智能算法模型预测蜡沉积研究进展
2022-05-17高志敏
高志敏
(西安石油大学石油工程学院,陕西 西安 710065)
近年来,基于机器学习的人工智能方法在各领域的研究中取得了丰硕的成果,该方法是在大量的复杂的数据中通过一定的模型及算法探究某一规律,以应用于某一问题的解决[1-2]。常用的一些智能算法模型,如人工神经网络模型、支持向量机模型等,在工程科技领域的应用逐渐兴起,在解决某些数据量较大且繁冗的工程问题上,智能方法具有较为独特的优势。该方法的使用价值和应用前景得到了较多科技工作者的肯定,显然,该方法在未来工业的发展中前途广阔。
目前,在石油化工行业,应用人工智能算法模型来解决部分实际问题的现象已较为广泛,在复杂的原油储层、井筒及管道流动环境中,原油的流态、相态、物性等指标所受影响因素较多,需要大量的模拟、预测等计算描述,对此而言,智能算法模型是一个有力且高效的应用工具。随着计算机技术的不断进步以及科研者的不断探究,人工智能能模型对于输油管道蜡沉积的预测应用逐渐增多。当原油温度受外在环境影响而降低至析蜡点温度及以下,并加之各种外在因素的影响,析出的蜡分子会沉积在管壁上,使得流通面积减小,且会对原有的油品流动性形成一定的阻碍。对蜡沉积而言,常用的描述参数有析蜡点温度、溶蜡点温度、析蜡量、蜡沉积量等,各参数的计算过程中需考虑的复杂机理、因素较多[3]。相较于传统的数学模型而言,智能模型的引入无需细致研究其机理,会节省一定的人工投入。
1 常用的智能算法模型
用于蜡沉积预测的智能算法模型中,使用较为广泛的有人工神经网络模型、支持向量机模型、遗传算法、蚁群算法等,以及各种模型组合使用的综合方法。对于不同条件进行的不同建模方法[4],整体来看,各学者使用较多的模型为人工神经网络模型、支持向量机模型,以及组合了多种算法后的委员会机器模型。
1.1 人工神经网络模型
早在1943年,McCulloch W S等人[5]依据神经元的原理提出了最早的神经网络模型。该原始模型是近代所出现的各种神经网络模型的雏形,但因其计算过程中的权重值必须通过手动调节,难以满足计算需求,且人工干预程度较大,故被逐渐淘汰。新发展的神经网络模型在此基础上进行了大量的改进与优化,与智能学习的趋势相接轨。
神经网络模型的结构主要由输入层、隐藏层、输出层构成,其中的隐藏层可根据建模情况分为单层和多层,其结构如图1所示[6]。
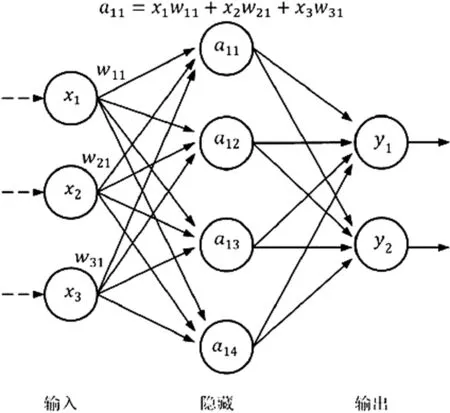
图1 三层神经网络结构图
其最小的组成部分便是神经元,作为连接输入和输出的枢纽,并承担着进行某种计算的任务,大多包含多个点的输入和一个点的输出。计算过程中所使用的算法和数学函数也是多种多样,不尽相同。各项参数输入模型中后,需进行大量的学习计算,对数据进行训练、测试,不断调整权重值,以期得到最好的预测情况。
常用的神经网络模型有误差反向传播(Back Propagation,BP)神经网络模型、径向基函数(Radial Basis Function,RBF)神经网络模型、长短期记忆(Long Short-Term Memory,LSTM)神经网络模型等。其中,BP神经网络模型是Rumelhart等人于1986年提出的,该模型依据人脑思维的第二种方式,将外部的信息按照输入层→中间隐藏层→输出层的正向进行传播,而将误差信息按照输出层→中间隐藏层→输入层的反向进行传播,以不断修正、调整各层的权重值,加强模型的学习及训练过程,针对于非线性连续函数,可用于解决其多层前馈神经网络权重值的调整问题。RBF神经网络模型是Broomhcad等人于1988年将RBF应用于神经网络的建模而形成,该模型可将输入的低维数据转变至高维空间内,可用于解决非线性函数的问题,具有分类能力较强、学习收敛速度较快的特点,这一模型的核心是基函数的选取,包括高斯函数、多二次函数等。LSTM神经网络模型是一种与时间有关的递归网络模型,相比与传统神经网络模型而言,其具有记忆功能,且具有解决长时依赖问题的能力。
彭继慎等人[7]建立了经典的“2-5-1”结构的RBF神经网络模型,“2-5-1”结构即为该模型中输入层节点的个数为2,隐藏层节点的个数为5,输出层节点的个数为1,该模型的原理如图2所示,由简单的3层前向网络组成。该模型结构虽然简单,却仍有较强的泛化能力,通过MATLAB软件进行了相关的仿真实验,结果表明,其设计的RBF神经网络与指数趋近律结合后,可实时调整其中的切换效益,具有较强的非线性跟踪能力,能够减少一定的设备损耗。

图2 RBF神经网络模型的原理图
1.2 支持向量机模型
早在1995年,Cortes C等人[8]提出了支持向量机(Support Vector Machines,SVM)模型,该模型基于统计学习理论、VC维理论等基础,经过科学研究者们多年呕心沥血的探索及改进,在算法训练、分类方法等方面有了许多创新性的改进,该领域的研究在多个行业里面也逐渐成为炙手可热的对象。截止到目前,该模型已成为一种较为通用的机器学习算法模型。
支持向量机模型与神经网络模型相似,但也有较大差别,二者都是基于机器学习的算法训练机制,但支持向量机模型主要针对的是小样本型的数据集,数据量较少,而神经网络模型主要针对的是大样本型的数据集,数据量较大且繁冗。此外,支持向量机模型的重点在于数学方法、优化技术的选择改进等。当然,为了更好地满足实际应用中的需要,多位学者也在积极探索研究大样本型数据集的训练算法,为提高求解精度而不断摸索尝试。目前,该领域内常用的训练算法主要有分块算法、子集选择算法、序贯最小优化算法、增量学习算法等类型,主要是针对于不同的目标,通过相应的约束条件等,解决各种训练速度、分类速度等相关问题。
关于该领域内的分类方法,其雏形是二分类问题,此后的各类方法皆是基于此而提出。现实生活中很多问题都是多分类的问题,多数研究者的目光也是聚集在该类问题上。这一类问题的解决方法笼统来说可以分为两种:直接法、间接法,各有特点与局限性,针对不同的问题辩证使用。支持向量机模型中核函数的选取是一个非常重要的问题,该模型方法之所以能够解决非线性分类问题、高维模式识别问题,很大程度上取决于核函数的引入和核参数的优化,因此在建模过程中需抓住这一关键问题。
李捷辉等人[9]为了提高分类预测的效果,建立了基于改进蝙蝠算法优化的支持向量机模型,其分类路线如图3所示。为解决实际应用的多分类问题,通过一对一的方法,以一层的训练样本和一层的测试样本数据集,对所建模型的功能进行数据的训练及测试,通过改进的蝙蝠算法对模型中的惩罚系数、核函数半径等参数进行优化,同时与遗传算法、粒子群算法、网络搜索算法、蝙蝠算法优化的支持向量机模型进行精度对比。结果表明,该改进蝙蝠算法优化的支持向量机模型精度为97.5%,预测效果最好。

图3 支持向量机分类路线图
1.3 委员会机器模型
早在1965年,Nilsson[10]提出了委员会机器(committee machine, CM)模型(图4),该类模型提出的最初目的是为了克服关于多层感知器的某一缺点——缺乏自适应学习规则,后来经过各科研学者的研究与探索,逐渐在各种领域中铺展应用开来,并出现了相应的许多改进模型。该类型的模型其实是一种集成的学习方法,通过单一的模型进行某一单模块的任务求解,然后对各模块的解进行合成,得到最后的结果。

图4 动态分类委员会机器流程图
该类模型通常由输入层、专家层、组合器和输出层4个部分组成[11]。其中,输入层是这一类模型的开端处,原始数据从此处输入并进行相关的预处理;专家层是模型的重要组成部分,包含多种算法,各自承担着相应模块的训练任务及预测结果的输出任务;组合器是该类模型核心部分,针对于各专家模块权重值的计算与分配等重要问题。委员会机器模型通常分为两类:静态委员会机器模型、动态委员会机器模型,前者通常会受限于专家的自身性能,提升空间有一定限制,后者可以简化数据结构,进而提升相关训练模型的性能。
白洋等人[12]通过引入门网络建立了动态分类委员会机器模型,在输入层和输出层之间建立了敏感性评价指标,由门网络对输入数据进行划分,使用概率神经网络、决策树、BP神经网络、贝叶斯分类、最近邻算法5种智能算法对各子数据集进行训练,通过组合器对各子模型进行优化和组合。结果表明,该委员会机器模型的训练集的准确率为96.29%,验证集的准确率为91.39%,相较于其他单一模型而言精度最高,提高了流体类型的预测准确率。
2 蜡沉积预测应用
原油蜡沉积的传统预测模型主要为动力学模型和热力学模型,前者基于分子扩散、剪切剥离、老化作用等机理,考虑不同影响因素,通过大量的实验数据以及适当的数学方法建模。后者基于相平衡理论,从原油组分的微观角度入手,建立相关的预测模型。近年来随着智能算法模型的发展,多为研究学者在原油蜡沉积智能模型预测方面进行了探索应用,开辟了更广阔的道路。
邹德昊等人[13]针对于某油矿井筒的结蜡问题,通过对多口井的高含蜡、高凝原油的物性和流动性进行分析,发现井筒内剪切应力、原油黏度、径向温度梯度、蜡分布密度4个因素对原油蜡沉积的影响较大,便以这4个因素作为输入变量,以蜡沉积速率作为目标参数,用SPSS Modeler软件建立了BP神经网络模型。该模型以双极S形函数为激活函数,最大训练周期设为1000次,最终的预测表明,该蜡沉积速率预测结果用于清管周期的计算时,误差率在3%以内,效果较好。
杨鸣峰等人[14]利用开源文献中的实验数据,考虑了4个影响因素:管壁处温度梯度、管壁处剪切应力、原油动力黏度和管壁处蜡分子质量分数梯度,通过MATLAB软件建立了RBF神经网络模型,以较小的样本数据作为训练和测试(24组训练,6组预测),结果表明,预测的相对误差在2%左右,与实验数据值吻合度较好。
田震等人[15]在研究BP神经网络对管道蜡沉积的预测过程中,分析了不同的输入维数对神经网络模型预测精度的影响,通过灰色关联法对输入维数为7(7个影响因素)和输入维数为4(4个影响因素)时进行了关联度计算,发现输入维数为7时更为合适。在建模过程中,借助MATLAB软件,选用trainlm函数作为训练函数,将最大训练次数设为10000,隐藏层的节点数设置为10,通过38组开源文献数据进行数据的训练及测试。结果表明,该模型预测的相关系数为0.999962、均方误差为0.0475085,精度较高。
王磊等人[16]在研究支持向量机模型对蜡沉积速率的预测研究中,利用开源文献中的环道实验数据,将7个影响因素:流速、油温、壁温、原油动力黏度、管壁处蜡分子浓度梯度、管壁处温度梯度、管壁处剪切应力作为输入变量,将蜡沉积速率作为输出变量,选取RBF作为核函数,用svmtrain函数训练相关的样本数据,用svmpredict函数测试相关的样本数据,建立了相关预测模型。最终的预测表明,训练数据的相关系数为0.9907,测试数据的的相关系数为0.9823,预测精度较高。此外,通过网格参数寻优法、遗传算法、粒子群算法三种方法对分别支持向量机模型进行参数优化,发现最终结果的差异并不大,预测的差值在0.05左右,效果不错。类似的,靳文博等人[17]从最小二乘支持向量机预测的角度出发,通过对模型的参数进行相关优化,建立了适用于小样本数据集的蜡沉积速率预测模型,相对于神经网络模型而言,该模型可以得到显式表达式,具有一定的优势,且预测效果较好。
Jalalnezhad M J等人[18]对输油管道蜡沉积智能模型的开发进行研究,基于实验数据集,将神经网络与模糊逻辑组合成一种新的智能算法模型——自适应神经模糊推理系统模型,对蜡沉积厚度进行预测。其研究基于管道单相紊流状态,以雷诺数、时间、蜡含量、周围环境温度、油温、管壁温度等7个影响因素作为输入变量,建立了自适应神经模糊推理系统模型五层结构。该模型基于if-then规则的模糊逻辑,考虑了具有2个输入x、y和1个输出f的网络。模型推理完毕后,使用实验数据值与模型预测的结果进行对比,该项研究从1500个数据中随机选取1000个数据作为训练集数据,剩余数据作为测试集数据,最终的预测结果如图5、图6所示。其中,图5显示了自适应神经模糊推理系统模型的测试结果与该研究中的实验结果的对比,图6显示了该模型输出的实际结果与实验结果的对比。其结果表明,该模型的计算结果与实际计算结果吻合较好,其中,均方误差为0.00077034,绝对相对偏差为0.015720,平均相对偏差为0.097961,该模型的精度较高。在单相湍流流动状态下,该自适应神经模糊推理系统模型比Halstensen模型所预测的蜡沉积厚度更为精准。

图5 蜡沉积厚度随时间的变化图

图6 模型预测结果图
3 存在的问题
目前,随着智能化趋势的到来,虽然已有较多学者使用智能算法模型对原油蜡沉积的预测进行研究及探索,但仍存在一定的问题,具体如下:
1)智能算法模型相比于传统预测模型而言,对数据的要求较高,对不同数据的适应性较差;2)不同智能算法模型对于数据量大小的要求不同,学习速率受影响较大,各模型相关参数值对预测结果的影响较大,理论方面有待提高;3)不同输入维数对最终的预测结果也有一定影响,维数过大过小都不合适,其选择也要适当。
4 结论与展望
1)相比穿传统的热动力学预测模型,智能算法模型无需考虑各种复杂的机理,人工投入较少,且计算精度较高;2)智能算法模型对于单种油品的预测效果较好,但应用于多种类油品的预测时,稳定性则较差,其专注性强于普适性;3)未来智能算法模型的发展,应更贴近于实际预测应用,加强数学理论深度的研究,深入开发适应性强的算法,综合多种算法模型的组合使用。
