基于过离散数据下的模型选择
2022-03-30重庆工商大学数学与统计学院杨小藜
◇重庆工商大学数学与统计学院 杨小藜 孙 荣
本文针对一组具有过离散特征的保险索赔数据,采用对比分析的研究方法分别对泊松回归、负二项回归模型、泊松-逆高斯模型以及零膨胀泊松模型和零膨胀负二项模型进行探讨,主要采用AIC和BIC信息准则对模型加以比较。最终拟合结果显示,负二项回归模型和泊松-逆高斯对过离散型索赔数据的拟合效果相当,且两者均比泊松回归和零膨胀模型更佳;综合看泊松-逆高斯模型的效果表现为最佳。
1 引言
根据某一属性或类别先分组计数,再汇总后得到的信息称为计数型数据,它的变量值是定性的而且取值常常是非负的整数;日常生活中,像保险索赔次数、车流量、旅游景区数、访问人数等等都可当作计数型数据研究分析。对于计数型数据,线性回归是最早使用的领域,但因为该模型要求因变量服从连续型或至少为准连续型而造成它的运用受到限制;后来泊松回归模型逐渐走入人们的视野,该模型要求方差与均值相等;特别是在精算领域,关于风险费率厘定方面的问题,泊松回归模型一度受到欢迎。尽管如此,由于保险公司在划分保单类型时,被归为同一类的保单并非没有差别,往往存在异质性,说明在实际应用中的确存在方差大于均值的情况,也就是过离散现象。如果在存在过离散问题的情况下仍然采用泊松回归模型,那么从拟合结果能够明显发现参数的标准误差被低估,显著性水平被过高估计的问题,最终就会影响模型的准确与客观性。对于这样的过离散现象,杨肇(2003年)[1]等人在logistic回归分析中提出了通过Pearson和Deviance统计量以及Williams法进行纠正;Noriszura Ismail和Abdul Aziz Jemain(2007年)[2]提出可以处理过离散问题的负二项和广义泊松模型,并在三组不同的索赔频率数据上通过拟合、检验,比较了Poisson、负二项和广义Poisson的乘法与加性回归模型。Richard Berk 和 John M.MacDonald(2008年)[3]讨论了回归模型在计数型数据中的应用,而且证明了在犯罪学应用中,只有在特殊情况下使用负二项分布才能解决过离散问题。徐飞(2009年)[4]针对具有过离散现象的一组车险数据讨论并应用了两种分布形式的负二项分布模型。徐昕(2010年)[5]等人基于车险损失数据推出的三参数负二项回归模型有效地改善了拟合效果,但是参数越多计算量会越复杂。曾平(2011年)等[6]总结对比了可以检验是否存在过离散现象的四种方法。乔舰(2016年)[7]等人对过离散问题形成的原因进行了论证,即根本问题是类内样本数据具有非齐次性和正相关性。
文章的主要工作是针对一家保险公司的索赔次数数据,对仅含主效应和含有交互效应的不同方程分别采用泊松回归模型、负二项回归模型、泊松-逆高斯模型以及零膨胀泊松、零膨胀负二项模型加以拟合,最终的拟合结果说明泊松-逆高斯模型的表现最佳,负二项模型的效果与之近似,两个模型相较于泊松回归模型和零膨胀模型更适合用于拟合具有过离散特征的索赔数据。
2 模型理论
(1)在车险索赔数据中,对于索赔次数的分析最常用的是泊松回归模型,而对于过离散的问题,我们有相应的负二项分布和泊松-逆高斯分布,这两者都是混合泊松分布,负二项分布是泊松与伽马分布的混合分布;泊松-逆高斯分布是泊松与逆高斯的混合分布。
(2)零膨胀模型是指:当观测值有零膨胀现象且因变量服从相应分布时的零膨胀回归模型。
(3)概率密度函数为:
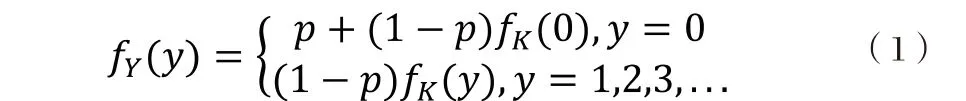
(4)在医疗、精算等领域,当人们对此类数据进行研究之前通常会做过离散检验。2011年曾平[6]在文章中总结出了过离散检验的几种方法,分别是O检验、残差检验、得分检验以及拉格朗日乘数检验。文中所用的五个模型中,只有泊松回归模型的均值与方差相等,其它几个模型均满足方差大于均值的条件,在实证分析中将通过比较这五个模型来选择出最适宜拟合过离散车险数据的模型。
3 模型比较
3.1 AIC和BIC信息准则
当模型的样本量差异不大时,所用的AIC和BIC信息准则为:
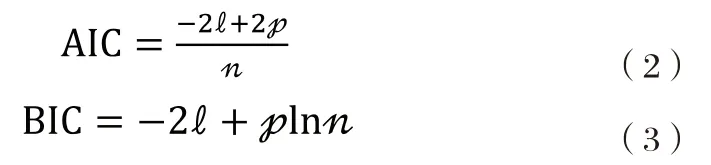
3.2 分位残差和QQ图
对于因变量的不同类型,通常分为连续型和离散型,相应的分位残差是不同的,离散型因变量的分位残差表现为随机性,故称为随机分位残差图。由于分位残差和随机分位残差近似服从标准正态分布,所以相应图形与正态分布的贴合程度能够体现出模型的拟合效果。QQ图即标准化残差QQ图,当QQ图的分布近似表现为一条直线时,说明了正态性假设得以满足,也即模型的拟合结果比较理想。
4 实证分析
4.1 数据描述
文章使用的索赔次数数据来自某汽车保险公司[8],影响因素共涉及三个因素,分别是:
汽车类型(type)分为4个水平:A、B、C、D;
车龄(vage)分为4个水平:0-3、4-7、8-9、10+;
投保人年龄(age)分为8个水平:17-20、21-23、25-29、30-34、35-39、40-49、50-59、60+[9]。
按照以上三个因素可以设置128个风险单元,将车龄和年龄两个变量都当做分类变量处理,将汽车类型A、车龄0-3年以及年龄17-20岁设为基准水平。
根据以上要求来定义如下回归方程:
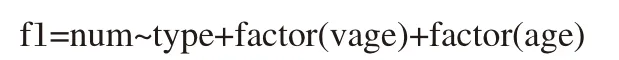
考虑含有交互效应的情况:
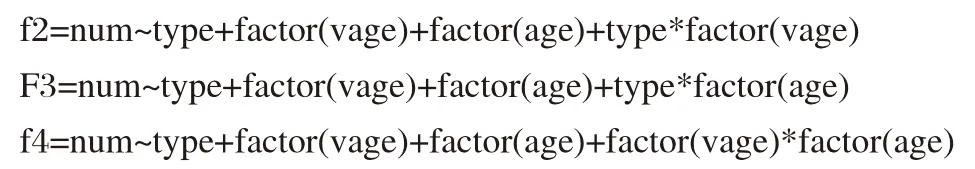
对索赔次数初步分析知,该保险索赔次数的均值为71.1484,方差为9260.7258,方差远大于均值,可以看出该类数据具有明显的过离散现象。
4.2 模型比较

表1
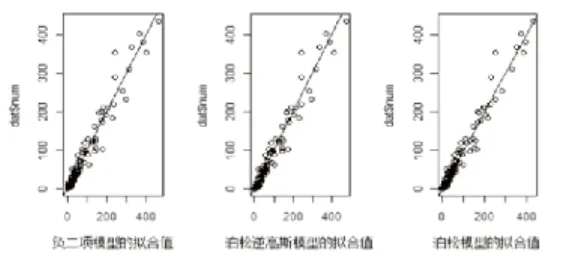
图1 模型拟合值
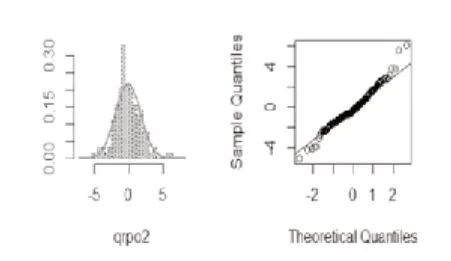
图2 泊松回归模型

图3 负二项回归模型
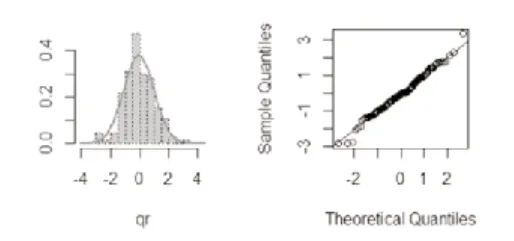
图4 泊松逆高斯模型
4.3 结论及分析
实证结果表明,首先是考虑了含有交互效应的模型的AIC和BIC值明显优于不含交互效应的模型;而且在所有含有交互效应的模型中,效果最优的是含有车型(type)与车龄(vage)的乘积因素以及三个主效应因素的回归模型。其次从对比各个模型来看,零膨胀泊松、零膨胀负二项模型都没有体现出本身的优越性,因此可以排除该类索赔数据存在零膨胀现象的可能性;也可以说明虽然以上两个模型的分布都具有过离散特征,但是并不适用于此类数据。
在考虑了车型和车龄的交互效应之后,可以看到索赔风险降低,其中风险最小的是车龄在10年以上的D型车,最高的是车龄为4-7年的B型车。单通过车型的估计结果来看,B型车存在的索赔风险最大,D型车的风险最低。通过比较车龄的估计结果知,车龄越小的车具有越高的索赔风险,而越老的车风险越低,这有可能是因为对于越老的车司机越重视其安全系数以及更加注重汽车维修保养等从而降低了保险索赔次数。从投保人年龄来看,索赔风险最高的是40-49岁之间的投保人,且对于小于50岁的投保人存在年龄越大风险越高的趋势,也就是说随着年龄增加,有可能因为反应变慢、安全意识降低等因素增大了事故发生可能性。
比照泊松回归模型与负二项回归模型和泊松-逆高斯回归模型,泊松回归模型的标准误差明显低于后两者模型,也可以说参数的标准误差在泊松回归模型中被低估,而参数的显著性被过高估计,这就导致模型其实有失准确性与客观性;反之,负二项回归模型与泊松-逆高斯模型的AIC和BIC值虽然不相同但两者并没有特别突出的差异,并且和泊松回归模型比较发现它们的拟合效果更优。再从三个模型的拟合值来看,也反映出泊松回归模型的拟合效果相对较差;最后通过随机分位残差图和QQ图更是能区别出泊松回归模型的拟合结果比其余两模型都差一些。综上,负二项回归模型和泊松-逆高斯模型相较于泊松回归模型更适合用于拟合存在过离散问题的车险索赔数据。
5 结束语
本文首先通过一组汽车索赔次数数据,对比了在考虑交互效应和不考虑交互效应下,模型的优良性;针对此次索赔数据,零膨胀泊松模型、零膨胀负二项模型虽然具有过离散特征,但并没有展现很好的拟合效果,说明数据不存在零膨胀特征;对比分析了当存在过离散现象时,负二项回归模型与泊松-逆高斯模型的拟合效果差异不突出,并且两者都比泊松回归模型更加准确、客观,综合看表现最好的为泊松-逆高斯模型,所以可以优先考虑该模型。
