基于强化学习的部分线性离散时间系统的最优输出调节
2022-09-30庞文砚范家璐LEWISFrankLeroy
庞文砚 范家璐 姜 艺 LEWIS Frank Leroy
输出调节问题是一种对于线性和非线性动态系统,设计反馈控制器从而使系统实现渐近跟踪和干扰抑制的问题[1-5].输出调节问题的显著特征则是参考输入和干扰由已知的外系统自主微分或差分方产生的[5].目前,已有学者研究了连续时间系统的输出调节问题[6-8].文献[5]对线性和非线性连续时间系统的输出调节问题给出了解决框架.文献[6]研究了一类加入瞬态性能概念的输出调节问题,详细研究了可解性条件和调节器结构等问题.而文献[5-6]都需要在系统的动态模型参数已知的情况下,解决其输出调节问题.
强化学习作为一种机器学习方法,是以目标为导向的学习工具,其中智能体或是决策者通过与环境交互为最优化长期奖励来学习控制策略[9-11],可主要解决控制领域中的最优控制问题,其中包括最优调节,最优跟踪以及最优协同问题.最优控制问题是一类通过使得代价函数或性能指标达到最优而为动态系统寻找控制律的问题.典型的最优控制问题是需要系统的模型参数完全已知,问题的求解是离线的,其不能适应动态系统中模型参数的变化和不确定性,因此数据驱动的强化学习方法也就应运而生,广泛应用于解决离散时间和连续时间不确定系统的最优控制问题.文献[12]利用数据驱动的强化学习方法利用沿着系统的数据解决了线性系统的最优跟踪问题,又因为系统的状态数据往往难以获得,文献[13]提出仅利用输入输出数据,利用强化学习中的策略迭代和值迭代算法在线寻得最优控制律从而实现最优跟踪.这2 篇文献是针对于线性系统,文献[14]则针对于非线性系统,采用基于Actor-Critic 结构的强化学习方法数据驱动在线学习跟踪哈密顿-雅可比-贝尔曼方程(Hamilton-Jacobi-Bellman,HJB),从而解决最优跟踪问题.由于H无穷问题也可看作是一种最优控制问题,主要是分别找出最优反馈控制律和最优扰动控制律的一类问题,因此强化学习也应用于该问题的解决.针对于H无穷控制问题,对于线性系统模型参数未知的文献[15],该文采用强化学习离线策略控制方法进行解决,并证明了探测噪声会对在线策略迭代算法产生影响使获得参数不准确,而则不会对离线的策略迭代算法产生影响,同时证明了离线策略迭代算法的收敛性.文献[16]则对于未知的非线性系统,采用强化学习的离线策略方法学习跟踪哈密顿-雅可比-艾萨克方程方程(Hamilton-Jacobi-Isaac,HJI)的解,在不知道系统模型参数的情况下解决了H无穷跟踪控制问题,并给出所提算法的收敛性.数据驱动的强化学习方法还可应用于无线网络环境下的控制问题,文献[17]就针对于离散时间的网络系统利用沿着系统轨迹的数据实现网络控制系统的最优跟踪问题.数据驱动的强化学习方法近年来解决了线性与非线性系统、连续和离散系统、传统状态空间控制和网络控制系统、利用沿系统轨迹数据和利用输入输出数据等的最优控制问题.
前文提到传统的输出调节问题都是基于系统的模型参数即模型已知的前提下求解输出调节问题.而文献[7-8]则是在系统模型参数不确定的情况下利用数据驱动的方法解决输出调节问题.在文献[7-8]中,对于连续时间系统分别采用近似动态规划和鲁棒近似动态规划的方法解决了线性系统和部分线性系统的最优输出调节问题.由于强化学习是解决最优控制问题的有力工具,前述也有许多学者采用了强化学习方法解决最优跟踪问题,现在另外考虑外部系统的干扰,把强化学习应用到解决最优输出调节问题中.文献[18]将文献[7]中利用数据驱动方法求解线性连续时间系统的最优输出调节问题拓展到线性离散时间系统中.本文则是针对部分线性的离散时间系统,在具有模型参数未知的情况下,利用基于强化学习的离线策略更新方法数据驱动求解最优输出调节问题.
本文将数据驱动的强化学习方法与最优输出调节问题相结合.主要贡献如下: 针对于存在线性干扰和非线性不确定性的部分离散时间系统的最优输出调节问题,提出基于强化学习的离线策略更新算法.该方法不需要知道系统的模型参数,只利用测量数据在线求解即可实现对最优输出调节控制律的自适应学习,即可应对系统模型参数的变化,且提出的方法不仅可以抑制线性的外部干扰并且对动态非线性不确定性存在鲁棒性保证渐近跟踪.并运用了小增益定理说明了本文提出的方法可以保证闭环系统的稳定性.
本文结构如下: 第1 节介绍离散时间部分线性系统的最优输出调节问题.提出最优输出调节问题中的两个优化问题,分别为静态优化问题和动态优化问题;然后将该离散时间系统转化为误差系统,通过证明误差系统的全局渐近稳定性以推出原系统的最优输出调节问题的可解性.第2 节针对具有线性外部干扰和非线性不确定性的部分线性离散时间系统,提出离线策略更新算法利用在线数据求解动态规划问题,并基于动态规划问题的解,用数据驱动的方法解静态规划问题以此解决其最优输出调节问题.第3 节提供仿真结果验证本文方法的有效性,并进行对比实验,比较性能指标突显本文方法的优越性.第4 节为结束语.
符号说明及概念介绍.R+表 示非负实数集,Rn×m表示n×m维矩阵,Rn即 Rn×1,Z+表示非负整数集,⊗表示克罗内克积,vec 为矩阵的拉直运算,把矩阵按照列的顺序一列接一列的组成一个长向量,trace 表示矩阵的迹,Id 表示恒等函数,◦表示函数的复合运算,f◦g表示函数f和g的复合函数,即f◦g(x)=f(g(x)),λmax(λmin)表示矩阵的最大(最小) 特征值,|x|表示向量x的欧几里得范数,‖A‖表示矩阵A诱导欧几里得范数,xT表示向量x的转置.‖u‖表示 s upk>0|u(k)|.
K类函数[19].该类函数为一个严格递增连续函数α: R+→R+且α(0)=0,其可以表示为α∈K.
K∞类函数[19].一个函数为K类函数,当s →∞时α(s)→∞,那么该类函数是K∞类函数,其可以表示为α∈K∞.
KL类函数[19].一个连续函数β: R+×R+→R+.如果对于每个特定的t∈R+,β(·,t)均是一个K类函数,并且对于每个特定的s>0,β(s,·)递减并满足 l imt→∞β(s,t)=0,那么就称β为KL类函数,并表示为β∈KL.
1 控制问题描述
1.1 离散时间部分线性系统被控对象
考虑一组离散时间部分线性系统:


1.2 输出调节问题中的两个规划问题
受文献[7-8,18]启示,对于最优输出调节问题的求解,可拆分成两个规划问题,分别为受约束的静态规划问题和动态规划问题.通过解静态规划问题1可以确定输出调节器方程的解X*,U*,解动态规划问题2 可以确定最优反馈控制增益K*,则可得到最优控制器u*(k)=-K*(x(k)-X*v(k))+U*v(k).
问题1.静态规划问题
通过解下面的静态规划问题确定线性调节器方程的唯一解(X,U)
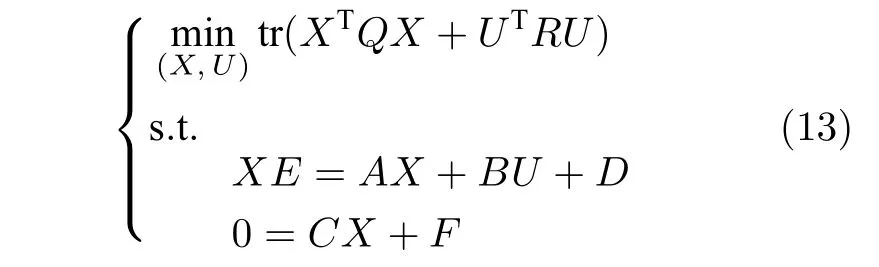
式中,Q=QT>0,R=RT>0.式(13)有约束的规划问题等价于下面的形式:
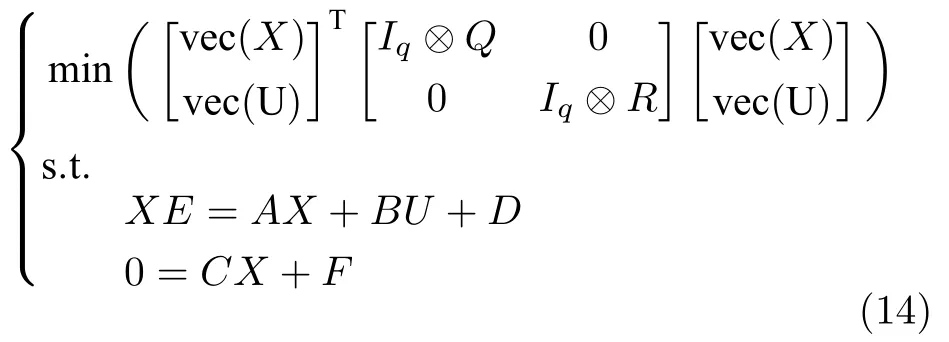
下面先介绍当系统模型参数已知的情况下,静态规划问题的解,即是线性调节器方程的解,并将静态规划问题1 重新改写形式.此部分为第二部分数据驱动求解静态规划问题做铺垫.
且 Λ21是非奇异矩阵.
将式(18)进行展开计算,并把χ中的调节器方程的解 ve c(X) 和 ve c(U)分离出来,可以得到式(19).
定理1.通过解式(19),可得线性调节器方程的解(X,U):
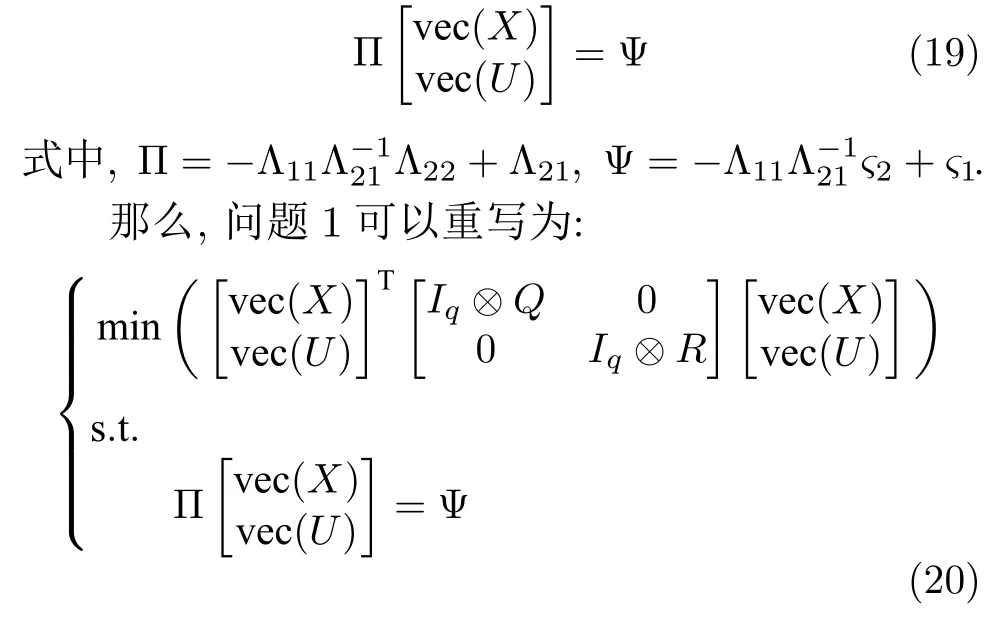
问题2.动态规划问题
解决如下问题来确定最优反馈增益K*:

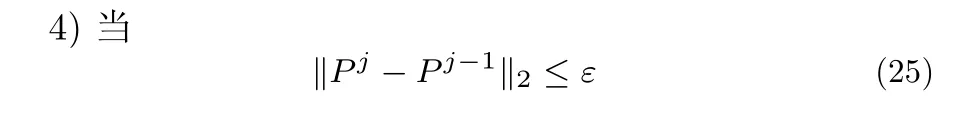
时停止,否则j←j+1 返回2).ε是一个数值很小的正数.
注3.动态规划问题的求解是针对于线性系统,即不考虑系统存在非线性不确定性时,求得的最优反馈增益.第1.3 节对该最优反馈控制器对非线性不确定性是否存在鲁棒性,即是否可以全局渐近镇定误差系统(10)~ (12)进行说明.
1.3 系统最优输出调节问题的可解性
本节将原系统最优输出调节问题的可解性转化为误差系统的全局渐近稳定性,通过提出两个定理进行说明.定理1 说明了最优输出调节控制器使得闭环误差系统是全局渐近稳定的,定理2 说明了原系统的最优输出调节问题是可解的.

成立时,关联的误差系统在原点处全局渐近稳定.□
注7.子系统中的输入-输出增益,是子系统中输入-输出增益.当两个子系统都是强无界能观和输入输出稳定的,且在输入输出稳定小增益条件成立下,两个子系统的输出都趋于零,那么由x¯ 子系统的输入状态稳定性质和子系统的零偏差强无界能观性质,可以知道两个关联系统的状态也是趋于零的.

原系统最优输出调节问题的可解性得以证明后,下部分将对该最优控制器进行学习.第2 节针对于具有未知系统模型参数的离散时间的部分线性系统,用基于强化学习的数据驱动方法,利用测量数据在线求解其最优输出调节问题.
2 数据驱动在线求解最优输出调节问题
强化学习中学习的方式分为离线策略学习算法和在线策略学习算法两种.离线策略更新算法中的行为策略和目标策略不是同一策略,行为策略用于产生数据,目标策略则是被评估和提高的策略.而在线策略算法则是行为与目标策略一致.本文提出一个仅利用在线数据基于强化学习的离线策略的数据驱动方法,用于求解离散时间部分线性系统的最优输出调节问题.由于本文系统的模型参数是未知的,首先求解动态规划问题求得最优反馈增益,然后基于动态规划问题的解,本文提出一种数据驱动方法,在无法获取系统模型参数的情况下在线求解静态规划问题的解.
2.1 数据驱动求解动态优化问题

写出k+1 时刻的值函数减去k时刻的值函数,将式(32)代入,可得:

为将上式的数据与矩阵参数进行分离,将式(34)各项用克罗内克积和矩阵的拉直运算进行表示,即根据aTWb=(aT⊗bT)vec(W),可得上式对应的各式可以等价的表示如下:
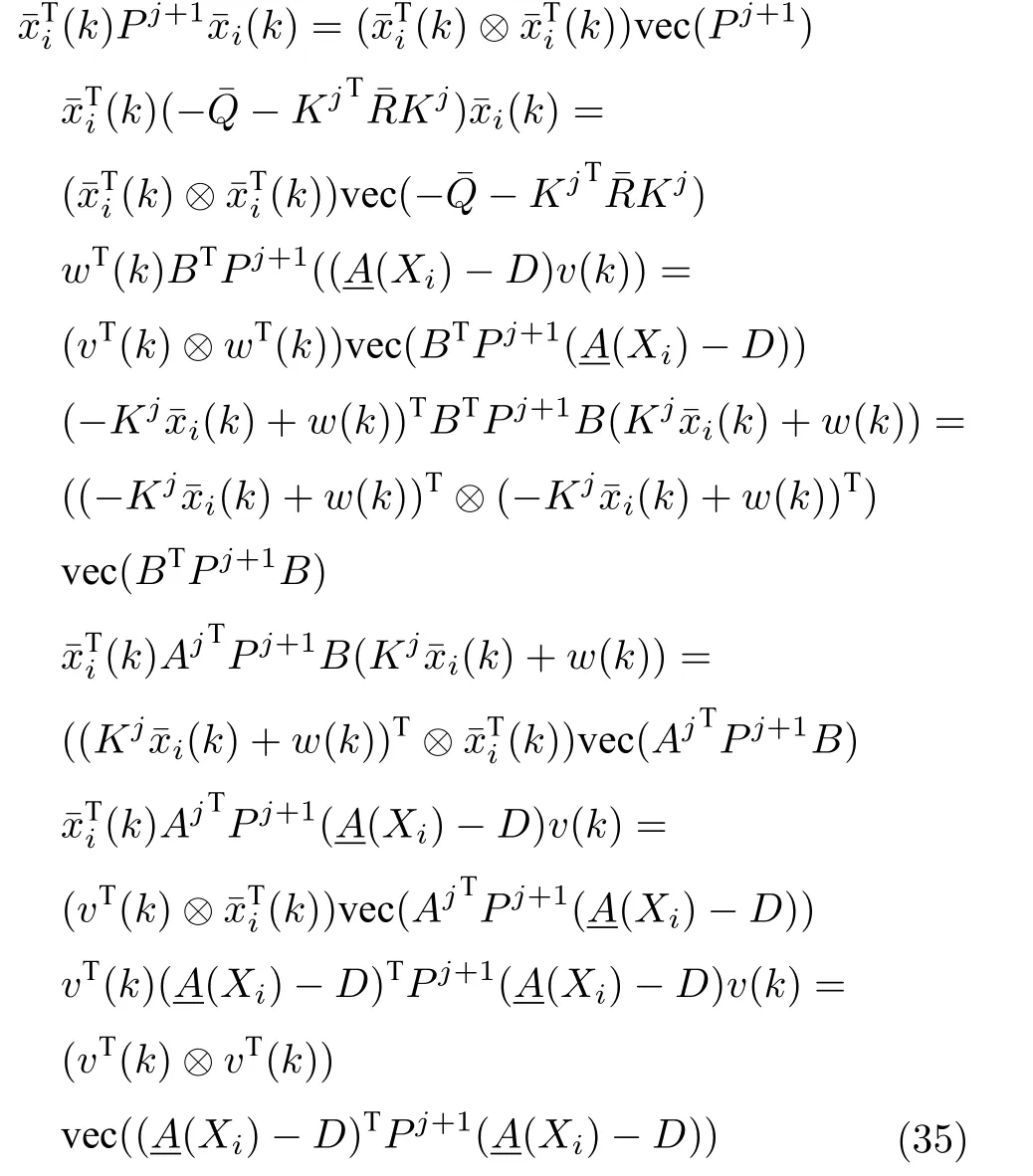
因此,式(34)可以用式(35)的形式表示为:
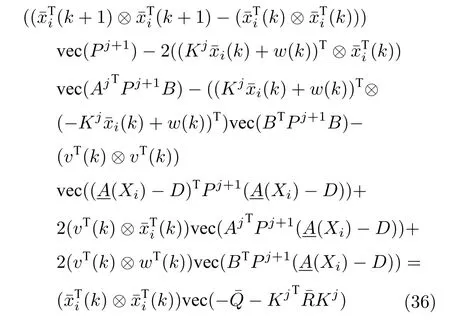
为了对参数矩阵进行学习,将式(36) 写成式(41)的形式,则需定义待求的参数矩阵如式(37)和数据组(38)和(39)如下,式(38)收集的是式(36)中等式右边的t组数据组成数据向量式(39)收集的是式(36)中等式左边的t组数据组成数据矩阵


2.2 数据驱动求解静态优化问题
前面已经介绍了当模型参数已知时,受约束的静态规划问题应如何求解,并将原静态规划问题1的形式重新改写.在此基础上,下面提出数据驱动的拉格朗日乘子法来求解式(20)这个受约束的静态规划问题.该方法无需知道系统的模型参数,仅使用测量的数据.

为避免需要知道系统准确的模型参数,根据动态规划问题的解来求得静态规划问题的解.通过解动态规划问题可以求得定义如下:
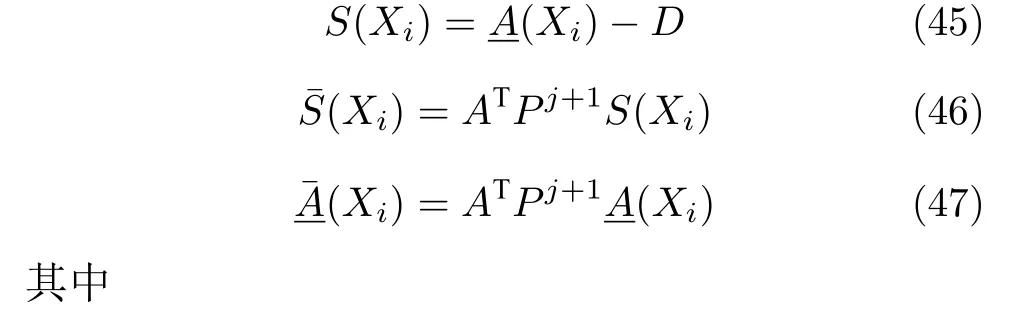
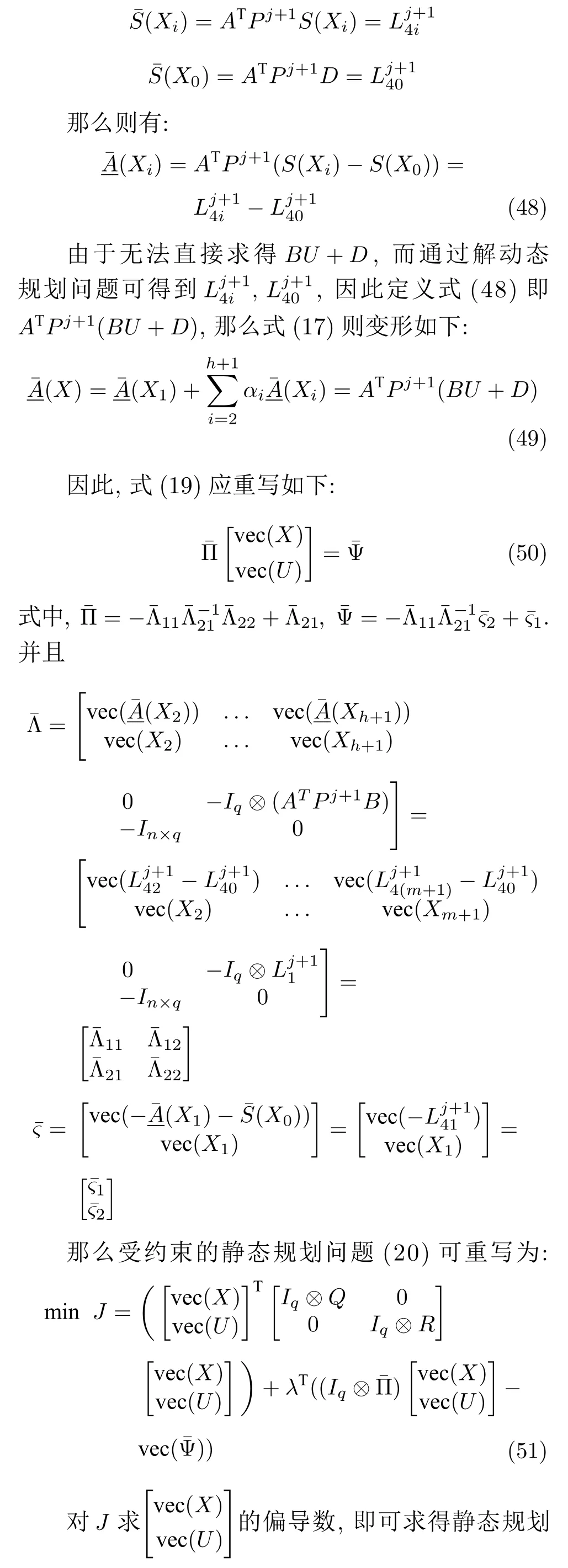

3 仿真实验
本节首先建立一个仿真实验,来说明本文方法的有效性;然后进行对比实验,用本文方法与对比方法进行仿真实验,用评价指标结果说明本文方法的优越性.
3.1 仿真实验参数选择
考虑下面这个离散时间的部分线性系统:

3.2 仿真结果
在仿真实验中,算法2 经过迭代学习4 次收敛,得到Pj+1=[35.8976 0.7433;0.7433 4.0401] 和增益Kj+1=[-0.3475 0.9987].学到最优增益后找调节器方程最优解为X=[4.281×10-17-1;-1.139-2.997]和U=[0.6888 1.9995].从而得到L=[-0.4486-0.6461].
仿真结果见图1~ 5.图1 给出了算法2 的系统输出、参考输入和跟踪误差,图2 给出了控制输入.由图1 可知,鲁棒最优输出调节控制器在由如图3 系统干扰和存在非线性不确定的情况下,仍可使得y(k) 跟踪参考输入r(k).图4 给出了在学习阶段P和K收敛到最优值的收敛情况,由图4 可知,通过4 次的迭代学习就可以求出最优的P和K.图5给出了误差系统的状态,图5 说明了误差系统在原点处是全局渐近稳定的,同时也表明闭环系统的稳定性.在仿真结果中,跟踪误差从100 步之后明显减小;从第120 步起,跟踪误差的最大数量级为10-9,控制输入中存在的动态非线性不确定性的大小从第10 步起的最大数量级为 1 0-9,说明跟踪效果好,且对于动态的非线性不确定性有良好的鲁棒性.仿真结果表明,本文算法在模型参数未知、存在干扰和输入中存在非线性不确定情况下,只利用系统数据,就可以实现具有鲁棒性的最优输出调节控制.
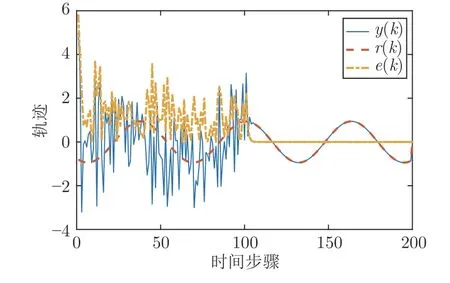
图1 系统输出与参考轨迹及跟踪误差Fig.1 Trajectories of system output and reference and tracking error
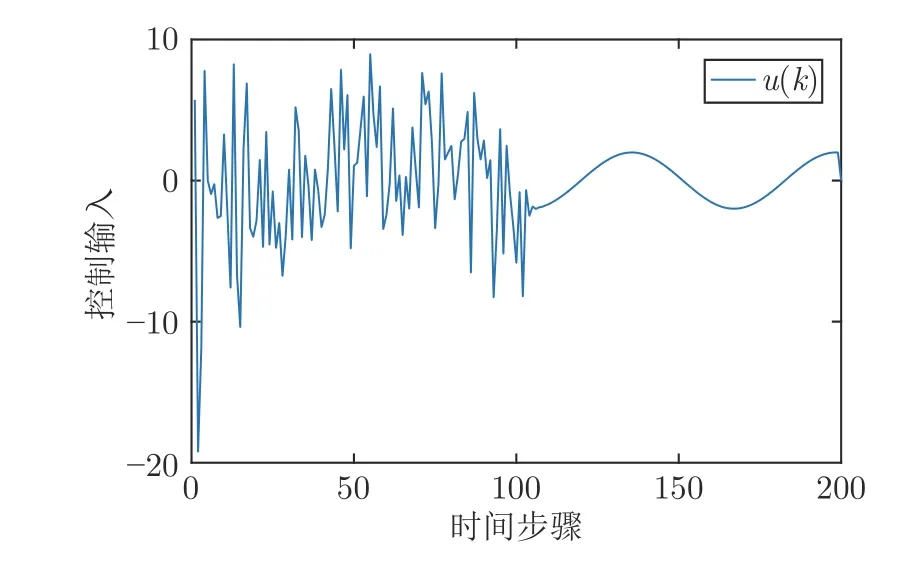
图2 控制输入轨迹Fig.2 The control input trajectory
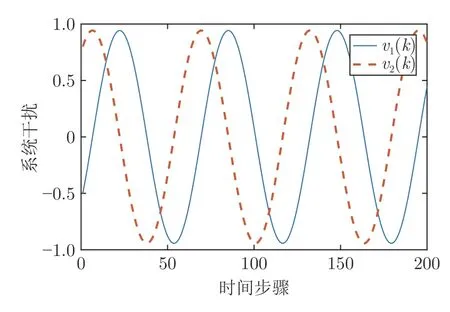
图3 系统干扰Fig.3 The disturbance of system
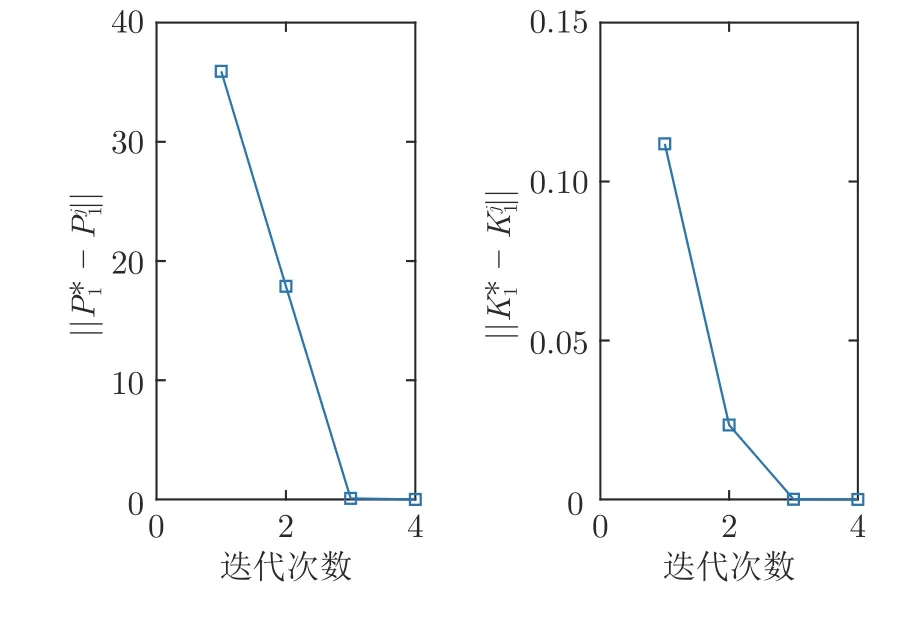
图4 学习阶段 P 和 K 的收敛情况Fig.4 The convergence of P ,K during learning phase
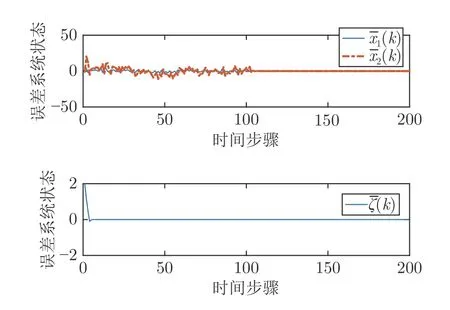
图5 误差系统状态轨迹Fig.5 The error system state trajectory
3.3 对比实验
对比实验1 采用本文提出的鲁棒最优输出调节的方法来跟踪参考信号,且满足本文的假设条件.对比实验2 是文献[12]的方法,在模型参数未知时采用Q-学习的方法解决线性最优二次跟踪问题来跟踪参考信号.2 个对比实验的未知模型参数和参考信号相同,不同的是对比实验1 还在控制输入中加入了非线性不确定性.对比实验仿真结果见图6~ 7.
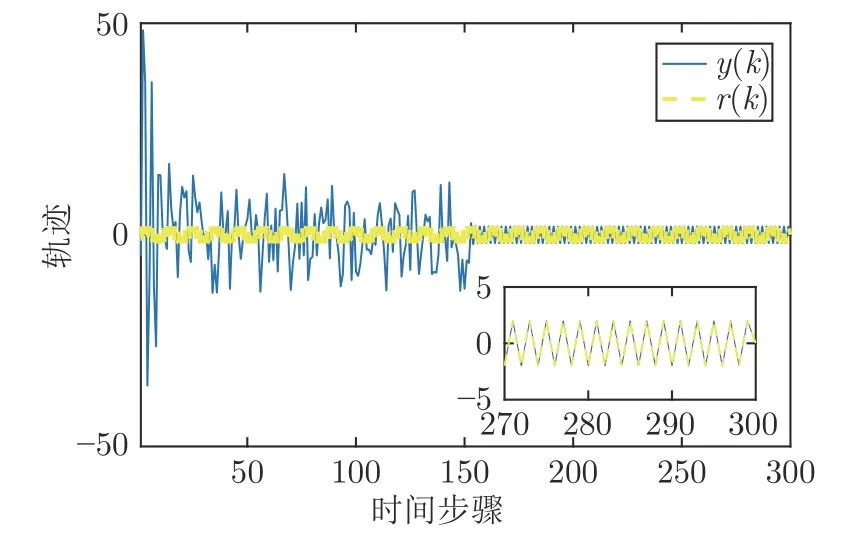
图6 对比实验1 仿真结果图Fig.6 The result of comparison experiment 1
对比实验1 模型为:

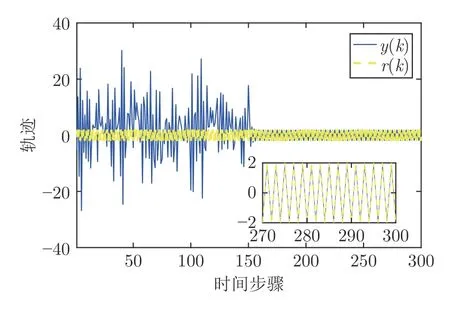
图7 对比实验2 仿真结果图Fig.7 The result of comparison experiment 2
本文用绝对误差积分(Integral absolute error,IAE) 和均方根误差(Root mean square error,RMSE)两个指标[18,26-29]来评价本仿真实验的控制效果,结果见表1.
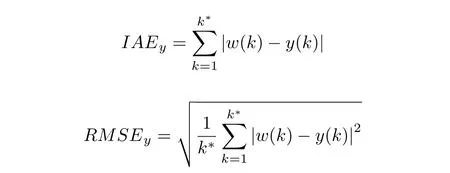

表1 对比实验评价指标Table 1 Performance index of comparison experiment
由图6~ 7 可知,对比实验1 和2 都能较好地跟踪设定值.对比实验1 相较于对比实验2 还增加了非线性不确定性,又从表1 可知,对比实验1 的跟踪性能指标较对比实验2 更好,这也说明了本文提出算法的优越性.
4 结束语
本文提出一个基于强化学习的数据驱动算法,用于解具有未知模型参数的离散时间部分线性系统的最优输出调节问题.首先将原系统的输出调节问题的可解性转化为误差系统的全局渐近稳定问题,给出了原问题的可解性说明;然后在未知系统模型参数的条件下,利用在线数据利用基于强化学习的数据驱动的离线策略算法求解最优反馈控制律,并给出该算法的收敛性说明.该控制律可以完成系统的干扰抑制和渐近跟踪且对于系统中存在的非线性不确定性存在鲁棒性.仿真结果验证了本文方法的有效性,通过对比实验和性能指标的比较,说明了本文所提方法的优越性.与跟踪问题相比,本文方法不仅可以实现跟踪,当系统本身存在干扰时,同时可以抑制干扰达到闭环系统的稳定性.本文方法与完全线性系统的输出调节问题相比,对输入中存在的动态非线性不确定性存在鲁棒性.本文将数据驱动的强化学习方法和小增益原理进行结合,该方法可实现鲁棒强化学习,从而也为更多控制问题的解决提供了思路.
