文本幽默识别综述:从数据到方法
2022-05-09吕欢欢马宏伟杨东强
吕欢欢,马宏伟,王 璐,杨东强
(山东建筑大学 计算机科学与技术学院 ,济南 250101)
1 幽默计算相关概述
社交媒体的快速发展产生了大量用户生成的言论,这为幽默的可计算性奠定了基础[1].幽默计算旨在赋予计算机学习人类语言行为认知模式的能力,以使计算机理解并产生幽默新颖的表达.幽默计算研究涵盖幽默识别和幽默生成两个子领域,幽默生成不仅要求计算机“读”懂幽默,更要求计算机会表达幽默,因此,需要在幽默识别的基础上探索更复杂的计算模式.基于幽默计算的人工智能研究可以被应用于多种场景,包括聊天机器人、机器翻译、儿童教育软件等.对于人机对话系统,幽默计算可以帮助计算机产生更自然诙谐的表达.电商平台利用幽默计算,可以深入挖掘用户评论背后隐含的真正情感含义,针对用户做出更精准的推荐.幽默计算还应用于社交平台中,通过分析用户发表的意见,可以挖掘其背后隐含的幽默,辅助判断舆情趋势.另外,幽默计算可以应用在机器翻译中,例如中文歇后语的英文翻译等.
由于幽默的主观性及对语境和文化背景的依赖性,使计算机理解幽默并非易事,但幽默理论的探索以及基于机器学习的幽默计算研究表明,计算机仍可以完成一些简单的幽默识别任务,该领域目前处于初步研究阶段.幽默识别的早期研究主要是基于幽默理论进行特征工程设计,使用支持向量机、朴素贝叶斯、随机森林等传统机器学习算法进行幽默二元分类(即识别是否幽默).Yang等人[2]基于幽默理论,从不一致性、模糊性、个人风格和语音的声调韵律方面设计幽默特征,使用随机森林分类器进行二元幽默分类.Mihalcea和Strapparava[3,4]为幽默二元分类任务创建了一个单语笑话语料库16000 One-Liners,定义了一组基于幽默理论的启发式特征(例如头韵、反义词等),利用支持向量机和朴素贝叶斯分类器进行幽默分类.除了幽默二元分类任务,相关研究也陆续提出了关于幽默识别的各种下游任务.例如,基于细粒度的幽默程度评级任务,幽默锚点的识别(即自动学习引起幽默的关键语义单元),幽默语料库的构建等.使用基于数据驱动的方法进行幽默识别,幽默语料库的创建是基础且关键的工作.
幽默本质上是人类所能感知的一种特殊的隐式情感,但其产生机制和表达方式比一般情感更复杂.幽默识别与文本分类、情感分析任务既有区别又有联系.从语法和语义角度看,幽默分为形式幽默(例如排比、押韵、对偶等)和内容幽默(例如关键词幽默、上下文幽默等),这是幽默识别任务相较于一般文本分类任务的独特性.从语料角度看,三者相关语料库的标注具有较大差异.文本分类语料的标签多种多样,而幽默识别标签主要表示是否幽默、幽默程度以及幽默类型,例如讽刺、双关语等.从应用场景看,文本分类涵盖了多种场景,例如新闻分类、情感分类等,而幽默识别主要可作为机器翻译、幽默生成、人机对话系统的基础任务,更适合应用于社交媒体的用户言论数据的分析中,是一种具有更细粒度的研究方向.目前大部分关于幽默计算的研究聚焦于幽默识别,因此本文着重对幽默识别相关研究进行了总结.目前,幽默识别研究的主要工作集中在两方面:幽默语料库的创建和基于机器学习的幽默识别方法的探索.
本文的组织结构如下.首先系统介绍幽默理论研究及幽默特征提取,然后围绕从数据到方法介绍幽默语料库构建、基于传统机器学习的幽默识别方法、基于深度学习的幽默识别方法,最后对幽默识别研究进行总结与展望.
2 幽默相关理论及特征提取
2.1 幽默相关理论
目前,幽默计算依赖于幽默理论的支撑.“幽默”一词源于英语的“humor”,意思是心血来潮、反复无常,后来演变成了“搞笑”的意思.尽管从词源上幽默是舶来品,但其存在是跨文化的,不同的文明形态下的幽默是普遍存在的,差异可能在于所谓“笑点”的不同.
幽默是一种特殊的语义表达,幽默的理解通常需要在字面含义的基础上探索更深层次的语义内涵.大量心理学、语言学、哲学等领域的学者对幽默成因进行了研究,从古希腊亚里士多德时期至今,诞生了上百种幽默理论.其中,具有代表性的是“优越论”、 “宽慰论”、“乖讹论”三大幽默理论[5,6].“优越论”认为笑声产生自一种优于他人的感受.优越论虽然很好地诠释了幽默使人发笑的背后原因,但对于一些幽默表达无法给出合理解释,这是优越论的局限性.“宽慰论”认为笑声是缓解压力、释放压抑神经的一种途径,可以解释为什么当人们谈论一些敏感话题时会引起笑声.“乖讹论”也称为“不一致性理论”,“乖”和“讹”是两个不协调的对立面,不协调会使人意外,而意外可能会导致惊喜或发笑.例如,“有钱的人怕别人知道他有钱,没钱的人怕别人知道他没钱.”Reskin[7]提出了一种由“乖讹论”延伸出的幽默语义脚本理论(Semantic Script-based Theory of Humor,SSTH).SSTH认为笑声源于处于一个语篇内兼容的两个脚本之间的对立,笑话结构被拆解成“主体(set-up)”和“妙语(punchline)”两部分,主体包含多个可能的解释,只有一个解释是明显理解的,而幽默产生自其他隐含意义的解释妙语.Attardo和Raskin[8]提出的言语幽默一般理论(General Theory of Verbal Humor,GTVH)扩展了SSTH的可解释性和描述性,除了情景对立外,强调了影响幽默的其他因素,认为言语幽默包括六种幽默元素:幽默语言、叙述策略、对象、情景、逻辑机制、对立.SSTH强调语义对立关系,而GTVH除此之外另包括语用、声调韵律等语言学方面的因素考量.近年来,幽默本体语义理论(Ontological Semantic Theory of Humor,OSTH)[9]也是在“乖讹论”基础上发展起来的,是一种将词语激活脚本的过程形式化的通用模型,使脚本具有更加统一的表达形式和明确的内部结构.
2.2 幽默特征提取
幽默是一种特殊的隐式情感,其表达通常通过语言、表情、肢体动作等方式含蓄表达,这也决定了幽默计算任务相较于常规情感分析任务或文本分类任务的特殊性.对大量相关研究的调查发现,目前幽默特征的设计及表示直接对幽默识别的结果产生重大影响.幽默计算的特征设计可归纳为以下几类:基于语言学的特征、基于幽默理论的特征、基于幽默结构和类型的特征及基于内容和上下文的特征,如图1所示.
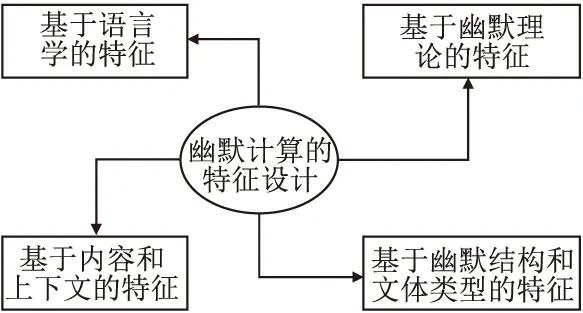
图1 幽默计算特征分类Fig.1 Humor computation features classification
基于语言学的特征涵盖了语音、语义、语法特征,例如头韵、押韵、谐音、反义、歧义、语义距离、语义熵、词性及数量等.基于幽默理论的特征主要是根据经典的“宽慰论”、“优越论”、“乖讹论”及其衍生出的SSTH等幽默理论来设计,涉及范围广泛.例如,情感极性特征,情感关联特征,不一致性特征等.基于幽默结构和文体类型的特征,Cattle和Ma[10]认为幽默文本可拆解为“铺垫”和“笑点”两部分,单独针对“铺垫”和“笑点”设计特征以及设计能反映二者语义关联的特征,能极大提升幽默计算的表现.幽默有多种类型,例如讽刺、双关、俚语、文字游戏等,每种文体的幽默成因不同,因此泛化性能强的计算模型离不开针对各种幽默文体设计的特征.例如,句长特征、标点符号特征、转折词特征等.基于内容和上下文的特征,例如N-gram特征等,得益于深度神经网络的超强抽象能力,主要是基于神经网络和大规模模型的预训练表示进行获取,例如Bi-LSTM、GPT、BERT模型等.
3 幽默识别语料库
目前幽默识别研究仍处于起步阶段,现有的高质量公开数据集并不多.基于数据驱动的幽默识别方法需要大规模、高质量的幽默语料库,特别是带有人工标注的幽默语料库.本部分详细介绍一些公开、常用的幽默计算语料库.
3.1 英文语料库
3.1.1 16000 One-Liners
Mihalcea和Strapparava[3,4,11]使用10条英语单句幽默笑话作为随机种子和关键字,查询包含笑话的网页,最终收集了16,000条笑话.为了验证语料库的有效性,从中随机抽取了200条进行人工标注,其中只有9%被认为是噪声(即非笑话文本).除此之外,使用相似的文本特征,例如文本长度等,从路透社新闻标题、谚语(Proverb)、英国国家语料库(BNC)句子以及开放思维常识语料库(OMCS)中选择非幽默文本,与16,000条笑话文本共同组成幽默二元分类数据集.目前16000 One-Liners已成为幽默二元分类任务的常用数据集.本文将该数据集简写为“16000OL”.
3.1.2 Pun of The Day
Pun of The Day语料库的2423条幽默正样本是Yang等人[2]从“Pun of the Day”双关语网站中收集的.双关语是一种文字游戏类型,它利用一个术语或类似术语的多重含义,以达到预期幽默或修辞效果.为了执行幽默分类任务,该数据集的2403条负样本收集自AP News、New York Times、Yahoo! Answer、Proverb等网站.为了消除正负样本领域不同带来的分类性能偏差,限制负样本中的词语都包含在正样本词典中,并使用相似的文本特征(例如句子长度等)收集负样本.句子的平均长度为10~30个单词.目前该数据集已经被广泛用于许多幽默二元分类研究中.Cattle和Ma[12]基于数据集16000 One-Liners和Pun of The Day验证了其设计的幽默特征的有效性.本文将该数据集简写为“PoTD”.
3.1.3 Twitter Humor Corpus
16000OL的幽默实例是静态不变的,并且所有实例类型是固定的单语笑话.而在社交网络中,用户产生了大量更加生动的幽默文本.从这些动态数据来源中研究识别幽默是一个值得研究的方向.Zhang和Liu[13]为了识别Twitter推文中的幽默,使用Twitter API收集了2000条幽默推文.虽然这些推文的源标签都是幽默的,但为了缩小源标签和用户真实标注之间的差异,对推文进行了人工标注,去除144条重复推文后得到了1267条幽默推文和589条非幽默推文.之后,从1267条幽默推文中随机抽取1000条作为正样例.同时使用Twitter API收集1500条非幽默推文和带有幽默标签的非幽默推文中随机选取1000条作为负样例,并从网站textfiles.com收集了1000条非推文的幽默的短笑话实例.并限制该数据集的所有样本长度均不超过140个字符.综上,该数据集共包含3个子集:1000条幽默推文,1000条非幽默推文,1000条非推文幽默笑话.本文将该数据集简称为“Twitter Humor Corpus”.
3.1.4 Humicroedit
Humicroedit语料库包含两部分:1) Hossain等人[14]从Reddit(reddit.com)社区收集的热门新闻原始标题,2) 使用Amazon Mechanical Turk众包平台对原始标题进行微编辑使其具有趣味性评分的幽默版本,最终得到15,095条经过编辑的新闻标题和其对应的幽默等级评分.该数据集包括两个子集:subtask-1和subtask-2.subtask-1用于评估新闻标题趣味性的回归任务,subtask-2用于预测同一标题的两个编辑版本中哪个版本更有趣.每个子集包括训练、验证、测试集,以及train-funlines.csv文件,该文件是从FunLines比赛中额外收集的训练集数据.该数据集的统计信息如表1所示.由于该数据集中样本的幽默是经过添加或替换一个名词或动词得到的,所以不仅可用于幽默评级回归任务,还可应用于幽默锚点识别任务和自动幽默生成任务.

表1 Humicroedit语料库统计信息Table 1 Statistical information of Humicroedit
3.1.5 Short Jokes
Short Jokes是来自于Kaggle项目的一个开放数据库.包含了231,657个短笑话,不限制笑话类型,长度从10到200个字符不等,每个样本包含笑话文本和唯一ID.文献[15]采用Short Jokes作为幽默正样本,另外爬取了相同规模的WMT16英语新闻作为负样本,用于幽默二元分类任务中.
3.1.6 The rJokes Dataset
Weller和Seppi[16]为了缓解英文幽默检测缺乏大规模语料库的困境,收集了一个包括573,335个笑话的幽默文本语料库.每个笑话实例都被标注了代表笑话程度的标签(0~11,分值越高代表幽默程度越高),笑话的平均长度为239.78个字符,语料来自于Reddit r/Jokes子社区.样本字段包括了笑话文本和妙语、笑话幽默程度标签以及笑话发布日期.
3.1.7 SemEval-2021 Task 7
幽默具有高度主观性,年龄、性别、经济水平、社会地位等因素均会对幽默的感知产生影响.因此,SemEval 2021 Task 7数据集的标注者年龄介于17岁-80岁年龄段之间,代表了不同性别、政治立场、收入水平等.该任务要求标注给定的文本是否幽默,以及如果是幽默文本,在1~5评分区间内标注文本的幽默等级,标注文本是否具有攻击性以及攻击性程度.因为一个用户认为是幽默的文本可能对另一个用户来说具有攻击性.
3.1.8 UR_FUNNY
目前多模态数据分析已成为自然语言处理领域的研究热点.由于幽默常在人们面对面的社交活动中出现,伴随手势、声音韵律的语言常使幽默表达更加丰富.Hasan等人[17]创建了一个用于幽默识别任务的多模态数据集UR_FUNNY.不同于传统的幽默二分类任务,该数据集可用于笑点检测,即检测给定序列是否会在笑点之后引发笑声.UR_FUNNY的数据来源于TED演讲视频,TED演讲不仅涵盖了不同主题和类型的幽默,且演讲者也具有不同的文化背景.另外,该数据集与传统数据集的负样本采样方式有所不同,传统数据集的负样本大部分来自于新闻门户网站,比如New York Times、Yahoo! Answer等.而该数据集为了不引入主题偏差,负样本与正样本来自于同一视频片段.该数据集的统计信息如表2所示.
3.2 非英文语料库
现有幽默数据集大部分是英文数据集并且数据集规模相对较小,不能反应幽默的广泛性,而幽默的表达会因语种不同而存在差异.因此,为研究不同语言中的幽默识别方法,有研究者构建了一些非英文幽默语料库.
3.2.1 FUN
Blinov等人[18]在Stierlitz数据集[19]的基础上收集构造了一个俄语短文本幽默语料库FUN,数据来源于各种在线网站,以保证数据的多样性和代表性.该数据集包含超过300,000条短文本,其中大概一半是幽默样本,并且人工标注了1877条样例来证明语料库构建方法的可靠性.为了验证数据的有效性和多样性,计算FUN数据集中的笑话和非笑话文本的KL散度,结果表明扩展后的FUN数据集相对Stierlitz数据集更具有多样性.
3.2.2 HAHA Dataset
HAHA数据集是用于西班牙语幽默计算的文本语料库.Castro等人[20]在2016年建立了第一个西班牙语推文幽默计算语料库,但是该数据集存在以下问题:1)每个样本的标注者较少,且标注者之间的意见一致性较低;2)幽默和非幽默样本的来源种类有限.为了解决上述问题,Castro等人[21]建立了一个众包标注的西班牙语幽默语料库,其中每条样本被标注了是否是幽默文本,以及幽默程度评级得分(1-5).该语料库共包含27,282条推文和117,800条标注,每条推文具有4个注释,且具有高度的一致性.然而,文献[21]创建的语料库仍然存在问题,包含较多的重复推文以及存在类别不平衡问题.Chiruzzo等人[22]在以上基础上构建并发布了HAHA-2019幽默语料库,在收集更多推文的同时删除了重复推文,并将数据集和标注合并,同时要求标注者在标注幽默标签时判断该推文是否具有攻击性.让标注者标注推文是否具有攻击性的目的有两个,一是收集带有攻击性标签的推文,以分析幽默属性和攻击性之间的联系;二是明确标注过程,若推文是具有攻击性的,则该推文被标注为非幽默的.该数据集已经用于由IberLEF主办的HAHA 2019比赛中.
3.2.3 CCL数据集
中国计算语言学大会(China Computational Linguistics,CCL)近两年发布了一些关于幽默计算的任务.CCL-2019“小牛杯”中文幽默计算发布了2个子任务:生成幽默识别和中文幽默等级划分.其数据集共分为两个子集,分别对应于两个子任务.子任务1要求识别计算机生成的幽默,是二元分类任务.共有21,552个样本,数据字段包括幽默文本ID、幽默文本内容、幽默文本类型.子任务2为中文幽默等级划分,分别用标签“1”、“3”、“5”表示文本的幽默递增程度.子任务2的数据集包含21,885个样本.CCL-2020“小牛杯”中文幽默计算发布了情景喜剧笑点识别任务,任务数据集来源于《老友记》(英文名:Friends)和《我爱我家》两种不同语言的情景喜剧,一段对话包含多句对白,每句对白被标注幽默标签“0”(非幽默)或“1”(幽默笑点).其中,英文数据集包含约700段对话、10,000句对白,中文数据集包含约500段对话、18,000句对白.CCL-2021“小牛杯”幽默计算发布了图文多模态幽默识别任务,基于Meme(以图文组合方式形成幽默)数据集,子任务1要求对给定的2个Meme进行幽默程度比较,子任务2是Meme幽默等级划分,每个Meme被标注“强幽默”、“普通幽默”、“弱幽默”3种标签之一.
目前,大部分幽默语料库只是笑话、幽默片段、双关语或俏皮话等与非幽默文本的集合.为了更深入理解文本中引起幽默的元素,以及幽默产生的影响,智能人机交互系统除了具有区别笑话和非笑话的能力,笑话结构和幽默意图是计算机理解幽默的必要知识.任璐等[23]对笑话语料库构建所需的幽默理论基础及标注分析工作进行总结,收集了涵盖故事、新闻、谚语/歇后语、微博4种不同体裁、不同来源、不同场景的33,025条笑话.Tseng等人[24]构建了一个具有人工标注幽默技巧、意图和幽默度的笑话语料库.该语料库包含3365个笑话,每个笑话被标注五级幽默程度,8个幽默技巧,以及六维幽默意图.Zhang等人[25]创建了一个含有9123条样本并标注了关系、幽默发生场景、幽默类型、幽默等级、触发幽默的关键词以及数据来源的幽默分析数据库,不仅可以用于幽默分类任务,还可用于幽默锚点识别、幽默生成等任务.表3给出一些幽默语料库的正负样本统计信息.

表3 幽默语料库正负样本统计Table 3 Positive and negative samples′ statistical information of some humorous corpura
4 模型与方法
在幽默识别模型与方法方面,一些研究人员致力于提高传统机器学习算法的表现并将其用于幽默识别;一部分研究人员尝试改进经典的神经网络结构,例如循环神经网络、卷积神经网络,来学习更好的幽默语义表示;最近,许多研究人员集中于使用预训练模型,例如Glove、BERT等,来更好地执行幽默识别任务.
4.1 基于传统机器学习的幽默识别
识别幽默通常需要语境、常识以及文化背景等经验知识的综合理解,精准识别文本中的幽默仍然具有挑战性.早期的幽默识别研究中,大部分方法是基于语言学特征,使用传统机器学习方法进行二元分类,即判断给定的文本是否幽默.传统机器学习方法进行幽默识别的流程如图2所示.
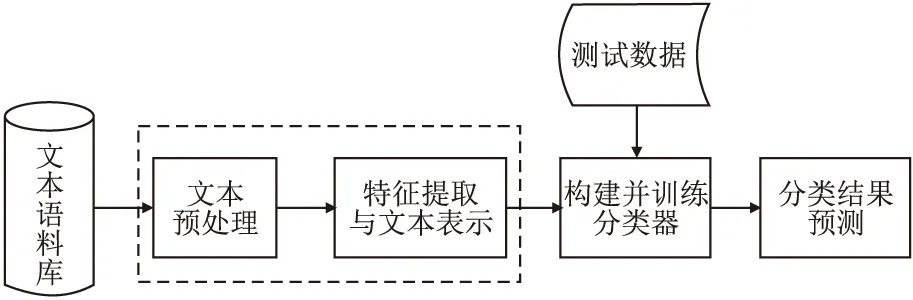
图2 基于传统机器学习的幽默识别流程Fig.2 Humor recognition procedure based on traditiaonl machine learning
Mihalcea和Strapparava[4]定义了一组基于幽默理论的启发式特征,例如头韵、反义词、成人俚语等,同时学习基于文本内容的特征,然后利用支持向量机和朴素贝叶斯算法进行幽默识别.在16000OL数据集上的实验结果表明,头韵在单句笑话幽默中是一个重要因素,而单独使用成人俚语特征效果仅比随机预测稍有提高.主要原因之一是缺少专门的成人俚语词典资源,并且成人俚语一般比较敏感,在幽默文本中出现的频率不高.实验分别使用4种不同文体的负样本,结果相差较大,使用BNC语料库的效果最差的原因在于BNC中文本风格多样,仅使用头韵、反义词、成人俚语特征并不能将幽默文本与其他文本区分开,而单句笑话使用传统机器学习算法无法学习更多的上下文信息.该研究为幽默二元分类提供了j重要的数据支持,不足之处是尚未给出能更好挖掘幽默的特征.
Yang等人[2]基于幽默理论,从不一致性、模糊性、个人风格和语音的声调韵律4个方面定义幽默特征,并与word2vec[26]相结合,使用随机森林训练幽默文本分类器,执行幽默二元分类任务.实验结果表明,这些人工设计的特征结合word2vec取得的效果优于单独使用word2vec或语言模型的效果,说明将幽默语言学特征与词嵌入相结合能够取得比较好的效果.除此之外,他们还提出了一种识别幽默锚点的方法.幽默锚点的识别可以进一步提高幽默分类的性能,特别是对于幽默的细粒度分类任务.因此,未来可将幽默锚点识别作为辅助任务,与幽默分类进行联合学习,进一步提高幽默分类的性能.目前,该研究成果已成为幽默二元分类任务的重要基线.
Cattle和Ma[12]结合统计学习方法特征的良好解释性和神经网络方法自动表征学习的优势,设计了基于词语间关联的语义特征,自动进行笑话语义和结构特征学习,并将幽默锚点的提取任务整合到幽默分类过程中.使用随机森林分类器的实验结果表明,在PoTD和16000OL数据集上的实验结果表明,单词关联特征比word2vec[26]相似度特征对于幽默识别任务更有用.Liu等人[27]认为幽默是一种文体,与句法结构相关,幽默文本和非幽默文本具有一些不同分布的句法结构.基于此,设计了3种类型的句法结构特征:结构元素统计特征、句子的构成规则特征、元素间依赖关系特征.以Yang等人[2]的研究为基线,使用随机森林分类器,在数据集16000 OL上F1值提高了7.2%.这表明,句法结构特征可以显著弥补基于幽默理论的特征的不足.句法结构特征之所以能够在幽默识别任务中发挥重要作用,一方面是因为幽默文本用词简单但句法结构复杂,同时幽默文本是生动而具体的,多出现于人们日常对话中.
Castro等人[20]的研究是首次挖掘西班牙语幽默的工作,收集了来自Twitter幽默账户的西班牙语幽默文本语料,建立多项贝叶斯结合词袋的模型作为基线,比较了SVM、DT、GNB、MNB以及KNN的实验结果.其中,SVM取得了最佳效果,F1值达到75.5%,准确率为83.6%.根据“优越论”和“宽慰论”,幽默文本中应该普遍存在情感信息来表达情感对比或情绪变化.Liu和Zhang[28]认为建模篇章级的情感关联特征比简单统计情感词的特征对于幽默识别任务来说更有效.他们定义了3种情感关联关系:情感冲突、情感转换、语篇关系,使用随机森林作为分类器.实验结果表明,结合语篇关系的情感关联特征相对于情感词数量是更有效的特征.未来可以将情感极性预测作为辅助任务,帮助提高幽默识别的效果.樊小超等[29]从不一致性、模糊性、情感特性、语音特性和句法结构特性5个维度构建了30多种幽默特征,并对比使用不同分类器的效果,在数据集16000OL和PoTD上的实验结果表明,基于不同维度设计合理充足的特征能有效表达幽默信息.
由于短文本包含的上下文信息较少,因此基于上下文内容的特征有时并不能有效表达幽默,并且语言的多样性也增加了幽默识别的难度.基于传统机器学习的幽默识别方法的研究重点在于如何设计特征以能够捕获幽默含义,该类方法结合词嵌入能有效提升效果.基于传统机器学习的方法建立一个表现优秀的幽默识别模型,不仅需要研究者对幽默理论和幽默语言学有深入了解,而且需要大量的外部知识和文化背景.幽默识别特征工程工作的困难繁杂是制约传统机器学习方法幽默识别性能的一个重要因素,大部分幽默特征的设计并不是系统地从幽默理论中衍生出来的.
4.2 基于深度学习的幽默识别
虽然传统机器学习模型简单高效,但其面临的一个主要问题是文本表示的高维度高稀疏问题,特征表达能力弱.随着云计算和大数据技术日益成熟,计算机算力和存储容量有了大幅度提高,深度学习时代迅速到来.幽默识别任务可以使用深度学习模型,利用海量数据进行端到端的训练,无需人工干预特征的选择过程.深度学习方法的工作重点是模型的构建和调参.基于深度学习的技术使用大规模数据训练幽默计算模型,可以完成不同类型的幽默识别任务.基于深度学习的幽默识别主要流程图如图3所示.
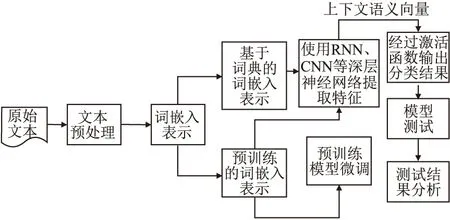
图3 基于深度学习的幽默识别流程Fig.3 Humor recognition framework based on deep learning
4.2.1 基于卷积神经网络的方法
卷积神经网络[30](Convolutional Neural Network,CNN)不仅是计算机视觉领域的核心技术,在自然语言处理领域也取得了重要进展.卷积神经网络包括一维卷积神经网络,二维卷积神经网络和三维卷积神经网络.其中,一维卷积神经网络主要用于序列类型数据的处理,二维卷积神经网络常应用于图像、文本数据的处理,三维卷积神经网络主要应用于视频数据的处理.若将文本看作一维序列数据,使用循环神经网络来表征文本比较自然.若将文本看作一维图像,则可以使用一维卷积神经网络捕捉上下文的词间关联.CNN提取文本特征的基本原理,CNN网络的输入为文本的词嵌入向量,输入会经过不同的卷积和池化层,每层卷积可使用不同的卷积核进行计算,以此学习文本更丰富的特征.
将CNN应用于文本分析的开创性研究是Yoon Kim提出的TextCNN[31].TextCNN主要使用了一维卷积层和时序最大池化层,该模型对文本表示执行整行卷积操作,保证了单词的语义完整性.Chen和Lee[32]弥补了CNN应用于幽默识别缺乏严格实验对比的缺陷,同时探索了CNN网络提高幽默识别性能的重要技术,比如改进CNN网络结构,提高网络学习幽默特征的能力.该研究收集了一个开放的在线演讲语料库TED Talks,来识别TED演讲中的幽默.该语料库的正样本和负样本都来源于演讲对话,这尽可能减小了由于数据主题不同而产生的效果偏差.在PoTD数据集上的实验结果表明,基于CNN的幽默识别模型相对于传统基于语言知识的模型具有极大优势,但在TED Talk上的准确率和F1的值均低于PoTD上的结果.可能原因是PoTD中的样本长度较短,CNN能够更好学习短文本的语义表示.
Chen和Soo[15]提出了一种CNN结合高速公路网络(Highway Network)[33]的幽默识别模型,降低网络规模以提高训练速度,缓解了随着网络深度增加模型训练困难的问题.高速公路网络使用门控单元来调节通过网络的信息流.该模型依次由词嵌入层、卷积池化层、高速公路网络层和全连接层构成.在数据集16000OL、PoTD、Short Jokes、PPT Jokes上进行了大量实验,F1的值分别高达0.903、0.901、0.924、0.943.这表明该网络模型不仅可以学习单句笑话、双关语以及短文本等不同类型的幽默含义,还可以实现多语言的幽默识别.但其仍难以识别更微妙的幽默,模型结构还有较大的改进空间.由于CNN可以自动学习文本适用于当前任务的表示特征,这使它可以在不同语言的分类任务上取得很好的性能.Winters和Delobelle[34]在基于负样本生成方法构建的荷兰语幽默识别数据集上,使用卷积神经网络、长短期记忆网络等不同模型比较验证识别来自不同领域幽默文本的能力,其中CNN识别谚语的表现良好.
CNN虽然可以表示文本、视频等时间或序列数据,但无法对位置信息进行建模.幽默与语境存在较大的依赖关系,未来可在CNN模型中加入位置或序列信息,进一步表达引起幽默的不一致性、歧义性.目前将CNN用于幽默识别任务中的改进方面主要体现在不断往CNN架构中加入新的幽默特征,其实质还是手工设计特征的另一种表现形式.
4.2.2 基于循环神经网络的方法
CNN虽然可以成功识别一些短文本序列特定类型的幽默,然而在理解更长序列文本中的的微妙幽默方面存在不足,并且CNN的输入和输出长度都是相对确定的.当训练样本是连续的长度不一的文字序列时,很难将其拆分为一个个独立的样本来单独训练CNN.而循环神经网络(Recurrent Neural Network,RNN)对于处理序列数据十分有效.RNN可以将任意长度的序列数据转换为数值向量.几种典型的RNN结构包括长短期记忆网络(Long Short-Term Memory,LSTM)[35]、门控循环神经网络(Gated Recurrent Unit,GRU)[36]以及变体.LSTM已经被广泛用于语音识别、语言建模、情感分析及文本预测等任务,其使用门控机制控制记忆过程,可以极大程度缓解传统RNN在训练过程中存在的梯度消失和梯度爆炸问题,可以学习词语、句子或段落之间的长距离依赖关系.LSTM具有庞大的参数矩阵,计算代价较高.2014年Cho等人提出的GRU,效果与LSTM相当,但参数更少,更易于训练.
Bueno等人[37]提出了一种语言学特征与注意力机制相结合的循环神经网络模型用于幽默识别,设计了语音声调韵律特征、语言内容和结构特征、情感特征,将融合这些特征的词嵌入输入循环神经网络.实验结果表明,语言学特征与深层分布式语义表示相结合能进一步提高幽默文本识别的效果,但是该模型无法有效降低幽默程度预测回归任务的均方根误差RMSE.可能的原因之一是这些人工设计的语言学特征对于文本的有趣性质失效,得到的语义向量表示与实际的有趣语义差异较大.Bertero和Fung[38]综合了CNN和LSTM对日常情境中的幽默识别问题进行研究,目标是在一个自发的对话情景中预测何时会引发观众的笑声.采用的语料库来自于情景喜剧“生活大爆炸”(英文名:The Big Bang Theory),将剧本分为多个语篇,每个语篇包含多段对话.使用CNN为对话进行编码,编码特征包括独热编码和word2vec特征等,使用LSTM编码对话的上下文序列信息,并结合语言学统计特征,例如情感、词性特征等,用于幽默笑声的最终预测.实验结果表明,与条件随机场基线相比,效果得到大幅度提升.该研究设计的幽默特征比较详细,涉及了结构、词、情感、笑点位置等多个方面.
Garain[39]构建了一种基于双向LSTM(BiLSTM)的网络结构用于HAHA比赛中的幽默分类和幽默评级任务.数据样本来源于比赛发布的推文数据集.经过初步数据清洗,对其进行手工特征设计,例如情感词的数量和特殊标点符号的数量,与经过独热编码的特征向量结合,共同输入到BiLSTM网络.同时,为了解决训练数据的标签类别倾斜带来的高准确率问题,设计训练停止条件并将类标签权重引入训练过程中.该研究的实验结果表明,BiLSTM可以很好地学习上下文幽默信息,但F1值不高.可能的原因一是训练数据规模不大,而网络参数规模较大,二是特征设计与学习不充分.未来可在此基础上引入领域知识.Sane等人[40]为了解决英语-印地语双语混合推文上的幽默分类问题,提出了将CNN、BiLSTM、BiLSTM结合注意力机制的深度学习模型学习双语的幽默语义表达,其中BiLSTM结合注意力机制模型取得了最好的效果,准确度达到73.6%.他们提出的深度学习模型结构简单,仅运用了简单粗粒度的注意力机制,未来使用更复杂精细的注意力机制预计可能会进一步提升效果.
Fan等人[41]构建了词对(word pair)间内部注意力网络和句子间外部注意力的BiLSTM网络,分别计算可能导致幽默的单句的词语对最大语义冲突和句间词语多重含义的贡献度.在PoTD和16000OL上的实验结果表明,结合内部注意和外部注意的神经网络可以较好地表达词间的复杂关系以识别幽默.然而,实验数据的幽默类型相对单一,并且能否很好识别较长文本中的幽默还未可知.
未来可在识别更长文本中的幽默或识别更多类型的幽默方向开展工作.Li[42]等人为研究俚语和表情符号对中文细粒度情感分析效果的影响,构建了包含576个中文常见的俚语词典和包含109个微博表情符号的词典,并将这两种词典应用于基于注意力机制的BiLSTM神经网络.实验结果显示,俚语和表情符号作为幽默情感表达中的重要元素,可以很大程度上提高中文情感预测的表现.该研究的不足在于其俚语词典和表情符号词典是基于特定社交媒体和数据构建的,领域迁移和泛化能力相对较差,且随着社交网络的不断发展,网络新词和新的表情符号也会不断涌现,词典的更新维护较困难.Ren等人[43]设计了一种幽默识别与双关语检测进行联合学习的多任务学习框架,使用Bi-LSTM编码句子表示,使用注意力机制获得词语的不同权重,共享幽默和双关语的共同特征,与单个任务的私有特征进行融合,实验结果验证了多任务学习和注意力机制在幽默识别和双关语识别任务上的有效性.
由于幽默常出现于人们面对面的社交活动中,伴随手势、声音韵律的语言通常会使幽默表达更加丰富.因此,文本结合听觉、视觉信息进行幽默识别近期受到了更多的关注.Hasan等人[17]在其构建的多模态幽默数据集UR_FUNNY上进行笑点检测,即检测给定文本是否会在笑点触发后立即引起笑声.他们分别对不同模态数据(文本、声音、画面)进行特征提取,然后在记忆融合网络结构基础上,提出了一种 上下文记忆融合网络(C-MFN模型),提取上下文多模态幽默信息.实验结果表明,C-MFN在UR-FUNNY上的准确率达到65.23%,而人类在UR-FUNNY上的准确率为82.5%,这说明多模态数据的幽默识别还有较大的进步空间.同时说明笑点和语境对于幽默识别非常重要.
卷积神经网络需要开发者确定精确的模型结构并且超参数调节过程十分耗时,而循环神经网络能够便捷地实现多层网络堆叠,例如BiLSTM或多层GRU等,且超参数数量不多.对于双关语、单句笑话等短文本类型的幽默识别,卷积神经网络比较适合获取短文本的幽默语义表示,而循环神经网络适用于对话型幽默文本识别任务中.因此,可探究CNN-RNN网络的组合方法进行幽默语义挖掘.例如,杨勇等人[44]详细设计了语音、字形以及语义等语言学特征,并与层次注意力机制相结合进行幽默识别,使用CNN提取语音特征、BiGRU提取字形和语义特征,采取层次注意力机制整合这3种特征,以获得不同特征对幽默表达的贡献度.Ren等人[45]将幽默语言学理论与深度学习方法相结合,使用CNN、Bi-LSTM结合注意力机制提取语音、词汇语义、语法及上下文语义特征,同时使用注意力机制获得不同特征的重要程度,该方法在基于幽默本质的前提下提取抽象深层特征,结果表明该方法能有效识别双关语、单语笑话等类型中的幽默.
4.2.3 基于预训练词嵌入的方法
目前神经网络在训练时,一般基于反向传播(Back Propagetion,BP)[46]算法.训练时先对网络参数进行随机初始化,再利用梯度下降等优化算法不断优化模型参数.而预训练的思想是,模型参数不再是随机初始化的,而是先进行预训练,得到一套模型参数,然后用这套参数对模型进行初始化,再基于特定任务和数据继续进行模型训练.
BERT[47]是一种基于Transformer[48]的双向编码器,使用掩码语言模型(Masked Language Model,MLM)和下一个句子预测(Next Sentence Prediction,NSP)双任务训练模型,充分描述字符级、词级、句子级以及句间关系特征.相比于循环神经网络,可大幅度降低训练时间.RoBERTa[49]在BERT的基础上进一步训练,取消了NSP预训练任务,改进了训练方法,使用更大规模的数据进行训练,进一步增强了模型的泛化能力,其GLUE基准测试结果优于BERT.ALBERT[50]为了减少BERT及其相关模型的训练时间,使用剪枝、蒸馏等技术减小网络规模,但是模型的性能有所下降.为了缓解上述问题,Sanh 等人提出了DistilBERT[51]模型,使用知识蒸馏方法压缩原生BERT模型,在保留BERT的95%性能基础上,将模型参数规模减少原生BERT的一半.而He等人[52]提出的DeBERTa模型为解决BERT模型预训练和精调的不匹配问题,引入一种增强型掩码解码器,同时进一步增加了序列的相对位置信息,使用解耦注意力机制.
目前,幽默识别研究的关注焦点转移至基于预训练模型的方法上.Weller等人[53]从Reddit网站收集了一个幽默数据集,首次提出基于Transformer的幽默识别方法.在Short Jokes、PoTD和其从Reddit爬取的数据集上的实验结果表明,相较于单独使用CNN和RNN等方法的效果有了大幅度提高.该研究一是针对于大部分Reddit用户认可的幽默类型,这表明未来可以从特定人群中学习幽默表达;二是将笑话的笑点与铺垫分开,重点关注笑点在幽默表达中的作用.Mahurkar和Patil[54]使用BERT及其衍生模型RoBERTa、ALBERT及DistilBERT对SemEval-2020 Task 7新闻短文本幽默评分问题进行研究.在Humicroedit和FunLines数据集上的实验结果表明,BERT及其衍生模型经过微调便可以很好适应幽默评分任务,可以将注意力集中在新闻标题中经过编辑的部分.使用跨数据集交叉验证的实验结果表明BERT在不同数据集之间的泛化能力较强,这进一步说明注意力机制在幽默检测中具有良好的应用前景.为了从语言学角度更好理解幽默,Wang等人[55]认为“铺垫”和“妙语”是笑话的核心.一般认为,笑话的“铺垫”和“妙语”之间存在语义冲突,但是由于笑话一般是短文本,理解幽默需要丰富的先验知识,因此将预训练模型应用于幽默检测是合适的.他们提出一种用于幽默检测任务的数据增强方法,同时提出一种衡量句子对之间差异性的方法,最后将幽默类别预测与句子间差异预测结合,共同用于幽默检测.该模型建立在Multilingual_BERT的基础上,因此可以检测汉语、俄语、西班牙语等中的幽默.实验结果表明,在3种语言上,F1值与传统神经网络模型相比提高了4%-6%,这说明了该方法检测多语言幽默的有效性.
Guo等人[56]研究了文本幽默性和用户偏好之间的相关性,不仅提出了一种使用用户偏好因子为SemEval-2020 Task 7数据集生成隐式幽默标签的方法,同时提出了一种基于BERT的联邦学习模型,能够同时考虑文本幽默分数和幽默标签来预测不同用户的个性化幽默表达.Ballapuram[57]在孪生Transformer基础上构建了双输入孪生BERT网络,利用语言模型进行微调,结合局部注意力和全局注意力机制完成了SemEval-2020 Task 7发布的两个幽默识别子任务.该研究的实验结果表明关键词结合其上下文的语义向量能很好地识别语境中的幽默.Ismailov[58]提出一种基于模型集成的方法,将经过微调的多语言BERT模型与基于TF-IDF的朴素贝叶斯模型集成用于幽默二元分类任务,将BERT模型与LightGBM(Light Gradient Boosting Machine)模型集成用于幽默评级任务.同时,为了解决过拟合问题,采用不同网络层不同学习率的策略,使用无监督学习对BERT模型进行微调,分类任务F1的值为0.821,评级任务的F1值为0.736.Farzin等人[59]提出一种基于预训练模型ULMFiT[60]的微调方法,用于HAHA-2019比赛的幽默识别任务.为了避免预训练网络参数规模过大导致过拟合现象,收集了475,143条推文完成语言模型的预训练,结合标签平滑技术逐步解冻预训练网络,使用交叉验证和随机种子初始化,在微调过程中选择最佳模型,最佳模型F1的值为80.99%.Xie等人[61]使用SemEval-2021 Task 7数据集微调DeBERTa模型,在幽默二元分类、幽默程度评分等任务中取得了良好性能.Hasan等人[62]为了研究多模态数据中的幽默,使用预训练模型ALBERT获得文本表示,使用Transformer编码器获得声音、图像的特征表示,同时引入基于幽默理论的特征作为知识源嵌入,设计多模态特征融合层获得模态的统一表示,在数据集UR-FUNNY上的实验结果表明该方法能大幅度提高多模态幽默识别的表现.
目前,预训练语言模型的通用范式是:1)基于大规模文本,预训练得出通用语言表示;2)通过微调,将学习到的通用知识迁移到不同的下游任务中.在微调过程中,每种预训练模型在不同任务中的用法不同.预训练模型结构和训练方法不断创新,从单语言到多语言,从单一模态到多模态,为自然语言处理技术进入“工业化”时代奠定了坚实基础.深度神经网络由多个隐藏层组成,具有更高的复杂度,并且可以在非结构化数据上进行训练,直接从输入中学习特征表示,无需太多的人工干预和先验知识.但是,深度学习技术是一种数据驱动方法,通常需要大量数据才能实现高性能.目前在幽默识别领域,大规模高质量的幽默语料库仍然是一个亟待解决的问题.尽管基于注意力机制可以为一些单词间的语义带来可解释性,但与浅层模型进行比较并不足以解释其原因和工作方式,它目前实质上仍然是一种“黑箱”模型.
自然语言处理领域的一些国内和国际比赛推动着幽默计算领域的发展.新的幽默计算任务、幽默计算语料库以及模型方法被陆续发布.本节介绍目前关于幽默识别任务的一些主要比赛.SemEval-2017 Task 6(#HashtagWars)[63]重点是对一个电视节目的推文的趣味性进行排名,#HashtagWars数据集自电视节目“@midnight”,共有12,000条推文,每条推文被标注了满分为3分的幽默分数.SemEval-2017 Task 7[64]关注双关语的自动检测、定位和解释,SemEval-2018 Task 3[65]对推文中的讽刺现象进行检测.SemEval-2020 Task 7[66]的目标是确定机器如何理解文本经过短编辑后产生的幽默感.SemEval-2021 Task 7主要预测文本是否幽默以及文本的幽默程度,同时预测文本的冒犯程度(0-5).数据标注来自18-70岁不同的年龄段人群,该任务是第一个将幽默和攻击性结合的任务.HAHA大赛检测并评价西班牙语中的幽默[67].中文幽默计算比赛主要来自中国计算语言学大会(CCL)举办的“小牛杯”中文幽默计算比赛(见本文3.2.3节).
4.3 不同幽默识别方法对比分析
表4给出了一些重要幽默识别方法的性能比较.可以看出,基于预训练模型的方法在幽默二元分类任务上取得了较好效果,但对于幽默程度评级任务、笑点检测任务等还有很大的提升空间.分析这些主流方法可以预测基于预训练模型的方法结合设计合理的幽默特征可以进一步提高任务性能.表5从核心思想、适用情景、优势及局限性等维度对不同类别幽默识别方法进行了对比分析.
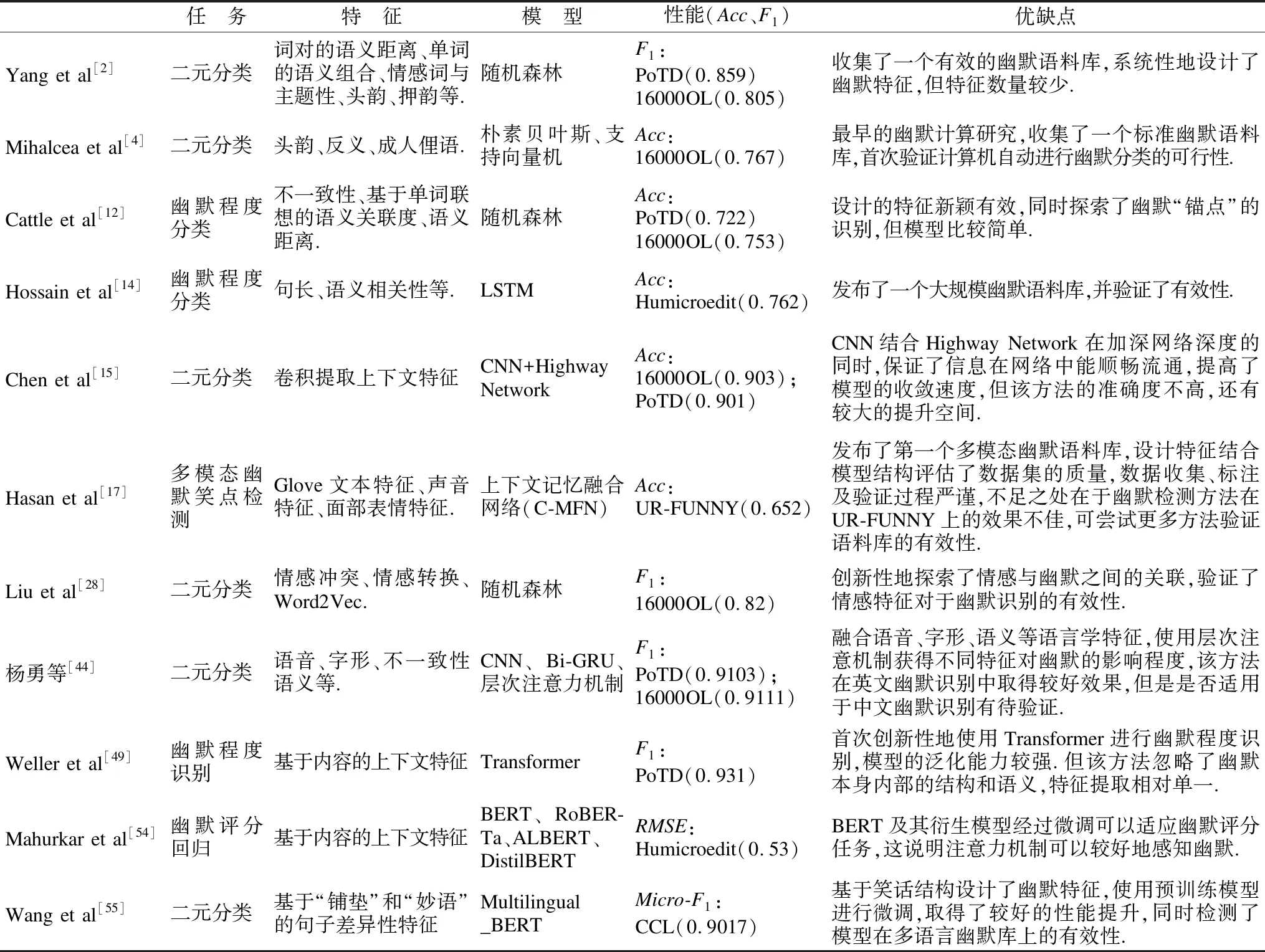
表4 幽默识别相关研究方法对比Table 4 Comparison of some researche of humor recognition

表5 不同类别幽默识别方法对比分析Table 5 Comparison of different types of humor recognition methods
5 结 论
幽默是人类交流中自然而又重要的组成部分.从认知学角度来看,幽默是以隐喻来代替字面含义以强调思想和感情的载体.但从计算语言学角度看,幽默识别具有挑战性,语言计算模型本质上并不具备人类判断和传达幽默的先验知识.因此,需要探索不同特征、模型、方法来使计算机识别和生成幽默.未来幽默识别领域要解决的重要问题:1)语料库的构建问题.由于目前幽默识别的研究主要集中在基于数据驱动的深度学习方法上,大规模高质量的幽默语料库的构建仍然是一个复杂昂贵而繁琐的问题.这不只包括单一模态语料库的创建,多模态语料库的构建将会更有意义;2)如何使计算机学习幽默背后的本质原理以及深层语义,例如探索结合知识库和知识图谱的文本学习深度网络模型;3)多模态数据的幽默识别、多语言幽默识别以及跨主题的幽默识别研究将是未来的研究重点.最后,在幽默识别研究的基础上继续探索幽默生成领域是一个有趣的方向.
