基于深度学习的冒犯性语言检测方法综述
2022-07-10郭博露熊旭辉
郭博露 熊旭辉


摘 要:冒犯性语言在社会化媒体上频繁出现,为了建立友好的网络社区,研究高效而准确的冒犯性语言检测方法具有重要意义。文章首先阐述冒犯性语言的定义,然后分析各种检测方式的特点与基于预训练的深度学习检测方法的潜力和优势。随后对现阶段常见的预处理方法及几种典型的深度学习模型的利弊、现状进行介绍。最后对冒犯性语言检测领域面临的挑战和期望进行归纳总结。
关键词:深度学习;冒犯性语言;文本分类;数据预处理
中图分类号:TP391.1 文献标识码:A文章编号:2096-4706(2022)05-0005-06
A Review of Offensive Language Detection Methods Based on Deep Learning
GUO Bolu, XIONG Xuhui
(College of Computer and Information Engineering, Hubei Normal University, Huangshi 435002, China)
Abstract: Offensive language appears frequently in social media. In order to establish a friendly online community, it is of great significance to study efficient and accurate offensive language detection methods. This paper explains the definition of offensive language firstly, and analyzes the characteristic of each detection method and the advantages and potentiality of deep learning detection method based on pre-training. Then the paper introduces the advantages and disadvantages and current situation of common pre-processing methods at the present stage and several typical deep learning models. Finally, it concludes and summarizes the challenges and expectations of the field of offensive language detection.
Keywords: deep learning; offensive language; text classification; data preprocessing
0 引 言
隨着社会化网络应用的高速发展,网络社交媒体由于其公共性、虚拟性及匿名性等特点吸引了数量庞大的用户。以微博、Twitter为代表的网络社交媒体已经成为人们交流信息的一个重要渠道[1]。而网络社交媒体中言论自由的界限模糊,冒犯性语言甚至攻击性语言在网络平台上频繁出现。因此,为了约束用户的言论进行和建立网络友好社区,有必要研究网络社交媒体冒犯性语言的高效、准确检测方法[2]。
关于冒犯性语言的定义,现代汉语词典将冒犯解释为:言语或行动没有礼貌,冲撞了对方。对于语言接受者而言,包含威胁、辱骂、负面评价等言语的段落都可以被称为冒犯性语言[3]。而社交媒体中的冒犯性语言常表现为辱骂性语言、网络欺凌及仇恨言论等方面[4-6]。
目前,冒犯性语言的检测方法分为人工检测与自动化检测两种类型[7]。人工检测方法虽然准确率高,但是,效率低、反应速度慢,难以满足海量的社交媒体数据的实时检测要求[8]。因此,社交媒体中的攻击性、冒犯性语言的自动化检测是网络环境净化的关键,通常可以分为三种方法:
(1)机器学习检测方法。以SVM为代表的机器学习方法是基于概率、规则、空间等分类器实现的,同时可以使用词向量、攻击性词语、情感分数等特征辅助检测手段,从而提高准确率[9,10]。在该类方法中,人工完成特征的提取和选择,其结果作为机器学习算法参数训练的前置数据,因此需要大量的人力和时间完成准备工作,同时,得到的机器学习模型的健壮、鲁棒性较低[11]。
(2)传统深度学习检测方法。传统深度学习方法一般是指基于RNN、CNN、LSTM等模型的检测方法[12,13]。社交媒体中,网络用语变化极快,具有很强的时效性,因此要求模型具有很高的鲁棒性。相比于机器学习检测方法,传统深度学习检测方法是基于骨干特征提取网络获取特征数据,因此在鲁棒性方面具有更好的表现[14]。该类模型通常只依赖于上文信息识别语义,然而语言的含义常常也和下文相关,因此,即使双向LSTM等方法具备了一定的感知能力,但仍然难以解决长文本、长距离依赖关系中的上下文信息的提取问题[15,16]。
(3)基于预训练模型的检测方法。基于Transformer的预训练模型近年来受到广泛关注,其代表模型有BERT和XLNet等[17,18]。Transformer结构通过Multi-Headed Attention捕获上下文关系,同时仅关注词语间紧密程度,忽略文本的位置信息,解决了传统机器学习中长文本信息缺失的问题。此外,Transformer增加了Positional Encoding来处理Multi-Headed Attention中忽略的位置信息[19]。
基于预训练模型的检测方法解决了传统的人工检测方法效率低下及深度学习模型特征提取不全面等问题,凭借其强大的学习能力和特征提取能力成为自动化检测社交媒体中的冒犯性语言领域广受关注的方法,也是当前的研究主流。因此,下面重点介绍社交网络冒犯性语言的数据预处理及几种典型的深度学习语言冒犯性检测方法[20],主要包括卷积神经网络(CNN)、循环神经网络(RNN)和Transformer等深度学习模型。
1 预处理方法
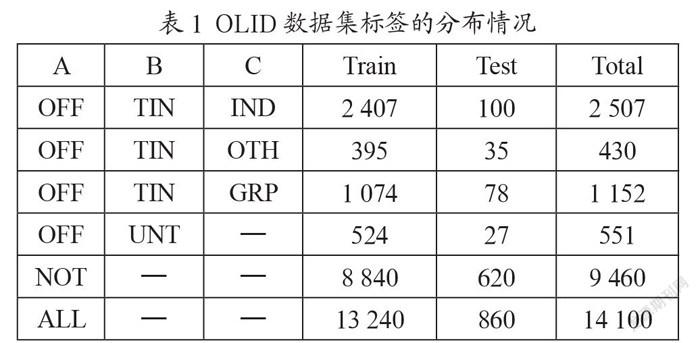
冒犯性语言检测任务通常使用攻击性语言识别数据集(OLID)[21],该数据集一共包含14 100条文本数据,取其中13 240条作为训练集,860条作为测试集。OLID数据集采用三层的分层标注模式,每条文本数据的攻击目标和冒犯言论的类型都进行了人工标注。
冒犯性语言检测包含三个子任务。首先,子任务A的目标是区分冒犯性推文(OFF)和非冒犯性推文(NOT)。其次,子任务B的目标是对推文中的攻击性内容的类型进行分类,主要分为针对个人、团体或其他的侮辱类型(TIN)和非针对的咒骂(UNT)等类型。最后,对于子任务B中的划分出来的TIN类型,在子任务C中再对攻击目标进行详细区分。子任务C分为针对个人的冒犯(IND)、针对群体的冒犯(GRP)和针对事件/现象/问题的冒犯言论(OTH)。在社交媒体中,仇恨言论通常是指针对群体的侮辱,而网络欺凌通常针对个人。表1为OLID数据集在三个子任务中标签的分布情况。
1.1 数据增强
通过数据增强方法,可以增加训练数据数量、避免样本不均衡、提升模型的鲁棒性,避免过拟合。在一定程度上,数据增强能够解决OLID数据集较小,样本不足的问题。数据增强可以分为文本改写、增加噪声和采样等三种方法。其中,文本改写是指对句子中的词、短语、句子结构进行更改,利用词典通过随机将一组词替换为具有相似语义内容的词,从而获得少数群体的合成样本;增加噪声是在保证分类标签不变的同时,增加一些离散或连续的噪声,在不影响语义信息的同时提升模型的鲁棒性;采样旨在根据目前的数据分布选取新的样本,生成更丰富的数据。
1.2 数据清洗
OLID数据集中的文本数据来自社交平台Twitter,包含错误拼写、Emoji表情、特殊符号、俚语、冗余信息等各种混杂信息,对模型的预测结果产生干扰,因此必须进行数据预处理。这类问题常见的预处理方法有以下6种:
(1)拼写纠错。拼写纠错,即自动识别和纠正自然语言中出现的错误。拼写纠错主要分为拼写错误识别和拼写错误纠正两个子任务。英文拼写纠错按照错误类型不同,可以分为Non-word Errors和Real-word Errors。Non-word Errors是指拼写错误后的单词本身就不合法,而Real-word Errors是表示那些拼写错误后的单词仍然是正确的词汇,但是表达含义有误差的情况。中文纠错单个字为单位,分为同音字错误和同形字错误两种,需要结合语境以及上下文之间的关系进行检错纠错。常用的方法有:基于规则、统计和特征的技术进行纠错、基于深度学习算法进行纠错、命名实体识别等。
(2)Emoji替换。在网络社交语言中,Emoji表情的使用现象十分普遍,直接过滤表情可能会造成语义表达的缺失。通过预处理将表情统一映射为替换短语,可以保留原本的语义信息。例如,将竖大拇指的表情替换成同义短语“thumbs up”。
(3)大小写转换。英文单词有大小写区分,社交媒体中的文本输入存在不规范使用大小写的情况。在进行预处理时一般需要将所有的词都转化为小写,例如将“Home”转换成“home”。
(4)停止词、非文本部分删除。停止词即信息检索中的虚字、非检索用字,对语义表达并没有实际含义。OLID数据集中的文本除了含有停用词之外,还包含用于定义网页内容的含义和結构的超文本标记语言标签(HTML标签)以及包含用户名的标签@USER和标点符号等内容。删除标点、重复字符等内容可以过滤无意义的信息。
(5)词干提取。词干提取是去除一个词的词缀得到它的词根形式的过程。词干提取的主要目的在于避免单词的时态和单复数形式对于文本处理的精度造成影响。例如词干提取可以简化词“finishes”“finishing”和“finished”为同一个词根“finish”,去除文章里的多种词性变化,减少计算量,提高效率。词干提取的常用方法有Porter Stemmer、Lancaster Stemmer和Snowball Stemmer。
(6)词形还原。词形还原是一种基于词典的、将单词的复杂形态转变成一般形式形态,实现语义的完整表达。与词干提取不同,词形还原不是简单地剥离单词的前后缀,而是转换单词的形态。因此,词干提取的结果完整的、具有意义的词。例如“is”“are”和“been”词干提取的结果为“be”词形还原一般可以使用TreeTagger和WordNet词形还原方法。
1.3 类不平衡
在OLID数据集中,类不平衡问题表现为每个子任务的标签分布不均衡,少数标签的样本数目稀少。在训练模型时,类不平衡问题会对训练结果产生一定干扰,影响模型的分类性能。过采样、调整阈值和调节样本权重等方法可以缓解类不均衡问题对训练结果产生的影响。过采样方法通过增加分类中少数类样本的数量来实现样本均衡,最直接的方法是简单复制少数类样本形成多条记录,这种方法的缺点是如果样本特征少而可能导致过拟合的问题;经过改进的过抽样方法通过在少数类中加入随机噪声、干扰数据或通过一定规则产生新的合成样本,例如SMOTE算法。调整阈值是根据实际情况调整划分类别的阈值,对不均衡的样本数据,根据正负样本的比例对阈值进行适当调整。调节样本权重即对训练集里的每个类别或者样本加一个权重。如果该类别的样本数多,那么它的权重就低,反之则权重就高。
2 深度学习模型
2.1 CNN
1987年由Alexander Waibel等人[22]提出的时间延迟网络(Time Delay Neural Network, TDNN),这是卷积神经网络(CNN)出现的开端。卷积神经网络是一种包含卷积运算的深度神经网络,主要由输入层、卷积层、池化层、全连接层、输出层5个部分构成。近年来,CNN在图像处理及自然语言处理领域中应用十分普遍。
在文本分类中,卷积神经网络处理的对象是以短文本为主,其算法流程主要分为四步:(1)首先将一句话中的每一个词使用word2vec拼接,构成句子的特征矩阵,作为神经网络的输入。(2)进入卷积层,与卷积核进行卷积运算,用于特征提取和特征映射,捕捉更高层次的特征。(3)通过池化层进行下采样,对特征进行压缩、去除冗余信息、抽取最重要的特征(4)形成了特征向量后,使用dropout规则化,防止过拟合,再采用全连接层使用Softmax分类器完成多分类任务。卷积神经网络用于文本分类的模型框架如图1所示。
卷积神经网络具有强大的局部特征提取能力,但卷积运算和池化导致信息的丢失,同时也会忽略掉整体与部分之间的关联。其应用场景包括机器学习、语音识别、文档分析、语言检测和图像识别等领域。
2.2 RNN
循环神经网络(RNN)是一类用于处理序列数据的递归神经网络。为了处理序列建模问题,循环神经网络引入了隐藏态的概念,由输入层、隐藏层和输出层组成,可以对序列型的数据提取特征,接着再转换为输出。隐藏层的值不仅仅取决于当前输入值,还取决于上一个时间点的隐藏层信息。
循环神经网络对文本的处理有着出色的表现,可以通过利用输入序列的上下文,提取具有上下文语境信息的文本特征。图2是循环神经网用于文本分类的模型架构。
图2 循环神经网络用于文本分类的模型框架
循环神经网络的常用领域有图像处理、机器翻译、情绪分析、文本生成和语音识别等。理论上,循环神经网络可以记忆任意长度序列的信息,其记忆单元中可以保存此前很长时刻网络的状态,但是实际应用中的记忆能力存在局限性,通常只能记住最近几个时刻的网络状态。
为了解决长距离依赖的缺陷,长短期记忆网络(LSTM)在循环神经网络隐藏层的基础上,再增加一个状态,让它保存长期记忆的能力。长短时记忆网络通过“记忆门”和“遗忘门”实现了对重要内容的保留和对不重要内容的去除,普遍用于文本生成、机器翻译、语音识别和图像描述等领域。
2.3 Transformer
Transformer是谷歌于2017年提出的一个深度学习模型框架[23]。它提出了一种基于注意力的特征抽取机制,大幅提升了模型的准确率和运算效率。不同于基于RNN的seq2seq模型框架,Transformer采用注意力(Attention)机制代替RNN来搭建整体模型框架。此外,模型提出了多头注意力(Multi-headed attention)机制方法,在模型结构中大量地使用了多头注意力机制,广泛应用于NLP领域,例如机器翻译、问答系统、文本摘要和语音识别等。
Transformer模型采用了encoder-decoder架构,如图3所示。编码器(encoder)将输入序列(x1,…,xn)转换为一个包含特征信息的序列Z=(z1,…,zn),然后解码器再基于该序列生成输出序列(y1, …, ym)。
Transformer结构的核心是自注意力(Self-Attention)机制。该机制计算输入序列中每个单词与该序列中所有单词的相互关系,然后根据计算过后的相互关系来调整每个单词的权重,得到包含上下文单词信息的新序列。采用该机制得到的单词向量既包含单词本身含义又具有该词与其他词之间的关系,因此,这种方式可以学习到序列内部的长距离依赖关系。计算方法如式(1)所示。其中,Q表示查詢向量;K表示键向量;V表示值向量;dk示输入向量维度。
(1)
自注意力机制只能捕获一个维度的信息,因此,在Transformer中采用了多头注意力机制。多头注意力机制通过多个不同的线性变换对Q,K,V进行投影,然后分别计算attention,最后再将所有特征矩阵拼接起来,从而获得多个维度的信息。计算公式如式(2)所示。
MultiHead(Q,K,V)=Concat(head1,…,headh)(2)
这里,
Transformer模型的多头注意力机制有助于网络捕捉到更丰富的特征,但架构中没有循环以及卷积结构,缺少输入序列中单词顺序的解释方法。为了使模型能够利用序列的顺序,捕获的顺序信息,额外引入了位置向量和段向量来区分两个句子的先后顺序。
型忽略单词之间的距离直接计算依赖关系,这种计算方法所需的操作次数不随单词之间距离的增加而增长。与基于RNN的方法相比,Transformer不需要循环,突破了RNN模型不能并行计算的限制,可以并行处理序列中的所有单词或符号。同时利用自注意力机制将上下文与较远的单词结合起来,并让每个单词在多个处理步骤中注意到句子中的其他单词。Transformer方便并行计算,能解决长距离依赖问题,在自然语言处理领域应用广泛。
2.4 BERT
BERT是谷歌团队Jacob Devlin等人于2018年提出的一种基于Transformer模型的编码器的大规模掩码语言模型[24]。BERT采用了Transformer的encoder框架,并且堆叠了多个Transformer模型,并通过联合调节所有层中的双向Transformer来预先训练双向深度表示。
目前将预训练的语言模型应用到NLP任务主要有两种策略,一种是基于特征信息的语言模型,如ELMo模型;另一种是基于微调的语言模型,如OpenAI GPT。
BERT模型与OpenAI GPT模型均采用了Transformer的结构。BERT使用的是Transformer的encoder框架,由于自注意力机制,模型上下层直接全部互相连接的。而OpenAI GPT基于Transformer的decoder框架,是一个从左及右的Transformer结构,只能捕获前向信息。ELMo模型使用的是双向LSTM,将同一个词的前向隐层状态和后向隐层状态拼接在一起,可以进行双向的特征提取。但是ELMo模型仅在两个单向的LSTM的最高层进行简单的拼接,并非并行执行的双向计算,上文信息和下文信息在训练的过程中并没有发生交互。ELMo这种分别进行left-to-right和right-to-left的模型实际上是一种浅层双向模型。BERT、OpenAI GPT和ELMo模型对比如图4所示。因此,只有BERT具有深层的双向表示,是其中仅有的深层双向语言模型,能同时对上下文的信息进行预测。
BERT模型是在来自不同来源的大量语料库上进行预训练,使用的两个无监督任务分别是掩码语言模型(Masked LM)和下一个句子预测(NSP)。
掩码语言模型通过随机使用[MASK]标记掩盖句子中的部分词语,然后使用上下文对掩盖的词语进行预测。这个方式融合了双向的文本信息,并且由解决了多层累加的自注意力机制带来信息泄露的问题,因而可以预训练深度双向的Transformer模型。
传统语言模型并没有对句子之间的关系进行考虑。为了获取比词更高级别的句子级别的语义表征,让模型学习到句子之间的关系,BERT提出了第二个目标任务就是下一个句子预测。下一个句子预测通过预测上下句的连贯性来判断上下句的关系。最后整个BERT模型预训练的目标函数就是这两个任务的取和求似然。使用BERT模型不需要人工標注,降低了训练语料模型的成本。通过大规模语料预训练后,预训练的BERT模型可以通过一个额外的输出层来进行微调,很大程度上缓解了具体任务对模型结构的依赖,能适应多种任务场景,并且不需要做更多重复性的模型训练工作。
然而BERT也存在缺陷,使得模型的有一定局限性。例如,BERT模型在预训练中对被[MASK]标记替换掉的单词进行独立性假设,即假设被替换的单词之间是条件独立的,实际中这些被替换的单词可能存在相互关系。此外,BERT模型在预训练中使用[MASK]标记,但这种人为的符号在调优时在真实数据中并不存在,会导致预训练与调优之间的差异。
2.5 XLNet
XLNet改进自BERT,是一种自回归预训练模型[25]。XLNet针对BERT的缺点从三个方面进行了优化:(1)使用自回归语言模型,解决[MASK]标记带来的负面影响;(2)采用双流自注意力(Two-Stream Self-Attention)机制;(3)引入Transformer-xl。
XLNet首先通过乱序语言模型(Permutation Language Model,PLM)随机排列文本的语句,再使用自回归语言模型(Autoregressive Language Model)进行训练,将上下文信息和token的依赖纳入学习范围。同时,XLNet还引入Transformer-xl模型扩大了上下文信息的广度。
BERT作为自编码语言模型,可以结合上下文的语义进行双向预测,而不是仅仅依据上文或者下文进行单向的预测。同时也导致BERT受[MASK]的负面影响,忽略了被替换的词之间的相互关系。因此,XLNet在单向的自回归语言模型的基础上,构建了乱序语言模型,使用因式分解的方法,获取所有可能的序列元素的排列顺序,最大化其期望对数似然,提取上下文语境的信息。XLNet提出的乱序语言模型,避免使用[MASK]标记来替换原有单词,保留了BERT模型中替换词之间的存在依赖关系,又解决了BERT不同目标词依赖的语境趋同问题。
由于因式分解进行重新排列,采用标准的Transformer结构会导致不同位置的目标得到相同的分布结果,因此,XLNet使用新的目标分布计算方法,目标感知表征的双流自注意力来解决这一问题。
对于长文本数据,BERT使用绝对位置编码,当前位置的信息仅针对某一片段,而不是文本整体。相对位置编码基于文本描述位置信息,可以很好的解决这一问题。因此,XLNet集成了Transformer-xl的相对位置编码与片段循环机制。在计算当前时刻的隐藏信息的过程中,片段循环机制通过循环递归的方式,将上一时刻较浅层的隐藏状态拼接至当前时刻进行计算,增加了捕获长距离信息的能力,加快了计算速度。
3 结 论
人为筛选冒犯性语言的工作繁琐且十分有限。冒犯性语言检测最初的目的是净化网络环境,在冒犯性语言出现在社交平台之前,自动检测并限制这些内容的出现。许多研究工作都致力于实现这一任务的自动检测,传统学习和深度学习在这项任务上得到了广泛的应用。就目前的发展状况,基于深度学习的方法对这些充满仇恨、暴力的言论进行识别分类是非常具有前景的手段。虽然冒犯性语言检测分类的任务上有表现优异的算法模型,取得了很多优秀的研究成果,但仍然有些问题亟待解决:
(1)跨语种分类。由于源语言与目标语言的特征空间存在差异,且语言特征不尽相同,对不同语言进行识别分类的技术仍需突破。目前冒犯性检测的数据集采用的单一语言文本,跨语种或者多语种的文本分类还不是很成熟。
(2)自动检测精确度不足。现阶段很多优秀的模型在冒犯性语言检测上表现出优异的性能,取得了很大进展,但和人为筛选的准确率相比还有很大差距。寻找高效、准确的检测方法,提出新的算法模型,有效弥补自动检测精确度不足的缺陷。
(3)数据集挑战。冒犯性语言检测的数据集相对较小,且存在类不平衡问题,容易导致过拟合。对数据集进行数据扩充或特征增强可以一定程度上缓解样本过小的压力,但是容易引入噪声数据,对分类效果产生负面影响。需要构建一个更大规模的冒犯性语言检测数据集。
(4)衡量算法性能與效率。目前冒犯性语言检测任务中不仅仅只考虑提升算法精确度的问题,提升算法的运行效率也同样值得关注。现有的深度学习模型都需要在大规模数据上预训练,当训练样本总数变大时,会使计算复杂度增高,导致运行效率降低。如何在不牺牲太多精度的情况下提升运行效率依然是值得研究的课题。
冒犯性语言检测这项任务中,文本数据嘈杂、训练样本不均衡、预测精确度以及模型的优化等问题仍然需要研究和突破。因此,探索的有效方法,产生更好的性能是这一任务未来研究的目标。
参考文献:
[1] 臧敏,徐圆圆,程春慧.社交媒体对网络新闻传播的影响分析——以微博为例 [J].赤峰学院学报(汉文哲学社会科学版),2024,35(4):121–122.
[2] WANG S H,LIU J X,YANG X O,et al. Galileo at SemEval-2020 Task 12: Multi-lingual Learning for Offensive Language Identification Using Pre-trained Language Models [J/OL].arXiv:2010.03542 [cs.CL].[2021-12-25].https://doi.org/10.48550/arXiv.2010.03542.
[3] 冉永平,杨巍.人际冲突中有意冒犯性话语的语用分析 [J].外国语(上海外国语大学学报),2011,34(3):49-55.
[4] DAVIDSON T,WARMSLEY D, MacyM,et al.Automated hate speech detection and the problem of offensive language [J/OL].arXiv:1703.04009 [cs.CL].[2021-12-24].https://doi.org/10.48550/arXiv.1703.04009.
[5] DADVAR M, TRIESCHNIGG D,ORDELMAN R,et al. Improving Cyberbullying Detection withUserContext [EB/OL].[2012-12-25].https://link.springer.com/chapter/10.1007/978-3-642-36973-5_62.
[6] MALMASI S,ZAMPIERI M. Challenges in Discriminating Profanity from Hate Speech [J/OL].arXiv:1803.05495[cs.CL].[2021-12-25].https://doi.org/10.48550/arXiv.1803.05495.
[7] SINGH P,CHAND S. Identifying and Categorizing Offensive Language in Social Media.using Deep Learning [C]//Proceedings of the 13th International Workshop on Semantic Evaluation.Minneapolis:Association for Computational Linguistics,2019:727–734.
[8] 高玉君,梁刚,蒋方婷,等.社会网络谣言检测综述 [J].电子学报,2020,48(7):1421-1435.
[9] BURNAP P,WILLIAMS M L. Cyber hate speech on twitter:An application of machine classification and statistical modeling for policy and decision making [J].Policy & Internet,2015,7(2):121-262.
[10] MODHA S, MAJUMDER P,MANDL T,et al. Filtering Aggression from the Multilingual Social Media Feed [C]//Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying (TRAC-2018),Santa Fe:Association for Computational Linguistics,2018:199–207.
[11] 李康,李亚敏,胡学敏,等.基于卷积神经网络的鲁棒高精度目标跟踪算法 [J].电子学报,2018,46(9):2087-2093.
[12] BANSAL H,NAGEL D,SOLOVEVA A. Deep Learning Analysis of Offensive Language on Twitter:Identification and Categorization [C]//Proceedings of the 13th International Workshop on Semantic Evaluation.Minneapolis:Association for Computational Linguistics,2019:622-627.
[13] GAMBACK B,SIKDAR U K. Using convolutional neural networks to classify hatespeech[EB/OL].[2021-12-25].https://aclanthology.org/W17-3013.pdf.
[14] GOODFELLOW I,BENGIO Y,COURVILLE A.Deep Learning [EB/OL].[2021-12-25].https://www.deeplearningbook.org/.
[15] ZHANG Y J,XU B,ZHAO T J.CN-HIT-MI.T at SemEval-2019 Task 6:Offensive Language Identification Based on BiLSTM with Double Attention [C]//Proceedings of the 13th International Workshop on Semantic Evaluation,Minneapolis:Association for Computational Linguistics,2019:564–570.
[16] ALTIN L S M,SERRANO À B,SAGGION H. LaSTUS/TALN at SemEval-2019 Task 6:Identification and Categorization of Offensive Language in Social Media with Attention-based Bi-LSTM model [C]//Proceedings of the 13th International Workshop on Semantic Evaluation.Minneapolis:Association for Computational Linguistics,2019:672–677.
[17] DEVLIN J,CHANG M W,LEE K,et al. Bert: Pre-training of deep bidirectional transformers for language understanding [J/OL].arXiv:1810.04805 [cs.CL].[2021-12-25].https://arxiv.org/abs/1810.04805.
[18] YANG Z L,DAI Z H,YANG Y M,et al. XLNet:Generalized Autoregressive Pretraining for Language Understanding [EB/OL].[2021-12-25].https://zhuanlan.zhihu.com/p/403559991.
[19] VASWANI A,SHAZEER N,PARMAR N,et al. Attention Is All You Need [J/OL].arXiv:1706.03762 [cs.CL].[2021-12-25].https://arxiv.org/abs/1706.03762v1.
[20] ZAMPIERI M,MALMASI S,NAKOV P,et al. NULI at SemEval-2019 Task 6: Transfer Learning for Offensive Language Detection using Bidirectional [C]//Transformers2019.Proceedings of the 13th International Workshop on Semantic Evaluation,Minneapolis:Association for Computational Linguistics,2019:75–86.
[21] ZAMPIERI M,MALMASI S,NAKOV P,et al. Predicting the Type and Target of Offensive Posts in Social Media [J/OL].arXiv:1902.09666[cs.CL].[2021-12-25].https://arxiv.org/abs/1902.09666.
[22] WAIBEL A,HANAZAWA T,HINTON G,et al. Phoneme recognition using time-delay neural networks [J].IEEE Transactions on Acoustics,Speech,and Signal Processing,1989,37(3):328-339.
[23] VASWANI A,SHAZEER N,PARMA N,et al. Attention is All you Need [J/OL].arXiv:1706.03762 [cs.CL].[2012-12-25].https://arxiv.org/abs/1706.03762v1.
[24] DEVLIN J,CHANG M W,LEE K,et al. BERT:Pre-training of deep bidirectional transformers for language understanding [J/OL].arXiv:1810.04805 [cs.CL].[2012-12-26].https://arxiv.org/abs/1810.04805.
[25] YANG Z L,DAI Z H,YANG Y M,et al. XLNet:Generalized Autoregressive Pretraining for Language Understanding[J/OL].arXiv:1906.08237 [cs.CL].[2021-12-26].https://doi.org/10.48550/arXiv.1906.08237.
作者簡介:郭博露(1999—),女,汉族,湖北荆州人,硕士研究生在读,主要研究方向:自然语言处理;通讯作者:熊旭辉(1971—),男,汉族,湖北黄石人,副教授,硕士生导师,工学博士,主要研究方向:计算机系统结构、自然语言处理。
