基于BP-GA算法的水平井智能压裂设计方法
2022-06-09宋丽阳王纪伟刘长印
宋丽阳,王纪伟,刘长印
(中国石化石油勘探开发研究院,北京 100083)
基于机器学习算法的人工智能技术已成为油气田关注焦点[1-3]。与传统压裂井产能评价[4-5]、基于数值模拟的压裂正交优化设计方法[6-8]相比,根据现场实际数据,采用BP-GA综合机器学习模型(简称BP-GA模型),可直接预测压裂井产能,获取可循环应用与积累校正的经验规律,从而运用灵活高效的数据推算演化生成最优方案。
国内外部分学者将机器学习算法应用于压裂数据处理:一些学者应用机器学习方法对现场数据进行训练和回归检验,建立各影响因素与产量的关系[9-14],但并未给出基于产能预测结果的压裂优化设计方法;一些学者应用大数据分析方法优化部分压裂参数,借助数值模拟软件与编程软件之间的调用接口,让机器学习算法作为一种辅助工具,与传统数值模拟方法、正交优化方法结合应用[15-18],但不能从根本上提高计算效率。本文基于BP-GA算法建立产能预测与压裂方案进化优化模型,高效变异进化生成考虑非均质性、段簇干扰等复杂因素的最优压裂方案,以指导压裂现场施工。
1 BP-GA模型
BP-GA模型,首先基于BP神经网络系统中误差逆传播算法,通过正反向传播,建立地质、工程影响因素与产能的相关模型,同时采用GA遗传算法,仿真生物界自然选择、遗传、杂交、变异等过程,对压裂方案中的各个参数因子进行重组、变异,通过与BP神经网络系统产能预测模型进行关联,以产能最大化为目标对方案进行迭代筛选优化。
1.1 BP神经网络模型
假设有n个影响因素,对所有因素完成无量纲归一化处理后,由输入层向隐含层前向传播,神经元Hi的输入加权值之和netHi可表示为
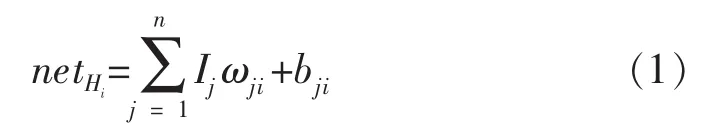
式中:j为第j个因素;i为第i个神经元(n个影响因素,相应地有n个神经元);Ij为第j个因素归一化值;ωji为第j个因素在第i个神经元中与产能的关联权重值;bji为拟合调整参数。


计算输入层与隐含层间所有权重值,完成1次误差反向传播。通过对权重值进行更新、迭代、再更新,直至计算产能值与实际产能值误差低于0.1%,获取产能经验模型。
BP神经网络的隐含层数目可根据样本数据规模、质量及计算目标确定。本文采用的双层神经网络系统,既能灵活调整权重值,又不会使计算过于复杂,可高效建立各影响因素与产能的关联,完成产能高精度预测。图1为假设3个影响因素的双层神经网络正向传播示意图(图中:分别为第1个因素在第i个神经元隐含层1和隐含层2的产能关联权重值;分别为第2个因素在第i个神经元隐含层1和隐含层2的产能关联权重值;分别为第3个因素在第i个神经元隐含层1和隐含层2的产能关联权重值)。
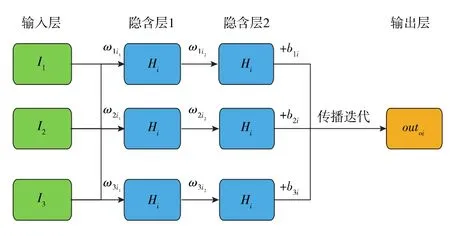
图1 双层神经网络正向传播示意
如图1所示,每完成1次正向传播后,即进一步进行误差计算和反向传播更新权重值,经反复正反向传播及迭代计算、权重值更新,直至误差低于设定值终止计算,获取最终输出值。
1.2 GA遗传算法
基于GA遗传算法建立压裂方案初始种群及种群遗传重组、变异、迭代进化机制,自动大量完成压裂参数重组与压裂方案设计。
首先对压裂参数进行编码组合,生成第1代方案组,创建形成初始方案种群。初始方案种群的坐标在0到1之间,采用二进制编码方式将初始方案种群的选项创建为[0,1]。如图2所示,引入BP神经网络产能预测机制,迭代计算适应度值,优选适应度值最高“父母”样本组,将产能影响参数基因遗传给“子女”样本,以样本自存、交叉重组、进化突变3种模式进行遗传进化。
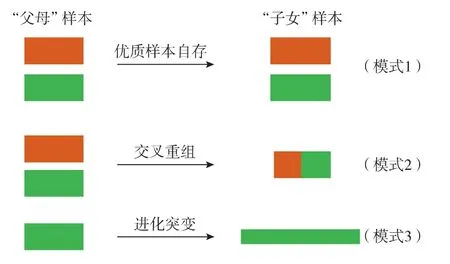
图2 “父母”代到“子女”代遗传进化模式
将通过优质样本自存遗传、产能相关影响参数交叉重组及参数基因进化突变形成的“子女”方案种群组进一步迭代计算,以实现最高产能为目标,在每次迭代中优胜劣汰参数基因及方案体。随着迭代遗传进化的次数增加,参数因子和方案种群会逐渐收敛,种群样本体向[0,0]点聚合,此时种群体所共有的参数因子在组合、变异进化中逐步收敛指向最优方案。
2 压裂设计模拟与遗传优化
以鄂尔多斯盆地70口致密气井作为样本,在充分收集现场地质、工程和生产参数的基础上,辅助采用油藏数值模拟历史拟合与产能预测结果,建立数据库样本集。运用BP-GA模型进行方案模拟:将样本集导入BP神经网络模型中进行训练,建立产能与各影响因素关联模型;在GA神经网络系统中对不同类型井组各个压裂井的压裂参数进行优化,形成针对各压裂井的差异式压裂改造方案,以获取规律性认识。
2.1 方案优化示例
将其中56口样本井数据导入BP神经网络进行训练,建立影响因素与产能关联模型,基于另外14口井数据开展精度验证与误差校正。以1口井为例,应用生成的神经网络系统预测50种压裂方案累计产气量,选取优质方案。
表1为排在前15的压裂方案部分优化参数。15种方案中,压裂50段、每段3簇、裂缝半长60~70 m和压裂45段、每段4簇、裂缝半长50~60 m 2组方案产能相对较高。以优质方案为“父母”样本,将优质“父母”样本中的影响参数拆分为基因序列进行交叉遗传重组和变异优化,生成“子女”样本方案,在GA遗传系统中迭代进化。经120次遗传迭代,样本种群收敛生成最优方案。最终优化设计压裂48段,一段一策差异设计段簇间距、射孔位置、压裂缝长、导流能力等参数,裂缝半长总体呈现从两端到中间逐渐缩短的抛物线形趋势,两端布缝密度相对于中间较高。最终优化方案中5 a累计产气量达到4 615×104m3;相对于初始样本方案,累计产气量提高了12.2%~12.5%。
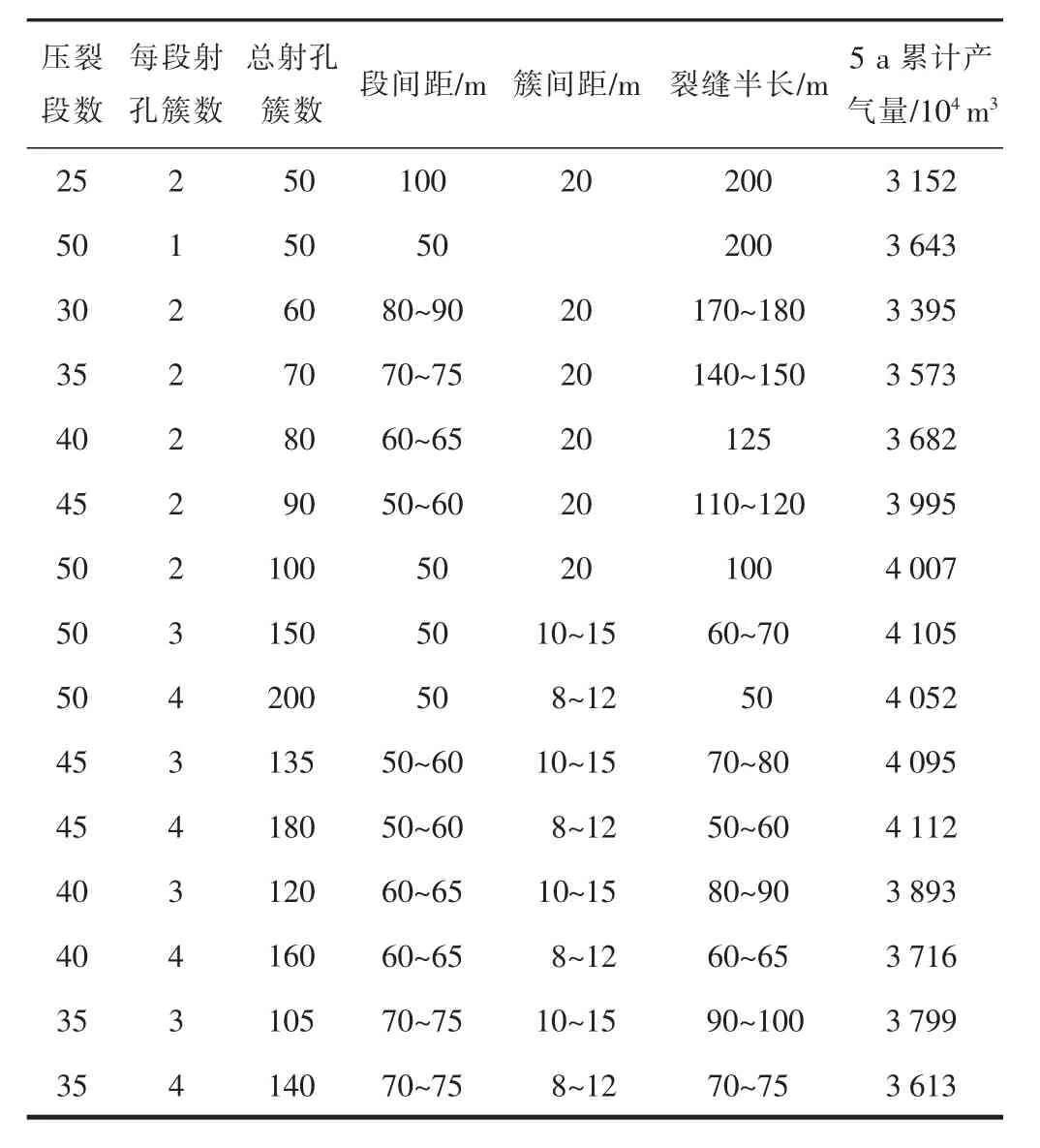
表1 15种不同压裂方案累计产气量对比
2.2 不同压裂方案对不同水平井压后产能的影响规律
综合甜度值是基于储层地质工程因素综合评估压裂方案的综合指标,在固定施工参数条件下与压后产能成正比,可用于判断某压裂段的可压性——综合甜度值越高,压后获得高产的潜力越大。以水平井分段综合甜度平均值(水平井所有压裂段区域综合甜度的平均值)与综合甜度方差值(水平井所有压裂段区域综合甜度与综合甜度平均值的方差值)为排列基准,将样本分组。综合甜度值Sm可表示为
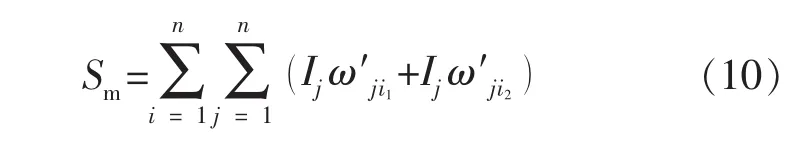
式中:ω′ji1为BP神经网络经过多次正反向传播及权重值更新、误差值小于设定值、终止计算后最终确定的第j个因素在第i个神经元隐含层1的产能关联权重值;ω′ji2为最终确定的第j个因素在第i个神经元隐含层2的产能关联权重值。
以水平井段各段综合甜度平均值为依据,将水平井划分为3个甜度等级;进一步以综合甜度方差值为依据,将3个甜度等级各水平井再划分为3类:这样,可将样本分为9组。对比甜度等级最高、非均质性最小的均质高甜度井组和甜度等级中等、非均质性最高的可改造非均质水平井组发现,前者适宜采用多段少簇密集式压裂,后者适宜采用高甜点多簇、一段一策式精准压裂方案。
W1井为均质高甜度水平井,在总裂缝长度一定的情况下,采用单段单簇、40 m段间距、压裂60段、裂缝半长80 m的方案,5 a累计产气量明显高于少段多簇、少段长裂缝方案(见表2)。

表2 均质高甜度井W1井不同方案累计产气量对比
W2井为可改造非均质水平井,固定总裂缝长度,高甜点段采用3簇/4簇射孔压裂,中等甜点段采用1簇/2簇射孔压裂,避开低甜点段,裂缝长度根据各段甜点值分布灵活调节。相对于单段单簇均匀布缝方案,一段一策布缝方案产量明显提高(见图3)。
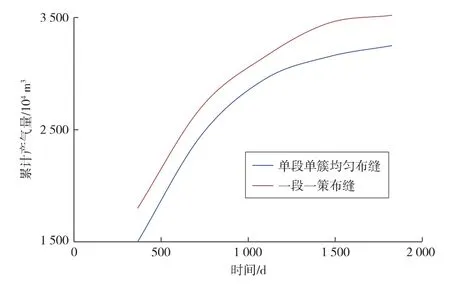
图3 W2井均匀布缝与一段一策布缝方案产量对比
对于3簇/4簇压裂布簇段,还应考虑簇间干扰对裂缝扩展的影响,将单元不连续核心力学关系式[19]加入BP神经网络系统中,根据缝内各簇裂缝扩展情况确定最优布缝位置,接入产能预测数学模型系统。
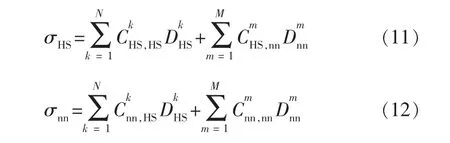
式中:σHS,σnn分别为横向剪切和正向边界应力,MPa;k为第k个偏横向剪切作用影响因素;N为偏横向剪切作用影响因素数目;m为第m个偏正向作用影响因素;M为偏正向作用影响因素数目;为第 k 个偏横向剪切作用影响因素的横向剪切边界应力影响系数,MPa/m;为第m个偏正向作用影响因素的横向剪切边界应力影响系数,MPa/m;为第 k 个偏横向剪切作用影响因素的正向边界应力影响系数,MPa/m;为第m个偏正向作用影响因素的正向边界应力影响系数,MPa/m;为第k个偏横向剪切作用影响因素的走滑剪切不连续位移,m;为第m个偏正向作用影响因素的正向位移,m。
利用横向、顶部和底部的尖端应力强度因子计算水力裂缝在垂向和横向的扩展速度(表征尖端裂缝单位时间的扩展面积)。尖端应力强度因子和裂缝扩展速度分别为
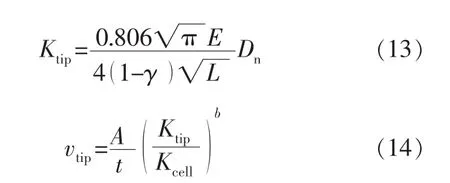
式中:Ktip为尖端应力强度因子,GPa·m1/2;E 为弹性模量,GPa;Dn为不连续位移,m;L 为研究对象长度,m;γ为泊松比;Kcell为研究单元应力强度因子,GPa·m1/2;A 为单元截面积,m2;t为模拟计算时间,s;vtip为裂缝扩展速度,m2/s。
模拟计算发现,对于3簇/4簇裂缝,采用不等间距布缝,使得中部裂缝簇靠近两端裂缝簇,可实现裂缝更均匀扩展 (见图4)。这是由于中部裂缝簇受到应力干扰,裂缝扩展受到抑制;通过不等间距布缝,可避开应力干扰作用最大的位置,降低应力干扰作用对裂缝扩展造成的不利影响。
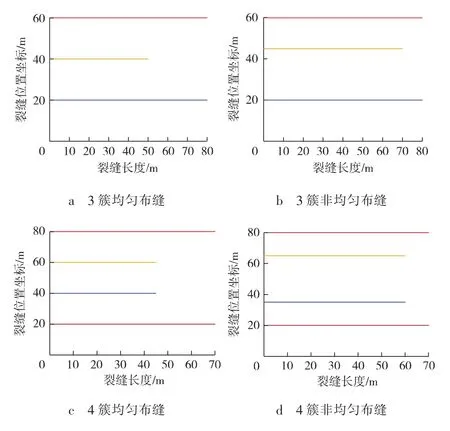
图4 3簇/4簇裂缝不同布簇方案裂缝扩展对比
3 模型精度验证
将基于BP-GA模型的产能(日产气量)预测结果与商业软件计算数值模拟结果,以及从现场获取的真实产量数据进行对比,评估模型精确度。选取鄂尔多斯盆地2口致密气井,将其中一口井——W3井在BP-GA模型中生成的最优方案输入三维数值模拟软件,建立地质与压裂裂缝模型;对比BP-GA模型产能预测结果与数值模拟预测产能,结果如图5所示。选取另一口井——W4井的现场实际施工参数作为方案参数,输入BP-GA模型与数值模拟软件中;对比BP-GA模型、数值模拟预测产能与实际产能,结果如图6所示。
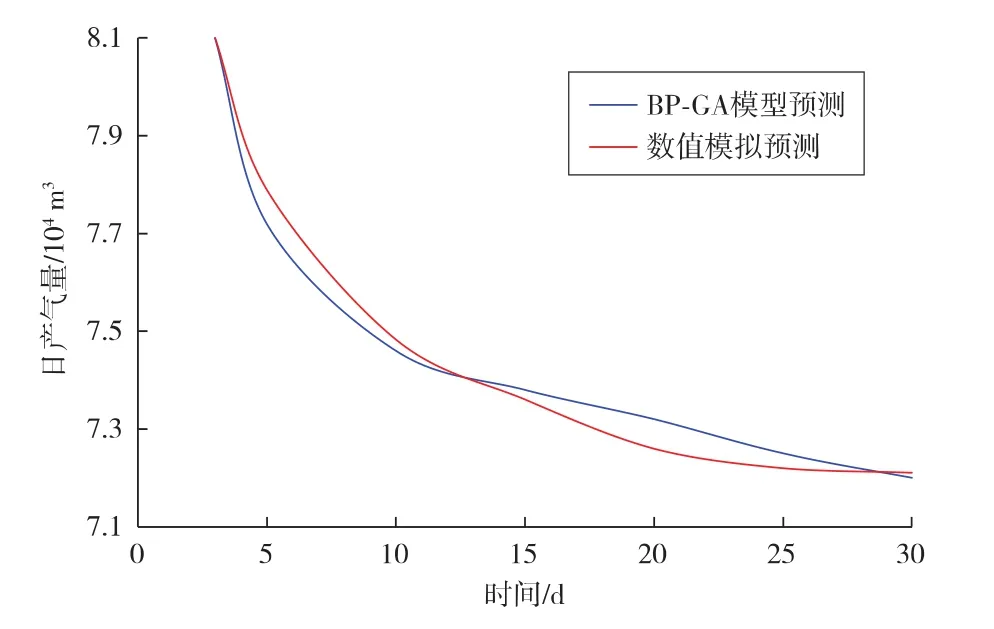
图5 W3井BP-GA模型与数值模拟预测产能对比

图6 W4井BP-GA模型、数值模拟预测产能与实际产能对比
对比W3井BP-GA模型产能预测数据与数值模拟计算结果,最大相差不超过0.91%,平均相差为0.41%。——说明两者预测结果相近,基于本文建立的BP-GA模型预测的产能数据结果可信。
对比W4井BP-GA模型、数值模拟预测产能与实际产能,数值模拟预测产能与实际产能的平均误差为2.66%,最大误差为3.86%;BP-GA模型预测产能与实际产能平均误差为1.72%,最大误差为2.08%。可见BP-GA模型预测结果与实际生产数据更为相近,这是由于BP-GA模型预测更直接地应用现场数据进行训练模拟,且参数调整更为灵活、精细。
4 结论
1)本文建立的BP-GA综合机器学习模型,是综合应用BP神经网络与遗传算法而建立的产能预测与压裂方案进化优化模型,通过将优质参数值基因进行遗传交叉重组、变异优化、迭代进化,使种群收敛生成最优压裂方案。
2)以综合甜度值、综合甜度方差值为标准,对样本井进行分组,针对不同类型水平井组进行差异式压裂方案设计。均质高甜度井组适用单段单簇、多段密集压裂方案,非均质中等甜度井组适用高甜点多簇、中甜点少簇、避开低甜点段的一段一策压裂方案。对于多簇段,通过采用不均匀布簇方式,可降低应力干扰的影响,促进裂缝均匀扩展。
3)相对于常规数值模拟方法,采用BP-GA模型预测的产能与实际产能更为接近,预测精度更高。
