一种软件需求依赖关系自动提取方法
2022-07-21刘萍萍盛靖媛
关 慧,刘萍萍,盛靖媛
(沈阳化工大学,辽宁 沈阳 110000)
0 引 言
相关研究表明,大约80%的需求是相互依赖的忽略需求依赖,对项目的成功有不利的影响。近年来,许多研究探索了基于机器学习的需求依赖提取。Deshpande等人使用NLP和ML方法提取依赖关系。Samer等人分析了小型工业数据集,并使用潜在语义分析提取了依赖类型。Priyadi等人提出了一种针对软件需求规格说明文档的需求依赖图建模方法,以及判断需求之间的相似性、精细化和约束关系的方法。Arora等人应用NLP自动识别需求语句的组成短语,计算短语之间的相似度得分,输出语法和语义相似度函数来判断需求之间的关系。
本文基于深度学习技术,提出了一种基于自然语言编写的需求文本的系统依赖关系提取方法。首先,构建需求命名实体识别模型,将最能表达需求语义的词提取为实体;其次,构建需求实体关系提取模型,提取需求实体之间的关系;然后根据需求实体关系提取需求依赖关系;最后利用多个数据集对该方法进行了评估。
1 实验方法
近年来,使用机器学习方法进行需求依赖关系提取时,通常是基于大量高质量的需求依赖关系标注文本进行的。这就导致在缺少标注文本时进行需求依赖关系提取的难度增加。因此本文提出了一个可以在缺少需求依赖关系文本的情况下进行需求依赖关系自动提取的方法,总体流程如图1所示。

图1 需求依赖实体关系的识别和提取过程
1.1 需求文本预处理
首先,对需求文本进行预处理。使用自然语言处理技术将需求文本中的语句按照“。”进行分割;然后,用特殊符号

表1 命名实体标记
1.2 需求实体提取
BiLSTM-CRF模型是由双向长短期记忆网络(BiLSTM)和条件随机场(CRF)组成的命名实体识别模型。BiLSTM能够有效表达输入向量特征在上下文中的意义,并预测相应的标签概率。CRF层可以学习序列标签的约束,并通过传递特征来考虑输出标签之间的顺序,以保证预测结果的有效性。该方法使用Glove方法将需求文本进行向量表示,然后输入到BiLSTM-CRF模型中进行预测,形成需求实体集,用于后续的需求实体关系提取。需求实体处理过程如图2所示。

图2 需求实体处理流程
经过需求实体提取后,形成了需求文本实体集entity={Subject, Predicate, Object},Subject={,, ...,S},Predicate={,, ...,P},Object={,, ...,O},见表2所列。

表2 需求实体
1.3 需求实体关系提取
1.3.1 需求依赖关系
需求之间存在各种类型的依赖关系,如需要、相似性、影响、冲突、业务相关性、演化、价值、成本、细化、包含、部分细化和不相关性。目前基于机器学习的依赖提取的研究大多是研究需求的基本依赖关系,即需求是依赖关系还是独立关系。在此基础上,一些学者对需求语句的相似度、精细化、约束关系等进行了研究。本文自动提取了相似、细化、需要、调用和冲突五种需求关系。以上关系的非正式定义如下:
(1)相似:如果需求和需要完成相同的行动或目标,那么和存在相似关系。
(2)细化:如果需求是对需求的补充或是详细说明,那么和存在细化关系。
(3)需要:如果需求需要在实现的情况下才能实现,那么和存在需要关系。
(4)调用:如果需求需要在之后实现,那么和存在调用关系。
(5)冲突:如果需求和不能同时实现,则和有冲突关系。
1.3.2 需求实体关系
需求依赖可以由谓语触发,因此谓语可以很好地表达需求语句之间的依赖关系。但是仅仅依靠谓语关系来判断需求相关性,将会得到许多错误的结果,从而影响研究。因此,本文不仅考虑谓词实体之间的语义关系,还考虑主语、宾语实体之间的语义关系。通过判断需求语句中的主-谓-宾实体关系,可以识别出需求依赖关系。例如,如果两个需求语句中的两个谓语实体存在相似关系,并且主语实体和宾语实体也具有相似关系,则可以将需求语句判定为相似关系。需求实体存在的关系见表3所列。

表3 需求实体关系
1.3.3 需求实体关系提取
Word2Vec-CNN模型由分布式词向量表示(Word2Vec)和卷积神经网络(CNN)组成。模型的输入是实体集,输出是两个实体之间的对应关系。对于输入实体集,Word2Vec可以用上下文语义的向量表示实体集,提高了CNN模型的泛化能力。CNN模型可以通过学习数据集中的规则进行训练。然后,对实体进行了对应的预测。本文将需求实体集输入Word2Vec模型进行向量表示。最后,将向量输入到CNN模型中,输出实体关系。该模型处理的需求实体集可以形成需求实体关系集,关系集可用于后续提取需求实体关系。需求实体关系提取过程如图3所示。

图3 实体关系提取过程
1.4 需求依赖关系提取
如果两个需求之间存在依赖关系,那么两个需求的谓语之间必须存在某种关系。但是,如果这两个需求之间的关系直接由谓语的关系决定,就会出现一定的语义缺失,导致判断结果不准确。因此,本文通过获取两个需求语句之间的主谓宾实体词之间的关系以及实体之间的关系判断需求依赖关系。关系判断方法如下:
(1)判断谓语实体之间是否存在已定义的关系。如果谓语之间不存在一定的关系,那么需求语句之间不存在依赖关系。
(2)如果谓语之间存在定义的关系,则接下来判断主语之间是否有一定的关系。如果主语之间没有一定的关系,那么辨别主语与宾语之间是否存在一定的关系。如果有,则此需求具有依赖关系;如果没有,则需求之间不存在依赖关系。
(3)如果主语之间存在一定的关系,那么辨别宾语之间是否存在一定的关系。如果没有关系,那么需求是独立的。
(4)在谓语、主语均存在一定关系的情况下如果宾语之间存在一定的关系,则需求之间存在依赖关系。
2 实验和讨论
2.1 数据集
本实验使用的样本数据为德保罗大学MSC学生作为学期项目开发的PROMISE和来自公共数据集的PURE,并使用文献[5]和文献[15]中的需求文本进行对比验证,以证明所提方法的有效性。
2.2 实验
为了证明该方法的可行性,本文采用的评价标准为:准确率、召回率、F1-score。
2.2.1 需求实体识别
利用BiLSTM-CRF模型进行实验,将需求文本标记为主语、谓语和宾语三种实体类型,然后将标记的数据集输入模型进行训练。实验中使用的BiLSTM模型是一个size为100、dropout rate为0.5的单层BiLSTM。将dropout rate设置为0.5的原因是dropout rate越高,准确率越低;dropout rate越低,时间效率越低。实验结果见表4所列。

表4 需求实体识别结果
从表4可以看出,BiLSTM-CRF模型的平均准确率和召回率都在80%以上,证明该方法能够有效区分需求文本中的主谓宾实体。但是,与其他主语实体和宾语实体相比,谓词实体的正确率和召回率都相对较低。这是因为大多数谓语实体是由动词构成的,而动词的时态、人称和上下文会影响其语义,从而对谓语实体的提取产生不利影响。
2.2.2 需求实体关系提取
使用Word2Vec-CNN模型进行实验。实验基于需求实体集定义不同的实体关系,并构建实体关系数据集;然后将需求数据输入Word2Vec-CNN模型进行训练。在实验中,选择“size=2,step=1”滑动窗口生成句子,即每个句子包含要求文本中的两个句子。将每个句子中出现的实体排列组合为候选实体对,然后对每个样本进行向量化,提取5个向量作为模型的输入。实验结果见表5所列。

表5 需求实体关系提取结果
从表5可以看出,该模型的平均准确率和召回率都在85%以上,在PROMISE数据集上准确率甚至达到91%,证明了该模型在提取需求依赖方面的有效性。
为了验证模型的有效性,使用文献[5]和文献[15]中的数据集进行比较。Deshpande等人利用弱监督学习对未标记数据生成伪标签,解决了所需文本缺乏标记数据集的问题,从而提高了机器学习的准确性,识别了相似、需要、或、异或等需求关系。通过本文方法对文献[15]中使用的数据集进行实体识别和关系提取,并根据依赖类型进行依赖关系提取。实验结果见表6所列。
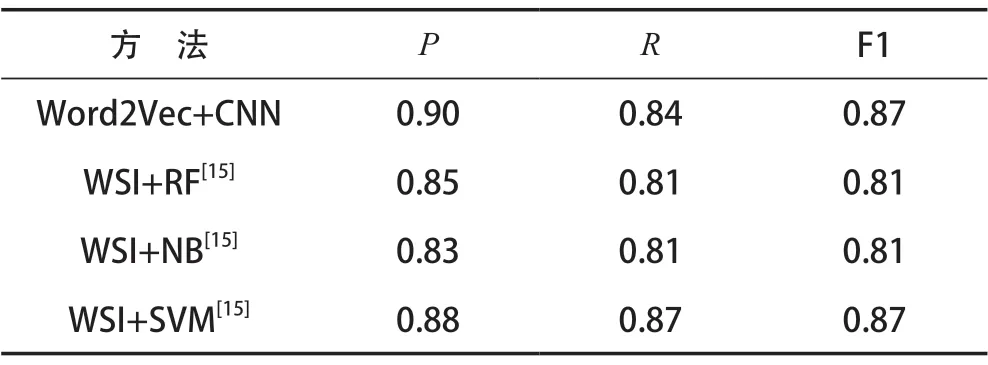
表6 本文方法与文献[15]的对比结果
从表6可知,平均准确率和召回率均在85%以上,说明该方法是有效的。虽然准确率较高,但召回率普遍较低,这说明目前的方法在处理需求依赖方面存在一定的缺陷。主要原因是,在提取需求依赖实体时,Glove的向量表示方法对一些不熟悉的需求词无效,导致提取实体不准确,出现一些错误。
Atas等人使用TF-IDF方法利用n-gram、POS-tag和“require”作为三个向量特征;通过网格搜索为每个分类器识别出最适合的特征组合;将特征组合输入到分类器(包括朴素贝叶斯、线性支持向量机、k近邻和随机森林),以自动识别需求依赖中的“需求”关系。另外,通过本文方法对文献[16]中使用的数据集进行实体识别和关系提取。实验结果见表7所列。

表7 本文方法与文献[5]的比较结果
从表7可知,准确率和召回率均在85%以上,说明该方法是有效的。虽然具有较高的准确性,但实验中的召回率较低,主要是因为在实验中使用的文本是从德国英语翻译而来,有一些语义和句子不准确,导致了一些语义错误产生。
3 结 语
本文采用实体识别和实体关系提取的方法,实现了需求依赖关系的自动提取。首先,利用BiLSTM-CRF模型识别需求文本的实体;然后,将识别出的需求实体输入到CNN模型中进行关系识别,提取需求依赖关系;最后,通过实验系统验证了该方法的有效性。本文提出的方法具有以下优点:(1)该方法在一定程度上解决了需求依赖文本缺乏标注而难以自动提取需求依赖关系的问题;(2)基于命名实体识别方法,解决了自然语言文本的模糊性问题;(3)建立需求实体关系,可以根据需求定义不同的关系,提取不同的需求依赖关系。
本文的方法虽然在一定程度上实现了需求依赖关系的自动提取,但仍存在一些不足。需求实体和实体关系的构建需要一定的人工成本。实验中使用的数据集越多,所需的人力资源就越多。今后将在这方面展开研究,改进关系提取模型,进一步提高实验的准确性和效率。
