基于卷积神经网络的生物医学实体标准化研究
2022-05-31赵兰枝史欣沅
赵兰枝,史欣沅
(1.河套学院 数学与计算机系,内蒙古 巴彦淖尔015000;2.中国科学院大学,北京101408)
在科学报告和公共出版物中,同一概念往往具有不同的表达方式。实体标准化,或者称为实体链接,就是要将不同的表达形式对应到相同的标准实体上。在生物医学领域,每年要出版数十万的文章。所以,自动的高效率信息检索和知识处理是非常重要的。自然语言处理领域的几大基本问题之一就是实体标准化。实体标准化要完成从模糊表达或者多样化表达到标准表达的任务。
人们为了完成实体标准化的任务做了许多的尝试。由于生物医学领域概念的多样性,生物医学的实体标准化始终是研究中的前沿领域,许多致力于完成实体标准化的文章纷纷发表。然而仅仅依靠形式上的相似来判定链接关系是不恰当的。要想准确地完成实体标准化,必须要从实体所蕴含的内在含义出发来思考问题。由于深度学习的崛起,人们期望机器能够自己学习到不同实体之间的链接关系,即使用机器学习的方法来完成实体标准化。
近些年来,以机器学习为代表的人工智能领域迅速崛起并且成为当代学术界和工业界的热点话题。现在,人工智能技术遍布我们的生活。从手机语音助手、商品推荐系统、人脸识别系统到自动驾驶技术,这些都或多或少地使用了人工智能技术。特别是近些年,随着数据的爆炸式增长、机器计算能力的增强、机器学习算法的成熟以及其广阔的应用前景,越来越多的人开始关注“深度学习”这个全新的研究领域,深度学习也以其强大的能力被运用于各个研究领域。词嵌入技术的出现使得自然语言转变为特征向量产生可能,也使得深度学习开始被运用于自然语言处理领域。然而深度学习需要大量的标注数据作为训练集。当可供训练的语料库较小时,通过深度学习完成实体标准化就成为了挑战。
本文从研究实体的语义含义出发,通过使用预先训练好的词向量所包含的语义信息来完成从通俗文本表达到标准实体的任务。通过整合完美匹配和浅层卷积神经网络的方法,本文模型能够在可训练样本较少的情况下达到非常好的性能表现。
1 基于广域表的缩写检测模型处理实体类型产生数据集的原理
通过将预先标注好的文件整合并处理后生成广域表,借由广域表完成缩写检测和找到本文处理的实体类型产生数据集。首先将数据集经过完美匹配模块进行部分匹配和剪枝,然后将目前还未被匹配的实体送入卷积神经网络模型进行实体标准化产生特征向量并与标准向量进行对比,通过投票器获得最终结果。
本文采用的输入数据是经过预先标注好的文本数据。预标注文本是由人工标注的文本,并为每个实体标记了类型。预标注文件分为两类,一类标注文件标记了每篇文章中出现的实体并为其编号,同时指明了该实体的其他具体信息;另一类标注文件标记了每篇文章中出现的标准实体并为其编号以及对应的字典ID等具体信息。例如对于一篇如图1所示的语段,其对应标注文件如图2和图3所示。

图1 原始文本数据

图2 预标注文件一(截图)

图3 预标注文件二(截图)
由《Abbreviation definition identification based on automatic precision estimates》一文提出的缩写检测模型(以下简称Ab3P模型)是一种准确率极高的,能将生物医学领域的缩写词转变成完整形式的模型。在各种各样的出版物中,缩写形式在通俗文本中是普遍存在的。例如CNS表示中枢神经系统(central nervous system,CNS),这样的用法经常出现在有关神经学科的研究文献中。显然,这样的缩写形式也应该链接到相应的实体上去。由于缩写词大部分来源于词组,缩写词通常没有预先训练好的词向量,并且会对模型的训练产生干扰。本文通过Ab3P模型[1]来将通俗文本中的缩写形式转换其对应的标准词组。Ab3P是一个专门为生物医学概念开发的缩写检测工具,其准确率高达96.5%。Ab3P缩写检测模块如图4所示。

图4 Ab3P缩写检测模块
通过应用Ab3P缩写检测模型可以生成每篇文章对应的缩写词对照表。缩写词对照文件包含实体的缩写形式和其对应的完整形式等信息。一个缩写词对照文件如图5所示。

图5 缩写词对照(文件截图)
对于神经网络所需要使用的输入数据,需要将通俗文本中的实体对应到相应的标准实体上。首先需要通过由Ab3P模型生成的缩写词对照表将缩写形式用完整形式替换,再将所有数据合并到一张广域表中以供模型之后使用。广域表的部分数据如图6所示。

图6 广域表部分数据(截图)
输入文件给出了标准词典,标准词典包含实体ID和标准实体名称2部分数据。部分标准词典数据如图7所示。

图7 标准词典部分数据(截图)
对于带有连字符的实体,需要用空白字符取代连字符来保证模型的正确运行。同时,大小写的不同也可能会对词向量的生成产生影响。如果某个词无法在词向量模型中找到匹配项,则需要将其全部转为小写形式再进行匹配。对于一个标准实体来说,使用预先训练好的Word2Vec模型,将实体中的每个词转变成相对应的大小为(1,200)词向量。每个词对应的词向量为xi=[x1,x2,...,xk],其中k=200。然后对这n个词向量做简单平均处理得到该实体对应的词向量y=[y1,y2,...yk],其中k=200。
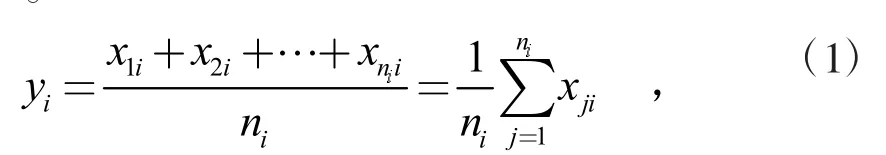
其中,xji表示第i个词向量的第j个分量,ni表示词向量的个数。
由于大小为(1,200)的词向量处理起来开销很大,并且包含许多次要信息,所以需要对词向量进行降维处理。本文使用主成分分析法对词向量进行降维,主要成分占比例不小于95%。经过主成分分析法降维的向量大小为(1,139),大大提升了模型的效率。假设实体E的标准向量为z,则z=PCA(y,ncomponent=0.95)$,其中y表示实体E的大小为(1,200)的词向量。最后将所有标准向量与标准词典表合并得到标准向量表。生成标准向量如图8所示。

图8 生成标准向量
首先要将训练数据分割为训练集和验证集,本文选择从训练数据中随机选择17%作为验证集数据。由于训练数据中包含许多未对齐实体(这些都是与本文所研究目标无关的实体),第一步要从广域表中去掉这些实体项。
同时本文的研究对象为phenotype和habitat,所以需要剔除其他类型的实体。然后将剩余的通俗实体通过词向量模型转化成大小为(8,200)的嵌入矩阵。由于98.8%的实体都是由不超过8个词组成的,所以设置嵌入矩阵的行数为8。如果实体的词向量个数不足8个,则需要用零向量填充至8个。若实体的词向量个数超过8个,则需要进行分组。每8个一组,组内进行简单平均处理。若最终结果不足8个,则进行0填充。经过这样的处理,每个通俗实体都是有大小为(8,200)的嵌入矩阵描述。令Xi表示第i个输入的实体,xij表示第i个实体Xi第j个单词的k维词向量,本文中k=200。定义词嵌入矩阵xi如下:
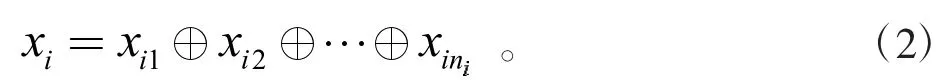
2 利用完美匹配模块提升模型的精度和提高卷积神经网络的训练效率
值得注意的是,自由文本中的某些实体能够通过基于规则的处理与标准实体完成形态上的匹配。这些实体经过形态上的比较即可快速地找到对应标准实体,而不需要被送入神经网络模型来完成链接。并且根据我们的词向量生成方式,形态上完全相同的实体之间,其特征向量一般也应该是相同的。由于完美匹配模块的贡献,本文的神经网络模型能够更高效地利用数据,收敛速度也会加快。完美匹配的规则如下:
(1)用空白符替代连字符;
(2)移除除去字母和空白符之外的所有字符;
(3)采用大小写不敏感匹配模式。
完美匹配模块如图9所示。

图9 完美匹配模块
采用卷积神经网络的灵感来源于KIM[2]和LIMIMSOPATHAM与COLLIER[3]等人。由于卷积核相当于特征提取器,使用卷积神经网络可以提取词向量中内在的本质特征。不同的卷积核可以提取的不同的特征,通过增加卷积核的个数可以增加提取的特征数目。一般来说直接提取的特征过于细致,所以需要使用池化来提升来进一步捕捉泛化特征和降低维度来提高收敛速度。使用全连接层可以学习到不同特征之间的相互联系。所以卷积神经网络往往会在网络尾端加入全连接层。
本文的卷积神经网络模块由1个一维卷积层、1个池化层和2个全连接层构成。神经网络的输入为大小为(8,200)的嵌入矩阵,输出为一个大小为(1,139)的特征向量。输出的特征向量将与所有标准向量进行比较,选择在特征空间中余弦距离最小的向量作为该实体对应的标准向量的得分。选择得分最高的标准向量最为该实体对应的标准向量。卷积神经网络结构如图10所示。

图10 卷积神经网络结构
为了减少过拟合,本文采用3个CNN模型同时训练的集成方法。3个CNN模型具有相同的结构,但是他们的初始权重却是各自随机初始化,并且具有不同的卷积核大小,不同大小的卷积核和可以抽取不同细粒度的特征。为了增强本文模型的泛化能力,CNN模型所使用的数据是经过随机bootstrap取样的[4]。并且本文采用5-折交叉验证的方法使用袋外数据来验证。3个CNN模型产生的特征向量将被送入一个多数投票器中。如果没有结果以多数优势胜出,则投票器会选取一个验证过程中准确率最高的模型产生的结果。结合集成机制的网络模型如图11所示。

图11 结合集成机制的网络模型
整个模型的输入数据分为2种:预注释通俗文本实体和标注实体。
标准实体通过词向量模型转变成(n,200)的向量模型,再经过简单平均和PCA降维处理后变成大小(1,139)的标准向量。
预注释文本中的实体首先经过Ab3P模块将缩写词还原到完整形式,然后通过词向量模型成为(8,200)的嵌入矩阵。嵌入矩阵被送入3个结构相同的CNN模型中,得到大小为(1,139)的特征向量。将特征向量与标准向量做比对,选取余弦相似度最高的标准向量送入投票器。投票器选择得分最高的标准向量作为结果。数据流动方向如图12所示。

图12 数据流动方向
3 实验结果及分析
本文所使用的生物医学语料库和预先注释的实体集由BioNLP-OS2019 task Bacteria Biotope提供。该任务中包含了2种实体类型:phenotype和habitat。实体phenotype描述了微生物的特性;实体habitat描述了可以观察到微生物的物理环境。同时该任务还提供了包含了3 602个相关标准概念的标准词典。在提供的原始词典中,每个实体被分配了一个唯一的ID,同时提供了该实体的层级信息。在本文中,每个标准实体的层级信息被省略。Ab3P缩写词探测器由任务组织者们另外提供。预先编译好的词向量模型也需要单独下载。本文所使用的实验环境为windows 10专业版20H2。本文使用基于Tensorflow和Keras的深度学习框架设计模型和算法,使用python语言进行编程。
本文的神经网络模型使用随机梯度下降算法作为优化方法,使用余弦相似度作为损失函数。在整个训练数据中,随机选择20%作为验证集数据。同时使用提前停止法来决定训练轮数。设置学习率为0.01,batch size为2,三个模型的卷积核大小分别为4、5和6,卷积核数目为5 000,超参数的设置由网格搜索法决定。
本文所介绍的模型具有良好的性能。表1展示了本文模型各个组件的准确率。通过分析表1可以看出,我们的完美匹配模块起到了相当的作用。在测试集中,CNN模块的准确率只有0.66,而整体的模型准确度却达到了0.71,这说明完美匹配模块对整体模型准确度的贡献相当可观。

表1 模型各部分性能
由表2可知,通过与其他模型的比较,ABCNN[5]只有0.22的准确率,而本文模型却具有0.71的准确率,显示了本文模型的巨大优势。由于ABCNN模型比较复杂,在数据集比较充分时发挥出非常高的性能。但是在数据集较少时,ABCNN模型的训练不足,无法发挥很好的性能。得益于浅层卷积网络的简单结构,本文模型在数据集较少时能够较快收敛并且达到非常高的精度。基准模型[6]的准确率为0.69,由于基准模型只有一个全连接层,无法从数量众多的特征中学习到各个特征和标准向量之间的关系。本文使用2个全连接层来捕捉特征和标准向量之间的对应关系,使得模型准确率上升到0.71。

表2 各模型性能比较
本文采用3个CNN模型同时训练的方法来提升模型准确率。整合模型的准确率略优于单个模型,所以整合模型确实起到了提升模型准确度的作用,但是整合模型训练比较费时。本文所使用的卷积核数目为5 000,改变卷积核的数目会导致CNN模型准确度的变化。图13给出了使用不同卷积核时CNN模块的准确度。

图13 卷积核数目对准确率的影响
当卷积核过少时,CNN模型对特征的提取不足,导致模型在训练集和测试集的精确度都比较低;当卷积核过多时,模型提取的特征太多太强,导致模型泛化能力变差,即使在训练集上精确度较高,但在测试集上的精确度却下降。同时,卷积核增多,训练时间也会呈现增加趋势。
虽然本文模型的性能表现比较不错,但是仍然存在许多不足。首先,在使用词向量模型构建标准实体的词向量时,标准实体中的每个词只是进行简单的加权平均。事实上,一个实体的词语中有的包含更多的语义信息,有的携带较少的语义信息。一种合理的方式是考虑为实体中的每个单词分配不同的权重,以使得生成的标准词向量更能表示其语义特征。或者使用其他的词嵌入模型,直接将实体转化成对应的词向量。
其次,CNN模块存在问题。通过分析CNN模块的准确率,CNN模块在训练集的准确率较高,但在测试集的准确率却相对较低。这说明CNN模块的泛化能力有待提升。
4 结束语
本文介绍了一个基于卷积神经网络的整合模型用来将自由文本中的生物医学实体标准化到其对应的标准实体上。使用Ab3P缩写词检测模块完成对输入文本中缩写词的处理。通过利用预先训练好的词嵌入模型将自然语言转变成机器可以处理的词向量。利用完美匹配模块来提升模型的精度和提高卷积神经网络的训练效率。3个具有不同大小卷积核的CNN模型同时训练提高了模型对词向量的特征抽取能力。浅层神经网络结构与完美匹配模块的结合使模型在训练数据较少时达到了相当的准确率。与相关模型的对比也展示出本文模型的效率。但本文模型依然存在一些问题,想要达到更高的准确率需要更加深入的研究。
模型性能的进一步提升有可能通过将更多的语义信息纳入模型而实现,例如上下文环境信息,实体的层次信息等。由于缺乏语境信息而导致标准化过程中产生偏差,这种偏差不仅影响卷积神经网络模块的性能,而且会影响完美匹配的性能。对于同一个文本中实体,标准词典可能具有多个候选实体可以与之对应。但是由于缺乏语境信息,本文模型只能将其对应到一个固定的标准实体上。尽管已经有人在研究如何在实体标准化时保留更多的语义信息,但是想要完成完美的实体标准化还有很长的路要走。
