聚类中心对齐的无监督域适应网络
2022-05-09陈辛怡
陈辛怡,孙 涵
(南京航空航天大学 计算机科学与技术学院,南京 211106)
1 引 言
近年来,深度学习在计算机视觉领域取得了显著的成果,特别是卷积神经网络已经被成功应用于各种图像分类和视觉识别任务.但是,这种成功往往依赖于大量带有丰富标签的训练数据,在现实场景中,对特定的新任务进行数据标记工作通常非常困难并且代价昂贵.一种有效率的解决方案是利用现有的标签丰富的公开数据集,提取有效知识用于新的无标签数据集的分类任务.把已标注数据集定义为源域,无标签的新数据集定义为目标域,由于两个域的特征空间和分布并不相同,直接使用源域数据训练的分类器对目标域数据的分类效果不尽人意.因此,有效利用相似域的可用数据,从而减少对新样本进行标记的需求和工作量是非常必要的.这就产生了一种新的机器学习领域即迁移学习[1],将源域和目标域是否有标签以及两个域任务是否相同作为划分依据将迁移学习分为3类:归纳式,直推式以及无监督迁移学习.域适应属于直推式,是迁移学习中最受欢迎的一个子领域,它假定源域有标签而目标域样本没有,同时源域和目标域任务相同.标签数据的稀缺性和处理域间差异的困难性促进了域适应领域的研究.域适应方法研究如何利用源域中学到的知识,结合目标域中的无标签数据,通过减少域偏移,去有效解决目标域的新任务.
域适应的主要思想是减少域之间的差异,学习预测模型.解决域偏移的策略主要有两种:基于统计准则和基于对抗学习.基于统计准则的方法通过计算并减小两个域的特征分布的距离来最小化域偏移,其中应用较多的距离有最大均值差异(Maximum Mean Discrepancy,MMD)[2],关联对齐距离(Correlation Alignment,CORAL)[3],中心距差异(Central Moment Discrepancy,CMD)[4]以及KL散度(Kullback-Leibler divergence)[5].基于对抗的域适应方法借鉴生成对抗网络(Generative Adversarial Networks,GAN)[6]的思想,将特征提取器用作生成网络,使用鉴别器来区分数据是来自源域还是来自目标域,从而达到对抗学习的效果,增加域混淆并最小化源域和目标域分布之间的距离.
无论是基于统计差异还是对抗学习,大部分方法都是通过最小化源域和目标域特征空间中的边缘分布的差异来对齐全局特征空间,但是这样会丢失局部信息例如每个类别的关键语义信息,导致源域和目标域同一个类别的特征可能会被映射到不同的位置.例如键盘和带有按键的手机从源域迁移到目标域后,两个类别因为特征的相似性造成分类边界模糊,导致被错误分到另一个类别.最近越来越多的研究工作意识到语义迁移的重要性,文献提出了滑动语义迁移网络(MSTN,moving semantic transfer network)[7],通过对齐标记的源域类别中心点和伪标记后的目标域类别中心点来学习目标域样本的语义表示.
在本文中,受到MSTN网络的启发,将对抗性学习与语义对齐相结合,在对齐两个域的类别中心之前引入源域中心增强模块,此模块通过缩小源域特征的类内距离,增大类间距离来得到更好的聚类中心,有利于目标域的类别中心在此基础上进行更准确的对齐,进而达到提高目标域任务的精确率的目的.此外,两个域之间虽然存在相似性,但是直接用源域分类器对目标域样本进行标注仍然会有不小的错误率.Laine S等人提出了用于半监督学习的自集成(self-ensemble)[8]方法,即在不同的训练周期,在不同的正则化和输入增强条件下,综合网络得到的不同输出结果来对未知标签进行预测,这样做能减少个别错误预测带来的影响.因为该方法具有鲁棒性,对虚假伪标签不敏感,把它改造后用于无监督域适应中,将源域分类器集成后作为目标域提供伪标签,这种集成预测比最近一次训练的网络输出更能预测未知标签,使得在源域上训练的分类器可以在大多数目标样本上表现良好.
本文贡献如下:
1)提出了聚类中心对齐的无监督域适应方法CADA(Centroid Alignment for Unsupervised Domain Adaptation),在传统的对抗域适应方法基础上增加了语义信息迁移,对源域数据执行类别中心增强操作来改善源域聚类效果,在此基础上将源域和目标域的类别中心进行对齐.
2)将集成学习方法用于无监督域适应中,首先源域图像和源域标签用于训练分类器,然后多次将目标域图像输入分类器使它经过随机增强步骤得到不同的结果,对这些结果进行加权求和,集成后的分类器为目标域图像分配的伪标签具有更高的准确率,从而使目标域类结构能更好的和源域进行对齐.
3)在不同的数据集上进行了实验,与其他域适应方法进行了对比分析,验证了本文方法的有效性.
本文的结构安排如下:第2节介绍域适应领域的研究现状,第3节详细描述本文提出的聚类中心对齐的域适应网络,第4节描述实验过程,展示本文的方法在域适应数据集上的效果,与其他域适应方法进行对比,并分析实验结果,第5节总结全文.
2 研究现状
传统的对抗性域适应方法训练域分类器以区分源域或目标域的特征,并训练特征生成器网络来提取域不变特征.其中神经网络的域对抗训练(DANN,Domain adversarial training of neural networks)[9]和对抗判别域适应(ADDA,Adversarial Discriminative Domain Adaptation)[10]是其中的典型方法.DANN用域分类器判别输入图像来自源域还是目标域来最大化分类误差,和源域最小化分类误差构成对抗训练,并且在特征提取器和与分类器之间增加了一个梯度反转层实现梯度在反向传播过程中的自动取反.ADDA方法提出了一个通用框架实例,它结合了判别性建模、权重共享和GAN损失,首先利用源域的标签学习一个判别性表示,再通过域对抗使用不对称映射将目标域上的数据映射到一个相同的空间当中.
传统的对抗域适应方法只尝试将特征区分为源域或目标域,不考虑类之间的任务特定决策边界,而经过训练的生成器会在类边界附近生成模糊特征.这几年越来越多的方法注意到域适应中的类别区分问题.Motiian等人意识到语义对齐的缺失是性能降低的重要来源,因此提出了少样本对抗域适应(FADA,Few-Shot Adversarial Domain Adaptation)[11],主要思想是利用对抗性学习来学习一个嵌入子空间,该子空间在语义上对齐两个域之间,同时最大化它们之间的混淆.Kuniaki Saito1等人提出了最大化分类差异的无监督域适应方法(MCD,Maximum Classifier Discrepancy for Unsupervised Domain Adaptation)[12],试图利用任务特异性的决策边界来调整源域和目标域的分布,提出最大限度地提高两个分类器的输出之间的差异,来检测那些远离源域的目标域样本.特征生成器最小化这个差异来生成靠近源域的目标域特征.这些方法不但能够将目标域样本空间映射到源域空间中,还能够通过对抗训练的方法进一步优化分类器,使得分类边界更加明显.
3 CADA网络模型
3.1 总体结构
本文提出的网络结构如图1所示,首先是传统的无监督对抗域适应.添加了一个判别器用来判断特征来自于源域还是目标域,目的是通过最大化域分类损失LDC来达到域混淆,而分类器的目的是通过最小化类别分类损失LC来获得更好的分类效果,因此分类器和判别器以对抗训练的方式来取得平衡,实现源域和目标域的特征边界对齐.将此和聚类中心对齐相结合,从两个方面来增强域适应效果.
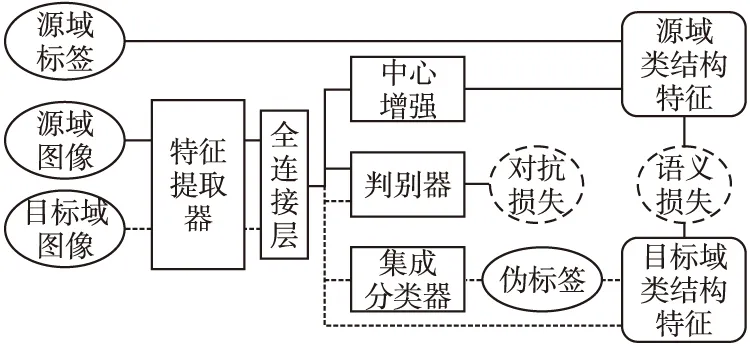
图1 CADA结构图Fig.1 Framework of CADA
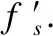
3.2 无监督对抗域适应
L=LC(XS,YS)+αLDC(XS,XT)
(1)
LC为监督分类损失,分类器h=FG,源域图像经过特征提取器G得到特征向量f,然后特征被送入F中输出预测分类结果.LDC为对抗损失,α为超参数,本文选择使用域对抗相似性损失来计算两个域的距离.使用了一个域判别器D为来判断特征提取器G的特征来自于源域还是目标域,而特征提取器G想提取更相似的特征使判别器D无法进行区分,这样通过博弈达到一个平衡,从而对齐源域和目标域特征空间的边缘分布.源域分类损失LC和对抗损失LDC分别表示如下:
(2)
LDC(XS,XT)=Ex~DS[log(1-D(G(x,θG);θD)]+
Ex~DT[logD(x,θD)]
(3)
其中J表示交叉熵损失函数,DS表示源域,DT目标域.
通过对抗训练,得到了域不变特征,完成了源域和目标域特征空间的边缘分布对齐,但是这种对齐是整体的,而局部的语义信息并没有得到正确的迁移.理想的情况是源域和目标域相同类别的样本能被映射到同一区域,而不同类别之间能被很好的区分.为了实现域适应过程中对语义信息的保留,引入了聚类中心对齐.
3.3 中心增强
在进行两个域的聚类中心对齐之前,先对源域的类别中心进行优化,加强类间的离散性和类内的紧凑性以便于目标域能更好的在源域中匹配到同一类别的中心.Wen Y等人提出了用于人脸识别任务的center loss[13],通过同时学习每个类的特征中心,并缩小特征与其对应的类中心之间的距离,来提高特征的可判别性.受此启发,将center loss用于域适应任务,在分类前的最后一层加入center loss,结合softmax loss进行联合监督,可以训练一个健壮的卷积网络来获得尽可能多的具有判别性的深层特征.Softmax loss使得每一类别可分,可以使源域的特征类间距离更大,而center loss可以让类内距离更小,由此就能获得更清晰的聚类中心.中心损失Center loss改变类内距离的过程可表示如下:
(4)
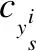
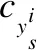
(5)
(6)
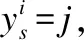
3.4 聚类中心对齐
首先将分类器进行集成,即利用网络训练中在不同的迭代时期的输出,最重要的是在不同的正则化和输入增强条件下,形成对未知标签的共识预测.具体方法是将同一样本多次输入分类器,而每次操作会由于dropout等随机因素而得到不一样的输出,然后结合不同的输出结果为目标域样本提供伪标签.标记过后的目标域就能和源域进行聚类中心对齐,对齐方式采用了MSTN方法提出的语义迁移损失(semantic transfer loss):
(7)
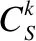
采用类别中心对齐进行语义迁移是因为分类器给目标域分配的伪标签并不都是正确的,如果用每个样本直接进行迁移会受到错误伪标签的影响产生误差,而类别中心往往可以在代表一组样本的同时避免个别错误标记的样本带来的负迁移.如果直接对准源域和目标域中心,因为是基于小批量进行中心的更新,即使是一个伪标签也会导致伪标签中心与真实中心之间的巨大偏差.所以语义迁移损失采用指数滑动平均中心(moving average centroids)作为替代,具体方法是为每个类维护全局类别中心(global centroids).在每次迭代中,源域中心由标记的源域样本更新,目标域中心由伪标记的目标域样本更新.然后,可以根据公式(7)对齐这些滑动平均中心.最后,整个网络的损失函数如下:
L(XS,YS,XT)=LC(XS,YS)+αLDC(XS,XT)+
βLCT(XS,YS)+λLSM(XS,YS,XT)
(8)
其中,α,β,λ分别为对抗损失,中心损失和语义对齐损失的平衡权重.
4 实验过程与结果
4.1 实验数据集
本文使用了两组域适应任务中常用的数据集对提出的方法进行了实验,这两组数据集分别是数字数据集SVHN-MNIST-USPS以及现实生活场景类的数据集office-31[14],接下来会对数据集以及使用方式作简单介绍.
SVHN-MNIST-USPS是最简单的域适应任务,由3个数字数据集组成.SVHN[15]是一个现实世界的图像数据集,是从谷歌街景图片中的门牌号获得的,MNIST[16]是一个手写数字数据集,USPS是美国邮政手写数字数据集.这3个数字数据集常用于机器学习和目标识别算法,对数据预处理和格式要求最低.同时因为3个数据集具有较高的相似度,也多用于域适应方法的验证.MNIST数据集的图像大小是28×28,一共7万张图片,USPS数据集的图像大小是16×16,一共两万张图片,SVHN数据集的图像大小是32×32,拥有10万多张图片和5万多个附加图片,本次实验中不使用附加图片.利用这3个数字数据集实现了3个域适应任务,分别是SVHN到MNIST(S-M),MNIST到USPS(M-U)和USPS到MNIST(U-M).
Office-31数据集包含31类生活中的常见物品,共有4652幅图像,分别来自3个不同的域,分别是:1)亚马逊(Amazon,源自亚马逊网站),包含2817张图像;2)网络摄像头(Webcam,从网络摄像头捕获的低解析度图片),包含795张图像;3)单反相机(Dslr,从数码单反相机捕捉的高解析度图片),包含498张图像,3个域的示例图片如图2所示.用这3个域完成了6种迁移场景,分别是A→W,D→W,W→D,A→D,D→A和W→A.

图2 Office-31数据集示例Fig 2 Represent examples from Office-31 dataset
4.2 实验设置
对于SVHN-MNIST-USPS任务,本文按照MSTN的网络,将LeNet[16]作为骨干网络,采用两个卷积层后接池化层和两个全连接层.因为3个域的图像尺寸不同,将所有图像统一投射到28×28×1.对比实验方法选取了DDC(Deep domain confusion:Maximizing for domain invariance.)[17]、DRCN(Deep reconstruction-classification networks for unsupervised domain adaptation)[18]、RevGrad、ADDA、MCD和MSTN.其中DDC基于统计方法,选取MMD距离作为度量准则;DRCN是基于重构的方法,TPN(Transferrable Prototypical Networks)[19]重构原型网络来学习嵌入空间,并结合了类别信息,通过类到原型距离的重构进行域对齐;DANN和ADDA是传统的对抗域适应网络;MCD和MSTN是结合了类别信息的域适应方法;IT-ADDA(Improved Techniques for Adversarial Discriminative Domain Adaptation)[20]是将MMD距离与对抗域适应方法相结合,在ADDA网络上进行改进的方法.
对于Office-31任务,本文选取AlexNet[21]作为卷积网络,在fc7层之后增加了一个256维的瓶颈层fcb,并使用fcb作为鉴别器的输入以及类别中心的计算.对比实验方法选取了DDC,DRCN,RTN(Unsupervised domain adaptation with residual transfer networks)[22],RevGrad,ADDA,JAN(Deep transfer learning with joint adaptation networks)[23],CDAN,MADA,MSTN作为对比方法进行实验.其中RTN和DDC都是选取MMD距离作为度量准则的基于统计的域适应方法,不同的是RTN考虑到了源域和目标域的差异,增加了分类器适应,较DDC能达到更好的效果.JAN在MMD的基础上提出了JMMD(joint maximum mean discrepancy),不同于MMD测量网络单层的差距,JMMD度量网络最后基层联合分布的差异,能有效利用网络层之间的相关信息.CDAN(Conditional Adversarial Domain Adaptation)[24]提出了条件对抗域适应,对特征表示和分类器预测的协方差进行调节以提高可判别性,同时调节熵控制预测的不确定性以保证特征的可迁移性.根据分类器输出结果中包含的可鉴别信息来调整对抗域自适应模型.MADA(Multi-Adversarial Domain Adaptation)[25]提出了一种多模态的对抗域适应网络,采用多个判别器对源域和目标域数据进行细粒度对齐.
主要调整5个超参数:权重平衡参数α,β,λ和滑动平均系数θ.对于θ,在所有实验中设置θ=0.7.对于权重平衡参数,设置α=2/(1+exp(-β,p))-1,其中β设置为10,p值在0~1之间.对于中心损失的参数λ,在数字数据集的实验中,λ取值在0.1~1之间,在office-31数据集中λ取值范围为0.0005~0.001.
4.3 实验结果分析
在数字数据集任务上,本文的方法CADA在M-U,U-M这两个方向的迁移取得了最高的精度,见表1,分别为95.1%和98.5%,在S-M方向上CADA分类准确率为95.2%,比取得了最好效果的IT-ADDA方法低了1.2%.IT-ADDA方法的优越性在于它将MMD损失,重构损失与对抗训练相结合,并在源域类别上扩展鉴别器输出,从不同角度上促进了源域和目标域特征分布的对齐.虽然没有在所有迁移的任务上得到最好的结果,但是CADA在这3个不同任务上发挥稳定,没有明显弱势,说明本方法具有较强的鲁棒性,可以灵活适应不同的迁移任务.MCD,MSTN,TPN以及CADA比传统域适应方法DDC,RevGrad,ADDA,DRCN获得了显著了提升,证明了语义信息的保留在域适应中的必要性.CADA与同样进行类结构适应的MCD,MSTN和TPN方法相比有明显优势,比如在U-M方向上,CAAD方法的精度比这3种方法提升了4%左右.最后,CAAD在源域的样本上增加了中心增强操作之后再进行对齐的方法比直接进行中心对齐的MSTN方法在所有的任务上都有较大的改善.CADA和MSTN方法在S-M和U-M任务上的准确度对比如图3所示.

表1 基于SVHN-MNIST-USPS数据集的实验结果Table 1 Classification accuracies(%)on digit recognitions tasks
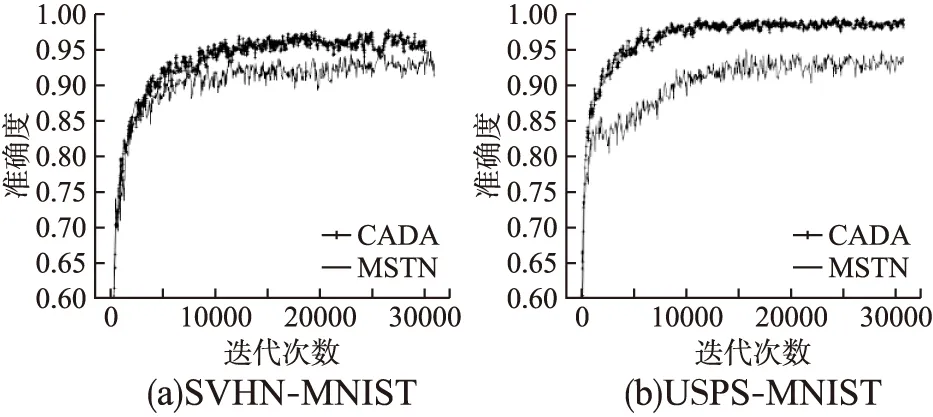
图3 不同方法准确度对比图Fig.3 Comparison of testing accuracies of different models
基于office-31数据集的实验拥有比数字数据集更复杂的迁移任务和更高的难度,在这6个迁移任务中,如表2所示,CADA方法的平均精度为80.1%,比MSTN方法提高了1%,比传统对抗域适应方法RevGrad提高了5.7%,比AlexNet网络提高了10%.其中D域和W域之间的迁移正确率极高,因为都是摄像头采集的图像,极高的相似度使它们无需进行域适应就能取得很好的效果,如W-D的任务仅使用卷积神经网络AlexNet就能达到99.0%的精度.所以我们的方法CADA在D域和W域之间的任务上提升并不明显,而在迁移难度较大的A域和D域之间,CADA方法能有较大的提升.
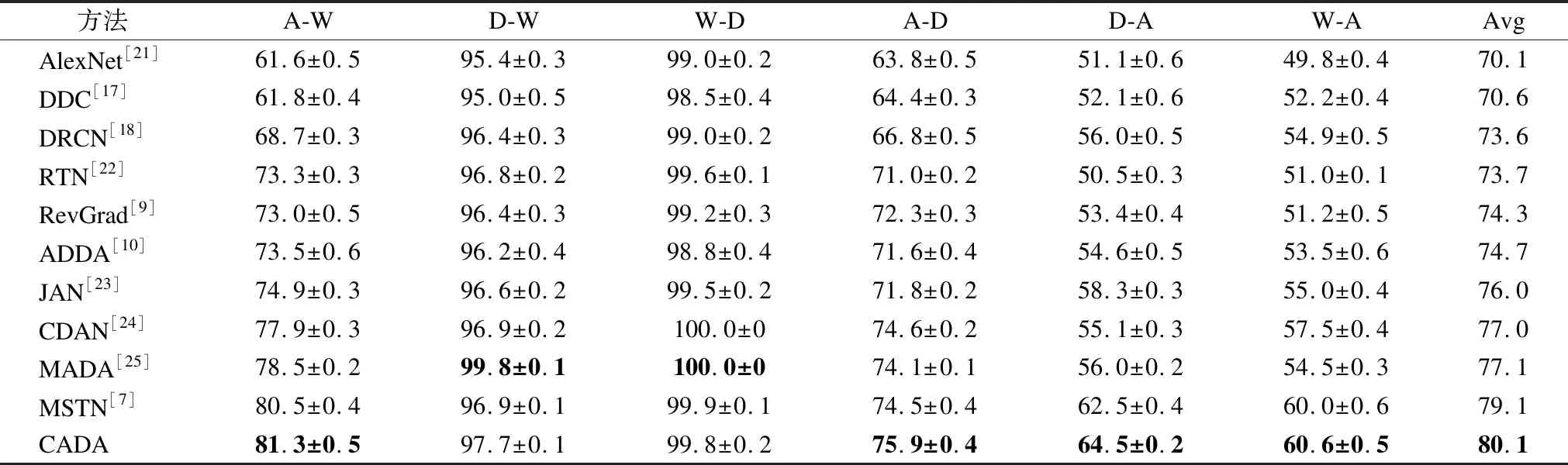
表2 基于office-31数据集的实验结果Table 2 Classification accuracies(%)on office-31 datasets
RTN比DDC方法多加了分类器适应之后取得了更好的效果说明了只进行特征空间对齐的方法的局限性.而作为统计适应方法中表现最好的JAN的结果也不如MSTN和CADA,这一结果验证了语义迁移在域适应中的有效性.在传统对抗域适应方法上进行改进的CDAN和MADA平均准确度仅次于MSTN和CADA,其中MADA在D域和W域之间的迁移任务上取得了最好的结果,表明在两个域相似度极高的情况下,MADA方法是非常有效的.但是在难度大的任务比如W到A域的迁移上,本文提出的CADA方法比MADA提高了6.1%,说明CADA能有效减少域间差异,不仅在Office-31数据集所有的迁移任务上都取得较高的准确度,并且表现平稳,能适用不同的场景.
CADA与RevGrad方法在A-D以及A-W任务上的准确度和JS散度(Jensen-Shannon divergence)如图4所示.用JS散度来衡量源域和目标域特征分布的距离.在A-D任务中,RevGrad的JS散度最小值更小,这是因为该方法只进行特征空间边缘分布对齐,尽力缩小两个域的分布差异.我们的方法结合了语义信息后虽然域间距离不如RevGrad方法小,但是取得了更高的精度,JS散度下降速度也更快.在A-W任务中,CADA不仅准确度更高,JS散度最小值和RevGrad也近似,更说明了语义对齐能有效减少域偏移,并且能灵活适用于不同的场景中.
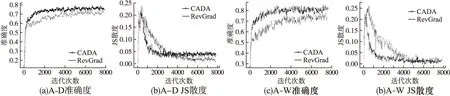
图4 不同方法准确度和JS散度对比图Fig.4 Comparison of testing accuracies and JSD of different models
5 总 结
本文探讨了如何利用语义信息更好的进行域适应,提出了将对抗训练和类别中心对齐相结合,不仅对源域和目标域特征空间的边缘分布进行对齐,而且有效的利用了类条件结构完成了语义迁移.在office-31和数字数据集上进行了大量的实验,并与基于统计,基于对抗以及基于重构等多种不同的域适应方法进行了对比,验证了CADA方法的有效性和鲁棒性.在未来的研究中,CADA中类别中心加强以及集成学习的思想不仅可以应用到新的域适应方法,也有望应用于其他计算机视觉任务中,如细粒度分类和目标检测.
