基于极限梯度爬升算法与支持向量回归算法变权组合模型致密油的采收率预测
2022-05-19张金水田冷黄诗慧董鹏举
张金水, 田冷, 黄诗慧, 董鹏举
(中国石油大学(北京)石油工程学院, 北京 102200)
非常规油气藏作为中外日益备受重视的油气资源,各国对致密油藏等非常规油气藏都加大了勘探开发力度,而可采储量是油气田开发动态分析的基础,可评估油气藏开采潜能大小,不同采出程度可表征当前油气田的不同开发阶段,中后期可根据采收率预测的变化对生产措施实时调控,更好地适应油藏的开采,为油田的进一步提高采收率提供战略性的部署。以中国某致密油藏为例,储层岩性和孔隙结构复杂、渗透率低,其储层为裂缝—孔隙双重介质,裂缝所占的储集空间远小于基岩的储集空间,渗流特征难以表征,可采储量影响因素复杂多变,导致难以准确计算储层压裂后采收率,因此需要建立一种动态监测可反映出该致密油藏压裂水平井开发的生产动态分析和采收率预测方法,一是可以评估当前储层改造程度[1],二是可实时获取施工参数对产量的直接影响,便于动态指导施工。
以往对致密油藏的研究表明,对致密油的采收率预测可分为宏观平衡法和微观实验法。宏观平衡法是根据油藏的类型,进行物质平衡分析,从宏观上来预测油藏的可采储量,孙贺东等[2]建立幂函数形式的高压、超高压气藏物质平衡方程,分析了视储层压力衰竭程度和采出程度对储量计算可靠性的影响;毕海滨等[3]以物质平衡时间法来评估试采阶段出现边界流动特征的单井可采储量。微观实验法是根据岩心渗流实验、试井解释、水驱特征曲线的变化进程等来进行微观储量分析。Clarkson等[4]研究了经典速率瞬变技术(流动状态分析、类型曲线方法和模拟)在致密油储层分析的应用;Cook[5]以递减曲线回归法完成了三叉形地层石油资源的评估;耿站立等[6]将具有唯一解的常用水驱特征曲线优选问题转化为广适水驱特征曲线与丙型、丁型曲线联合求取唯一解问题,提高了不同水驱方式下采收率预测精度。但致密油储层渗透率低、单井产能低的特性决定了其开发大多伴随着压裂施工改造过程,对于多因素分析的致密储层压裂改造后的采收率预测模型研究尚有不足,而微观实验法所需要的成本高昂且步骤复杂,易受到外界因素干扰。
人工智能作为一种新兴的热门领域,因其同时兼备大数据分析与精细模拟的优势,被广泛应用于图像音色识别[7]、无人系统驾驶[8-9]以及智能计算芯片[10]等,在各个行业领域中不断得到传播和发展[11]。近年来,机器学习被广泛应用于石油行业,如储层酸压性能预测[12]、压裂缝网表征[13]、裂缝处理[14]、注采井间连通性识别[15]等,机器学习可以有效承接油气勘探形成的海量地质信息、井信息以及生产数据信息,支撑精细油气藏描述模型的建立,为致密油藏的采收率实时、精准预测提供了可能。李磊等[16]在算法研究领域,运用加速遗传组合算法,根据最小二乘原理提出了最优离合点,优化了以往以平均数群决策的综合意愿不足的缺点;段友祥等[17]利用多种弱分类器组合算法进行岩性分类建立模型来预测储层属性参数,从而计算油藏采收率,为融合算法在石油行业的发展提供了参考。但这类方法难以处理高维复杂数据、提取数据之间的深层关联信息,在特征识别方面存在一定的不足。
为此,在多种弱分类器组合算法基础之上提出一种新的融合算法,将极限梯度爬升算法(extreme gradient boosting algorithm,XGBoost)与支持向量回归(support vector regression algorithm,SVR)算法以残差自适应性方式赋值单模型加权系数组合,建立致密油储层压裂后采收率预测模型。因机器学习中SVR算法可有效降低泛化误差和计算复杂度,且具备高维度映射预测的优势,XGBoost算法可解释性较强,多个决策树模型可减小误差相关度,因此XGBoost-SVR模型可以有效地利用单模型的优势所在,同时还能减小SVR单模型对核函数的敏感依赖大、XGBoost单模型数据集存在空间复杂度过高等结构和功能上的缺陷。在模型中借鉴了残差进化算法思想,不断基于单模型残差误差分析更新模型的结构参数和融合模型的加权系数[18-19],实现了不同模型间加权系数的最优组合。从地质、流体和工程三方面分析影响采收率的相关因素,原始数据集经过数据预处理之后导入融合模型,通过特征识别来确定各影响因素排序,再经过4折交叉验证来验证采收率的预测准确度,可通过实际工程数据和生产信息来实时反映采收率的变化指标,更有效地实现现场施工参数的动态调控,基于生产大数据可有效得模拟地质构造背景,反映真实的地下储层改造情况,实现模型与实际工程间的仿真交互环境,实现对致密油的采收率动态预测。
1 研究方法
1.1 XGBoost原理
XGBoost算法[20]是一种集成的并行决策树模型,是Boosting算法的一种结构拓展和优化,由多个决策树弱分类器基于熵的组合形成一种具有预测性能的强分类器,在损失函数推导过程中,使用了一阶导数gi和二阶导数hi(对损失函数做二阶泰勒展开求解函数),经过多个迭代生成M轮CART回归树,并在目标函数之外加入正则项整体求最优解,用以权衡目标函数的下降和模型复杂程度,进而准确求取目标参数。
学习多颗分类回归树的梯度加法模型,预测结果等于所有单决策树的得分总和。其理论公式可表示为
(1)
定义目标函数,即损失函数和正则项,可分别表示为
(2)
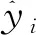
图1中,所有弱分类器的结果相加等于预测值,然后下一个弱分类器气拟合误差函数对预测值的残差。

y为单棵决策树的预测目标值;fk(x)为第k棵决策树所输出的预测值图1 XGBoost算法流程图Fig.1 Flow chart of XGBoost algorithm
再将所定义的目标函数进行组合,并进行二阶泰勒公式展开,求得最终目标函数为

(3)

1.2 SVR原理
SVR是一种划分超平面方法,定义为特征空间上的间隔最大的线性分类器,即基本思想是实现多样本数据点之间的间隔最大化原则,最终可转化为一个凸二次规划问题的求解[21]。SVR算法影响因素与预测数据之间的非线性拟合函数f(x,w)可表示为
f(x,w)=wφ(x)+b=(w,φ)+b
(4)
式(4)中:w为权值矢量;φ(x)为非线性映射,生成和输入向量x同维的向量;b为偏差;(w,φ)为w和φ的内积。
SVR也可用于非线性数据集的分类或回归预测,存在数据样本为线性不可分数据集时,提高空间维度来映射数据点,可引入适当的核函数向高维空间进行映射,通过内积函数从原始空间映射更高维空间,分析输入因素与目标序列的特征关系组合,来实现非线性样本分类或回归预测。
核函数的最佳选择是SVR模型最优化问题的关键,在一定误差允许内,预估目标输出,同时最小化w模型参数,使其具有更强的泛化能力。优化目标等价于一个最基本的凸二次规划问题,可表示为
(5)
(6)
式(6)中:ε为规定误差;yi为目标值。
1.3 Pearson系数分析
Pearson相关系数是用来衡量定距不同因素变量之间的相互关联程度。皮尔逊相关系数r表征的相互关联程度为-1~1,系数越高,则不同变量之间的相互关联程度越高。在分析多因素变量之间的影响相关度方面,更能反映出因素之间的冗余特征重合度,可实现多数据集的因素交互分析。
(7)

1.4 变权组合预测模型
构建组合预测模型,关键参数是各单模型权重因子的赋值,采取的是残差赋权法,基于双模型预测参数与标准值的残差分析,不断更新其模型的适应度,实现模型间的有效交互模式,达到准确预测回归变量的目标。以XGBoost和SVR单模型预测数据与真实数据之间的残差来确定组合模型的权重系数,它融合各个模型的优势与特点,利用最优化数学模型来求出各模型组合赋权系数,来构造基于残差的自适应变权组合模型来进一步提高致密油的采收率预测精确度。
(8)
式(8)中:n为预测模型的总个数;ωi(t′)为t′时刻第i个模型的权重;εt′(t′)为t′时刻第i个模型的预测误差平方和;f(xt′)为t′时刻融合模型的预测值;fi(xt′)为t′时刻第i个模型的预测值。
2 数据预处理
2.1 数据选择
该致密油藏为裂缝—孔隙型双重介质储层,存在储层流体渗流特征复杂、启动压力梯度高等开发难点,不能准确得确定采收率的影响因素。原始数据集从地质因素、储层因素和工程因素三方面来选取采收率影响参数,岩石储层的物性参数对油气藏的采收率有直接的影响关系,该地区储层间的岩石孔隙度决定了油气资源的富集度,有效厚度、含油饱和度等因素直接影响了油层的采出程度,工程改造参数(如加砂量与支撑剂浓度等)都会直接影响人工裂缝的导流能力,压裂簇数则决定了压裂井井筒的泄流面积,采收率标定按油藏数值模拟来表征相应参数。将收集后的数据进行归类整理,剔除与采收率无关或偏差较大的数据,留下与采收率影响因素相符的数据,部分数据集如表1所示。

表1 致密油部分影响因素原始参数集Table 1 Original parameter set of some influencing factors of tight oil
2.2 数据清洗
2.2.1 离群点处理
选取的生产数据离群点一般分为“真异常”和“伪异常”两种,前者是由于各种地质因素、特定工程因素导致的数据量变化,比如酸化或者压裂之后,地层渗透率明显增高,产量规模大幅度提高,这些都是基于油藏正常状态,而不是数据本身的异常;而后者是地质条件如若未发生改变,数据分布明显不合理,存在极大的统计误差,排除因地下油藏条件变异反应,即为“伪异常”。可以根据该离群点是否存在工程措施、地下储层是否发生明显突变来判断真伪异常,再将整理好的采收率相关数据集进行二次处理,对空白字段、无意义数据进行删除,来确保采收率数据的有效性。
由图2可知,渗透率、温度等参数存在异常值和离群点,如正常温度为80~110 ℃,而统计温度存在65.23、67.25 ℃异常点;渗透率整体范围低于5 mD,而统计渗透率存在8.56 mD异常点,可基于井位初步判断其地下条件,可根据该井附近的地层中温来进行温度和渗透率的校正。

图2 数据异常值分析图Fig.2 Data outlier analysis diagram
2.2.2 缺失值处理
现场采集致密油采收率影响因素数据时,油井的地震、测井、压裂、生产等数据因钻井、井下作业及工程因素,会存在一定记录缺失和字段信息缺失等情况,其对数据分析和模型精度会有较大的影响,导致最终采收率预测结果带有不确定性,所以有必要对采集的现场数据进行缺失值处理。
在此对数据采取基于统计学的填充方法,均值填充,取附近地质储层数据相近的三口井的均值作为填充数据,每一个影响因素的填补都需要考虑其本身的工程背景含义,要在排除“真异常”点基础上综合补充缺失数据集。
2.3 特征相关性分析
首先计算采收率与各特征影响因素的皮尔森相关系数,结果如表2所示,这可以在一定程度上判断特征对于预测的作用。相关系数大于0.85的特征量可以去除,保留其一即可,避免造成数据冗余。

表2 Pearson相关系数Table 2 Pearson correlation coefficient
Pearson相关性分析可以有效提高变量特征与采收率因素之间的可解释性,增强对采收率和影响因素之间的理解。经过分析,如图3所示,总液量与总加砂量、每簇加液量与每簇加砂量两因素之间相关系数大于0.75,两变量因素之间特征重合度过高,会降低主控因素对采收率的影响因子排序。

图3 Pearson相关系数图Fig.3 Pearson correlation coefficient diagram
因总液量与总加砂量、每簇加液量与每簇加砂量因素间Pearson系数属于极强相关,存在特征重叠冗余现象,因此需筛选因素特征。如图4、图5所示,根据特征因素吻合度差异选择总加砂量与每簇加液量即可。

图4 总加砂量、总液量对比分析Fig.4 Comparative analysis of total sand addition and total liquid volume

图5 毎簇加砂量、毎簇加液量对比分析Fig.5 Comparative analysis of sand addition and liquid addition per cluster
3 模型构建与调试
3.1 组合预测模型构建流程
图6为XGBoost-SVR模型流程图,具体步骤如下。

图6 XGBoost-SVR模型流程图Fig.6 Flow chart of XGBoost-SVR model
步骤1根据测井数据、岩心分析、地震以及压裂数据等采集目标区块采收率影响因素原始数据集,构造模型训练所支撑的数据集。
步骤2对原始采收率数据集进行必要的预处理分析,重点包括真伪异常分析、数据清洗、判断数据准确性等,在缺失值部分采用属性相近井资料数据进行均值补充。
步骤3各类型数据进行了筛选与整理,构建单个机器学习模型,输入数据按训练集∶测试集=7∶3进行随机数据划分后,以此为基础分别训练SVR单模型和XGBoost单模型,不断调试单模型超参数,达到最优之后保存各个训练模型。以训练好的模型来预测测试集数据,最终得到SVR与XGBoost单模型预测结果。
步骤4对单模型预测值进行回归分析,与实际值偏差满足一定条件前提下,可进行组合模型构建。
步骤5利用已训练好的单模型来基于残差分析赋值各个单模型权重比例,不断更新迭代其权重系数,最终可得到组合模型最终预测结果。通过二者基于残差自适应变权组合形成的模型来进行致密油的采收率预测。
步骤6模型评价分析,根据模型评价指标比较模型预测能力,分析模型预测效果。
3.2 单模型调参
以采集的致密油藏采收率以及影响采收率的13种因素共122组生产数据集,作为样本库,其中随机97组数据作为训练集,剩余25组作为测试集,建立XGBoost-SVR采收率预测模型。这是一个目标变量回归预测问题,不同的模型原理和所得结果之间是存在差异的。此次融合了XGBoost以及SVR两个模型,其中第一类可以看作是决策树模型,SVR为支持向量机模型。这两类模型原理相差较大,产生的结果相关性较低,融合有利于提高预测准确性。
XGBoost模型根据数据大小和种类以及影响采收率参数来参数寻优,模型参数最终设置为:决策树的深度max_depth=5,学习率learning_rate=0.01,最大迭代次数n_estimators=200,随机采样的比例subsample=0.7,每棵随机采样的列数的占比colsample_bytree=0.8,静默模式silent=True,线程数nthread=0.2。SVR模型确定固定值向量机结构参数中,惩罚因子C=24.83,单个样本的影响波及范围g=5.77来开始支持向量机模型的训练与预测。
3.3 XGBoost-SVR组合模型构建与调试
在进行模型构建过程中,要避免影响因素与采收率之间发生过拟合现象,即模型在训练样本中表现优越,但是在验证数据集以及测试数据集中表现不佳,可采用特征样本随机训练,减少树深度和正则化参数后等有效方法来降低过拟合。
两个单模型的超参数调整对于模型的表现有很大的影响,在不断地调试之后,结合误差值分析确定参数范围内最优的参数组合,在确定结构参数后,对于单模型再次在训练中使用交叉验证,一方面是可以对比不同模型的效果,另一方面是在4折交叉验证中,每折训练结束后的模型,结合本折交叉验证都对采收率进行一次预测。对XGBoost-SVR组合模型进行4折交叉验证,得出4个采收率预测数值,最终组合模型的预测结果是4次预测结果的平均值,基于抽样化的样本可以提高精准度,最终结果实际上是4个组合模型结果的融合,抽样和融合可以减少过拟合,可对预测精度有所提高。
3.4 预测结果分析
在验证基于残差自适应组合模型精确度的同时,分别对XGBoost单模型和SVR单模型进行预测输出进行对比试验,各个模型预测结果如图7、图8、表3所示。由图7、图8可知,采收率值实际值处于平均水平时,各模型预测值和实际值的拟合度都较高,而对于实际值远小于或远大于平均水平的拟合效果均较差(W87井、W31井)。相比于单机器学习模型,组合模型与实际值的拟合效果最好,起伏程度更加接近采收率变化的范围趋势,偏差较小。
利用保存好的组合模型对输入变量重要性分析评价,变量重要性结果如图9所示。采收率预测变量重要性结果为储层变量因素大于工程变量重要性,重要性顺序为簇数、有效厚度、渗透率、含油饱和度等。储层变量因素中有效厚度和渗透率的重要性相对较高,反映了储油层和致密油渗流通道的影响度,表明在采收率的影响因素中,裂缝发育程度、储层自身性质以及渗流通道都占了较大比重。

图7 XGBoost预测结果Fig.7 XGBoost prediction result

图8 SVR预测结果Fig.8 SVR prediction result

表3 各模型预测结果对比Table 3 Comparison of prediction results of various models
4 模型评估
对组合模型可从精准度和离散程度两方面评估模型性能,均方误差(mean square error,MSE)和均方根误差(root mean squared error,RMSE)反映了采收率模型预测值和真实采收率之间的偏离程度,R2可评估该模型预测数据的离散程度,如图10所示,从基本理论方面揭示了评估模型的精准度和离散程度差异性。
MSE和RMSE计算公式为
(9)

对上述3种模型预测方法进行模型评估,回归模型评估如表4所示。
如图11所示,相比于单模型,基于残差确定的组合模型可充分利用不同的定性预测模型或定量预测模型的优势,可以基于误差分析,不断提升组合模型的预测精度,模型类型相差比较大的两模型间优势互补,不同的预测方法从不同的角度挖掘到的信息也不一致,因此组合模型进一步提高了模型的泛化能力。

图9 特征影响因素重要性排序Fig.9 Ranking of the importance of feature influencing factors

图10 理论模型精确度和离散程度评估图Fig.10 Evaluation of the accuracy and dispersion degree of the theoretical model

表4 模型评估值结果Table 4 Model evaluation results

图11 融合模型预测值残差图Fig.11 The residual plot of the predicted value of the fusion model
5 结论
引进机器学习之中的模型融合技术来预测致密油的采收率,可以有效地提高回归预测的准确性,相比于单模型,融合模型在稳定性和精确度方面体现出了一定的优势。得出如下结论。
(1)经过对致密油的采收率影响特征重要性分析,储层因素的相对重要性高于施工参数的重要性,其中簇数、有效厚度和渗透率因素相对重要性高,而加砂量和加液量相对重要性较低,证明了储层物性、裂缝(天然裂缝、人工裂缝)的发育程度对采收率的影响非常重要。
(2)XGBoost-SVR组合模型可充分利用XGBoost单模型可解释性强和SVR单模型高维度映射的优势,同时也增加了一定容错率,对于致密油藏的采收率预测精度达到94.63%,可为致密油藏的开发措施调整提供良好的指导作用。
