基于机器学习的液压驱动单元能耗建模方法
2022-05-25王玉琳黄海鸿
左 昊,王玉琳,金 瑞,黄海鸿
(1.合肥工业大学 机械工程学院,安徽 合肥 230009; 2.合肥工业大学 机械工业绿色设计与制造重点实验室,安徽 合肥 230009)
0 引 言
液压系统具有高功率密度的特点,广泛用于工程机械和成形机械领域[1],但普遍存在高噪音、高污染、低能效问题[2]。为解决上述问题,很多学者对液压系统进行了研究,如文献[3-4]针对液压成形装备,对其工作过程中的能量流进行了研究。由于传统液压系统的驱动单元由异步电机和定量泵构成,输出的流量不能改变,导致在低速工况下输出流量大多通过溢流阀直接流回油箱,从而造成大量能量损失。因此,变流量液压驱动单元成为研究热点。
变流量液压驱动单元的实现形式主要有3种,分别是定速变排量驱动单元(由异步电机和变排量泵构成)、变速定排量驱动单元(由变速电机和定排量泵构成)和变速变排量驱动单元(由变速电机和变排量泵构成)[5-7]。
定速变排量驱动单元在工程中已经广泛应用。1973年,文献[8]首次提出了泵控技术,采用三相异步电机驱动变排量液压泵,并研究了泵控液压系统的静态和动态性能;文献[9]研究表明,同传统阀控系统相比,定速变排量驱动单元的节能效果高达40%。
随着电机控制技术的发展,变频器得到广泛应用,很多学者采用变频器控制三相交流电机,提出变速定排量液压驱动单元。文献[10]在液压电梯上采用变频电机驱动螺杆泵,该驱动单元与普通阀控液压系统相比,平均节能效果达46.3%;文献[11]对注塑机液压驱动系统进行了深入研究,对比了5种不同的驱动单元(异步电机驱动定量泵、变转速异步电机驱动定量泵、异步电机驱动变量泵、交转速异步电机驱动变量泵和交流伺服电机驱动定量泵),其中交流伺服电机驱动定量泵的能耗最小,相较于异步电机驱动定量泵,系统的节能率高达88%;文献[12]对比了定速变排量驱动单元和变速定排量驱动单元的能量效率,发现变速定排量驱动单元在大多数场合具有更高的能效。
文献[13-15]对3种液压驱动单元的性能进行了研究和对比,并对变速变排量驱动单元的动态性能进行了研究,发现借助驱动系统的动态损耗模型,可以将能耗降低20%以上。在文献[16]的研究中,变速变排量液压驱动单元被用于提高液压机的能效;通过对比3种驱动单元在液压机单个工作周期中的能效,发现变速变排量液压驱动单元具有最高的能量效率,变速定排量驱动单元次之,定速变排量驱动单元的能效最低;同时,提出一种变速变排量驱动单元的节能控制策略。虽然上述方案在实际案例中都取得了不错的节能效果,但是节能策略都建立在大量实验数据和有级工作区域的基础上,不能完全发挥变速变排量的节能潜力。此外,变速变排量驱动单元的理论能效模型存在转速和排量的耦合关系且模型误差较大,导致理论模型难以应用于实际生产中。
为了解决变速变排量液压驱动单元能效模型难求解和不精确的问题,本文提出采用机器学习算法建立能耗预测模型的方法。机器学习算法是通过找出数据里隐藏的模式进而做出预测的识别模式,广泛应用于能耗预测问题中。文献[17]通过响应面法结合期望函数的方法,建立了数控切削加工过程的能量模型,取得了较好的效果;文献[18]基于深度学习,研究了车削能耗的建模方法,并对比支持向量机(support vector machine,SVM)、卷积神经网络、堆栈自动编码器和深度信念网络的建模效果,结果表明堆栈自动编码器是最适合的能耗建模方法;文献[19]针对机器学习模型在住宅能耗预测领域的应用进行研究,提出并讨论了支持向量机、逆向传播神经网络(back-propagation neural network,BPNN)、随机森林和梯度提升机4种模型,其中基于集成学习方法的随机森林和梯度提升机模型的表现性能最好。
采用数据驱动的方法,根据部分实验数据建立误差较小的能耗预测模型。本文对变速变排量液压驱动单元进行能量分析,通过实验平台和数据采集系统采集传感器数据,并基于6种独立的机器学习方法(岭回归、SVM、随机森林、梯度提升决策树(gradient boosting decision tree,GBDT)、极端梯度提升(extreme gradient boosting,XGBoost)、BPNN)和一种堆叠模型对变速变排量液压驱动单元的能耗进行建模,通过能耗建模优化输入的参数配置,节约输入能量,以降低驱动单元能耗。
1 液压驱动单元的能量分析
变速变排量液压驱动单元由伺服电机和电磁比例柱塞泵构成,如图1所示。
图1中:伺服电机主要采用交流永磁同步电机,通过伺服驱动器实现转速的精确控制;通过控制电磁比例柱塞泵的伺服阀和2个控制活塞调整斜盘倾角,从而改变柱塞泵的排量;通过调整电机的转速和柱塞泵的排量控制液压驱动单元的输出流量。
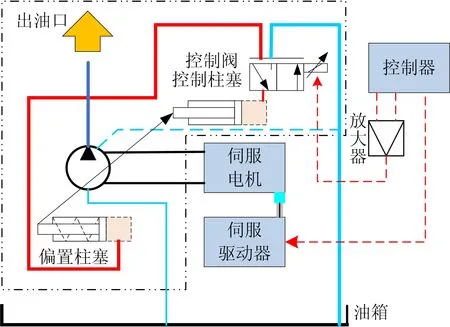
图1 变速变排量液压驱动单元示意图
伺服电机及其驱动器将来自电源的电能转换为机械能,液压泵将电机输出的机械能转换为液压能,驱动液压系统工作。液压驱动单元的能量损耗主要由电机驱动器能耗、电机能耗和液压泵能耗组成,如图2所示。
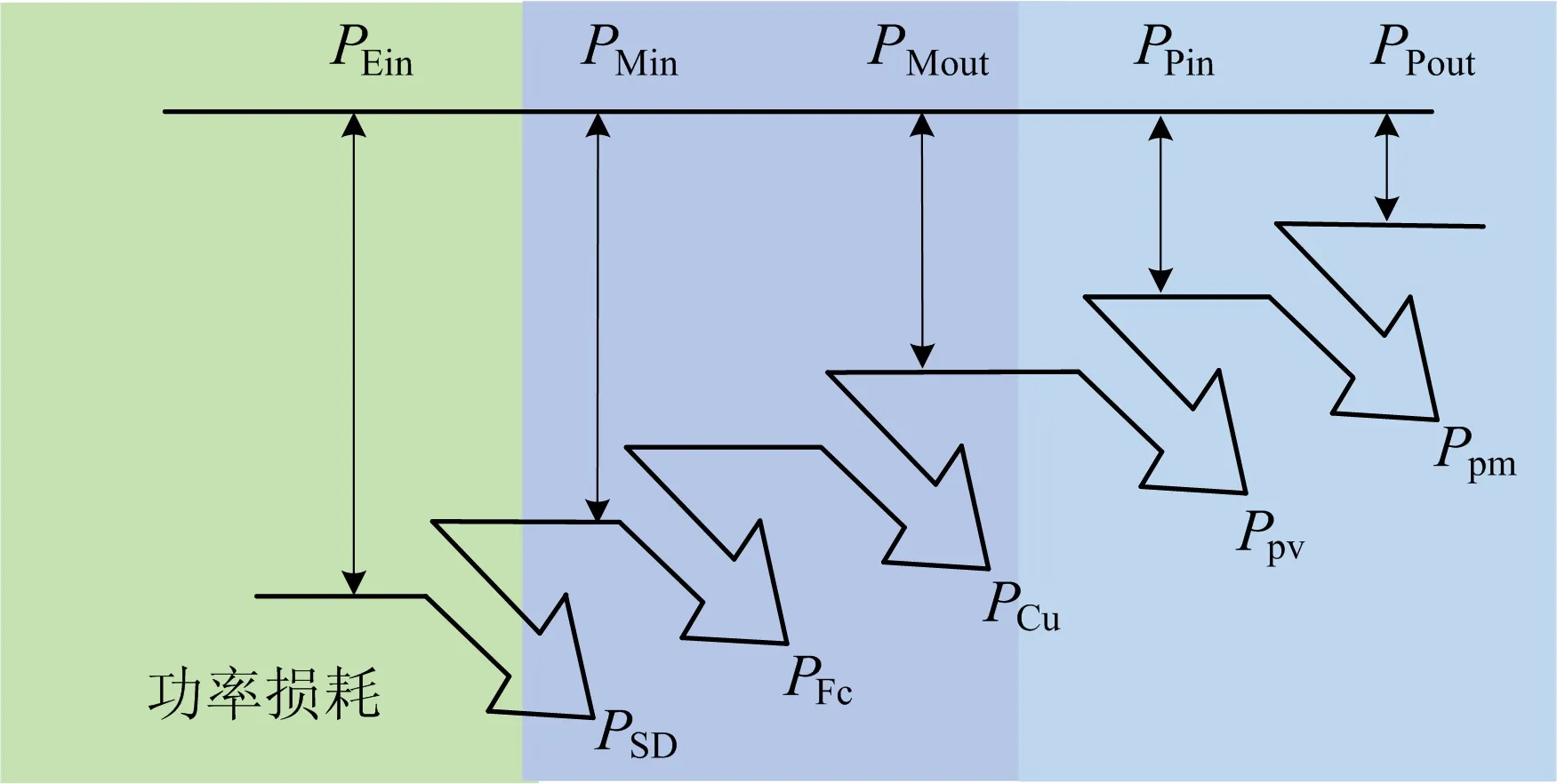
图2 变速变排量驱动单元的能量流
忽略伺服电机的转子损耗、机械损耗和杂散损耗,变速变排量驱动单元的能量损耗可以表示为:
(1)
其中:Eloss为驱动单元的能耗,单位J;Ptloss为总功率损耗,单位W;t为工作时长,单位s;PSD为伺服驱动器的功率损耗;PFe为电机定子铁损;PCu为电机定子铜损;Ppv为柱塞泵的容积损耗;Ppm为柱塞泵的机械损耗。
液压驱动单元的输出能量为:
(2)
其中:Eout为驱动单元的输出能量,单位J;Pout为柱塞泵的输出功率,单位W;ppump为柱塞泵出油端压力,单位MPa;qpump为柱塞泵的输出流量,单位m3/s。
结合(1)式、(2)式,液压驱动单元的总输入能量可以表示为:
(3)
其中,Pin为驱动单元的输入功率,单位W。
由于忽略了电机与柱塞泵之间传动的机械损失,电机的输出功率等于柱塞泵的输入功率。根据文献[14],PSD、PFe、PCu、Ppv、Ppm均与泵的输出压力、输出流量以及电机转速n具有函数关系,同时考虑温度T对液压油属性和零部件的影响,可将液压驱动单元的总功率损耗简化为:
Ptloss=f(ppump,qpump,n,T)
(4)
液压驱动单元的总输入能量表示为:
Etotal=g(ppump,qpump,n,T)
(5)
根据(5)式可得,变速变排量驱动单元的输入能量只与液压泵的输出流量、输出压力、电机转速和液压油温度有关。在实际应用中,相同的工况下(即Pout相同)可以采用驱动单元的输入功率Pin作为评价能效的特征。
因此,本文将基于机器学习方法,结合采集的数据,研究如何通过ppump、qpump、n和T建立对Pin的预测模型。
2 机器学习方法
2.1 实验平台与数据采集系统
实验平台和数据采集存储系统框架如图3所示。
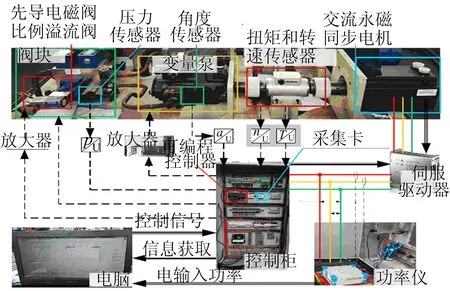
图3 实验平台与数据采集系统示意图
实验平台由交流永磁同步电机、伺服驱动器、电磁比例变量柱塞泵、集成式阀块、电磁比例溢流阀和油箱等构成,其主要参数见表1所列。
实验平台通过转速转矩传感器获取伺服电机的转速,角位移传感器获取电磁比例柱塞泵的排量,压力计获取柱塞泵出口压力,温度传感器获取油箱温度。以上信息数据通过NI数据采集卡传递给基于LabVIEW软件搭建的数据采集系统。同时,电源端的功率数据由功率仪采集,并通过Modbus-RTU数据传输协议传递给采集系统。

表1 实验平台的主要参数
2.2 数据预处理
根据上文所述,变速变排量液压驱动单元能耗模型的数据包括电机转速n、柱塞泵的出口流量q、出口压力p、油箱的温度T以及驱动单元的输入功率Pin。由于流量传感器在小流量时的数据不稳定,无法直接用于机器学习模型训练。在实际实验中,采用柱塞泵的排量V代替柱塞泵的出口流量,用于能耗建模。实验数据采集过程如下:
(1) 设定液压系统工况,即伺服电机的转速、柱塞泵的排量和溢流阀的工作压力。
(2) 持续运行实验平台,在该过程中,采集伺服驱动器端的实时输入功率Pin、电机实际转速n、油箱的温度T、柱塞泵的实时排量V和出口压力p,总时长为s。
(3) 更改液压系统的工况,重复执行步骤(1)和步骤(2),直至采集到充分的实验数据。
液压系统在切换工况过程中需要短暂的时间恢复至稳定状态,以便更好地建立能耗预测模型,保留每组数据的稳定值部分,防止异常数据影响模型精度。
采用下式对每组特征(Pin,n,T,V,p)对应的数据分别进行零均值归一化处理:
(6)
其中:特征的均值为μ;标准差为σ。该处理将原始数据映射到均值为0、标准差为1的正态分布上。
2.3 机器学习算法模型
变速变排量液压驱动单元的能耗预测是一种非线性问题,可以采用具有非线性拟合能力的机器学习回归算法求解。在众多的机器学习算法模型中,岭回归模型在线性回归的基础上进行了改良,具有处理非线性问题的能力,并加入了正则化项来缓解过拟合;支持向量机回归模型利用核函数进行非线性映射,其决策函数只由少数的支持向量确定,具有很好的鲁棒性;集成学习通过构建并组合多个学习器实现建模,具有较好的泛化能力,其代表性算法有bagging方法中的随机森林模型和boosting方法中的GBDT与XGBoost模型;BPNN是目前广泛应用的一种神经网络形式,具有良好的非线性映射能力、自学习自适应能力和泛化能力。本文将采用上述6种机器学习算法建立变速变排量液压驱动单元的能耗预测模型,所有模型都采用交叉验证的方法,并对各模型进行超参数优化。
2.3.1 岭回归
给定数据集D={(x1,y1),(x2,y2),…,(xm,ym)},其中xi=(xi1,xi2,…,xid),yi∈R。线性回归(linear regression)试图学得一个线性模型以尽可能准确预测实际值输出标签值。其损失函数如下:
(7)
其中:yi为第i个样本真实值;xi为第i个样本的特征取值;ω为特征系数。
在线性回归的损失函数上添加L2范数正则项即岭回归[20],L2范数为:
(8)
岭回归的损失函数为:
(9)
2.3.2 支持向量机SVM
SVM[21]属于有监督学习算法的一种,其回归模型为支持向量回归(support vector regression,SVR),其问题可形式化为:
(10)
其中:C为正则化常数;lε为ε-不敏感损失(ε-insensitive loss)函数,即
(11)
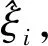
s.t.f(xi)-yi≤ε+ξi,
(12)
由于线性学习器的表示能力有限,需要引入核函数来将线性学习器拓展为非线性学习器,常用的核函数包括线性核函数、多项式核函数以及高斯核函数,本文中使用的是高斯核函数。
2.3.3 随机森林
随机森林[22]以决策树作为基学习器,并在决策树的训练过程中引入了随机属性选择。回归或分类随机森林伪代码如下所述。
1.Forb=1 toB
(a) 用自助法从训练数据中提取大小为n的样本Z*;
(b) 通过递归重复,将随机森林算法树的数目Tb增长到自助法数据量,为树的每个终端节点执行以下步骤,直到达到最小节点大小nmin;
i. 从变量p中随机选择m个变量
ii. 在m个变量中选择最佳变量/分割点
iii. 将节点分成2个子节点
2.3.4 梯度提升决策树GBDT
Gradient Boosting[23]是Boosting中的一大类算法,典型的算法代表为GBDT,其基本思想是根据当前模型损失函数的负梯度信息来训练新加入的弱分类器,然后将训练好的弱分类器以累加的形式结合到现有模型中。在每一轮迭代中,首先计算出当前模型在所有样本上的负梯度,然后以该值为目标训练一个新的弱分类器进行拟合并计算出该弱分类器的权重,最终实现对模型的更新。
2.3.5 极端梯度提升XGBoost
XGBoost[24]是在GBDT算法的基础上改进的模型,其目标函数为:
(13)
其中:l为平方损失函数;yi为真实值;Ft-1(xi)为现有的t-1棵树最优解;ft(xi)为第t棵树预测的残差值;Ω(ft)为树的复杂度。
XGBoost有特定的准则来选取最优分裂。通过将预测值代入到损失函数中可求得损失函数的最小值为:
(14)
其中:Gj为叶子节点j所包含样本的一阶偏导数累加之和;Hj为叶子节点j所包含样本的二阶偏导数累加之和;λ为正则化项的系数;γ为一个叶子节点的复杂度;T为叶子节点的数量。
计算出分裂前、后损失函数的差值为:
(15)
XGBoost采用最大化该差值作为准则来进行决策树的构建,通过遍历全部特征的所有取值,寻找使得损失函数前、后相差最大时对应的分裂方式。
2.3.6 逆向传播神经网络BPNN
BPNN[25]是一种多层前馈神经网络,信息可以在神经网络中交替地向前、向后传播。
对每个样本,BPNN执行以下操作:将输入样本提供给输入层神经元,逐层将信号前传,直到产生输入层的结果;计算输出层的误差,再将误差逆向传播至隐层神经元;最后根据隐层神经元的误差来对连接权重和阈值进行调整。该迭代过程循环进行,直到达到某些停止条件为止。
本文采用4层神经网络结构,其中输入层的特征参数为n、T、V、p,输出层为Pin,b1和b2为偏置参数,G()函数为激活函数。
BPNN结构如图4所示。
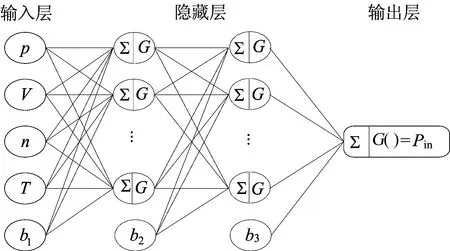
图4 BPNN结构
由于算法模型的差异,模型的超参数也不相同。6种模型的超参数与取值见表2所列,其中所有的超参数均为调参之后的结果。
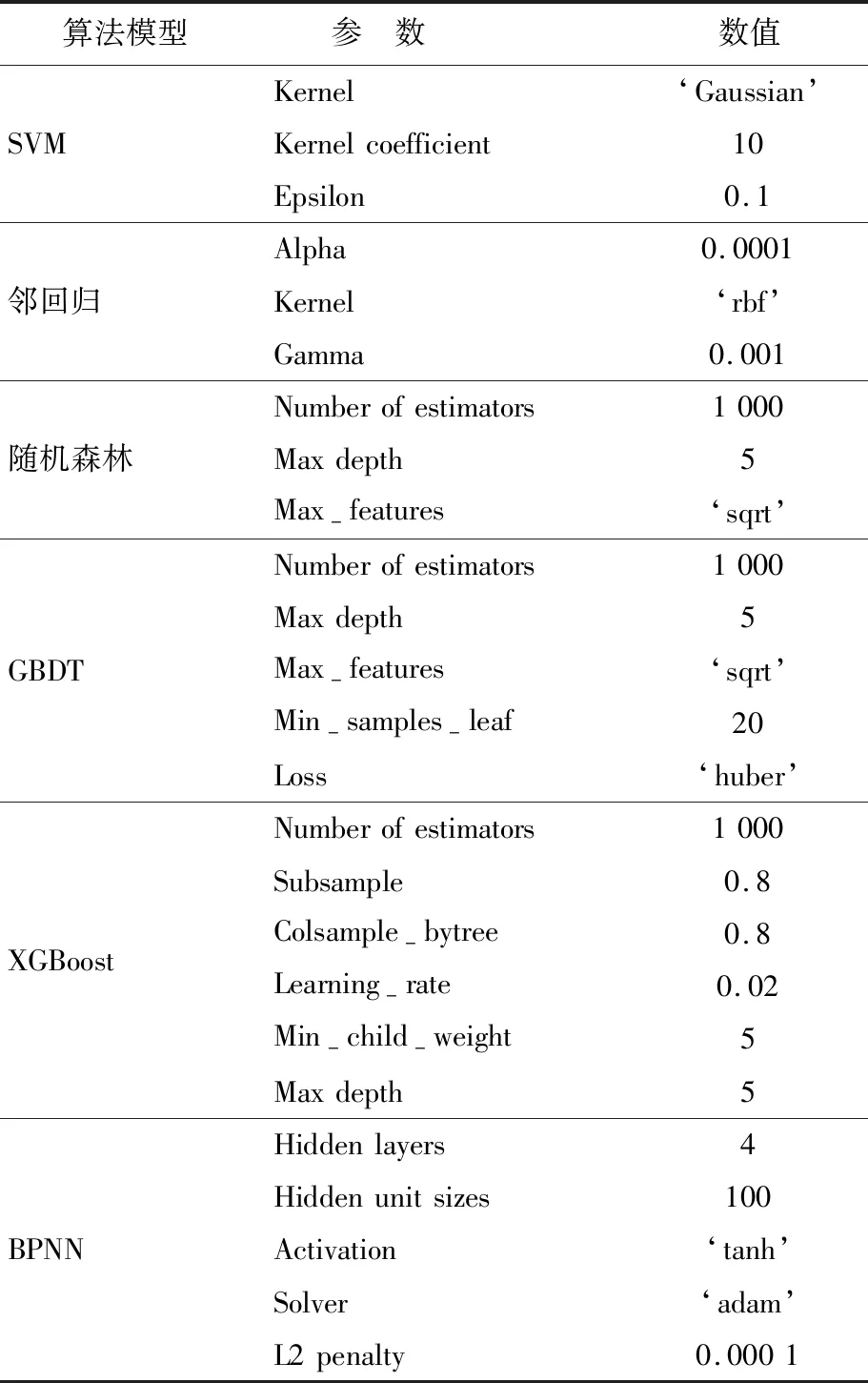
表2 模型超参数
2.4 模型评估
2.4.1 交叉验证
机器学习建模过程是将数据划分成训练集和测试集。测试集是与训练集独立的数据,完全不参与训练,只用于最终的模型评估。模型在验证数据中的评估和超参数选取常用K折交叉验证法。本文采用5折交叉验证,如图5所示。
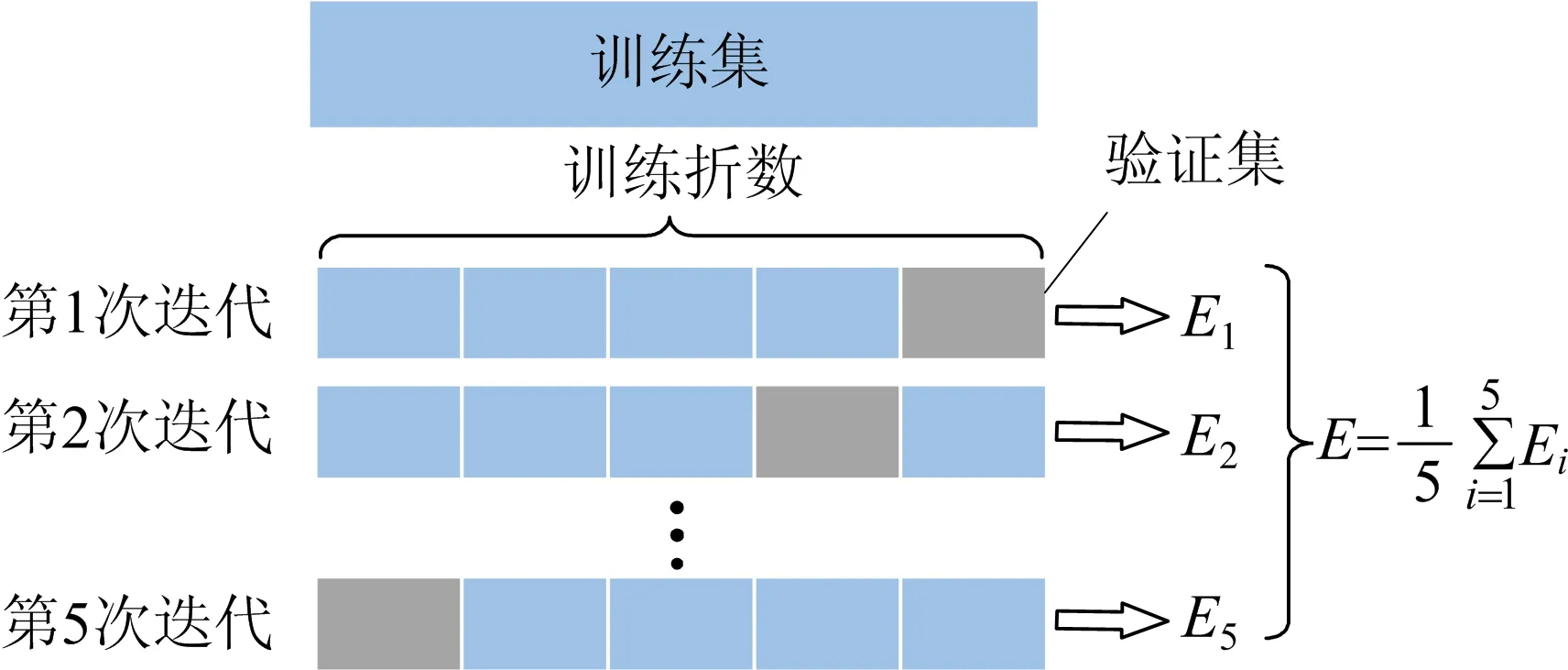
图5 K-Fold 5折交叉验证
原始数据被分成K组,依次将每组数据作为验证集、其余K-1组数据作为训练集,最终将K个模型的误差加权平均得到交叉验证误差。
2.4.2 评价函数
评价函数反映了任务需求,在对比不同模型的性能时,使用不同的性能度量会导致不同的评判结果。评估学习器f的性能,需要将学习器预测结果f(x)与真实标签y进行比较。
回归任务最常用的性能度量是均方根误差(root mean squared error,RMSE),即
(16)
在本文的数据集中,可能会存在个别偏离程度非常大的离群点,即使少量的离群点也会让RMSE指标变差。因此选择鲁棒性更好的平均绝对百分比误差(mean absolute percentage error,MAPE)为:
(17)
MAPE不仅考虑预测值与真实值的误差,还考虑了误差与真实值之间的比例。相较于RMSE,MAPE相当于将每个点的误差进行了归一化,降低了个别离群点带来的绝对误差的影响。
当利用数据拟合一个回归模型,还需要度量模型对观测值拟合的好坏,决定系数R2为度量模型拟合优度的一个指标,即
(18)
本文采用RMSE、MAPE和决定系数3种评价方法共同作为衡量模型性能的指标。
3 结果与讨论
对上述6种能耗预测模型性能进行对比分析,结果见表3所列。

表3 算法模型性能评价指标值
最好的能耗预测模型应该有最小的ERMS和PMAE以及最大的R2。从表3可以看出:XGBoost模型在测试集上具有最小的ERMS(76.252)、最小的PMAE(3.407)和最大的R2(0.988);GBDT模型在3个指标上的表现仅次于XGBoost模型;SVM模型的泛化能力较好,训练集与测试集的误差最小;岭回归模型在训练集和测试集上的表现较好;BPNN在测试集上的ERMS和PMAE均较差,比XGBoost模型高3倍左右;随机森林方法在测试集上的误差最大。此外,XGBoost模型训练时长为16.38 s,仅次于SVM和岭回归模型。各种算法训练时长见表4所列。
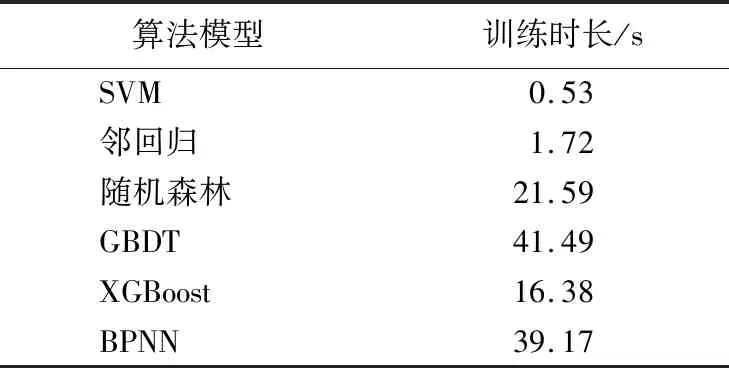
表4 交叉验证的算法训练时长
综合考虑能耗预测模型精度和训练时长,XGBoost模型是适用于变速变排量液压驱动单元能耗预测的机器学习模型。
然而,采用独立模型对原始数据进行训练容易发生过拟合。而多种模型有效堆叠的集成学习方法(stacking)可以集成不同算法的优势,从而在多个维度去优化模型,提高了能耗模型的泛化能力和鲁棒性。stacking是一种分层模型集成框架。以2层为例,第1层由多个基学习器组成,其输入为原始训练集,第2层的模型则是以第1层基学习器的输出作为训练集进行再训练,从而得到完整的stacking模型。鉴于6个模型在训练集和测试集上的表现,将stacking的第1层的基学习器由SVM、GBDT、随机森林、BPNN和XGBoost模型组成,第2层的元模型为岭回归。从表3可以看出,stacking模型在测试集上的表现和泛化能力均好于所有独立模型。
4 结 论
本文基于机器学习方法建立了7种变速变排量液压驱动单元能耗预测模型,即SVM、岭回归、随机森林、GBDT、XGBoost、BPNN和堆叠的集成学习模型,通过模型评估得到以下结论:
(1) 在建立的6种独立的能耗预测模型中,XGBoost模型具有最好的预测性能,且预测精度明显优于其他机器学习模型;GBDT模型的表现性能仅次于XGBoost模型;岭回归和SVM模型表现一般;BPNN模型的预测性能比XGBoost模型差了3倍左右,且表现性能差异较大;随机森林模型在测试集上的表现最差。XGBoost模型在变速变排量液压泵驱动单元的能耗预测上具有优势。
(2) 多种模型有效堆叠(stacking)的集成学习方法融合了多个模型的优点,不仅在测试集上有着最好的效果,而且提高了模型的泛化能力,使模型具有了更好的稳定性。
(3) 虽然本文通过机器学习方法解决了变速变排量液压驱动单元的能耗建模问题,但由于采集到的数据量有限,样本的特征数较少。在后续的工作中将考虑丰富数据量和特征维度,并考虑运用深度学习的方法,进行更深层次的能耗建模,以便其能应用于变速变排量液压驱动单元的技能控制策略中。
