基于特征融合注意网络的图像超分辨率重建
2022-09-30周登文马路遥田金月孙秀秀
周登文 马路遥 田金月 孙秀秀
近年来,单图像超分辨率(Single image superresolution,SISR)技术是图像处理和计算机视觉领域的研究热点,旨在由单幅低分辨率(Low-resolution,LR) 图像重建出具有更多细节的高分辨率(High-resolution,HR)图像,它在医学成像[1]、遥感卫星成像[2]和视频监控[3]等领域有广泛的应用.
超分辨率技术可大致分为3 类: 基于插值[4-5]、基于重建[6-7]和基于学习[8-13]的方法.其中,基于学习的超分辨率算法是目前的主流研究方向.2014 年,Dong 等[8]提出了基于深度卷积神经网络(Convolutional neural network,CNN)的SISR 算法,称为SRCNN.不同于传统的基于学习的方法,SRCNN直接学习低分辨率(LR)和高分辨率(HR)图像之间端到端的映射.该网络结构虽然简单(只有3 层),但是,超分辨效果很好.2016 年,Dong 等[9]在SRCNN 的基础上,进一步提出了基于沙漏型结构的FSRCNN 方法.该方法参数量和计算量都更小,速度也更快.Kim 等[10]利用残差网络(ResNet)[14],加深了网络结构(20 层),提出了使用很深CNN 的SISR方法VDSR (Verp deep super-resolution),取得了更好的效果.Tai 等[11]提出了深度递归残差SISR网络DRRN (Deep recursive residual network),采用了更深的网络结构.受益于参数共享策略,相比VDSR 方法,参数量更少,效果更好.2017 年,Lai等[12-13]提出了基于拉普拉斯图像金字塔的深度残差网络LapSRN (Laplacian super-resolution network).LapSRN 网络模型包含多级,每一级完成一次2 倍上采样操作.通过逐级上采样和预测残差,实现图像超分辨率重建.一次训练模型,可以完成多个尺度的超分辨率任务.我们的方法,主要是受到LapSRN 方法的启发.
VDSR、DRRN 和LapSRN 等方法都表明: 网络深度对于超分辨率图像重建质量有着至关重要的影响.以前基于深度CNN 的超分辨率方法,大多依赖于简单地叠加卷积层,构建更深的网络,以获得性能的改进.但是,这会导致对内存和计算能力需求的快速增加.
随着网络深度的增加,感受野会不断增大,各网络层提取的特征逐步抽象.本文认为: 网络模型不同深度提取的特征,均包含不同的、有利于超分辨率重建的信息,以前的方法大多忽略了如何充分利用这些信息.此外,超分辨率重建的重点是恢复图像边缘和纹理等高频细节,之前的方法通常对提取出来的特征信息同等对待,没有重点关注图像边缘和纹理等细节.
近年来,视觉注意机制[15]在图像分类和超分辨率等应用中取得了成功[16-19],它可以重点关注感兴趣的目标,抑制无用的信息.为了解决上述问题,本文提出了基于特征融合注意网络的超分辨率重建方法,本文的贡献主要包括: 1) 提出了多级特征融合的网络结构,能够更好地利用网络不同深度的特征信息,以及增加跨通道的学习能力;2) 提出了特征注意网络结构,能够增强图像边缘和纹理等高频信息.实验结果表明: 本文提出的基于特征融合注意网络的图像超分辨率方法,无论是主观视觉效果,还是客观度量,超分辨率性能均超越了其他代表性的方法.
1 本文方法
本文方法主要是受到LapSRN 方法的启发,为了便于介绍本文方法,首先对LapSRN 方法作一个简单的介绍.两级LapSRN 网络分为两级超分辨率子网络(每级11 个卷积层),每一级超分辨率子网络包含基于CNN 的特征提取和反卷积上采样2 个部分,以实现2 倍放大因子的超分辨率重建.LapSRN方法的两级超分辨率子网络,可同时重建 ×2 和×4倍超分辨率图像.
LapSRN 超分辨率子网络的结构较为简单,只是常规3×3 的卷积层的堆叠.本文特征融合注意网络模型的总体架构类似于LapSRN,也由超分辨率子网络组成,参见图1.但是,在每一级子网络的内部,有重要的改进.本文模型的每一级子网络包括3 个部分: 特征融合子网络、特征注意子网络和图像重建子网络(2 倍反卷积上采样),参见图2.特征融合子网络由维度转换层、递归卷积块、多通道融合层,以及全局特征融合层4 个部分组成.递归卷积块提取的不同深度特征,通过多通道融合层,传递到全局特征融合层,充分利用不同深度的特征信息和跨通道融合,以自适应地学习跨通道特征信息之间的相互关系,增强网络特征信息的选择能力.特征注意子网络将特征融合子网络输出的特征,进行高频信息的着重处理,以增强特征中边缘和纹理等细节信息.图像重建子网络则使用反卷积上采样层,生成2 倍超分辨率图像.本文的特征融合子网络中包含8 个递归卷积块,每个卷积块包含5 个3×3 的卷积层.由于采用了递归结构,各卷积块之间参数共享,以及两级超分辨率子网络之间其他参数的共享.虽然本文的网络模型有80 个卷积层,但参数总量大约只有LapSRN 方法的3/8.下面对网络模型的主要部分进行详细的介绍.
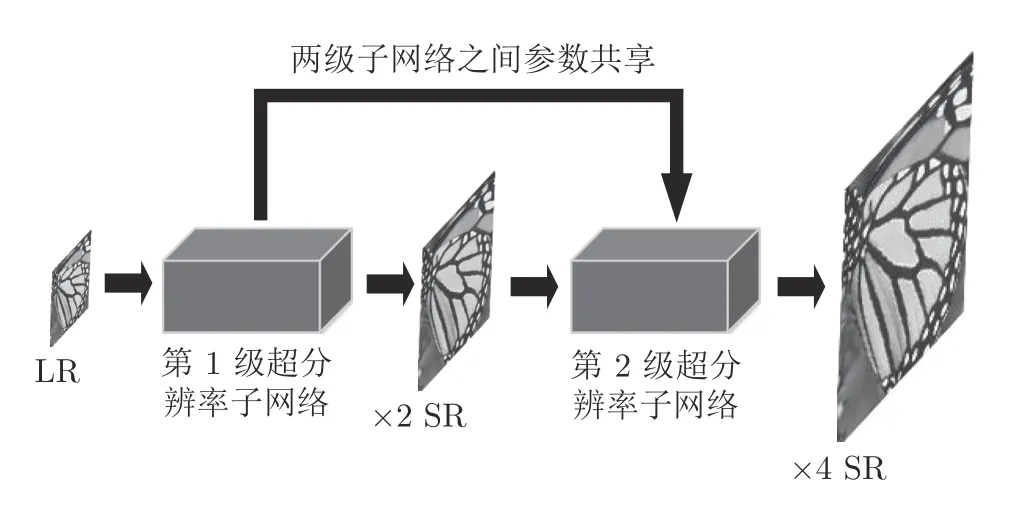
图1 网络模型的总体结构Fig.1 Overall structure of network model
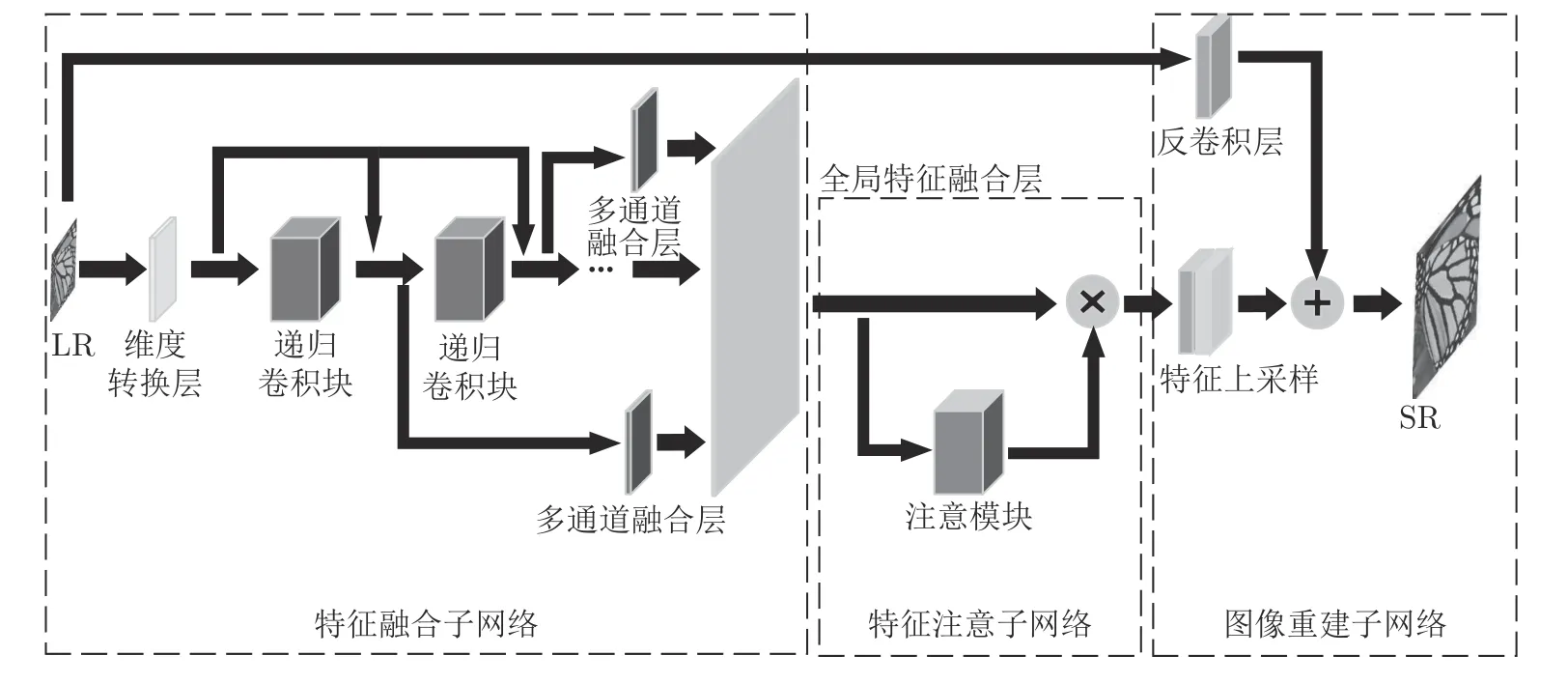
图2 超分辨率子网络内部结构Fig.2 Internal structure of super-resolution subnetwork
1.1 特征融合子网络
本文的特征融合子网络由维度转换层、递归卷积块、多通道融合层,以及全局特征融合层4 个部分组成.维度转换层为一个3×3 的卷积层,将输入的LR 图像转换到高维特征,并过滤掉一部分低频信息
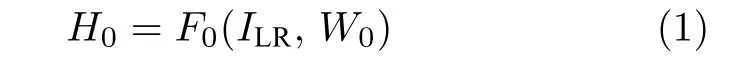
其中,ILR是输入的LR 图像,F0是维度转换层的映射函数,W0是F0的权重矩阵参数,H0是F0的输出特征.H0输入到8 个顺序连接的递归卷积块,每个卷积块包含5 个的卷积层,参见图3.递归卷积块对H0进一步进行特征提取
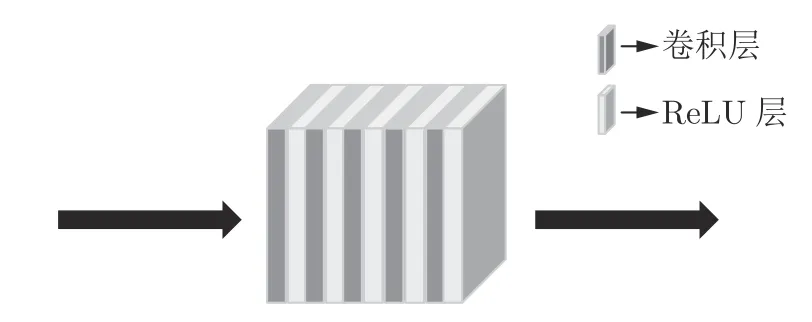
图3 递归卷积块的结构Fig.3 Structure of recursive convolutional block

其中,Fi是第i个递归卷积块的映射函数,Wi是Fi的权重矩阵参数,Hi是第i个递归卷积块的输出.
多通道融合层包含8 个1×1 的卷积层,分别对8 个递归卷积块的输出特征Hi,i=1,2,···,8,进行多通道融合和联通
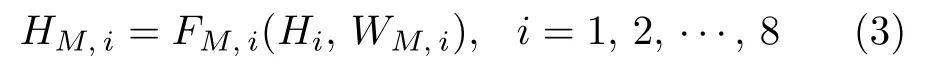
其中,FM,i是第i个多通道融合层的映射函数,WM,i是FM,i的权重矩阵参数,HM,i是第i个多通道融合层的输出特征.
全局特征融合层将多通道融合层的输出特征HM,i进行拼接,生成特征HM,再通过2 个1×1 的卷积层,进一步融合和降维,以提高不同深度特征的利用率
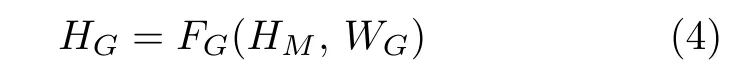
其中,FG是全局特征融合层的映射函数,WG是FG的权重矩阵参数,HG是全局特征融合层的输出.
多通道融合层和全局特征融合层的相互结合,使得本文的网络模型能够联通不同深度、不同通道特征,以更好地学习特征之间的相互关系.
1.2 特征注意子网络
注意力机制旨在将更多的注意力集中在感兴趣的信息上.在图像超分辨率重建中,我们更感兴趣图像的高频信息,即图像的边缘和纹理等信息.合适的网络结构是实现注意机制的关键.本文的特征注意子网络包含一个注意模块,由7×7 的最大池化层、三个3×3 的卷积层和一个S 形(sigmoid)非线性激活层组成,参见图4.7×7 的大感受野最大池化层,可以更多地保留特征的纹理信息,过滤一部分平滑的低频信息.S 形非线性激活函数的输出限制在0 到1 之间,减少对特征信息的扰动,并能够进一步抑制不重要的信息.特征注意子网络得到一个与输入特征尺寸相同的增强矩阵A,A与输入特征(即特征融合子网络的输出)HG逐元素相乘,对HG进行信息增强
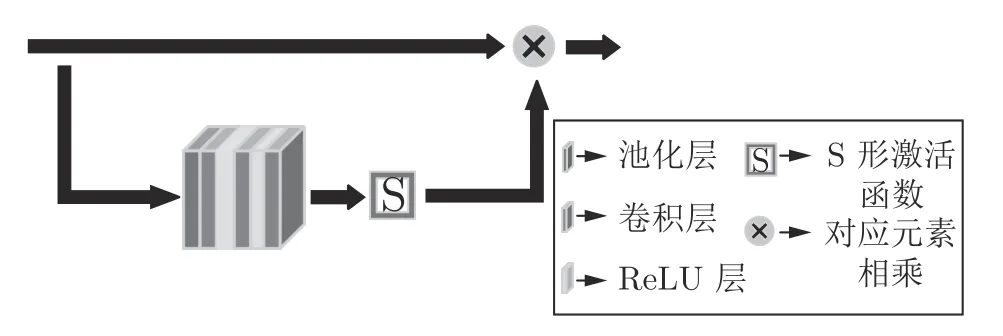
图4 特征注意子网络结构Fig.4 Structure of feature attention network
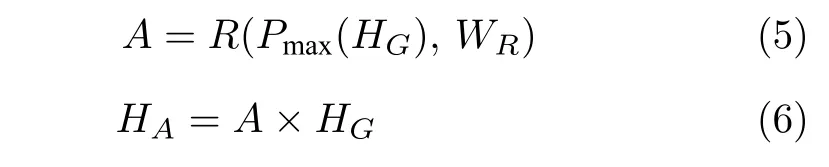
其中,A是注意模块的输出,R是注意模块中卷积块待学习的映射函数,WR是R的权重矩阵参数,Pmax是最大池化层函数,HA是增强后的特征,(·)是逐元素相乘运算.
1.3 图像重建子网络
我们使用与LapSRN 方法类似的图像重建子网络,在每一级超分辨率子网络的末端进行一次2倍超分辨率重建.将运用注意力机制增强后的特征HA和LR 图像分别进行反卷积上采样,并逐元素相加,生成重建的2 倍超分辨率图像
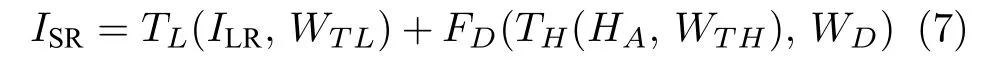
其中,ISR是重建的超分辨率图像,ILR是输入的LR图像,TL是LR 图像上采样反卷积层待学习的映射函数,WTL是TL的权重矩阵参数,TH是特征HA上采样反卷积层待学习的映射函数,WTH是TH的权重矩阵参数,D为降维卷积的映射函数,WD是D的权重矩阵参数.
1.4 跳跃连接
残差网络在计算机视觉任务中应用广泛,其跳跃连接通常源自前一层的输出.在特征融合子网络中,采用了同源跳跃连接结构,如图5 所示.该结构将维度转换层的输出H0传递到每个递归卷积块的输入中,每个递归卷积块的输入是上一个块的输出与H0的和.这样可以向网络深层传递更多的浅层特征信息,也可以有效地减轻梯度消失和爆炸问题.
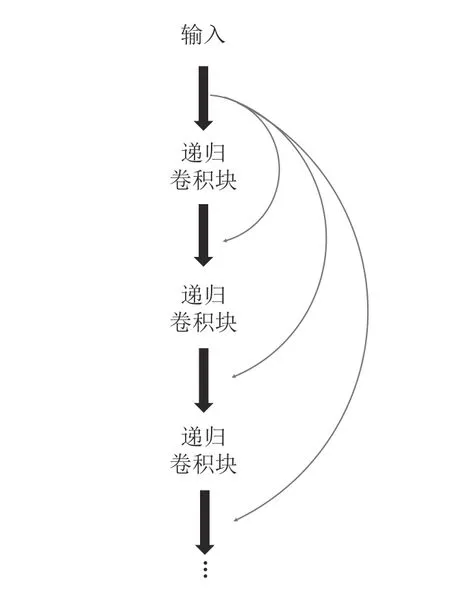
图5 跳跃连接结构Fig.5 Structure of skip link
1.5 损失函数
本文采用了与LapSRN 相同的L1 损失函数[13]
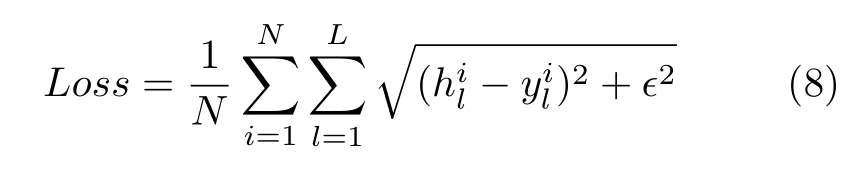
其中,N为每个训练批次的图像数量,L为整个网络包含的子网络数.为高分辨率图像,为对应的重建图像,ε设置为 1 0-6.
2 实验结果
2.1 训练和测试数据集
不同的基于学习的SISR 方法,使用不同的训练集.SRCNN 方法使用ImageNet 训练集[8],FSRCNN 方法使用General-100 训练集[9],Yang 等[20]使用91 幅训练图像.LapSRN 方法使用Berkeley Segmentation Dataset[21]中的200 幅图像,以及Yang 等[20]方法中的 91 幅图像,共291 幅图像作为训练集,并通过缩放、旋转等方式,扩充了训练集.由于本文的方法与LapSRN 方法的网络模型总体架构类似,因此也采用了与其相同的训练数据集和训练集增扩方法.
本文使用了Set5[22]、Set14[23]和BSD100[24]标准测试数据集,分别包含5、14 和100 个高分辨率(HR)原图像.
2.2 训练数据集预处理和训练参数设置
本文使用不同的下采样因子,下采样原高分辨率(HR)训练图像,获得对应的低分辨率(LR)图像,并且通过缩放和旋转增扩了训练图像: 首先,对训练图像以0.5 和0.7 的比例进行缩放;接着,对所有训练图像进行[ 9 0°,1 80°,2 70°]的旋转.所有训练图像都裁剪为96×96 的图像片(块),LR 和HR训练图像片对共123 384 个.本文在DIV2K[25]数据集中随机选取20 幅图像,也进行了增扩处理,获得2 688 个LR 和HR 图像片对,作为验证图像.本文网络模型中每一级超分辨率子网络参数设置可参见表1.其中,H、W是输入的LR 图像的高度和宽度,Conv 是卷积层,LReLU 是渗漏、修正的非线性层,MaxPool 是最大池化层,ConvT 是反卷积层.
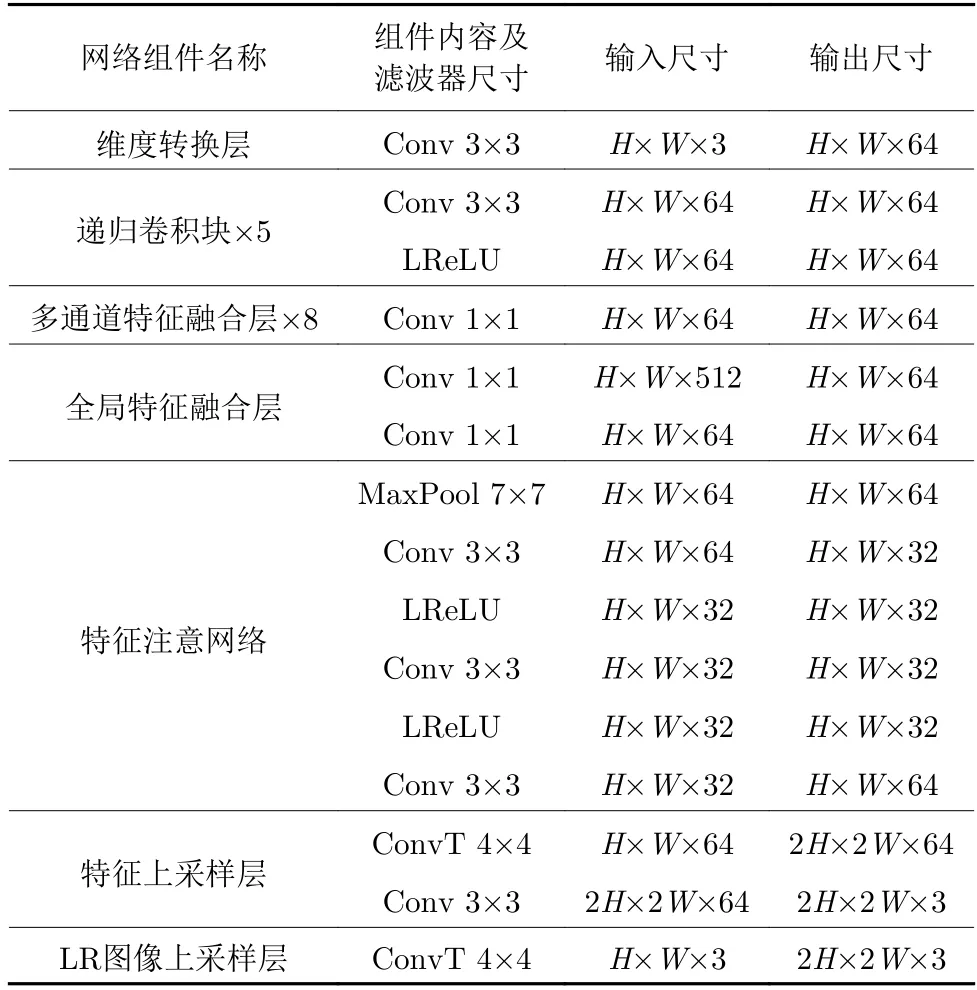
表1 每一级超分辨率子网络的参数设置Table 1 Parameter setting of each level of super-resolution sub-network
网络模型的其他训练参数设置: 每批64 个训练图像对,全部训练图像对共1 928 批,作为一个训练周期(Epoch),共训练100 个周期;训练优化算法: Adam[26];初始学习率: 1 0-4,每迭代20 个周期,学习率衰减一半;卷积滤波器初始化采用MSRA算法[27];反卷积滤波器初始化采用均值为0、标准差为0.001 的高斯分布[9].在Intel Core i7-4790K 4.00 GHz CPU,NVIDIA GTX Titan X GPU (12 GB内存)上,使用PyTorch 1.0 深度学习框架,作为训练平台.
2.3 模型分析
本文在Set5 和Set14 标准测试数据集上进行4 倍超分辨率实验.分析特征融合子网络和特征注意子网络对超分辨率性能的影响,参见表2.我们给出了不同模型变种的平均峰值信噪比(Peak signal to noise ratio,PSNR)[28]和模型参数量.可以看出:递归结构可以在对网络性能影响不大(PSNR最大相差0.01dB)的情况下,有效减少参数量,不使用递归结构,参数量将急剧增加(大约增加到7 倍).特征融合子网络和特征注意子网络均可以提升网络的超分辨率性能,两个子网络并用,效果最好.
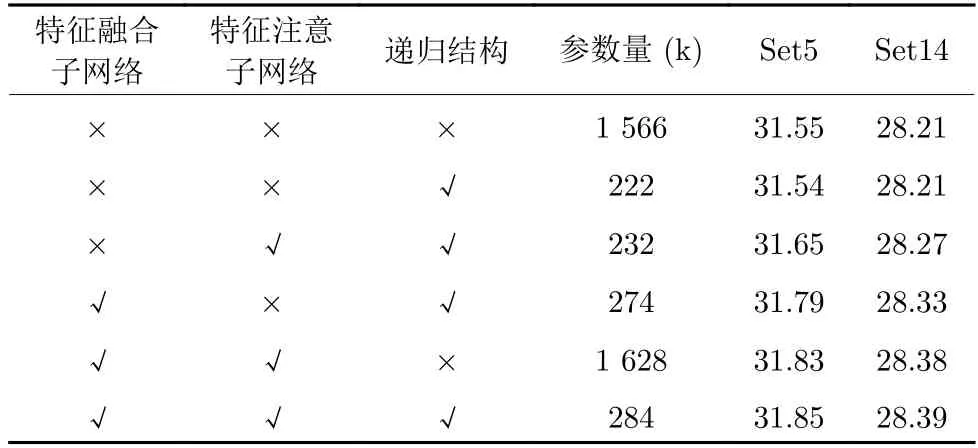
表2 不同变种的网络模型×4 超分辨率,在Set5、Set14数据集上的平均峰值信噪比(dB)及参数量Table 2 Average PSNR (dB) and number of parameters of different super-resolution network models for scale factor ×4,on Set5 and Set14 datasets
本文用NVIDIA Titan X (单卡),训练100 个迭代周期(Epoch),大约需要2 天.网络收敛曲线参见图6,纵坐标是损失值,横坐标是训练迭代周期数.“train loss”是训练损失收敛曲线,“val loss”是验证损失曲线.当训练损失和验证损失趋向于稳定时,停止训练.
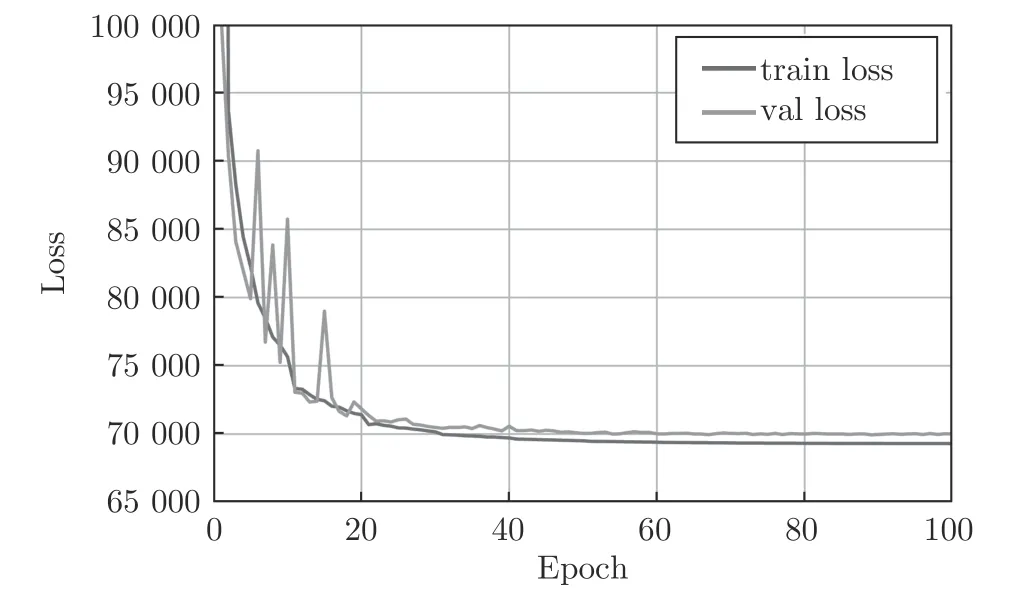
图6 网络收敛曲线 (“train loss” 是训练损失收敛曲线,“val loss” 是验证损失曲线)Fig.6 Network convergence curves (“train loss” is the training loss convergence curve;“val loss” is the validation loss curve)
2.4 实验结果分析
我们在Set5、Set14 和BSD100 标准测试集上,验证2 倍、4 倍和8 倍超分辨率性能.图像质量客观度量标准采用共同使用的PSNR 和结构相似度(Structural similarity,SSIM)[28],PSNR 和SSIM值越大,表示图像质量越高.我们也与一些代表性的SISR 方法进行了比较,包括经典的双三次插值方法Bicubic[29],Huang 等[30]基于自相似的SISR 方法SelfEx,Dong 等[8]使用深度卷积网络的SISR 方法SRCNN,Kim 等[10]使用深度CNN 的SISR 方法VDSR,Tai 等[11]深度递归残差网的SISR 方法DRRN,Lai 等拉普拉斯金字塔网络的SISR 方法LapSRN[12]和Ms-LapSRN[13]等.Bicubic 方法使用MATLAB interp2 函数实现;其他方法的实现均来自作者公开的源代码,使用原方法论文中的参数.2 倍、4 倍模型使用原作者预训练模型,8 倍模型用作者源代码训练得到.计算结果参见表3.
一个已知的事实是: PSNR 和SSIM 等客观度量方法与人的主观视觉并不是完全一致的.本文方法与其他比较的方法,在Set5、Set14 和BSD100测试数据集上部分图像的4 倍超分辨率的视觉效果(参见图7~ 9),图10 是8 倍超分辨率的结果.为了便于观察,对比的结果图像进行了局部裁剪和放大.第1 行和第3 行是选择的裁剪区域,第2 行和第4行是对红色方框中重点区域的放大.各个比较的方法标注在图像的下方.本文方法的超分辨结果明显优于其他比较的方法,更好地恢复了图像的边缘和纹理等细节,是清晰可视的.尤其是图8 中花瓶的纹理和鱼的眼睛,图7 中的文字和马腿部花纹.
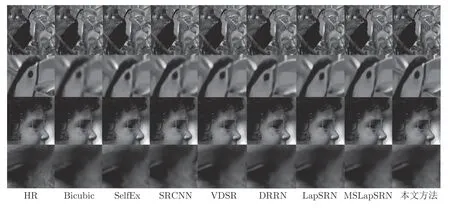
图7 在Set5 测试数据集上,2 个测试图像×4 超分辨率结果对比Fig.7 A comparison of super-resolution results of two test images in Set5 for scale factor ×4

图8 在Set14 测试数据集上,2 个测试图像×4 超分辨率结果对比Fig.8 A comparison of super-resolution results of two test images in Set14 for scale factor ×4
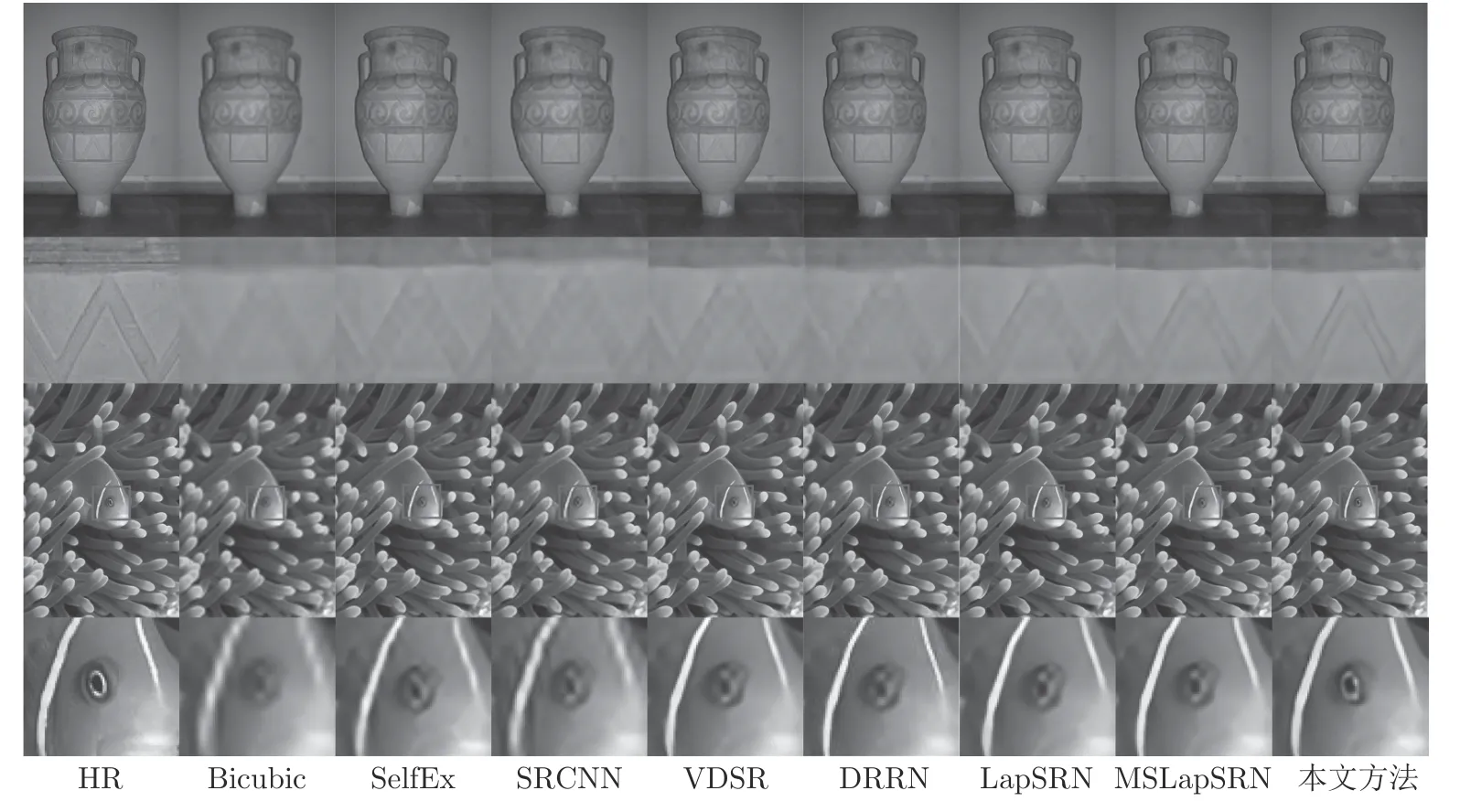
图9 在BSD100 测试数据集上,2 个测试图像×4 超分辨率结果对比Fig.9 A comparison of super-resolution results of two test images in BSD100 for scale factor ×4

图10 在BSD100 测试数据集上,2 个测试图像×8 超分辨率结果对比Fig.10 A comparison of super-resolution results of two test images in BSD100 for scale factor ×8
基于深度CNN 的6 个SISR 方法在BSD100测试数据集上,4 倍超分辨率的平均PSNR 和参数量的对比,参见图11.SRCNN 的网络模型只有3 层,故参数量最小,但是其PSNR 性能最低;本文方法的平均PSNR 最高,参数量却大约只有LapSRN的1/3,与DRRN 和Ms-LapSRN 方法,大致相当.
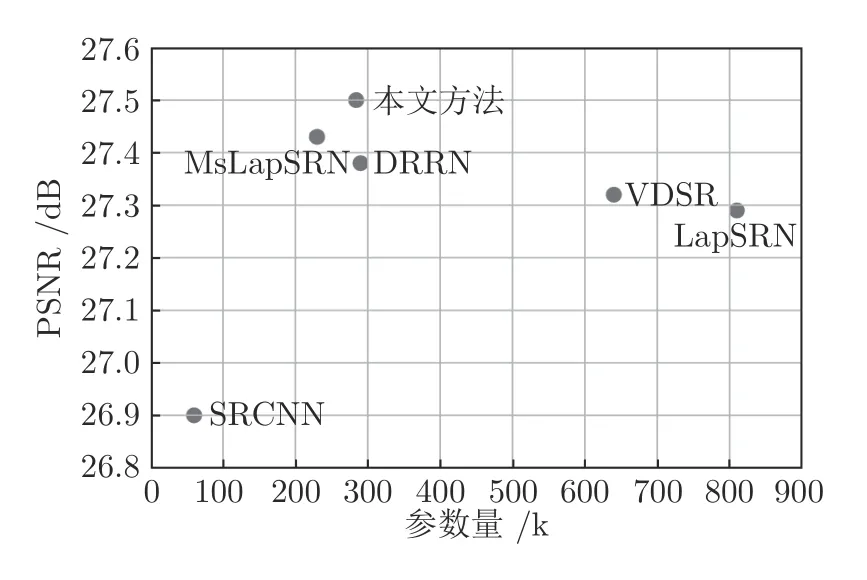
图11 6 个基于深度CNN 的方法,在BSD100 数据集上×4 超分辨率的平均PSNR 和参数量对比Fig.11 Number of parameters and average PSNR of six methods based on depth CNN,on the BSD100 for scale factor ×4
基于深度CNN 的6 个SISR 方法在BSD100测试数据集上,4 倍超分辨率的平均运行时间对比,参见图12.本文方法的速度略低于LapSRN、Ms-LapSRN 和SRCNN,但明显快于VDSR 与DRRN方法.LapSRN 方法最快,比本文方法也仅快大约0.06 s,本文方法比VDSR 大约快0.1 s,比DRRN大约快0.8 s.
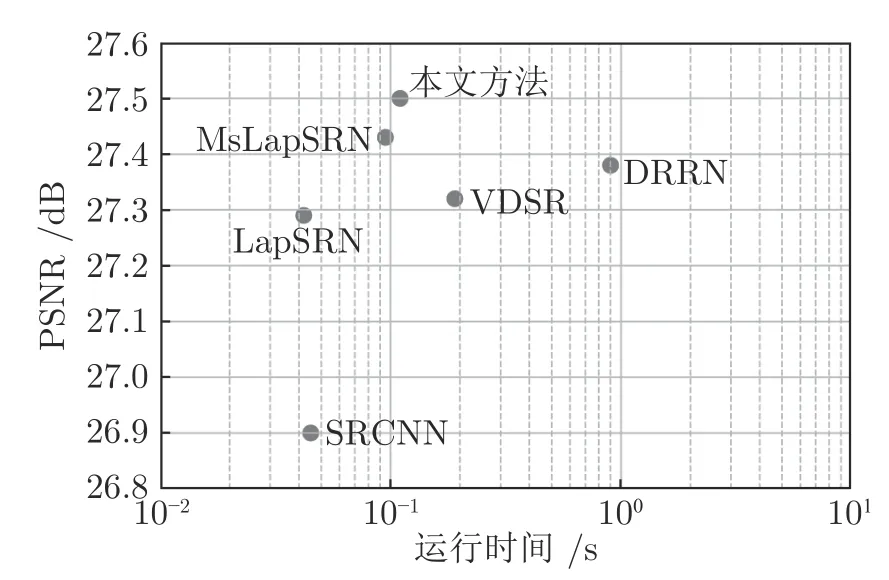
图12 6 个基于深度CNN 的方法,在BSD100 数据集上×4 超分辨率的平均运行时间对比Fig.12 A comparison of running times of six methods based on depth CNN,on the BSD100 for scale factor ×4
3 结束语
针对之前基于深度CNN 的SISR 方法中参数量大,图像边缘和纹理恢复效果不好等问题,受基于拉普拉斯图像金字塔的深度残差网络方法(LapSRN)的启发,提出了基于特征融合注意网络的超分辨率重建方法.我们保留了LapSRN 方法分级重建的优点,采用了递归和其他参数共享策略,使参数量急剧下降,大约只有LapSRN 方法的3/8.由于采用了多级特征融合和特征注意机制,使得本文的网络模型,能够充分融合和利用不同深度、不同通道的特征,重点增强边缘和纹理等高频信息,超分辨率效果显著提升.实验结果也证实了本文方法的良好性能,在进行比较的代表性方法中,本文方法更好地平衡了性能、模型的复杂度和运行时间等因素.未来我们将计划进一步优化和改进我们的方法.
