基于Shapley 值的陕西省粮食产量预测
2022-09-08谢玉莹
◎ 谢玉莹
(西安财经大学 统计学院,陕西 西安 710100)
粮食不仅影响区域农业经济的发展,而且与国计民生息息相关。在每年的政府报告中,国家对不同区域的粮食产量都有明确的要求,在2022 年的中央一号文件中更是把确保我国粮食安全作为底线任务之一。从生产的角度来看,粮食供给是基础,粮食产量则是保障供给的前提。陕西省作为西北地区经济中心,随着经济的快速增长,常住人口数量逐年增加,而粮食产量的增长却不容乐观。因此,对陕西省粮食产量的预测研究能为陕西省粮食安全问题提供数据支持,进而保障陕西省区域粮食产量安全,从而更好地满足人们生活的基本需求。
目前,有部分学者基于单一预测模型对粮食产量进行预测研究,如胡雪冰等[1]通过灰色模型对四川粮食产量和消费进行了预测,并根据产需平衡状况对四川省粮食安全进行了相应分析。周永生等[2]建立了多元回归模型,对广西壮族自治区粮食产量进行拟合预测并提出了相关建议,以确保广西壮族自治区未来粮食产量的稳定发展。还有一些学者,基于组合模型对粮食产量进行预测,如姚作芳等[3]将灰色预测模型、灰色马尔科夫预测模型及逻辑斯蒂预测模型加以组合,采用最优加权方法确定权重,建立了东北地区粮食产量预测模型。游文倩等[4]基于IOWA 算子将ARIMA模型、三参数指数平滑法和多元线性回归模型进行组合,利用误差平方和最小法确定权重,建立了我国粮食产量预测模型。通过对上述文献分析可知,鲜有学者从博弈论的角度对粮食产量进行组合预测。因此,本文从博弈论的角度,采用合作博弈论Shapley 值利益分配理论,并依据GM(1,1)模型、主成分回归模型和Holt两参数指数平滑法模型的预测平均误差平方和建立线性组合模型对陕西省粮食产量进行拟合预测。
1 数据来源及指标选取
1.1 数据来源
本文从自然条件、科学技术、农业投入和社会经济方面对粮食产量进行研究。研究所使用的粮食产量、粮食播种面积、成灾面积、农村用电量、农业机械总动力、农用化肥使用量、农用柴油使用量、农用塑料薄膜使用量、农业生产资料价格指数和有效灌溉面积等数据来源于2001—2020 年《陕西统计年鉴》[5]。
1.2 指标选取
为避免与粮食产量相关性较小的影响因素在预测时对结果产生干扰,导致预测精度下降。本文采用灰色关联度法对影响因素进行分析,并以此为依据对影响因素进行筛选,剔除关联度较低的因素,主要步骤如下。①确定比较序列和参考序列。本文以陕西省粮食产量Y为参考序列,粮食播种面积和成灾面积等相关影响因素X为比较序列。②采用初值法对数据进行无量纲化处理。③计算差序列。④计算极差。⑤计算灰色关联系数。其中,ρ是分辨系数,本文取为0.5。⑥计算灰色关联度。详细步骤与胡雪冰等[1]相同。
根据计算结果得出2001—2020 年粮食产量及相关影响因素的灰色关联度。由于灰色关联度越大,相关影响因素对粮食产量影响也会越大。因此,依据灰色关联度可得相关影响因素对粮食产量的影响强弱,具体排序为农业生产资料价格指数>有效灌溉面积>农用化肥使用量>粮食播种面积>农用塑料薄膜使用量>农用柴油使用量>农业机械总动力>农村用电量>成灾面积。剔除掉对粮食产量影响程度较小的影响因素,选取农业生产资料价格指数、有效灌溉面积、农用化肥使用量、粮食播种面积、农用塑料薄膜使用量和农用柴油使用量作为预测粮食产量的自变量,设为X01-X06。
2 陕西省粮食产量趋势预测
2.1 GM(1,1)模型预测
灰色系统理论是1982 年由中国学者邓聚龙教授创立的,以“小数据,贫信息”为特点的不确定性系统为研究对象。通常未经处理的数据具有很强的随机性。灰色预测是灰色理论中重要分支,具有样本需求量小等优点。其中,GM(1,1)是常见的单变量灰色预测模型,可以对中长期且平稳的数据进行有效预测。主要步骤如下。①根据2001—2020 年陕西省粮食产量数据,建立原始序列数据再进行累加,从而建立累加序列并进行邻均值序列生成。②根据上述生成的原始序列和邻均值序列建立基本方程,并通过最小二乘法求解出发展灰数a和内生控制灰数b。③建立白化微分方程。④代入a和b解出预测方程。详细步骤与姚作芳等[3]相同。
根据2001—2020 年陕西省粮食产量数据,通过matlab 软件得解出发展灰数a=-0.013 0 和内生控制灰数b=1 001.7,得出预测模型为
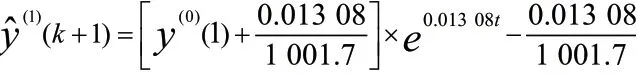
同时,得出模型的后验差c=残差序列标准差/原始序列标准差=0.399 3,小误差概率p=p{|e(k)-e-|< 0.674 5×原始序列标准差}=0.9,并对比精度检验表 (表1),证明了构建的灰色预测模型精度较高,适合对陕西省粮食产量进行拟合预测。

表1 精度检验表
2.2 主成分回归模型预测
在预测分析时,如果影响因素与预测对象之间相关关系大致呈线性且通过多重共线性诊断,VIF>10(即存在严重共线性),可以先采用主成分分析对数据进行降维,把原本互有关系的指标通过正交变换的办法,化为互不相关的几个综合指标,然后再进行回归分析和预测。主要步骤如下。①将2001—2020 年陕西省粮食总产量及筛选后的相关影响因素的数据进行标准化并进行多重共线性检验,本文中多项指标VIF>10,存在显著的共线性。②通过主成分分析进行降维,先进行适用度检验。通过适应度检验后,计算主成分,得出主因子。其中,适用度检验是指Bartlett 球形度检验的显著性水平小于0.001,KMO大于0.5,本文的显著性水平小于0.001,且KMO为0.687,因此适合进行主成分分析。主成分是依据特征值大于1 和累计贡献率达到80%以上的原则进行选择。根据SPSS 软件计算结果,本文选择两个主成分。第一个主成分的特征值为3.913,第二个特征值为1.013,两者累计贡献率为82.097%,符合选取原则。③将主因子带入回归模型并进行逆标准化还原,得出主成分回归预测模型。详细步骤与董京铭等[6]相同。使用SPSS软件通过带入2001 年到2020 年陕西省粮食总产量及筛选后的相关影响因素得出回归方程:
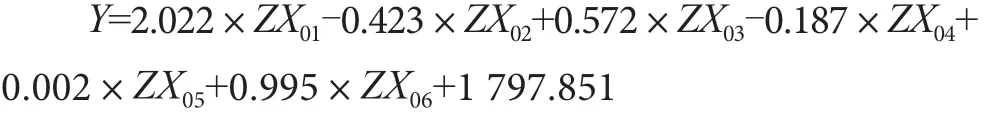
2.3 Holt 两参数指数平滑法预测模型
指数平滑法是基于统计学家Warren Persons 因素分解思想衍生出的一种时间序列预测模型,其基本思想是通过计算原始数据的平滑值,进而通过建立预测模型对数据进行预测。根据序列的发展变化趋势,一般可将指数平滑法模型分为3 类。①无长期趋势、无季节效应使用简单指数平滑法。②有长期趋势、无季节效应使Holt 两参数指数平滑法。③长期趋势可有可无,但一定有季节效应使用Holt-Winters 三参数指数平滑法。经过对2001—2020 年陕西省粮食产量的发展变化分析,得出陕西省粮食产量是属于有趋势、无明显季节效应。因此,本文采用Holt 两参数指数平滑法,通过不同参数,直接对趋势进行平滑处理。公式为

式中:Pt是调整后的平滑值;α和β是调整模型的两个参数;是l期后的预测值。
根据2001 年到2020 年陕西省粮食产量数据,通过R软件计算调整模型的参数,α=0.668 357和β=0.124 461 4,得出预测模型=1 264.889 72+13.413 21×l。
2.4 基于Shapley 值的组合预测模型
Shapley 值法是一种用来解决多人合作对策问题的数学方法。通过计算Shapley 值可以得出在团队合作中每个成员对主体的边际贡献率,并根据边际贡献率完成利益分配。其分配结果易于被各利益相关者接受且视为公平。因此,本文通过Shapley 值理论对各模型赋予权重,建立线性组合模型对陕西省粮食产量进行预测。在建立线性组合模型时,将总误差比作总收益,采用Shapley 值分配总误差的方法,计算各个模型的权重。具体步骤如下。
(2)计算第i种方法的边际贡献为

(3)计算第i种方法所分摊的误差为
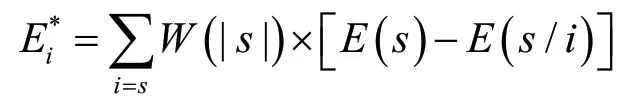
式中:n为n种方法,本文采用3 个单一模型进行组合,因此n=3。s为n种方法集合的任意子集,E(s)为其组合误差。W(|s|)为第i种方法的边际贡献,E(s)-E(s/i)为第i种方法加入后对误差的影响,Ei*为第i种方法所分摊的误差,|s|为s子集个数,s/i为子集除去i。Ei为第i种预测方法平均误差平方和,Ei*≤Ei。
根据Shapley 值理论,计算各单项模型的权重及组合预测模型:m1=0.522 7,m2=0.328 6,m3=0.148 7。
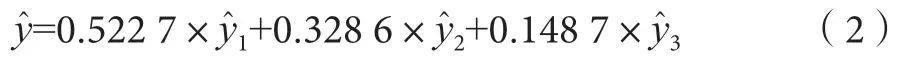
式中:为Holt 两参数指数平滑法的预测值;为GM(1,1)的预测值;为主成分回归预测值。
3 模型对比分析
选取2001—2020 年陕西省粮食产量的年度数据,并根据已构建GM(1,1)、主成分回归及Holt 两参数指数平滑法模型3 个单一模型和基于Shapley 值的组合模型计算出预测值。将预测值和实际值相比较,并计算出相对误差如表2 所示。
通过分析表2 的预测值及相对误差,可以得出基于Shapley 值的组合模型对陕西省2001—2020 年粮食产量预测的相对误差百分比平均值为2.557%,Holt两参数指数平滑法模型为2.574%,GM(1,1)模型为2.981%,主成分回归模型为3.178%。由此可得,Shapley值的组合模型预测MAPE 最小,预测误差最小,模型精度最高。通过对模型预测MAPE 的描述性统计分析可得,组合预测模型MAPE 的平均标准差最小,即相对预测误差波动最小且更加稳定。

表2 模型预测值及相对误差表
4 结论与讨论
本文先从线性回归、时间序列和灰色模型这3 个角度对2001—2020 年陕西省粮食产量进行拟合预测,然后采用Shapley 值法建立组合模型。通过研究得出结论如下。
(1)经过单一预测模型和组合模型的平均相对误差对比分析,组合模型较单一预测模型的预测精度高,平均相对误差仅为2.557%。同时,通过描述性分析也可以得出组合模型的相对误差的平均标准差小于单项模型,表明组合模型误差值波动较小。因此,在实际应用中,通过组合模型对未来预测时,预测误差更小且更稳定。
(2)通过灰色关联度分析,与粮食产量最相关的是农业生产资料价格指数,其次是有效灌溉面积、农用化肥使用量、粮食播种面积和农用塑料薄膜使用 量等。
为了更好地促进陕西省粮食生产,提高粮食产量,要坚持“两藏”战略。①“藏粮于地”,就是坚决遏制耕地“非农化”和防止耕地“非粮化”。严格区分经济作物与粮食作物的生产区域,控制耕地转化为其他农用地,防止耕地“非粮化”。禁止非法占用耕地,例如堆放固体废弃物和城镇化占用耕地等行为造成耕地“非农化”。②“藏粮于技”,就是向科技要单产,坚持农业科技自强。不仅要增加生物降解地膜、农用机械、育种、病虫害防治药物及监测系统等农业技术的研发投入,而且要加强培育高素质农业科技人才,增加农业院校及科研机构的资金投入,加强对农业生产者关于农业生产的技术培训及相关知识普及。
