电子商务中基于深度学习的虚假交易识别研究
2016-12-15刘畅殷聪
刘畅+殷聪


〔摘要〕为了解决电子商务平台中存在的虚假交易问题,本文依据商品的销售记录以及商家的基本信息,提出了一种结合深度置信网络和多层感知器的虚假交易识别方法,通过识别出以通过刷单增加销量的商品来识别虚假交易。首先利用深度置信网络对交易特征进行学习,得到更高层次的抽象特征;然后利用多层感知器进行分类任务,从而识别出虚假交易。从淘宝中爬取商品的交易记录和评论数据进行实验验证,与其他机器学习模型的实验结果进行对比,其性能有明显的提升。
〔关键词〕电子商务;虚假交易;深度学习;多层感知器;交易记录;商品评论;识别方法
DOI:10.3969/j.issn.1008-081.016.10.010
〔Abstract〕For solving the problem of fraud transaction in e-commerce platform,a method that combined Deep Belief Networks and Multilayer Perceptron based on the transaction records and review records of Products was put forward.Through recognizing the product which was increased sales in fraudulent transactions to recognize the fraud transactions.The features of transaction were learned by DBN to get the higher level of abstract features,and the MLP performed the classification task.Tested by experiments using the transaction records and review records of products crawled from Taobao,the comprehensive performance had improved significantly compared with the other machine learning model.
〔Key words〕e-commerce;fraud transaction;deep learning;MLP;transaction records;product review;recognition method
目前我国电子商务市场发展迅速,已超越美国成为全球第一大网络零售市场。据浙江省商务厅发布的《浙江省网络零售业发展报告》显示,2014年仅浙江一省的淘宝店铺数量已达到147万家。商品的高度同质化、流量分配不均、商家信誉差异大等因素不仅使广大消费者难以选择合适商品,也使得商家之间的竞争越来越激烈。影响淘宝搜索排名因素主要有动态评分、收藏人气、销量、浏览量等,但是由于淘宝网有大量的新开网店没有实际的销量作支撑,也没有足够的广告推广预算,很难在庞大的淘宝网店中生存。为了快速有效地解决这个问题,就催生出了一种虚假的网上交易模式——以虚假交易的形式提高商品和店铺的搜索排名。淘宝店铺为了提高网店或单件商品的搜索排名,达到销量火爆好评如潮的目的而采取了作弊行为。在没有被发现和惩罚的情况下,虚假交易确实能给网店,特别是新开的网店带来一系列好处。第一,可以通过虚假交易提升店铺整体信誉,从而吸引消费者。第二,提升商品销量。消费者往往具有从众心理,销量过低的商品,会使顾客产生戒备心理,很难让消费者下定决心购买。第三,提升搜索排名。消费者在淘宝网浏览商品时,根据搜索排名依次浏览,排名越靠前的商品,消费者购买的可能性就越大。第四,降低店铺的差评率。当淘宝网店的差评率升高时,商家会选择利用虚假交易的方法,雇佣刷客为自己的商品给予好评,从而降低店铺的差评率,达到欺骗消费者的目的。由于在刷单的过程中,刷客必须要给予卖家好评,而好评对于消费者的购买决策能够产生巨大的潜在影响,而且一个产品的评价数量也决定了用户在商品详情页停留的时间,但是虚假的销量和评论会对消费者的购买决策产生误导作用,严重损害了消费者的利益。因此识别虚假交易对电子商务的健康发展具有重要的意义。
1文献综述
刷单是指以单件商品为对象,雇佣刷客模拟真实交易的形式,通过搜索商品、浏览商品、购买商品,给予商品正面积极的评论的形式增加商品的销量。因此在进行虚假交易识别的过程中,则以商品的评论和商品的销售记录为研究对象。
近年来,垃圾信息的识别研究是近几年的研究热点,从总体上来说垃圾信息的检测总要分为以下两个方面:基于信息本身,基于垃圾信息发布者的行为。而检测的方法主要集中于机器学习、模式识别和分类器。基于垃圾信息本身的检测方式的关键点在于特征提取的方法。特征提取方法主要包括信息熵(IG),又称为Kullback-Leibler距离[2]。Korprinska等[3]以词频方差法(TFV)来选取具有高词频方差的词。Guzella等[4]则以词汇袋(BoW),又被称为向量空间模型来进行垃圾信息的检测。Li等[5]提出了基于用户反馈的改进朴素贝叶斯方法。Sakkis等[6]将K临近方法应用于垃圾邮件的检测。Elssied等采用基于支持向量机(SVM)的过滤器进行垃圾信息的检测。以上这些机器学习方法都是一种监督式的机器学习方法,需要先验知识和一个完美的训练集。
基于垃圾信息发布者的行为方面,孟美任和丁晟春[8]分别从推销、诋毁、干扰和无意义4个方面分析了虚假评论发布者的动机,依据对造假动机的研究分析了虚假评论发布者的造假行为和隐藏行为。然而他们并没有根据虚假评论者的行为特征对识别工作做进一步的研究。文献[9]以捕捉虚假评论群体为目标,首先利用频繁模式挖掘发现虚假评论者候选组,计算虚假评论者组的指标值,将正常评论者组剔除后采用SVM方法学习和产生最后的虚假评论者组的排名。Bouguessa等[0]剔除一种非监督方法识别社交网络中的垃圾评论者,其重点在于分析社交网络中用户的关系链接结构,为每一个节点分配合理的分数,通过beta分布模型化这些分数,最终可以有效区分垃圾信息发布者和正常用户。Jiang]总结了垃圾评论者的两种行为模式:短时期内对某一商品进行持续评论和商品的实际购买量相对于用户对商品的好评严重不符,通过分析用户评论行为和对商品评价的偏差,分析识别虚假评论。
从以上总结中可知,前人主要从被评论的主体入手,对其所属的所有评论信息进行分析,此外前人在进行虚假评论识别方面采用的是浅层机器学习模型,比如支持向量机、K最邻近算法等,作为有监督学习模型,需要大量的有标记样本进行学习,会耗费大量的人工标记时间成本。浅层模型主要依靠人工经验来抽取样本的特征,而模型主要是负责分类或预测,在模型的运用不出差错的前提下,特征的好坏成为整个系统性能的瓶颈。与传统的浅层学习不同,深度学习通过逐层特征变换,将样本在原空间的特征表示变换到一个新特征空间,从而使分类或预测更加容易,展现了强大的从少数样本集中学习数据集本质特征的能力。深度置信网络(DBN)是由若干层无监督的受限玻兹曼机(RBM)和一层有监督的反向传播网络(BP)组成的一种深层神经网络,是属于深度学习的一种机器学习模型[2]。DBN作为半监督深度学习模型,首先可以采用大规模无标签的样本集合,为DBN训练提供大量的样本,省去了标注大量样本的时间。其次DBN作为深层网络学习结构,能够学习到抽象特征,弱化浅层结构的错误特征。深度置信网络具有较强的无监督特征学习能力,但分类能力不强,为了弥补DBN分类能力不足之处,本文提出将多层感知器(MLP)与DBN相融合用于实现虚假交易的识别。感知器,就是二类分类的线性分类模型,其输入为样本的特征向量,输出为样本的类别,即通过某样本的特征,就可以准确判断该样本属于哪一类[3]。多层感知器对于非线性函数具有很强的逼近能力,并且对于连接权值的初始值具有很强的敏感性,与DBN相结合可以有效地提升分类识别能力。
基于商品销售记录的时序模型
在统计学中,多以商品销售量指数来描述商品某一时期销量的变化,商品销售量指数也称为商品销售量总指数,是一种数量指标指数,是反应多种商品销售量综合变动的总指数。在本文中,参考商品销量指数模型,以商品的月平均销量作为同度量因素,则商品的每日销量变化可以用以下公式表示:
其中Sit表示商品i在第t天的销量,Save表示商品的月平均销量。同时考虑到商家的基本信息:累计评论数、交易成功数、收藏宝贝、退款纠纷率和店铺注册时间,因此我们使用以下参数来作为描述店铺的特征:
店铺注册时间:注册时间短的店铺更有可能雇佣刷客为商品提高人气。顾客往往会信任信誉高的店铺,注册时间的长短也会影响到店铺的信誉值,为了快速增加店铺的信誉值,新注册的店铺更有可能雇佣刷客为商品提高人气。以店铺注册时间至收集到的商品最后一条销售记录的时间距离作为店铺的特征度量。
退款纠纷率:退款纠纷率高的店铺更有可能雇佣刷客为商品提高人气。在现实中淘宝会有7天无条件退货的要求,当顾客受骗时会选择退货,因此退款纠纷率高的店铺说明此店铺的商品质量有问题,因此其交易记录就有很大可能由刷客所刷。以店铺的退款纠纷率作为店铺的特征度量。
商品评论率=商品累积评论数商品成功效易数:商品评论率高的店铺更有可能雇佣刷客为商品提高人气。评论是刷客在进行虚假交易过程中的一个必需的步骤,因此当店铺的商品评论率高时,交易记录就有很大可能由刷客所刷。以收集到的最后一条交易记录的时间为节点,统计此商品有内容评论总数与成功交易数的比率作为店铺的特征度量。
单件商品评论比=单件商品评论数店铺商品评论总数:单件商品评论比高的店铺更有可能雇佣刷客为此商品提高人气。雇佣刷客的店铺往往是由于店铺商品销量低而采取的措施,因此在实际情况中,会出现单件商品评论数远大于店铺其他商品评论数的情况。以收集到的最后一条交易记录的时间为节点,统计此商品累积评论数与店铺评论总人数的比率作为店铺的特征度量。
收藏率=商品成交数收藏商品数:商品收藏率高的店铺更有可能雇佣刷客为此商品提高人气。在现实中,商品收藏数也会影响淘宝的搜索排名,为了使自己的商品能够在淘宝搜索排名中靠前,商家就会要求刷客在进行刷单的同时收藏此商品,并将收藏商品作为评判刷单是否完成的一个重要标准。以收集到的最后一条交易记录的时间为节点,统计此商品成交总数与收藏此商品总人数的比率作为特征度量。
重复评论率=重复评论数商品累积评论数:商品重复评论率高的店铺更有可能雇佣刷客为此商品提高人气。在现实的刷单交易中,商家为了防止刷客不评论或者给予不符合店铺要求的评论,往往会在发布的刷单要求中提供评论内容,将刷单的风险降至最低。因此可以推测,商品的重复评论率越高,则此商品就越有可能涉嫌刷单。以收集到的最后一条交易记录的时间为节点,统计此商品重复评论数与此商品累积评论数的比率作为特征度量。
平均评论长度=商品累积评论字数总和商品累积评论数:商品平均评论长度长的店铺更有可能雇佣刷客为此商品提高人气。在商家发布的刷单订单中,可以看出,为了能吸引消费者的目光,商家往往会在自己提供的评论中长篇描述本商品的优点和服务质量。因此可以推测,商品的平均评论长度越长,则此商品就越有可能涉嫌刷单。以收集到的最后一条交易记录的时间为节点,统计此商品累积评论字数总和与此商品累积评论数的比率作为特征度量。
通过以上描述,我们就可以得到输入向量:
其中Fi1表示第i件商品所在店铺的注册时间,Fi表示第i件商品所在店铺的退款纠纷率,Fi3表示第i件商品的商品评论率,Fi4表示第i件商品在店铺中的单件商品评论比,Fi5表示第i件商品的收藏率,Fi6表示第i件商品的重复评论率,Fi7表示第i件商品的平均评论长度。
3基于深度学习的虚假交易识别模型
一个n输入m输出的线性阈值单元组成的多层感知器网络结构如图1所示。
图中,输入与输出层之间存在一些隐层。网络的输入层没有计算节点,只用于获得外部输入信号,各隐层和输出层的神经元才是计算节点,其基函数取线性函数,激活函数取硬极限函数。假设MLP只有一个隐层,并设输入为x1,x,…,xn,隐层有n1个神经元,它们的输出分别为h1,h,…,hn1,网络输出用op表示[4]。
则隐层第j个神经元的输出为:
多层感知器用于解决实际问题时,首先必须解决输入到隐层间连接权的训练问题,但是由于难以确定隐层输出的期望输出值,导致网络权值训练无法实现。因此人们寻求其它神经网络方案以解决线性不可分问题,BP网络就是这样一种网络。
传统的深度置信网络(DBN)是利用限制波兹曼机(RBM)来构建深度置信网络,如图所示。在训练过程中,首先将显性向量值映射给隐单元,然后显单元由隐单元重建,这些新的显单元再次映射给隐单元,这样就获取了新的隐单元。
限制波兹曼机的能量函数可以定义为[5]:
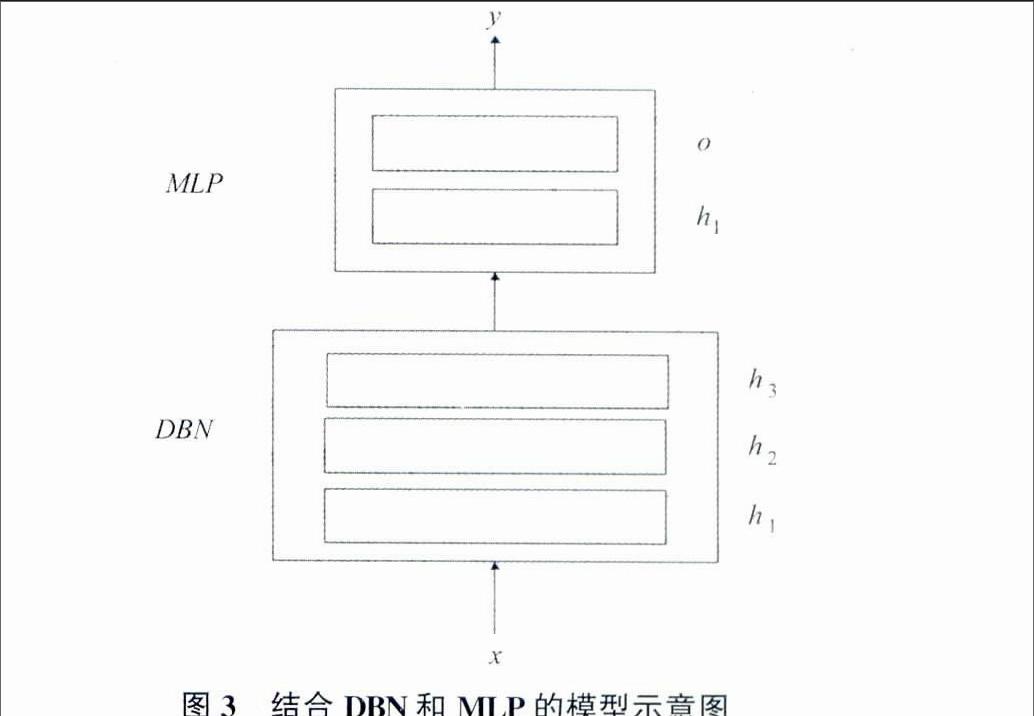
本文将MLP与DBN相融合,用于实现虚假交易的识别。首先利用DBN对交易特征进行学习,得到更高层次的抽象特征,然后对多层感知器进行初始化,从而实现虚假交易的识别,其中MLP在网络中进行分类任务。在DBN的初始化阶段,RBM将权重和偏置与MLP共享,这就意味着在DBN、MLP的初始化中,DBN模块和MLP模块使用同样的权重矩阵和偏置向量。当训练开始时,这些矩阵和向量会依据学习规则进行调节,随着训练的进行,DBN和MLP的权重矩阵和偏置向量会随之改变,也就不再相同。当训练整个网络时,参数会随之进行调节。简略图如图3所示。
4实验及结果分析
描述特征独立样本T检验结果,从输出数据中可以看出两样本均数差别有显著性意义,显著性差异明显。
本文采用分类器中最常用的评测指标:准确率(Accuracy)、精确率(Precision)、召回率(Recall)作为刷客识别的评判标准[6]。
准确率表示商品能够被正确分配到所属类别的准确率,它体现了分类器分类结果的准确程度。计算公式如下:
精确率表示虚假交易的商品能够被成功检测出来的精确率,它体现了分类器分类结果的准确程度。计算公式如下:
其中,TP表示把虚假交易的商品正确地预测为虚假交易的数量;FP表示把正常交易的商品错误地预测为虚假交易商品的数量。
召回率表示把虚假交易商品归类为虚假交易商品的概率,表示了虚假交易商品占总商品数量的比例。
TN表示把正常交易商品正确地预测为正常交易商品的数量;FN表示把虚假交易商品错误地预测为正常交易商品的数量。
在进行评价的过程中将精确度(Precision)和召回率(Recall)结合在一起,使用一个参数F-score来进行性能的评价:
中-1表示正常交易商品,1表示虚假交易商品。选取100件商品作为测试数据集,其中重合的点表示识别正确的商品,未重合的点表示识别错误的商品,从图中可以清晰地看出有5个未重合的点,即识别错误的商品,识别准确率达到了95%。使用分类识别中最常用的指标对识别结果进行量化分析可知精确率为100%,表示并未将正常交易的商品错误识别为虚假交易商品;召回率为90%,表示并未完全识别出测试集中的所有虚假交易的商品;综合精确率和召回率的指标F-score为9474%。接下来将此方法与DBN、SVM、随机森林(RF)和朴素贝叶斯方法(NBM)进行对比可以发现,其性能具有明显的提升。
5结论
本文将多层感知器和深度置信网络相结合,用于实现商品虚假交易的识别问题,其中多层感知器在识别模型中进行的是分类任务。首先利用深度置信网络对交易特征进行学习,得到更高层次的抽象特征;然后对多层感知器进行初始化,使用多层感知器进行分类任务,从而实现商品虚假交易的识别。根据商品的销售、评论记录以及店铺的基本信息来作为商品的特征,并将其量化。为了验证方法的可行性,从淘宝中收集商品的信息作为训练和测试集,对已经标记的商品数据进行训练学习,将此方法与传统识别方法进行对比,其性能有明显的提升。想对于淘宝中存在的海量的虚假交易的商品,本文中的实验数据相对较少,未来仍需要爬取相对较多的数据对方法进行进一步的验证。
参考文献
浙江省商务厅.浙江省网络零售业发展报告[DB/OL].http:∥www.zcom.gov.cn/art/2015/6/17/art1127176182.html,2015-06-17.
[2]Do M N,Vetterli M.Wavelet-based texture retrieval using generalized Gaussian density and Kullback-Leibler distance[J].IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society,2002,11(2):146-158.
