面向配电网大数据的自组织映射知识融合算法
2022-05-25张淑娟秦丹丹
王 鑫,赵 龙,张淑娟,汪 玉,秦丹丹,孙 伟
(1.国网安徽省电力有限公司 电力科学研究院,安徽 合肥 230022; 2.国网安徽省电力有限公司,安徽 合肥 230061)
Web 3.0与大数据时代的到来证实了多种前期技术理论的实践与应用的可行性,谷歌公司在2012年提出的知识图谱为其代表性实例之一[1]。知识图谱通过结合不同个体的关系、属性可视化模型与语义网(Semantic Web)技术,使复杂现代应用系统实现便捷、高效的人机信息交互。知识图谱是多种现代科技的结合技术,包含智能语义[2]、知识提取[3]、知识关联[4]、知识融合[5]、知识加工[6]等。其中,知识融合通过利用机器学习方法,从不同来源、不同结构的数据集中,提取近义个体的关系及属性并生成关联,实现异构数据的信息交互及协作应用。
知识融合是知识图谱的关键环节,也是支撑知识图谱可用性的重要因素,其核心为实体的消歧(disambiguation)[7]与解析(resolution)[8]。实体的消歧指大量数据中同义实体的抽取及分类,一般用于海量异构数据的实体融合;实体的解析指实体间或实体与属性间相互关系的分析,一般用于异构、同义实体的属性融合。实现实体的消歧与解析通常需要结合自然语言处理及机器学习技术,前者将非结构化数据转化为结构化数据,后者从结构化数据中分析、提取、融合实体的关联。机器学习中,监督式学习(朴素贝叶斯、支持向量机等)利用大量训练数据样本建立实体、属性、关系的分析模型并用于后续的知识融合,具有较高的实时性但需要一定的数据成本;无监督式学习(主成分分析、孤立森林等)无需训练成本,但其复杂度较高,尤其在大数据环境中较难满足知识融合的实时性。
本文提出一种基于自组织映射(self-organizing map,SOM)神经网络的低复杂度、无监督式知识融合算法。该算法面向多维、异构的配电网半结构化异构数据源,通过同构数据间的知识聚类及异构数据间的自组织迭代,有效降低分析复杂度,从而保障知识融合的实时性。本文提出的算法被用于国网安徽省配电网知识图谱系统的构建,并利用全业务统一数据中心的数据集进行实验分析,验证了知识融合的效率及应用可行性。
1 知识融合技术相关研究
目前,随着知识图谱在各行各业的迅速普及,跨业、跨界数据的知识融合技术已经引起学术界的广泛关注。
国内方面,文献[9]在知识图谱构建技术的综述中,具体解释了知识融合的概念、意义及知识融合在知识图谱应用中的重要性;文献[10]具体分析了现代知识融合的支撑理论架构,在知识融合的各阶段列举了多种知识融合理论模型;文献[11]分析了先网络环境的碎片化知识特征,提出了一种结合非线性融合模型的知识超网络的融合框架;文献[12]针对解决推荐服务的信息爆炸问题,通过推荐服务提出了一种基于贝叶斯网络模型的知识图谱融合技术;文献[13]面向用户行为数据的采集与共享应用,在科研数据管理系统中通过知识融合技术分析了科研工作者的行为数据共享机制,并通过开发、应用移动行为数据采集APP开展了实证研究。
国外方面,文献[14]针对车载自组织网络的上下文信息共享问题,提出了一种基于非标准、非单调推理服务的知识融合算法,实现了车载网络节点不一致上下文注释的自动协调及合并;文献[15]针对多源区间值(interval-valued)数据的动态融合,提出了一种将多源区间值数据转换为梯形模糊颗粒的模糊信息融合方法及增量分析算法;文献[16]面向基于社交行为提示的生物识别应用,通过融合个人知识、社交行为知识和独有生物特征,增强了传统生物识别系统的性能;文献[17]分析了基于知识图谱的专家系统、搜索引擎及知识问答系统在害虫及作物病害的应用,介绍了知识图谱的知识融合技术在智慧农业的应用现状;文献[18]针对电力设备电源质量问题的多样性及复杂性,提出了一种基于知识-数据融合的神经网络模型,在常规信息、质量信息、过程信息等异构数据中有效提高了电源质量问题的分析效率;文献[19]面向异构知识图谱的融合应用,提出了一种基于图结构数据、图神经网络,用于融合知识图谱实体子图结构的知识融合机制,实现了知识图谱中实体的融合嵌入。
2 本体融合
本文提出的算法针对配电网大数据环境中异构、半结构化数据的知识融合,而高效准确的信息融合离不开良好的本体模型的构建。本体(ontology)在信息学科中是一种对于数据的抽象概念模型,本体模型为知识融合提供了模板和依据。本体模型由实体、关系、属性等三元组组成,定义为:
O=(E,R,P)
(1)
其中:O为本体;E为实体(entity);R为关系(relation);P为属性(property)。实体、关系为结构化数据,而关系是一类数据的集合,包含实体所对应的所有属性的关联规则。实体、关系在同构数据集中具有同等的定义,但在异构数据集间需通过实体消歧进行实体融合。属性为非结构化数据的集合,包含实体所对应的事件等自然语言文本数据。
本文提出的知识融合是对同义、近义本体的实体及属性映射,因而需进行本体间的匹配度计算。本体匹配度的计算过程为:
MMatch(OA,OB)=αSsim(EA,EB)+
(1-α)Ssim(pA,pB)Ssim(R←pA,R←pB)
(2)
p=argmaxSsim(i∈P,i′∈P′)
(3)
其中:MMatch为匹配度;Ssim为0~1之间的相似度;α为匹配度权重系数,与同构数据集的大小相关。(2)式、(3)式中,2个本体间的匹配度由实体相似度、最大属性相似度p及其所对应属性的关系相似度而计算得出。
3 知识融合算法
根据上述的本体模型,本文提出一种基于自组织映射神经网络的异构本体知识融合算法(SOM-based knowledge fusion algorithm for heterogeneous ontologies,SOM-KFH)。
自组织映射神经网络是一种竞争型、无监督式神经网络,常用于数据聚类[20]、协同控制[21]等。该神经网络中,各神经元通过竞争、聚类、加权过程的多次迭代,实现复杂的信息处理。
通用的自组织映射神经网络模型如图1所示。该模型中,SOM-KFH的输出神经元对应异构数据库的所有本体,输入神经元对应待匹配本体,而竞争过程则对应匹配度的比较过程。
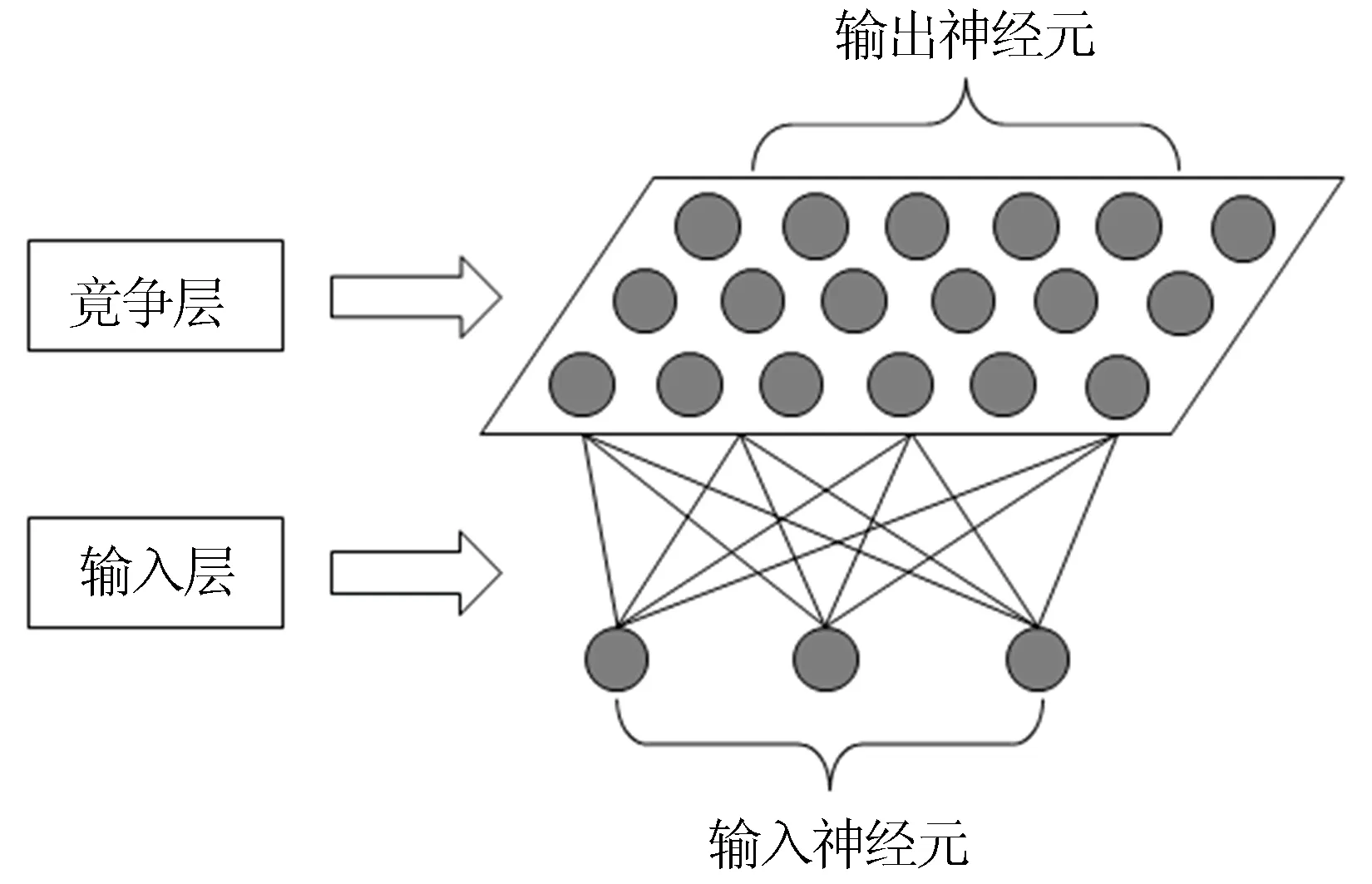
图1 自组织映射神经网络模型
SOM-KFH通过下述方式实现异构数据的本体映射。首次迭代中,根据输入层输入的待匹配本体在竞争层进行本体的匹配竞争,在第1个异构数据库中选择最高匹配度本体为获胜神经元;然后根据SOM领域函数,以获胜神经元为中心聚类匹配度较高的其他神经元,并根据领域函数值赋值下轮迭代的匹配权值,到此首次迭代结束。二轮迭代中,输入上一次聚类的神经元及对应的匹配权值,在第2个异构数据库中选择与聚类神经元中任意一个神经元匹配度最高的神经元,选为该轮的获胜神经元;继续迭代聚类与匹配权值更新过程,在后续数据库中持续进行匹配竞争。最后选择所有数据库的获胜神经元,映射相关本体并进行后续的属性融合。
下面举例介绍SOM-KFH算法的具体运作及应用过程,该过程假设从A、B、C、D 4个异构数据库中,选择与待匹配本体最为相近的4个本体,进行属性融合。
(1) 首次匹配。以首个数据库D的所有本体为输入神经元,待匹配本体为输出神经元,根据(2)式、(3)式进行匹配度比较,选择获胜神经元,如图2所示。
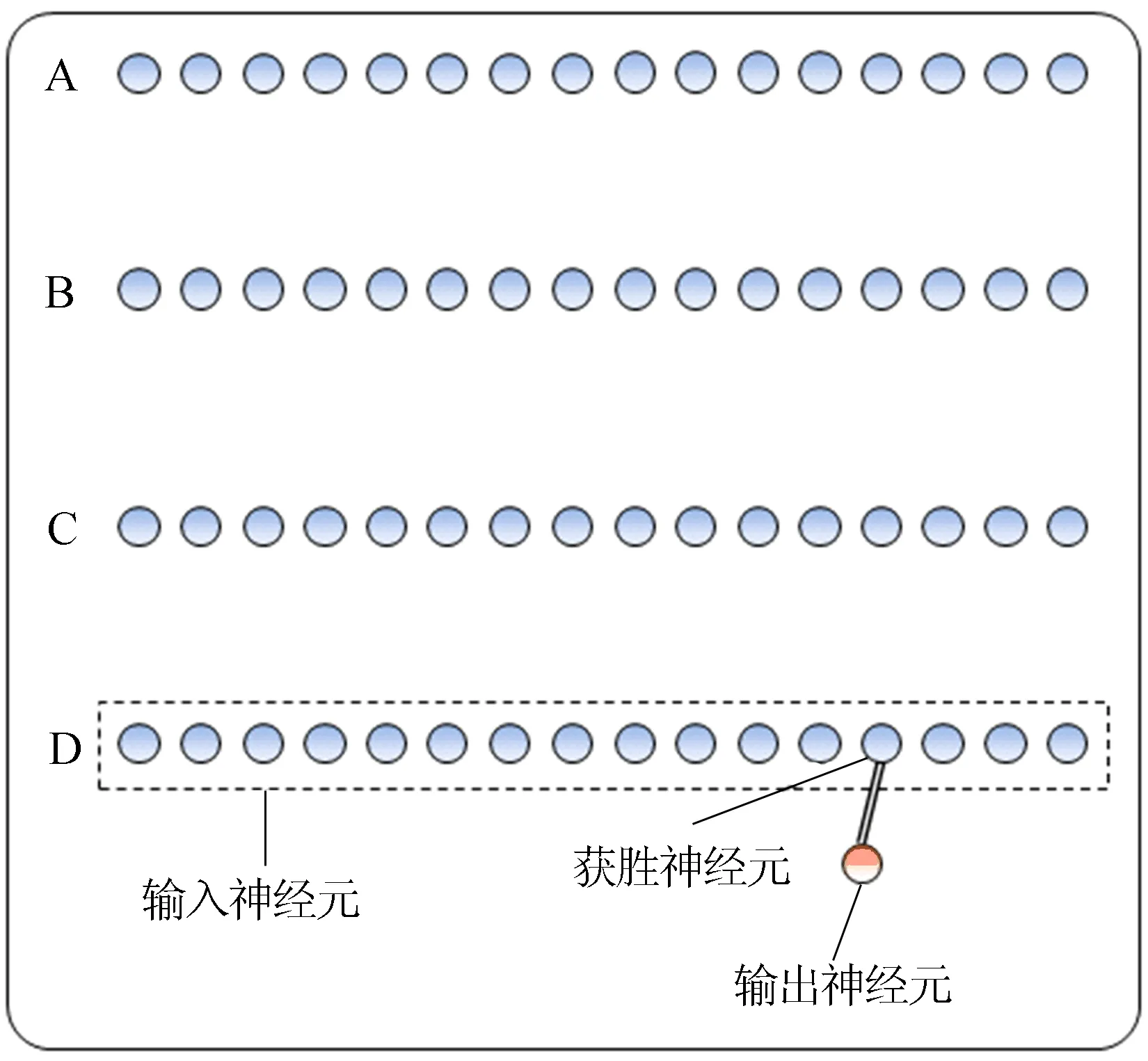
图2 SOM-KFH首次迭代
匹配度比较过程如下:
(4)
其中:Wwinner为获胜神经元;i为输入神经元编号;N为输入神经元集合;Iin为输入神经元;Oout为输出神经元。
(2) 本体聚类。以上一次获胜神经元为中心,计算SOM领域函数如下:
(5)
其中:j为输入神经元编号;δ为0~1的常数,根据数据库间的相关性设定;k为迭代次数;g为最高匹配值;λ为领域半径。
因此下一轮迭代的输出神经元为获胜神经元的领域半径λ内的所有本体,输入神经元为数据库C的所有本体,而领域值f则决定各输出神经元的匹配权值,获胜神经元获得最高权值,其他神经元与获胜神经元越近,则获取更高的权值。至此,首次迭代结束。
(3) 权值更新及迭代竞争。再次进行迭代竞争,与首次迭代不同,此时存在多个输出神经元,而各输出神经元具备不同的匹配权值。因此,匹配度比较公式更新如下:
(6)
其中:j为输出神经元编号;K为输出神经元集合;f为匹配权值。
选择该轮迭代的获胜神经元如图3所示。图3中,上轮的获胜神经元具备最高的匹配优先度,但在数据库C所有本体中得出最高匹配度的神经元是领域内其他神经元。因而,本轮获胜神经元为数据库C中与该最高匹配度神经元对应的神经元。
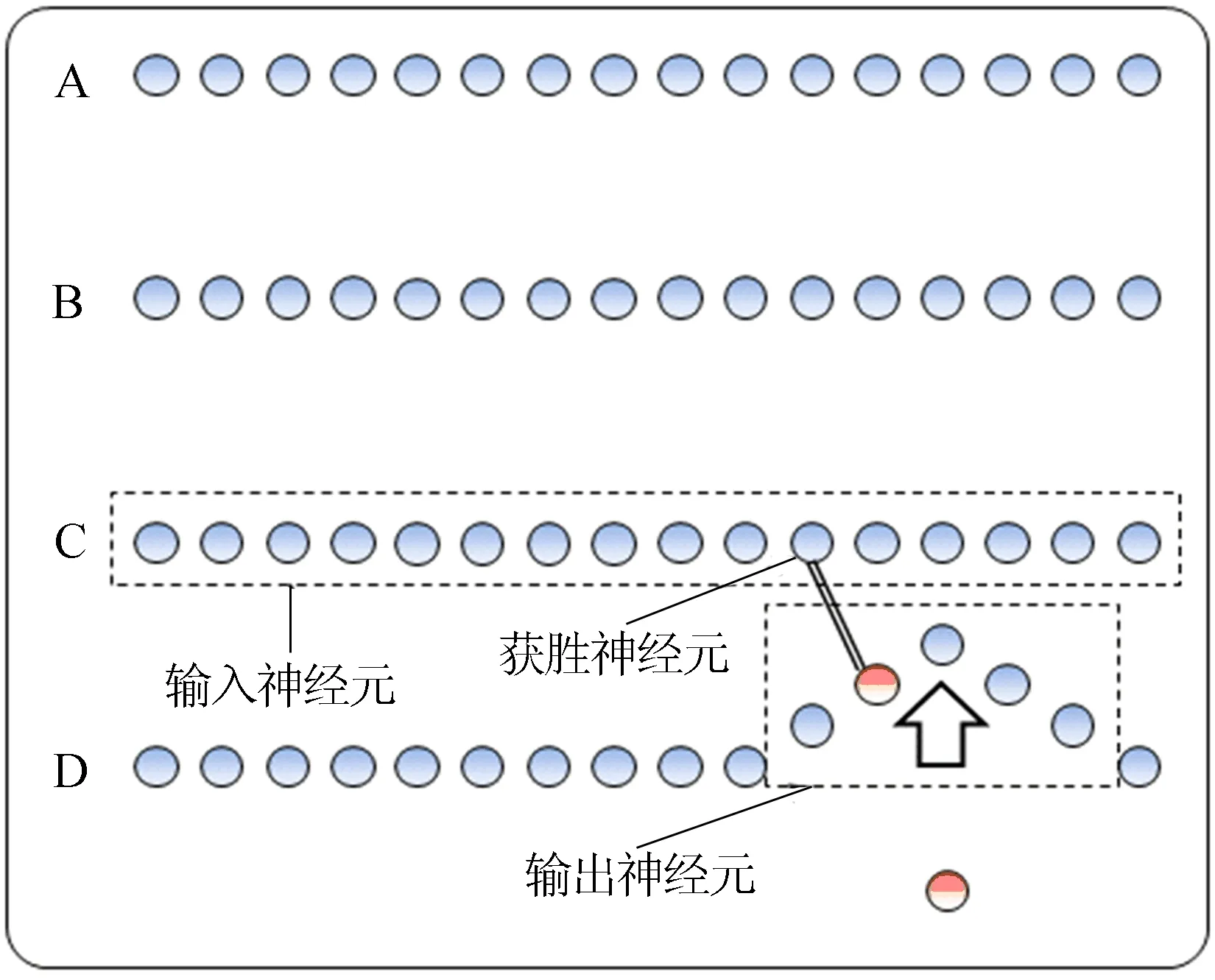
图3 SOM-KFH二次迭代
持续迭代该过程,直到在所有数据库中选出获胜神经元,如图4、图5所示。
(4) 本体映射。迭代结束后,提取所有迭代过程的获胜神经元,映射对应本体,进行属性融合,如图6所示。
SOM-KFH是一种无监督式神经网络算法,无需在数据库中获取基于机器学习的先验知识。
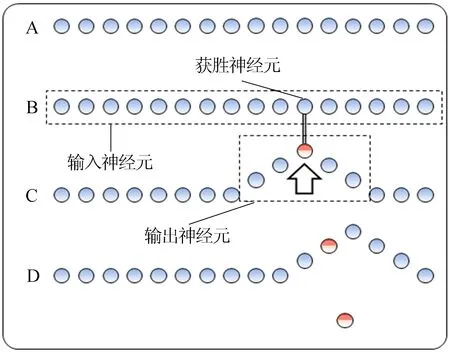
图4 SOM-KFH三次迭代
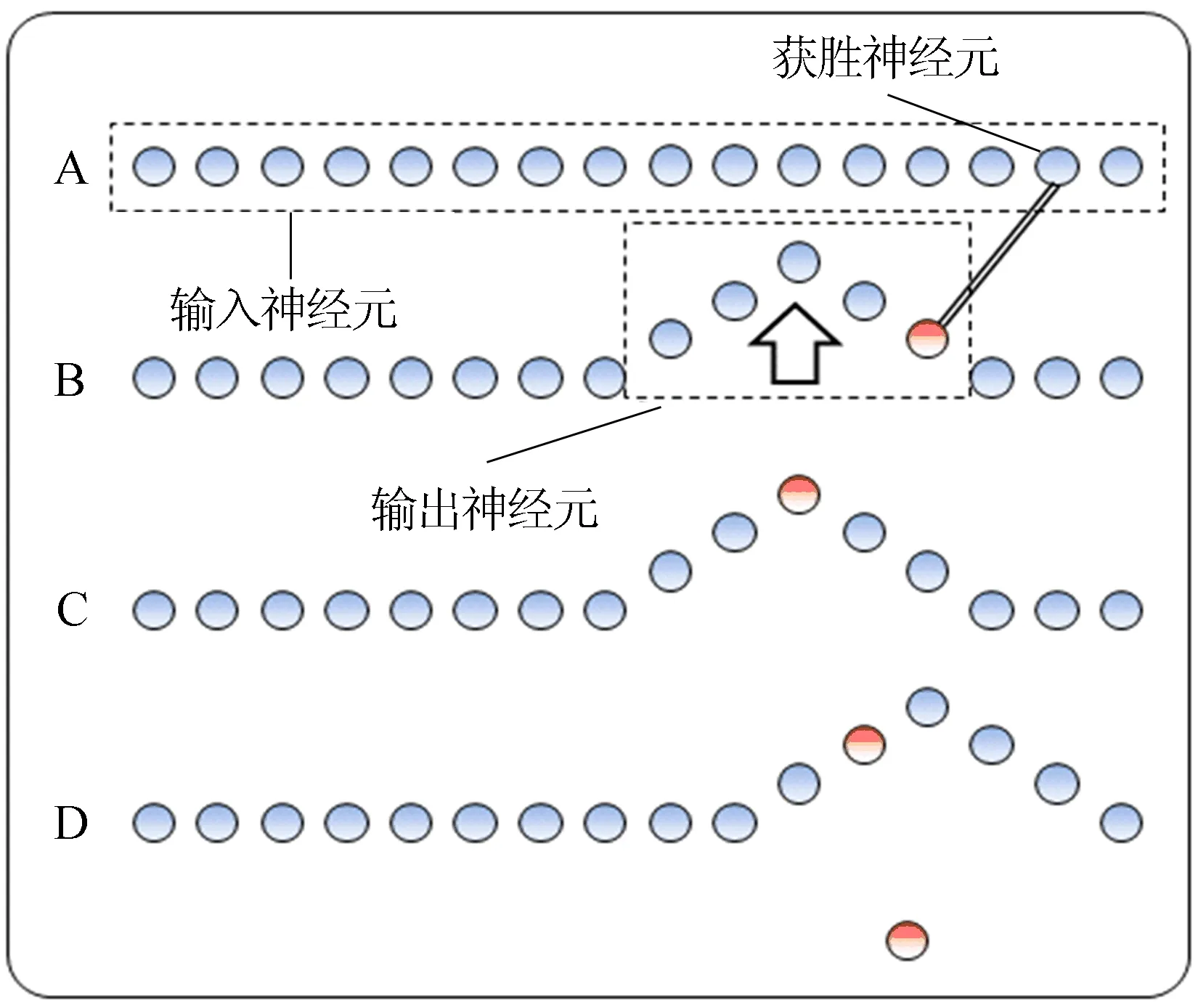
图5 SOM-KFH最终迭代
相比常规的无监督式神经网络算法,该算法在每轮迭代过程中,仅在获胜神经元领域半径内进行匹配度比较,从而大幅度降低了神经网络的拓扑结构复杂度,并保证了算法的收敛性。因此,该算法在基于异构本体映射的知识融合中具备良好的实时性。

图6 SOM-KFH本体映射
4 性能分析与评价
本文算法的性能测试使用国网安徽省电力数据。数据库包括营销业务应用系统、生产管理系统以及地理信息系统。本实验通过文字筛选及替换,将3类系统数据扩展为9类异构数据库,进行增量分析。9类数据量库按随机顺序进行本体映射,3类原始数据库维持相同的数据库相关度,即(5)式中δ,而增加的数据库与原始数据库间则设定了较小的数据库相关度。对比算法选择同为无监督方式的极大似然估计(maximum likelihood estimate,MLE)及K近邻(K-nearest neighbor,KNN)算法,其中KNN算法的K值为10。实验方法如下:
(1) 根据预定义的语料库,对所有异构数据库进行本体关联,定义融合指标。例如,异构数据中实体为“电缆”“缆线”,关系为“故障”“停役”等本体属于互映射本体,其属性为实体及关系所对应的事件(如发生***区域大规模停电、安排***维修员进行现场抢修等)。
(2) 在一个数据库中随机提取一个本体,使用融合算法在其余8个数据库中分别选择8个融合本体,各本体包含1个实体、5类包含的关系及3种各关系所对应的属性。
(3) 根据融合指标提取各融合算法的TP(true positive)、FP(false positive)及FN(false negative)指标,通过计算准确率(precision)与召回率(recall),比较分析F1分数,计算公式为:
Pprecision=TTP/(TTP+FFP)
(7)
Rrecall=TTP/(FFP+FFN)
(8)
F1=2(PprecisionRrecall)/(Pprecision+Rrecall)
(9)
F1分数的实验结果比较如图7所示。从图7可以看出,相比KNN,SOM-KFH和MLE得出较高的F1分数。KNN中,根据输入属性,在全局数据库间进行本体的聚类,选择数据库间离聚类中心最为接近的本体。这种方式在低维数据中可得出较好的融合效果,但在高纬度异构数据中,因持续累积的匹配误差,最终得出较差的F1分数。MLE采用比较所有实体→属性→关系似然值的全局搜索方式,得出较高的F1分数,但这种方式需要较高的时间复杂度。
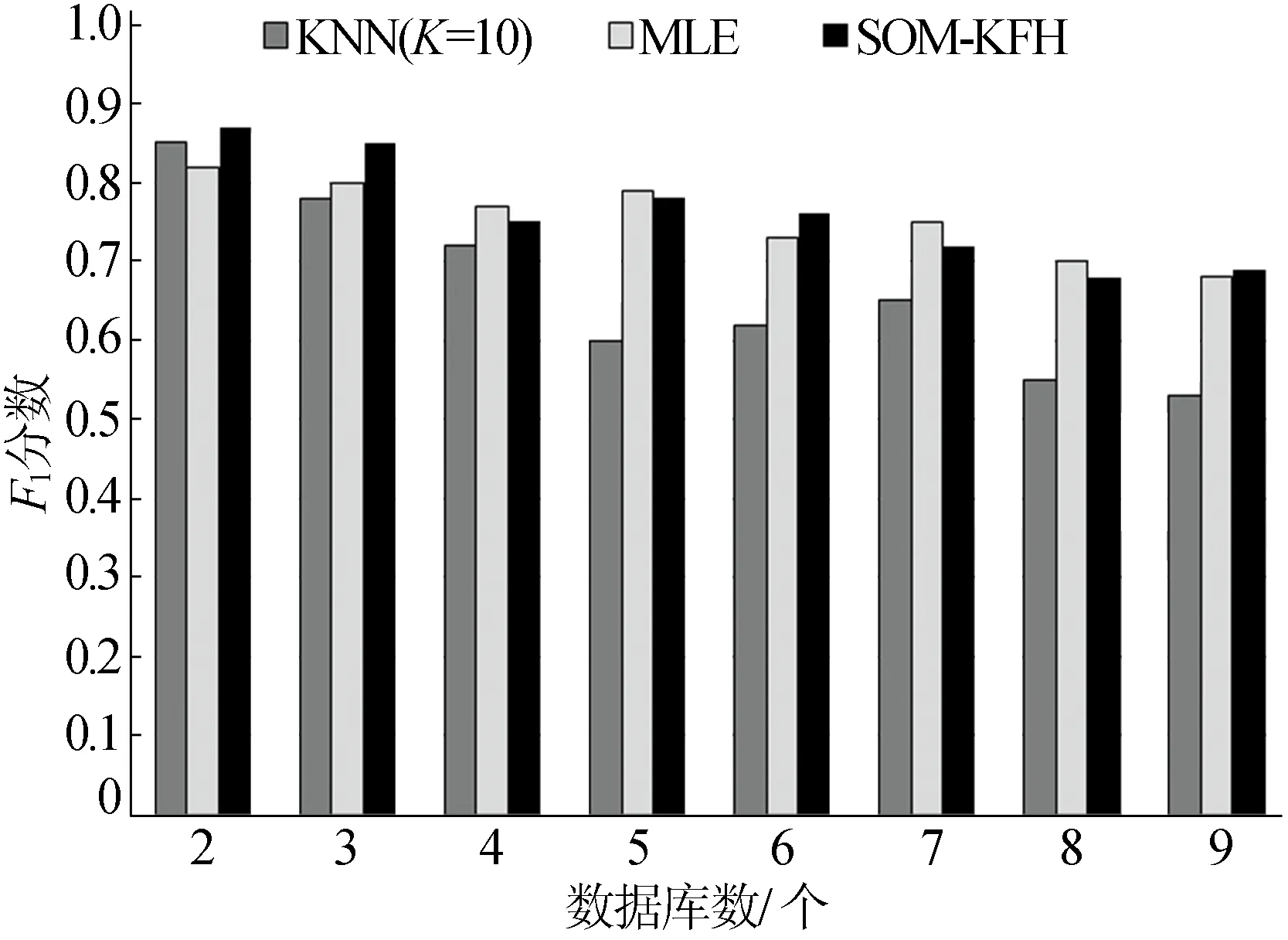
图7 F1分数的比较分析
本文对不同算法本体映射所消耗的时间进行比较,如图8所示。
从图8可以看出,MLE的运行时间指数级增长,因而较难应用于高纬度数据集。SOM-KFH与KNN的运行时间线性增长,但KNN的单次聚类的时间复杂度相对较低,消耗了较少的运行时间,因此具有更小的时间复杂度。
本文提出的SOM-KFH算法在F1分数和运行时间上均有较好的结果。相比KNN算法,消耗了略长的运行时间,但F1分数显著提高;相比MLE算法,得出类似的F1分数,但大幅度降低了多维数据库的本体映射所消耗的时间。上述实验证明本文提出的SOM-KFH算法在多维、异构的复杂数据集中,可通过有效映射同义、近义本体,保障知识融合的可行性。
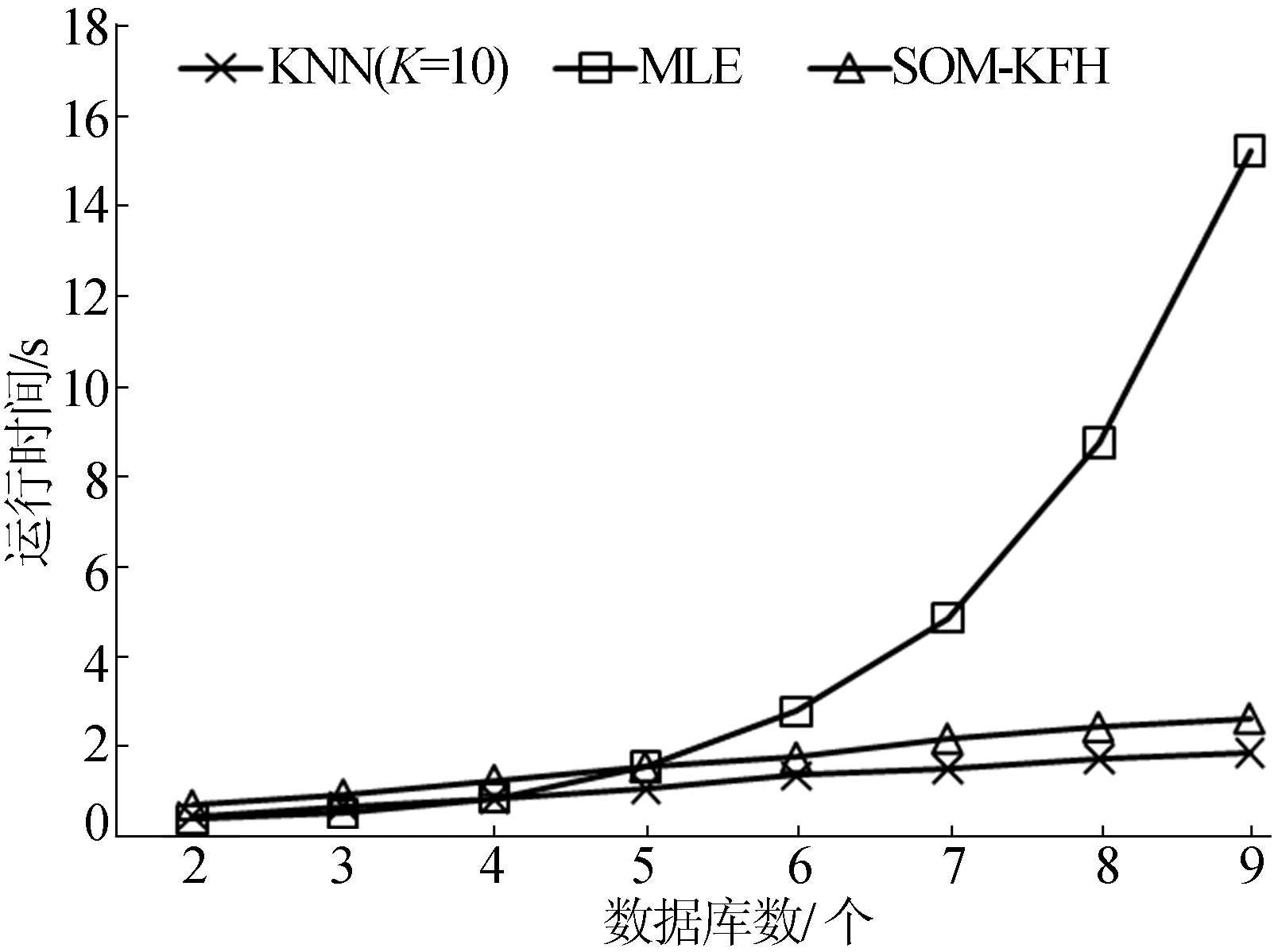
图8 算法运行时间的比较分析
5 结 论
本文面向大数据环境的复杂信息融合应用,提出一种基于自组织映射神经网络的知识融合算法。该算法通过引入由实体、属性、关系组成的异构数据本体模型至自组织映射神经元的聚类及迭代竞争,有效实现了异构本体的相互关联及知识融合,同时该算法继承了自组织映射神经网络的无监督学习特点,一定程度上保障了算法的收敛性。将本文算法应用于国网安徽省电力有限公司知识图谱系统的构建,研究发现,相较于MLE和KNN算法等传统无监督学习算法,本文算法在准确率、召回率和时间复杂度方面具有明显的优势,表明该算法具备较高的知识融合效率及运行性能。未来将进一步探索本文算法在非结构化异构数据源中的应用有效性和可行性。
