,将设备退化数据演化过程描述为线性Wiener 过程,最早将Bayesian 更新策略用于剩余寿命分布的在线递归预测.Huang 等[122]通过采用时间尺度变换线性化技术研究了一类基于一般Wiener 随机退化过程的剩余寿命预测问题,提出了漂移系数自适应更新方法;为处理本质非线性退化数据,Si 等[123]提出了一类一般非线性扩散过程模型描述退化数据,通过时间-空间变换,得到了剩余寿命分布的解析形式,并将所得结果应用于惯性平台的漂移退化和2017-T4 铝合金的疲劳裂纹增长.在文献[123]基础之上,出现了诸多的理论扩展及应用研究[124-125].最新出版的学术专著 [126] 对基于Wiener过程及其变形开展的单变量下随机退化设备剩余寿命预测基础理论和方法,从线性到非线性、从固定模式到切换模式进行了详细的论述.
在工程实际中,设备存在运行工况、运行环境、运行负载多变等复杂运行模式,反映设备性能退化的变量往往不止一个且相互关联,呈现多性能退化变量的特点,表征设备健康状态的性能退化指标往往并不唯一.文献[127]在Bayesian 框架下研究了多变量动态系统的可靠性估计问题,但将各个变量单独建模,未考虑多退化变量之间相互耦合的实际.当前,对多变量耦合的情况主要有两种思路.第1种是基于Copula 函数的方法.其中,Copula 函数是一种连接多维联合分布与一维边缘分布的特殊函数,基于此函数,多个相关退化量的联合分布可以通过每个退化量的边缘分布和Copula 函数融合为一个整体分布[128].Pan 等[129]、Peng等[130]、刘胜南等[131]、张建勋等[132]采用不同的随机过程模型和Copula 函数研究了多元退化变量的建模问题,并用于剩余寿命预测.然而,基于Copula 函数的方法成功应用的关键在于Copula 函数的选择,不同的退化数据常常适用于不同的Copula 函数,而且可供选择的Copula 函数形式是非常有限的,选择的过程有一定的主观性,选择结果也不唯一,因此这类方法难以对多个性能退化变量之间的相互作用关系进行合理的定量描述.第2 种是基于信息融合的方法.这种方法的主要思路是在进行退化建模之前,首先根据多维数据之间的关系,通过优化、加权、融合滤波等方式,将多维数据投影变换到一维数据上来,提取一个单变量复合性能指标,再应用已有针对单变量的方法对此一维数据进行建模和预测.例如,Liu 等先后提出了基于退化信号加权组合[133-134]、基于信号质量优化[135]、基于多源信息融合[136-137]的复合性能指标获取方法,据此采用单变量退化建模方法实现剩余寿命预测.此类方法的优点在于融合后的性能指标可以采用传统针对单变量的退化建模和剩余寿命预测方法.然而,在多维数据融合时其相互之间的关系一般难以界定,使得融合后的指标难以全面反映整个设备的退化,而且融合后的指标物理意义不明确,导致退化失效阈值的确定成为一个新的难题.
通过以上文献分析可以看出,统计数据驱动方法以概率统计理论为基础,利用随机模型对监测数据进行建模,进而对剩余寿命进行推断,可以得到剩余寿命的概率分布,在量化剩余寿命预测不确定性上具有天然优势,且随机模型参数与设备退化失效过程紧密相关使得模型可解释性较强(如反映退化快慢的退化率参数、反映退化过程时变不确定性的扩散系数等),因此得到了可靠性领域学者的大力推崇,发展迅速.但需要注意到的是,无论是单变量下还是多变量下,这类方法主要针对图2 所示的完整监测数据且需要能够从监测数据中提取具有一定统计特征的退化趋势数据以实现参数化的演变轨迹建模.然而,在大数据时代,通常采用传感器网络收集多物理源信号以全面反映设备状态,由于多源信号差异大、采样策略形式多,数据价值密度低,导致数据质量参差不齐,现有统计数据驱动的方法从大数据中提取退化特征信息如同大海捞针,处理如图2 所示的 “碎片化、分段的、稀疏的”监测大数据更是难上加难,没有良好统计特征的退化数据做输入,这类方法必将迷失于浩瀚的数据海洋.此外,单变量下随机退化设备剩余寿命预测研究试图提取单一特征表征设备健康状态全貌的思路,已与复杂运行条件下设备健康状态需从多维度表征的需求不相适应,而现有多变量下随机退化设备剩余寿命预测问题的研究基本都是试图通过转换为单变量情况再来处理,未充分考虑多性能退化变量相互耦合、相互影响的机制,多变量耦合导致的剩余寿命分布求解难题仍未能得到有效解决.因此,针对大数据环境下随机退化设备的剩余寿命预测问题,发展新的理论和方法势在必行.
5 机器学习方法与统计数据驱动方法相结合的剩余寿命预测
通过第3 节和第4 节的文献分析可以看出,以深度学习为代表的机器学习方法在监测大数据深层次特征自动提取、复杂结构数据拟合、非线性映射等方面具有强大的处理能力,但很难得到体现剩余寿命预测不确定性的概率分布,这与其强大的数据处理能力和学习能力还不相匹配.统计数据驱动的方法虽能得到剩余寿命的概率分布、在量化剩余寿命预测不确定性上具有天然优势,但对具有多源信号差异大、采样策略形式多、数据价值密度低、数据质量参差不齐等特点的监测大数据处理能力非常有限.因此,若能将机器学习方法与统计数据驱动方法相结合,有望综合两者的优势、弥补各自局限性.最近,一些学者也开始了这方面的探索性研究.Deutsch 等[138]将深度置信网络用于提取退化特征,然后用随机退化模型表示特征的演变趋势,利用粒子滤波算法实现模型更新,并得到了剩余寿命概率分布的数值形式.彭开香等[139]研究提出了一种基于深度置信网络的无监督健康指标构建方法,并结合隐马尔可夫模型对特征进行建模用于剩余寿命预测.进一步,该方法被改进为深度置信网络与粒子滤波相结合的形式[140],可以实现剩余寿命概率分布的数值计算.最近,Hu 等[141]利用深度置信网络的无监督学习特性构建性能退化指标,然后采用非线性扩散过程建模性能退化指标演变趋势,从而得到了剩余寿命的概率分布.
这些研究在做出了有益尝试的同时,还存在不容忽视的局限性: 1)以上方法中深度网络用于特征提取而随机模型用于建模特征实现剩余寿命的概率分布输出,但在实现过程中特征提取和模型建立是孤立进行的,由此导致机器学习方法和统计数据驱动方法实际是简单的组合关系,提取的深度退化特征能否适应并匹配所采用的随机模型仍是问题,因为在特征提取过程中并没有考虑提取后采用何种形式的模型对其建模表征;2)深度网络通常可以从监测大数据中提取深层次、多维度的退化特征,但以上方法通过指标筛选技术从多维度特征中选择单个特征用于随机退化建模,由此这类方法还存在第4节讨论的所选单一特征难以表征设备健康状态全貌、未考虑多变量耦合下剩余寿命分布求解等问题;3)通过深度网络从大数据中提取的退化特征实际上是虚拟退化指标,物理意义不明确,由此导致这些退化指标所对应的失效阈值确定成为一个新的难题.
通过上述分析可见,若能综合统计数据驱动方法在预测不确定性量化能力上的优势与机器学习方法在大数据处理能力上的优势,实现交互联动、交叉融合、强强联合,发展大数据环境下随机退化设备剩余寿命预测新理论与新方法,有望为大数据时代设备剩余寿命预测与健康管理打造一把利器.然而,现有为数不多的综合机器学习方法和统计数据驱动方法的剩余寿命预测研究中,基于监测数据的退化特征提取过程与所提取特征的随机过程建模是孤立进行的,由此导致机器学习方法和统计数据驱动方法实际上是简单的组合关系.此外,这些研究中提取退化特征的过程中主要关注了特征本身的特性(如单调性、趋势性等),但如此提取的特征能否适应并匹配所采用的随机过程模型并不能保证.因此,发展大数据下退化特征提取与随机退化建模交互联动的剩余寿命预测方法,将有助于形成大数据下剩余寿命预测研究的新模式.
6 一种数模联动融合多源传感器数据剩余寿命预测思路
根据第1 节大数据下剩余寿命预测问题面向的数据特点,可知如何有效融合随机退化设备的多源传感监测数据是实现这类设备剩余寿命精准预测的关键.针对多源传感监测大数据融合下的剩余寿命预测问题,通过第4 节和第5 节的文献介绍,可以发现Liu 等[133-137]在设备退化特征应当具有的单调性、趋势性、失效时刻复合健康指标值方差最小等期望特性的要求下,通过构建适当的优化目标函数,提出了多传感信号加权融合构建复合健康指标的方法,在此基础上采用随机系数回归模型建模复合健康指标的演化轨迹以实现剩余寿命预测;彭开香等[139]将深度置信网络应用于多源传感监测数据融合构建退化特征,提取复合健康指标,然后通过随机模型建模其演变过程实现剩余寿命预测.然而,以上研究均存在第5 节分析的将本身紧密相连的退化特征提取与随机退化建模过程孤立进行而导致构建的退化特征和所采用的模型难以匹配的问题.因此,第5 节提出发展大数据下退化特征提取与随机退化建模交互联动的剩余寿命预测方法具有重要研究价值.
为了解决以上问题并佐证前面提出的通过交互联动思想实现大数据下剩余寿命预测的可行性,本文以融合多源传感监测数据的剩余寿命预测问题为例,提出一种针对完整监测大数据的随机退化设备剩余寿命预测的新型解决思路,其基本思想是: 根据设备多源传感监测数据,在数据层进行多源传感器加权融合构建复合健康指标用于表征设备退化特征,然后采用随机过程模型建模该复合健康指标时变演化趋势,通过求解复合健康指标首达失效阈值的时间实现寿命预测,基于寿命预测值与设备实际寿命的偏差构建表征预测效果的优化目标函数,对多源传感器融合系数和随机退化建模中的参数进行反向优化调整,形成复合健康指标提取与随机退化建模的反馈闭环,实现复合健康指标提取与随机退化建模的交互联动、交叉融合,达到复合健康指标与随机模型自动匹配的目的,同时克服复合健康指标物理意义不明确进而导致其对应的失效阈值难以确定的问题.以上提出的新思路,简称为数模联动,是指数据退化特征提取与所提取特征时变演化过程随机建模的交互联动、交叉融合,力求思路导向结果.主要实现方案及流程如图3 所示.
通过图3 可以看出,本文提出的数模联动思路,通过形成复合健康指标提取过程与随机退化建模过程的反馈闭环,使得复合健康指标提取与随机退化建模交互联动,这一思路与文献[138-141]中退化特征提取与随机退化建模过程孤立进行的思路显著不同.此外,需要说明的是,图3 所示的数模联动方案与第2 节讨论的机理模型与数据混合驱动的方案最大的不同在于其中的退化模型的来源.机理模型与数据混合驱动方案中的模型为设备退化失效的机理模型,但如前所述这类模型的获取往往是困难的,而且机理模型的种类相当有限.相比之下,数模联动方案中的模型指的是用于描述退化特征时变演化趋势的随机过程模型,在模型构建及选择时可以融入退化失效的机理知识但又不完全受机理知识匮乏的束缚,而且根据第4 节的介绍可以看出剩余寿命预测领域对于随机过程模型的研究高度重视,仍处于蓬勃发展阶段,针对退化建模的各类随机过程模型层出不穷,因此数模联动方案应用于剩余寿命预测时更具灵活性,有助推广应用于各类退化设备.

图3 多源传感器剩余寿命预测数模联动解决方案与流程图Fig.3 Idea and flowchart of data-model interactive remaining useful life prediction with multi-source sensors
下面针对多源传感器监测下随机退化设备剩余寿命预测问题,根据上述数模联动原理,给出具体实现过程的一个示例,以说明其可行性和有效性.
6.1 多源传感器监测数据加权融合
令xi,j(t) 为第i(1≤i ≤N)个随机退化设备第j(1≤j ≤S) 个传感器在t(t ≥0)时刻采集到的性能退化监测数据,N为需要监测的随机退化设备个数,假设对于同一个随机退化设备共安装有S个传感器.根据多源传感器数据,运用加权方法,融合多传感器监测数据后的复合健康指标表示为

其中,wj表示第j个传感器的融合系数,衡量了该传感器在数据融合过程中所占比重.
假设第i(1≤i ≤N)个随机退化设备对应监测时刻为ti={ti,0,ti,1,ti,2,···,ti,Ki},则复合健康指标对应的观测数据为zi={zi,0,zi,1,zi,2,···,zi,Ki},其中,zi,k=Zi(ti,k),k=0,1,2,···,Ki,Ki为第i个随机退化设备的监测数据个数.不失一般性,本文仅考虑随机退化设备监测时间间隔为等间隔的情况,即 Δt=ti,k-ti,k-1.
6.2 基于Wiener 过程的随机退化过程建模
为说明数模联动的思路,这里以具有增长趋势的退化特征为例,考虑线性Wiener 过程建模复合健康指标随时间的演变过程,模型描述为

其中,zi,0为第i个设备在t0=0时刻的初始退化量,λi为漂移系数,反映了第i个设备的退化率,σi为第i个设备的扩散系数,刻画退化过程的随机不确定性,B(t)为反映退化过程时变随机性的标准Brownian 运动.
基于以上建立的退化过程,通过首达时间的概念,设备的寿命可定义为

其中,v是融合多源传感器的复合健康指标对应的失效阈值.
对于随机退化过程(2)和首达时间寿命的定义(3),根据文献[125]可知,寿命Yi服从逆高斯分布,其概率密度函数、数学期望和方差分别为

其中,

根据以上参数估计结果,第i(1≤i ≤N)个随机退化设备寿命的预测值(点估计)可以表示为

其中,失效阈值v和融合系数wj仍然为待确定量,将由下述的数模联动过程优化得到.
6.3 多源传感器监测数据复合健康指标构建与随机退化建模交互联动
多源传感器数据融合后构建的复合健康指标不具备实际的物理意义,且其构建过程和随机过程建模及失效阈值的确定是孤立进行的,相互之间未形成联动、融合机制,这是目前基于多源传感器数据剩余寿命预测需重点解决的关键问题.为解决这一难题,本文基于前面图3 所示的数模联动思路,构建以最小化预测均方误差为核心的优化目标函数,对多源数据融合系数和随机退化建模中的失效阈值进行反向优化调整,形成融合多源数据复合健康指标构建与随机退化建模的反馈闭环,达到复合健康指标构建与随机退化过程模型自动匹配的目的.

对于式(11)的优化求解问题,对应地由式(10)给出的目标函数,现有较为成熟的各类优化方法均可应用.本文在案例验证中将采用应用较为广泛、具有较强灵活性的拟牛顿法进行多维搜索求解,具体通过MATLAB 中的 “fminunc”函数实现.通过上述优化求解过程,对多源数据融合系数和随机退化建模中失效阈值进行迭代优化调整,实现退化特征提取与随机退化建模的交互联动、交叉融合,达到复合健康指标构建与随机退化建模自动匹配的目的.基于以上数模联动过程确定的复合健康指标融合系数和失效阈值,可以根据实际服役设备多源传感器监测数据,构建其复合健康指标,然后采用随机模型建模其演变过程,进而实现服役设备的剩余寿命预测.
6.4 案例应用
为验证上述数模联动融合多源传感器数据进行剩余寿命预测的思路,本文基于文献[142]和文献[143]提供的C-MAPSS 涡扇发动机退化数据集中的训练数据集train_FD001 通过数模联动过程确定复合健康指标融合系数和失效阈值,基于测试数据集test_FD001 验证应用于个体服役设备剩余寿命预测时的效果,其中训练数据集和测试数据集分别包括了100 个发动机的21 个传感器监测数据,即N=100.
针对涡扇发动机退化数据集,可以发现部分传感器的数据基本没有变化,不具有时变的趋势性特征,从数据趋势建模的角度看这些传感器数据的质量难以满足可预测性要求.因此,在进行多源数据融合前一般先进行传感器的选择.为此,本文选取衡量退化数据趋势性的皮尔逊相关系数作为表征数据质量的一个评价指标进行传感器的筛选.具体地,令第i(1≤i ≤N) 个发动机对应监测时刻为ti={ti,0,ti,1,ti,2,···,ti,Ki},xi,j(t) 为第i(1≤i ≤N)个发动机的第j(1≤j ≤S) 个传感器在t(t ≥0)时刻采集到的性能退化监测数据,Ki+1 为第i个发动机的监测数据个数,则第i个发动机的第j(1≤j ≤S)个传感器监测数据对应的皮尔逊相关系数ri,j为

根据式(12),对train_FD001 数据集中每个发动机的各个传感器数据对应的皮尔逊相关系数ri,j进行计算,然后取各个传感器相关系数的平均值作为传感器选择的依据.本文根据计算的皮尔逊相关系数ri,j,选择一致性较好且平均值较大的 2,3,4,7,11,12,15,17,20,21号传感器数据,用于数模联动的多源传感数据融合复合健康指标构建,此时S=10.在此基础上,本文对该训练集中100 台发动机的以上10 个传感器监测数据做最大-最小归一化处理和平滑去噪处理[144],然后应用本文提出的数模联动方法,通过MATLAB 中的 “fminunc” 函数求解式(11),可以得到融合系数为{W*}={-0.0204,0.3 0 3 6 4,0.4451,-0.2238,0.0910,-0.1339,0.1283,0.1126,-0.0201,-0.1522},失效阈值为v*=0.7648.根据以上融合系数,可以利用train_FD001 数据集,融合该数据集中100 个发动机考虑 2,3,4,7,11,12,15,17,20,21 号传感器数据的复合健康指标.然后,基于构建的复合健康指标和确定的失效阈值,利用如式(2)所示的线性Wiener 过程分别对测试数据集中100 个发动机的复合健康指标建模并预测剩余寿命,由此实现数模联动的融合多源传感器剩余寿命预测.
为了说明本文提出的数模联动方案实现复合健康指标提取与随机退化建模交互联动后对于数据质量的改善情况及应用于剩余寿命预测时的效果,下面分两个方面进行性能的对比.
1)数模联动后数据质量改善效果
首先,基于皮尔逊相关系数对数模联动优化后构建的复合健康指标与单一传感器指标数据在趋势性方面的效果进行对比.表1 给出了train_FD001数据集中100 个发动机的 2,3,4,7,11,12,15,17,20,21 号传感器数据的平均皮尔逊相关系数值和数模联动构建的复合健康指标的平均皮尔逊相关系数值.
由表1 中结果可以看出,数模联动融合多源传感监测得到的复合健康指标的皮尔逊相关系数平均值超过0.9,明显高于单一传感器对应的值,表明数模联动构建的复合健康指标的时变趋势性更好,在改善用于退化建模的复合健康指标数据的质量方面效果明显.

表1 皮尔逊相关系数对比结果Table 1 Comparative results of Pearson correlation coefficients
进一步,考虑到数据集中的发动机具有相同的型号且都是设定在相同的工作条件下,因此用于退化建模的健康指标值在发动机失效时刻的分散程度应当尽可能小,以体现同类发动机在相同条件下质量的一致性.例如,文献[133,137]中通过使复合健康指标在失效时刻取值的方差最小化来构建复合健康指标.鉴于此,本文将通过数模联动构建的复合健康指标在发动机失效时刻取值的方差与以上研究中的结果和单一传感器对应的结果进行对比,具体结果如表2 所示.

表2 失效时刻健康指标值的方差比较Table 2 Variance of health indices at failure time
根据表2 中的结果可知,本文数模联动下构建的复合健康指标值在失效时刻对应的方差值远小于单一传感器和文献[133,137]中构建的复合健康指标对应的方差值.值得一提的是,本文的数模联动方法是以寿命预测的均方误差最小为目标构建复合健康指标的,不同于已有文献[133,137]中以复合健康指标在失效时刻取值方差最小化的出发点,但通过表2 的结果表明本文方法在改善失效时刻发动机复合健康指标数值的一致性方面也有较好的效果,这将为本文方法提升剩余寿命预测效果奠定基础.
2)数模联动剩余寿命预测效果对比
本节将数模联动方法在剩余寿命预测的效果与基于单一传感器数据的方法及前面文献综述中涉及的方法进行对比,以佐证基于多源监测大数据进行数模联动剩余寿命预测的必要性和性能提升潜力.为此,本文采用针对该数据集的3 种剩余寿命预测领域常用的性能对比指标: 预测得分、准确性及均方误差,其定义分别如下:
a) 预测得分(Score)

该指标值反映了剩余寿命预测误差落在区间内的百分比,反映了预测的准确性,其值越大越好.
对于以上两种评价指标,这里需要说明的是:在剩余寿命预测领域,C-MAPSS 航空发动机退化数据集已成为验证剩余寿命预测方法的基准数据集,而该数据集最早用于IEEE PHM 2008 挑战赛,挑战赛主办方为了评价各类预测方法在该数据集上的表现,给出了预测得分(13) 以及准确性指标(14)和(15).通过式(13)可以看出预测得分是非对称的评价指标,且该指标值越小越好.采用非对称指标的主要出发点在于: 考虑到提前预测(errori ≥0)产生的后果要小于滞后预测(errori <0)产生的后果,对于提前预测给予较小的惩罚而对于滞后预测给予更大的惩罚这是由于滞后的剩余寿命预测将使得设备运行失效而未能提前维护的风险更大,因此给予更大的指标值以示惩罚.在该指标中,-10 和13 这两个数值就是用于反映这种非对称性的,也是由IEEE PHM 2008 挑战赛主办方给出的.因此,预测误差若能够落在区间,则在一定程度上就能够反映剩余寿命预测方法的准确性,这也就是准确性指标是统计预测误差落在区间内的百分比的原因所在.在IEEE PHM 2008 挑战赛后,预测得分和准确性指标被一直沿用于评价各种剩余寿命预测方法在C-MAPSS航空发动机退化数据集上的预测效果,-10 和13 这两个数值也被领域内广泛采纳.因此,本文为了和现有的各类方法进行对比,也使用了这两个指标.
c) 均方误差(Mean squared error,MSE)

该指标值反映了预测误差平方的平均值,其值越小越好.
基于以上预测性能指标,本文将提出的数模联动剩余寿命预测方法与基于单一传感器数据的方法及前面文献综述中涉及的一些典型的基于机器学习的方法和混合方法进行对比.具体地,用于对比的方法包括: 支持向量回归方法[65]、基于案例的学习方法[71]、基于案例的推理方法[72]、多目标深度置信网络集成方法[86]、卷积神经网络[92]、循环神经网络[96]、限玻尔兹曼机+LSTM 网络[104]、基于长短时网络的编码-解码器[106]、循环神经网络+自编码器[107]、基于多损失编码器与卷积复合特征的两阶段深度学习方法[108]、深度置信网络+后向传播神经网络+改进粒子滤波算法[140]、深度置信网络+改进粒子滤波算法[140]以及基于线性Wiener 过程随机建模单一传感器监测数据的剩余寿命预测方法.表3 给出了各类方法在预测得分、准确性、均方误差等性能指标上的对比结果.这里需要说明的是,为了更客观地反映对比效果,表3 中采用了对比文献中各类方法得到的预测得分、准确性及均方误差的最好效果(众所周知,机器学习类方法的预测结果对模型参数的设置具有较大依赖),其中 “—”表示对比文献中没有计算并给出这一指标值.
通过表3 中的结果可以发现,相比各类基于机器学习的剩余寿命预测方法、机器学习与统计数据驱动相结合的剩余寿命预测方法、基于线性Wiener 过程随机建模单一传感器监测数据的剩余寿命预测方法在该发动机数据集上的表现,本文提出的数模联动多源传感监测数据融合剩余寿命预测方法在预测得分、准确性、均方误差等性能指标上均保持明显的优势.以上验证结果表明,构建以最小化预测均方误差为核心的优化目标函数,对多源数据融合系数和随机退化建模中的失效阈值进行反向优化调整,形成多源传感数据复合健康指标构建与随机退化建模的反馈闭环,将很大程度上实现复合健康指标构建与随机退化过程模型自动匹配的目标,进而提升剩余寿命预测性能,有助于思路导向结果.此外,表3 的对比结果反映出通过数模联动实现退化特征提取与随机退化建模交互联动的思路在应用于剩余寿命预测时,预测性能好于典型的基于机器学习的方法,甚至也好于一些最新提出的基于深度学习的方法,进而显示出数模联动思路在大数据背景下剩余寿命预测中具有很好的应用潜力.这里需要说明的是,以上案例中所采用的随机过程模型仅仅是最基本的线性Wiener 过程模型,从式(8)可以看出,由于该过程的独立增量特性和马氏性,漂移系数估计结果中仅仅利用了初始时刻和最后监测时刻的数据,忽视了中间演变过程的数据,势必会影响建模及预测性能.因此,采用更为先进的模型参数估计方法(如Bayesian 方法、自适应滤波方法等)将有望进一步优化数模联动下剩余寿命预测的效果.此外,实现数模联动的关键在于构建反映预测性能的目标函数J(W,v),然而以上案例中J(W,v)仅仅考虑了剩余寿命预测的点估计,未考虑反映预测不确定性的剩余寿命预测的方差,因此通过预测误差和表征预测不确定性的量构建以预测不确定性为核心的优化目标函数将是值得深入研究的问题.以上两种思路将使得目标函数J(W,v)的复杂性显著增加,因此进一步研究相应的优化求解技术也很有必要.
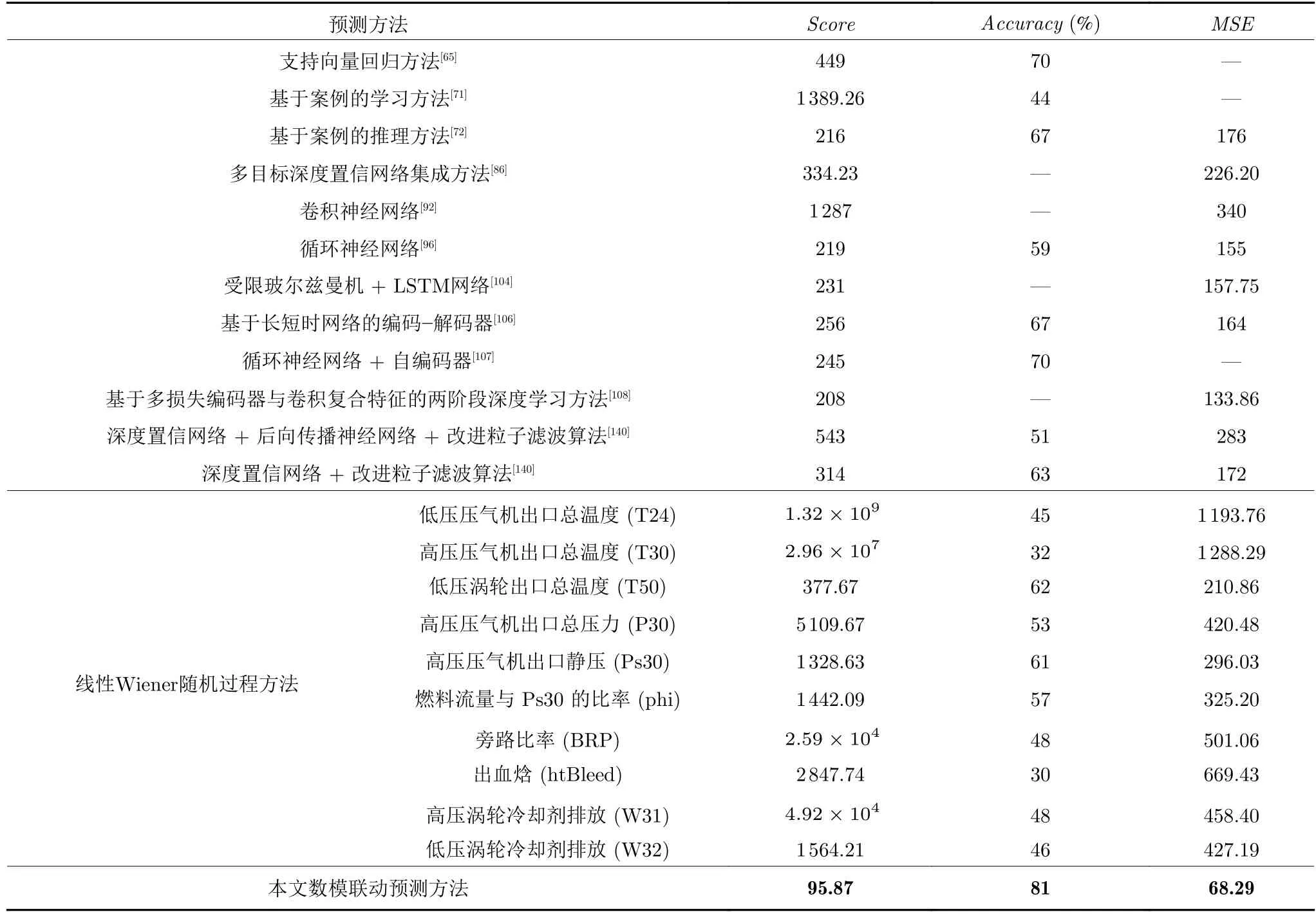
表3 剩余寿命预测性能比较Table 3 Comparative results in the performance of the remaining useful life prediction
综上,数模联动融合多源传感器监测数据的发动机剩余寿命预测应用案例结果虽然初步验证了本文提出的数模联动思路的可行性和有效性,但发展先进实用的数模联动剩余寿命预测技术,特别是如何将数模联动的思路推广用于解决大数据背景下随机退化设备的剩余寿命预测问题,任重道远.
7 主要挑战及科学问题
大数据环境下随机退化设备的剩余寿命智能预测是工程需求驱动的前沿研究方向,然而通过前面的文献分析可以发现已有理论与方法在解决大数据下剩余寿命预测问题时捉襟见肘,主要表现为: 1)基于机器学习的剩余寿命预测在大数据深层次特征自动提取、复杂结构数据拟合、非线性映射等方面具有强大处理能力,但用于剩余寿命预测时难以得到其概率分布并量化预测不确定性;2)统计数据驱动方法以概率统计理论为基础,在量化剩余寿命预测不确定性上具有天然的优势,但更多处理的是完整监测数据且需要一定趋势性的退化特征以实现参数化建模,在应对多源信号差异大、采样策略形式多、数据价值密度低、数据质量参差不齐等特点的监测大数据,特别是 “碎片化、分段的、稀疏的”监测大数据时明显力不从心;3)机器学习方法与统计数据驱动方法相结合的剩余寿命预测研究既能处理大数据又能得到剩余寿命的概率分布,但两者未能实现交互联动、交叉融合、自动匹配,存在特征提取与随机建模孤立进行、退化特征失效阈值难确定、多维化深度特征下剩余寿命分布难求解等问题,与大数据下剩余寿命预测的需求还不相适应.
针对以上研究挑战,第6 节以多源传感监测大数据下剩余寿命预测问题为例,提出了一种数模联动的完整监测数据下随机退化设备剩余寿命预测问题解决思路,并通过航空发动机多源监测数据初步验证了该思路的可行性和有效性.借鉴所提出的数模联动思路,综合考虑机器学习方法和统计数据驱动方法的优势,紧紧扭住剩余寿命预测不确定性量化问题,大数据背景下随机退化设备的剩余寿命预测主要存在以下亟待解决的关键科学问题.
7.1 深度学习与随机退化过程建模交互联动的剩余寿命预测问题
针对以深度学习为代表的机器学习方法在监测大数据深层次特征自动提取、复杂结构数据拟合、非线性映射等方面具有强大的处理能力但很难得到体现剩余寿命预测不确定性的概率分布,而统计数据驱动的方法针对完整监测数据虽能得到剩余寿命的概率分布但对大数据处理能力非常有限的问题,可以借鉴第6 节针对多源传感监测数据提出的数模联动思路,发展深度学习与随机退化过程建模交互联动的剩余寿命预测技术,通过深度学习网络提取大数据下设备退化特征,运用随机过程模型对其表征并预测寿命,构建以最小化预测不确定性为核心的优化目标函数,实现深度网络特征提取与随机退化建模的交互联动、交叉融合,达到深度特征提取与随机退化模型自动匹配、失效阈值优化确定的目的.通过这一思路,使得深度退化特征的提取直接服务于随机退化建模和剩余寿命预测,有助于保证思路导向最终的结果——提升剩余寿命预测性能.在此过程中,如何通过深度学习网络从大数据中提取反映设备退化的复合特征指标、如何构建面向预测不确定性最小化的优化目标函数、如何利用目标函数反向优化调整网络参数和模型参数形成复合特征指标提取与随机退化建模的反馈闭环等都是需要解决的关键问题.
7.2 多变量下数模联动的剩余寿命预测问题
在工程实际中,设备受运行工况、环境、负载等复杂因素相互影响,表征设备健康状态的性能退化特征往往并不唯一且相互关联.现有多变量下随机退化设备剩余寿命预测问题的研究基本都是试图通过转换为单变量情况再来处理,未充分考虑多性能退化变量相互耦合、相互影响的问题.因此,在深度学习与随机退化建模交互联动思路启发下,通过深度学习网络提取大数据中多维度深层次退化特征,构建多变量下的设备性能退化过程模型,研究多变量耦合下随机模型参数估计及寿命分布求解问题,实现深度网络特征提取与随机退化建模的交互联动,达到多维深度特征与随机退化模型的自动匹配、失效阈值的优化确定,对于大数据下复杂退化设备的剩余寿命预测具有重要意义.在此过程中,如何通过深度学习网络从大数据中提取反映设备退化的多维度深层次退化特征、如何考虑多维特征耦合关系的前提下建模其演变趋势、如何求解多变量耦合下设备的剩余寿命分布等问题极具挑战性,有待深入系统的研究.
7.3 非理想大数据下的剩余寿命预测问题
数据是开展数据驱动剩余寿命预测研究的基础,数据质量很大程度决定了剩余寿命预测的准确性和鲁棒性.然而,随机退化设备的监测大数据往往呈现非理想的状态,具体表现为大而非平衡、局部缺失、不完备等特点,如图2 所示的 “碎片化、分段的、稀疏的”非完整监测大数据.据统计公开发表的NASA 数据集中,正常工况的数据达95%,而异常极端环境数据只有5%[145],美国马里兰大学先进寿命周期中心(Center for advanced life cycle engineering,CALCE)公布的数据集中的情况与此类似[146].可见,实际设备的非理想监测大数据在工程中客观存在,数据的非理想将导致基于这些数据建立的剩余寿命预测模型泛化能力不足,局限于某一特定条件.
针对非理想数据中的非平衡、局部缺失等数据,如果能利用先进的数据增强技术或能够将其他工况、环境下的数据迁移到待研究的问题中,将有望改善数据质量从而提升剩余寿命预测的效果.例如,针对数据缺失问题,可以通过生成对抗网络利用有限的数据训练生成网络和判别网络以增强与扩充数据.当前生成对抗网络在处理缺失数据的问题中应用较多,但这些研究更多地追求生成的数据与真实数据之间的接近程度,如果能够应用前面提出的数模联动的思想,在构建生成对抗网络目标函数时考虑生成数据改善剩余寿命预测性能方面的效果,将数据扩充后剩余寿命预测效果改善情况用于指导数据生成,有望为缺失数据下剩余寿命预测问题的研究打开新的思路;针对不同工况下非平衡数据的问题,迁移学习技术将是有效的解决途径,通过挖掘源域和目标域的数据共性,将不同工况下的数据可以转换到特定工况下,以实现不同工况下非平衡数据的增强与扩充.类似地,如果在数据迁移实现数据扩充时能关注扩充后的数据在剩余寿命预测应用时的效果,将能够更好地实现数据的扩充直接服务于最终剩余寿命预测应用的目标,避免两者脱节导致数据与最终效果不匹配的问题.
此外,针对图2 所示的具有数据价值密度低、数据质量参差不齐等特点的 “碎片化、分段的、稀疏的” 非完备监测大数据,以深度学习为代表的新一代机器学习方法,在大数据深层次特征提取、复杂结构数据拟合、非线性映射等方面具有强大的处理能力,为建立 “碎片化、分段的、稀疏的” 监测大数据与剩余寿命之间的映射关系提供了新的可能,但在建立映射关系的同时如何量化预测不确定性仍是当前面临的主要挑战.为此,针对非完整监测大数据,可考虑直接通过深度学习网络建立 “碎片化、分段的、稀疏的” 非完整监测大数据与包含寿命信息的标签信息及其预测不确定性的映射机制,在网络构建过程中将网络参数随机化,表示为随机变量,由此构建概率深度网络,网路结构形式可以是卷积神经网络、循环神经网络、LSTM 等,然后运用Bayesian 方法估计网络参数的后验分布,使得网络输出具有随机性以达到获取概率分布的目标.最近,一些学者开始了这方面的有益尝试[147-148],但这些仅有的研究中需要充分的寿命数据作为标签数据,在实际工程中当面对截尾数据时,由于缺乏寿命信息,这类方法的适用性受到一定限制.因此,如何在寿命标签信息匮乏条件下,通过概率深度网络拟合监测数据趋势并滚动预测,由此发展面向非完整监测大数据的剩余寿命预测方法仍有待突破.此外,在概率深度网络中,由于参数的随机变量化处理,导致网络参数的Bayesian 估计涉及高维积分的求解问题,直接求解难度很大.因此,发展面向概率深度网络参数Bayesian 估计的高效近似求解技术,对于攻克非完整监测大数据下剩余寿命预测难题具有重要意义,值得深入研究.
综上,非理想数据的问题在大数据下随机退化设备剩余寿命预测研究中普遍存在,本文针对几类典型的非理想数据,探讨了可能的研究思路,但需要说明的是,剩余寿命预测领域对这一问题的关注程度还不够,目前针对性的处理方法还比较有限.可以预见的是,随着大数据下随机退化设备剩余寿命预测迫切需求的驱动和相关研究的深入,非理想大数据下的剩余寿命预测问题将逐渐成为新的研究热点.
8 结束语
本文面向大数据背景下随机退化设备剩余寿命预测的现实需求,深入分析了机理模型与数据混合驱动的剩余寿命预测技术、基于机器学习的剩余寿命预测技术、统计数据驱动的剩余寿命预测技术以及机器学习和统计数据驱动相结合的剩余寿命预测技术的基本研究思想和发展动态.在此基础上,结合随机退化设备监测大数据的特点以及剩余寿命预测不确定性量化问题,全面剖析了当前研究存在的局限性和共性难题.针对这些问题,本文以多源传感监测大数据下剩余寿命预测问题为例,提出了一种大数据下数模联动的随机退化设备剩余寿命预测问题解决思路,通过构建以最小化寿命预测均方误差为核心的优化目标函数,对多源数据融合系数和随机退化建模中的失效阈值进行反向优化调整,达到复合健康指标构建与随机退化过程模型自动匹配的目的,并通过航空发动机多源监测数据初步验证了该思路的可行性和有效性.最后,借鉴数模联动思路,本文提出了大数据背景下深度学习与随机退化建模交互联动、监测大数据与剩余寿命及其预测不确定性映射机制、非理想大数据下的剩余寿命预测等亟待解决的关键科学问题,并探讨了解决思路.
