基于注意力机制的视觉位置识别方法
2022-05-25戴天虹杨晓云宋洁绮
戴天虹 杨晓云 宋洁绮





摘要:针对现有的视觉位置识别方法在图像外观变化和视角变化时准确性和鲁棒性表现不佳的问题,提出了一个与注意力机制结合的视觉位置识别方法。首先,采用在大型位置数据集上预训练的卷积神经网络HybridNet提取特征。然后,运用上下文注意力机制对图像不同区域分配权重值,构建基于多层卷积特征的注意力掩码。最后,将掩码与卷积特征结合,构建融合注意力机制的图像特征描述符,从而提高特征的鲁棒性。在两个典型位置识别数据集上做测试实验,结果表明结合注意力机制的方法可以有效区分图像中与位置识别有关的区域和无关的区域,提高在外观变化和视角变化场景中识别的准确性和鲁棒性。
关键词:图像处理;位置识别;注意力机制;卷积神经网络;深度学习
DOI:10.15938/j.jhust.2022.02.008
中图分类号: TP391.41
文献标志码: A
文章编号: 1007-2683(2022)02-0063-06
Visual Place Recognition Method Based on Attention Mechanism
DAI Tian-hong,YANG Xiao-yun,SONG Jie-qi
(School of Mechanical and Electrical Engineering, Northeast Forestry University, Harbin Heilongjiang 150040, China)
Abstract:Aiming at the problem of poor accuracy and robustness of the existing visual place recognition methods when the image appearance changes and the viewing angle changes, a visual place recognition method combined with the attention mechanism is proposed. Firstly, we use the convolutional neural network HybridNet pre-trained on a large location dataset to extract features. Then, we use the context attention mechanism to assign weight values to different regions of the image to construct an attention mask based on multi-layer convolution features. Finally, we combine the mask with the convolution feature to construct the image feature descriptor fused with the attention mechanism so as to improve the robustness of the feature. Testing experiments on two typical place recognition datasets show that the method combined with the attention mechanism can effectively distinguish between the regions related to place recognition and the unrelated regions in the image, and it can improve the accuracy and robustness of recognition in scenes with changes in appearance and viewpoints.
Keywords:image processing; place recognition; attention mechanism; convolutional neural network; deep learning
0引言
視觉位置识别技术(visual place recognition,VPR)主要是指采用图像识别技术,判断当前图像是否是之前曾访问过的场景[1],目前广泛应用于机器人同步定位与构图(simultaneous localization and mapping, SLAM)的闭环检测和重定位环节中,可以消除机器人系统运动过程中的累计误差。
视觉位置识别算法主要包括对当前图像和曾经访问过的图像提取特征,对提取到的特征进行编码,计算当前图像和曾经访问过的图像之间的相似度,确定是否匹配等步骤。早期的视觉位置识别技术都是对图片提取手工特征描述符实现,比如局部特征SURF(speeded up robust features)[2]、SIFT(scale-invariant feature transform)[3]、ORB(oriented FAST and rotated BRIEF)[4],全局特征Gist[5]等,但是手工设计的特征在长时间的大型场景识别中无法做出较好的性能表现。近年来,由于深度学习技术在计算机视觉等领域得到了广泛的应用和发展[6-11],越来越多的研究人员开始通过卷积神经网络(convolutional neural network, CNN)提取特征来实现视觉位置识别。
文[12]采用在场景数据集上预训练的CNN模型进行位置识别,实验证明在光照发生变化的场景下CNN提取的特征显著优于传统人工设计的特征。文[13]利用CNN在外观变化和视角变化的数据集分析不同层提取的特征在位置识别中的性能表现,实验证明中间层和高层特征的性能表现较好。文[14]和文[15]针对位置识别任务分别设计训练了专用的CNN。但是,直接利用CNN提取的全局特征在视角变化的数据集上性能表现不佳,因为与位置识别技术相关的视觉线索通常不会均匀地分布在整幅图像中,图像中与位置识别无关的线索会影响识别的准确性,比如图像中的一些动态物体,如汽车、行人等。因此,文[16]、文[17]和文[18]提出识别图像中的显著区域,证明直接关注图像中的区域特征可以有效提高视角变化时的识别鲁棒性,但是这些方法都是通过生成局部区域探测器来检测图像中的地标性特征,容易忽略图像中的隐藏信息。
注意力来源于认知科学,指人类视觉在学习图像时,能快速判断并集中于与任务有关的重点目标区域,而忽略无关区域的过程。与深度学习结合的注意力机制一般指学习训练一个新的网络,通过学习图像中哪些区域对识别任务贡献大,哪些区域与识别任务无关,对图像中不同区域建立响应机制,从而达到有效识别的目的。
另外,通过CNN对图像提取特征,低层次的卷积特征图侧重于图像边缘、轮廓等信息,而高层次的卷积特征图含有较丰富语义信息。如果仅针对某个卷积层学习训练注意力,则可能造成图像信息丢失或不全。
综上所述,本文提出利用一个多尺度卷积滤波器建立上下文注意力机制,通过提取图像中隐藏信息,生成预测图像各区域响应的注意力掩码,并且针对不同卷积层提取特征的差异性,融合从多层卷积特征学习到的注意力掩码,最后将掩码直接与卷积特征加权,相比其他采用卷积神经网络的方法,可以生成更具鲁棒性的特征表示。
1基于注意力机制的视觉位置识别方法
融合注意力机制的视觉位置识别方法流程如图1所示。首先使用HybridNet[15]提取图像卷积特征,经注意力机制处理生成图像最终表示,最后采用余弦距离判断查询图像和参考图像之间是否发生匹配。
1.1卷积神经网络
HybridNet网络[15]模型结构如图2所示,输入图像大小为227×227×3,Conv、ReLu、Norm、Pool、FC分别代表卷积层、激活层、归一化层、最大池化层和全连接层。第一个卷积层的卷积核大小为11×11,第二个卷积层的卷积核大小为5×5,第三个到第六个卷积层的卷积核大小均为3×3。该网络的初始化是通过AlexNet网络[19]参数实现,然后在大型位置识别数据集SPED上训练。
SPED数据集收集来自世界各地2543台相机采集的总共大约250万张图片,分别在2014年2月和2014年8月2个不同的季节每隔半小时拍摄。相比其他用于场景训练的数据集,涵盖了更多的户外场景,比如城市建筑物、郊外森林等,并且每个位置的外观条件变化非常明显,同一个位置的数据由一年中不同的季节和一天中不同的时间点采集。
1.2上下文注意力机制
HybridNet提取到第l层的卷积特征用X表示,X∈R代表特征图中W×H位置一组C维向量。受启发于文[20],如图3所示,首先对提取的特征图Xlx使用3种不同大小的卷积滤波器提取上下文信息,尺寸分别为3×3,5×5,7×7,每个滤波器产生一个特征图,比如共有32个3×3大小的卷积滤波器,则产生32个W×H大小的特征图。按照通道方向串联所有的特征图形成X。
为了计算上下文注意力掩码,對X做CNN参数化处理,在X后面使用一个单通道输出的卷积层:
1.3多层注意力融合
1.4多分类训练
1.5相似度计算
2实验结果分析
在两个公开的位置识别数据集上进行测试实验。Synthesized Nordland数据集[22]包含摄像机在4个不同季节捕捉到的同一火车行驶轨迹的沿途风景图像,本文选取了夏季和冬季,含有明显的季节条件变化。Gardens Point数据集[13]在昆士兰大学校园内采集,包含2个白天的子数据集分别在人行道的左边和右边拍摄,还有1个晚上的数据集在人行道的右边采集,本文采用了白天左边拍摄和晚上右边拍摄2个子集,图像存在明显的视角和光照条件变化。
首先采用精确率-召回率曲线以及曲线与坐标轴围成的面积AUC(area under the curve)评价算法性能,AUC越接近于1,则算法性能越好。精确率(precision, P)和召回率(recall, R)计算公式如下:
将本文提出的算法与AlexNet[19]、AMOSNet[15]、HybridNet、Region-VLAD[18]4个算法比较。AlexNet网络是目前应用最广泛的卷积神经网络之一,位置识别算法的特征提取部分也大多采用该网络完成。AMOSNet网络结构与HybridNet相同,但是没有初始化过程,全部网络参数均是直接在SPED数据集上训练得到。Region-VLAD方法使用卷积神经网络提取特征,然后识别图像显著区域构建视觉词典,在识别中拥有优秀的准确性和实时性表现。本文还与仅在Conv5层使用注意力的方法(one layer-attention)做了比较。
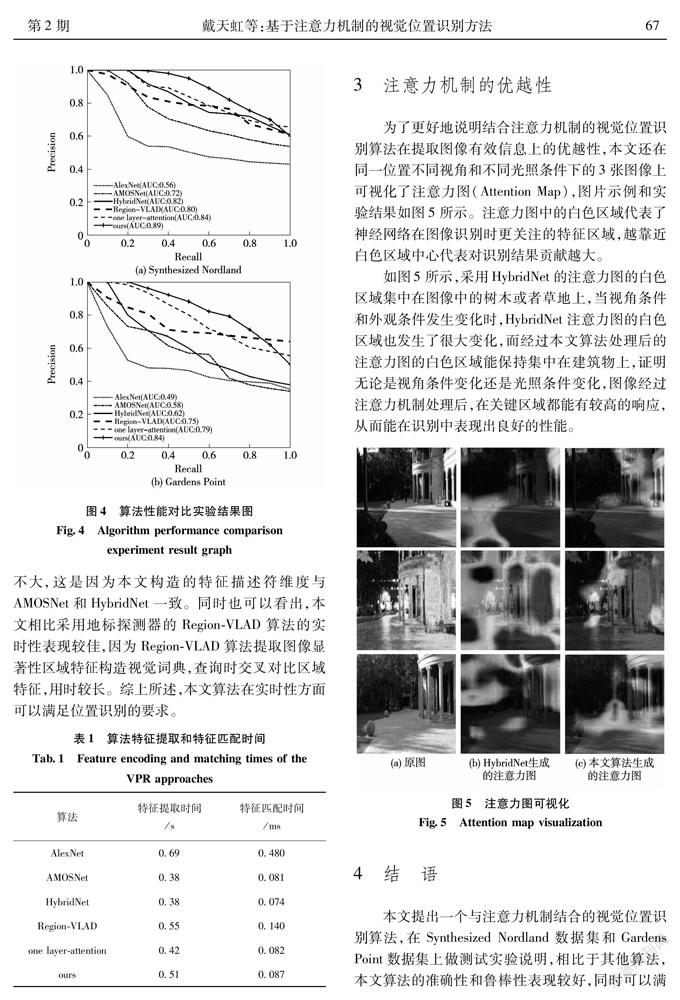
如图4所示,在季节条件变化明显的Nordland数据集上,AlexNet、AMOSNet、HybridNet 和Region-VLAD算法的AUC分别为0.56、0.72、0.82、0.80,而本文所提算法AUC为0.89,说明本文所提算法在外观条件变化时能优于其他4类算法,取得较好的识别效果。在含有视角变化和外观条件变化的Gardens Point数据集上,AlexNet、AMOSNet、 HybridNet和Region-VLAD算法的准确率都有所下降,AUC分别为0.49、0.58、0.62、0.75,而本文所提算法准确率变化较小,AUC变化也较小,说明本文所提算法的鲁棒性较好,克服了光照条件和视角变化带来的影响。本文使用多层注意力的识别方法相比单层注意力方法的AUC有一定提高,说明多层注意力的有效性。
视觉位置识别中,算法实时性也是需要考虑的一个重要因素。本文采用单张图像特征提取和特征匹配平均用时作为评价算法实时性的依据。具体结果如表1所示,可以看出,由本文算法完成特征提取用时相比基础的卷积神经网络AMOSNet和HybridNet较长,这是因为引入注意力机制后网络层数加深。特征匹配用时相比AMOSNet和HybridNet差别不大,这是因为本文构造的特征描述符维度与AMOSNet和HybridNet一致。同时也可以看出,本文相比采用地标探测器的Region-VLAD算法的实时性表现较佳,因为Region-VLAD算法提取图像显著性区域特征构造视觉词典,查询时交叉对比区域特征,用时较长。综上所述,本文算法在实时性方面可以满足位置识别的要求。
3注意力机制的优越性
为了更好地说明结合注意力机制的视觉位置识别算法在提取图像有效信息上的优越性,本文还在同一位置不同视角和不同光照条件下的3张图像上可视化了注意力图(Attention Map),图片示例和实验结果如图5所示。注意力图中的白色区域代表了神经网络在图像识别时更关注的特征区域,越靠近白色区域中心代表对识别结果贡献越大。
如图5所示,采用HybridNet的注意力图的白色区域集中在图像中的树木或者草地上,当视角条件和外观条件发生变化时,HybridNet注意力图的白色区域也发生了很大变化,而经过本文算法处理后的注意力图的白色区域能保持集中在建筑物上,证明无论是视角条件变化还是光照条件变化,图像经过注意力机制处理后,在关键区域都能有较高的响应,从而能在识别中表现出良好的性能。
4结语
本文提出一个与注意力机制结合的视觉位置识别算法,在Synthesized Nordland数据集和Gardens Point数据集上做测试实验说明,相比于其他算法,本文算法的准确性和鲁棒性表现较好,同时可以满足实时性要求。通过Attention Map可视化,融合注意力机制的位置识别方法能对图片中的有用区域产生较高的响应,并且当存在外观条件和视角条件变化时,高响应区域几乎没有发生改变,从而能保证识别的鲁棒性。
参 考 文 献:
[1]LOWRY S, SUNDERHAUF N, NEWMAN P, et al. Visual Place Recognition: A Survey[J]. Robotics, IEEE Transactions on, 2016, 32(1): 1.
[2]BAY H, TUYTELAARS T, GOOL L V. SURF: Speeded up robust features[J]. Computer Vision-ECCV, 2006, 3951: 404.
[3]LOWE D. Distinctive Image Features from Scale-Invariant Keypoints[J]. International Journal of Computer Vision, 2004, 20: 91.
[4]RUBLEE E, RABAUD V, KONOLIGE K, et al. ORB: An efficient alternative to SIFT or SURF[C]//Computer Vision. IEEE, 2011: 2564.
[5]OLIVA A. Building the Gist of a Scene: the Role of Global Image Features in Recognition[J]. Progress in Brain Research, 2006, 155(2): 23.
[6]BENGIO Y, COURVILLE A, VINCENT P. Representation Learning: A Review and New Perspectives[J]. IEEE Transactions on Pattern Analysis&Machine Intelligence, 2012, 35(8): 1798.
[7]RAZAVIAN A S, SULLIVAN J, CARLSSON S, et al. Visual Instance Retrieval with Deep Convolutional Networks[J]. Ite Transactions on Media Technology & Applications, 2014, 4.
[8]BABENKO A, SLESAREV A, CHIGORIN A, et al. Neural Codes for Image Retrieval[C]//European Conference on Computer Vision. Springer International Publishing, 2014: 584.
[9]WAN J, WANG D, HOI S C H, et al. Deep Learning for Content-Based Image Retrieval: A Comprehensive Study[C]//Acm International Conference on Multimedia. ACM, 2014: 157.
[10]丁博, 伊明. 基于卷積神经网络的三维CAD模型分类[J].哈尔滨理工大学学报,2020,25(1):66.
DING Bo, YI Ming. 3D CAD model classification based on Convolutional Neural Network[J]. Journal of Harbin University of Science and Technology, 2020, 25(1): 66.
[11]于舒春,佟小雨.基于CNN特征提取的粒子滤波视频跟踪算法研究[J].哈尔滨理工大学学报,2020,25(4):78.
YU Shuchun, TONG Xiaoyu. Research on Particle Filter Video Tracking Algorithms Based on CNN Feature Extraction[J]. Journal of Harbin University of Science and Technology, 2020, 25(1):66.
[12]HOU Y, ZHANG H, ZHOU S. Convolutional Neural Networkbased Image Representation for Visual Loop Closure Detection[C]//IEEE International Conference on Information & Automation, 2015: 2238.
[13]SUNDERHAUF N, DAYOUB F, SHIRAZI S, et al. On the Performance of ConvNet Features for Place Recognition[C]//2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2015: 4297.
[14]MERRILL N, HUANG G. Lightweight Unsupervised Deep Loop Closure[C]//Robotics: Science and Systems, 2018, 40(1): 223.
[15]CHEN Z, JACOBSON A, SUNDERHAUF N, et al. Deep Learning Features at Scale for Visual Place Recognition[C]//IEEE International Conference on Robotics and Automation (ICRA), 2017: 3223.
[16]SUNDERHAUF N, SHIRAZI S, JACOBSON A, et al. Place Recognition with ConvNet Landmarks: Viewpointrobust, Condition-robust, Training-free[C]//Robotics: Science and Systems, 2015.
[17]CHEN Z, MAFFRA F, SA I, et al. Only Look once, Mining Distinctive Landmarks from ConvNet for Visual Place Recognition[C]//IEEE/RSJ International Conference on Intelligent Robots & Systems. IEEE, 2017: 9.
[18]KHALIQ A, EHSAN S, CHEN Z, et al. A Holistic Visual Place Recognition Approach Using Lightweight CNNs for Significant ViewPoint and Appearance Changes[J]. IEEE Transactions on Robotics, 2019, PP(99): 1.
[19]KRIAHEVSKY A, SUTSKEVER I, HINTON G. ImageNet Classification with Deep Convolutional Neural Networks[C]//NIPS. Curran Associates Inc, 2012: 1097.
[20]WANG T T, ZHANG L H, WANG S, et al. Detect Globally, Refine Locally: A Novel Approach to Saliency Detection[C]//Conference on Computer Vision and Pattern Recognition (CVPR), 2018: 3127.
[21]ZHOU B, LAPEDRIZA A, KHOSLA A, et al. Places: A 10 Million Image Database for Scene Recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2018: 1.
[22]NEUBERT P, SUNDERHAUF N, PROTZEL P. Superpixel-based Appearance Change Prediction for Long-Term Navigation Across Seasons[J]. Robotics and Autonomous Systems, 2015, 69(1): 15.
(編辑:温泽宇)
