融合K值算法与三指标的神经科学领域“睡美人”论文识别及影响因素探析
2022-03-11胡泽文任萍沈佳慧
胡泽文 任萍 沈佳慧








关键词:“睡美人”论文;神经科学;K值算法;三指标法;被引延迟指数;计量特征;影响因素
科学技术传播方式的变革不断改进科技文献的开发与利用渠道,促进科学研究的价值发现与学术影响力提升。如何评价科学研究的价值和学术影响力,引起国内外学者的广泛关注,科技文献价值的评价、识别与推荐研究越来越受到学术界的重视。然而,现阶段学者关注更多的是单篇文献的指标体系设计与综合评价,评价指标较多且评价过程复杂。论文发表之后的引用轨迹能够在一定程度上反映学术论文受国内外学者的认可程度,因此,基于论文引用频次随时间的动态变化规律,从海量文献中识别出已公认高价值的“睡美人”论文显得更为高效简单。通常,科技文献出版之后的引用轨迹呈现出3类特征:①文献发表之后很长时期未受到任何引用或很少引用,即零被引或低被引文献;②文献发表之后快速达到引用高峰,成为高被引或热点文献;③文献发表之后很长周期内未被及时发现或引用推广,直到多年后才被发现和广泛使用,即“睡美人”论文。“睡美人”论文从科学计量学的角度,动态刻画了文献的引文特征及其随时间变化的历史过程,定量描述了各学科的前沿研究或变革性研究。超前研究和变革研究是“睡美人”论文形成的重要表现形式。超前研究是对现有研究的超越,由于科研人员并不了解该类研究的巨大潜在价值,所以往往被忽视;变革性研究会因为与主流研究的碰撞和不被科学界接受,而经常受到抵制。“睡美人”论文往往包含着重要的研究成果,对其进行识别、评价与推荐,能够充分发挥“睡美人”论文的巨大科学价值与现实指导意义。
早在20世纪60年代,已经有科学家关注到了科技文献中的“睡美人”现象。1989年,美国科学索引之父GarfieldE[1]提出了“延迟承认”这一理论,指的是发表初期未受到重视,但经过一段时间后突然高被引的文献。2004年,RaanAFJ[2]首次提出并定义“睡美人”论文的概念内涵,同时提出了识别“睡美人”论文的主观指标法。作者将“睡美人”论文的睡眠特征指标定义为:沉睡期大于等于5年,沉睡期年被引小于等于2次,且在唤醒后4年引用窗口被引频次大于20次。2012年,OhbaN等[3]将“睡美人”论文的睡眠周期界定为7~59年,平均19.7年,睡眠期内的年均被引频次处于0.09~0.82之间,平均为0.45,在唤醒后的前5年中,年均被引频次在3.60~17.80之间波动,平均被引用次数为8.51。2014年,姚建文等[4]学者通过测度国内图书馆与情报学领域的“睡美人”现象,建议“睡美人”论文必须满足至少5年不被引用,以及唤醒后被引用10次以上的指标要求。2016年,袁红等[5]提出“睡美人”论文应符合沉睡期至少5年,唤醒拉升比大于等于5,唤醒持续时长至少5年的标准。为了解决主观指标法的主观性高和识别不够精确的问题,国内外学者提出识别“睡美人”论文的客观指标法和曲线拟合法。在客观指标识别法研究方面,2015年,KeQ等[6]学者基于文献的引用频次,设计出一个无参数指标“美丽系数(B)”对“睡美人”论文进行识别。当文献睡眠区间越长,睡眠深度越深,觉醒强度越大时,所对应的“美丽系数”越大,越有可能成为“睡美人”论文。通过“美丽指数”能够快速识别出“睡美人”论文,但却无法反映年度被引次数达到峰值之后的被引状况[7]。2015年,杜建等[8]在“美丽系数”的基础上提出了Bcp指数,把坐标系中的年被引量改为年度被引次数累积百分比,并在临床医学领域文献中得到初步证实。YeFY等[9]通过引入动态引证角β来改进“美丽系数(B)”定量识别“睡美人”论文。此外,在识别“睡美人”的曲线拟合法研究方面,2014年,李江等[10]学者分析了341位化学、生理学、医学和经济学领域诺贝尔奖获得者文献的引文曲线,明确提出了“睡美人”论文的引文曲线模型。以天文学和天体物理学领域为例,王海燕等[11]发现,“睡美人”论文中的大多数引文曲线都呈现不断上升的趋势,“睡美人”论文中的引文曲线与学科发展趋势相吻合。区别于曲线直接拟合的“睡美人”识别方式,一些学者从聚类分析的角度识别“睡美人”论文。1985年,AversaES[12]采用K-means聚类分析和判别法对400篇高被引文献进行聚类分析,区分了睡美人与昙花一现型文献的引文曲线。2013年,BaumgartnerSE等[13]借鉴“组基轨迹建模”,并将此模型首次用于研究文献引用分布的年度特征。
综上所述,现阶段国内外学者识别“睡美人”论文采用的方法中,曲线拟合方法具有识别准确率高、结果直观清晰的优点,但在处理数据量较大的样本时效率较低,需要人工观察[9];主观指标法存在主观性大和识别准确率低的缺点;客观指标法为目前学者采用最多的方法,具有准确率与效率均高的优点,但也存在引文曲线不完整等缺点。本文在综合考虑的基础上,最终选择采用K值算法与三指标法相结合以及计算被引延迟指数两种方法识别神经科学领域的“睡美人”论文。
1方法和数据
1.1方法
1)三指标法。2004年,荷兰科学家RaanAFJ首次提出睡眠深度、睡眠时长与唤醒强度3个指标去界定“睡美人”论文。睡眠深度即文献在睡眠期间年均被引次数,小于等于1次的为深度睡眠,小于等于2次的为浅度睡眠;睡眠时长即文献浅度或深度睡眠所用时间;唤醒强度即文献唤醒后4年内的平均被引次数。本文在RaanAFJ等研究的基础上,将“睡美人”论文的界定参数设定为睡眠深度小于等于2次,睡眠時长大于等于5年,唤醒强度大于等于5次。
2)K值算法。2017年,TeixeiraAAC等[14]、李秀霞等[15]提出K值算法,通过分析文献按时间累积的被引次数量化文献引用分布。K值算法表达式为:
式中,yop为文献发表年份,noci为第i年被引次数,N为文献引文时间窗口。K取值范围为0~1,K值越大,则文献越有可能是“睡美人”论文。K值算法确保“睡美人”论文具有较长的清醒时间,同时能够考察文献完整的被引曲线。因此,K值算法能够较为高效客观地识别“睡美人”论文。
3)被引延迟指数。2013年,WangJ[16]提出被引速率指标,即一篇文献从发表后能以多快的速度累积至它的总被引频次。文献的被引次数是一个从零开始增长的过程,任何非零被引文献的被引次数曲线都是呈增长状态的。睡美人型增长曲线为总被引频次在文献发表后的一段时间内增长缓慢,在保持较长一段时间后突然快速增长,整体上被引速率较低。被引速率指标计算公式为:
式中,Ci为文献第i年的累积被引次数,Cn为文献总被引频次,n为文献被引的时间跨度。被引延迟指数(D)为被引速率的反向指标,表达式为D=1-CS。文献被引延迟指数反映了文献的被引延迟程度,D值越大,文献延迟承认程度越高,越有可能是“睡美人”论文。
1.2数据
数据均来源于WebofScience数据库中的核心合集。在WebofScience平台中,输入检索表达式:WC=Neurosciences,文献类型限定为Review、Pro⁃ceedingsPaper和Article,语言为全语言,共检索到神经科学领域论文905418篇。论文的年度数量分布、国家(地区)、语种、基金资助机构、来源出版物分布等基本信息如表1所示。
由表1可知,按照5年1个周期,可以看出神经科学领域出版的论文数量呈现周期增长趋势。2016—2019为4年周期,因此文献量少于前一个5年周期。领域科研产出最多的5个国家分别为美国、德国、英国、日本和加拿大,其中美国发文量远超其他国家。神经科学领域98.2%的文献语种为英语,此外,法语、俄语、西班牙语和日语文献数量仍然占极低的比例。神经科学领域科研产出较多的TOP5机构多为美国机构,其中美国卫生与公共服务部、美国国立卫生研究院的发文量分别达到20余万篇,共计439514篇,占领域总文献量的48.5%,TOP5机构的发文量占比达到70.7%。文献数量的国家、机构和语种分布符合典型的马太效应和二八定律,大部分论文多为美国出版,论文语种多为英语。然而神经科学领域文献数量的期刊分布相对均匀,其中《神经科学杂志》和《大脑研究》出版的论文数量最多,分别为32801和30749篇。
为动态展示论文的年度被引频次变化趋势,保证待分析论文具有15~20年的引用期,本文选取1990—2005年发表的377007篇文献为分析样本。按三指标法的唤醒强度指标,“睡美人”论文首先应保证有一定数量的总被引频次。本文综合考虑领域文献总量和引用频次分布,剔除总被引频次小于等于20次的文献,最终以206015篇文献为待识别样本,选取样本数量比例为总量的22.8%,符合典型的二八定律。
2结果分析
2.1基于K值算法与三指标法的睡美人文献识别
以206015篇神经科学领域文献为数据基础,利用K值计算方法测算出全部文献的K值,然后将K值由大到小排序,并结合三指标法的识别标准,进行“睡美人”论文识别。剔除K值为1和0的文献,K值为1表示只在被引时间跨度的最后一年被引用,K值为0表示只在文献发表当年被引用,不符合“睡美人”论文的基本特征。K值变化曲线如图1所示,其区间为(0.11,0.86)。根据现有研究发现,“睡美人”论文通常占文献出版总量的0.01%~0.1%,将K值由大到小排列,选择前200篇文献作为本文识别到的准“睡美人”论文。为提高识别准确度,对识别到的200篇“睡美人”论文运用三指标法进一步识别。分别计算准“睡美人”论文的睡眠深度、睡眠时长以及唤醒强度,要求睡眠深度小于等于2,睡眠时长大于等于5,唤醒强度大于5,最终筛选出神经科学领域符合“睡美人”特征的文献26篇,文献的基本信息如表2所示。
2.2基于被引延迟指数的睡美人文献识别
根据杜建等[17]学者的研究发现,文献延迟承认现象在高被引文献中出现频率较高,前人研究方法通常为筛选出高被引文献,将研究样本范围缩小至TOP0.5%高被引论文。本文为了全面考察文献的被引延迟承认情况,将待识别的206015篇文献全部纳入计算范围。计算206015篇文献被引延迟指数,同样剔除值为0和1的文献,被引延迟指数变化曲线如图2所示,其区间为(0.13,0.95)。被引延迟指数越高,则文献被引次数累积得越慢,越有可能在一段时间内快速积累,越有可能成为“睡美人”论文。杜建等[17]学者认定被引延迟指数大于等于0.6的文献为“睡美人”论文,由此共得到14817篇准“睡美人”论文。因得到“睡美人”论文数量较大,通过引用轨迹观察可以发现,这14817篇文献中有很大一部分不符合“睡美人”论文的沉睡特征。因此,在前人研究基础上,本文设定文献被引延迟指数大于0.8的文献为“睡美人”论文,共有65篇,部分识别结果如表2所示。
2.3识别结果对比与分析
通过K值算法与三指标法的组合识别出神经科学领域26篇“睡美人”论文,此外,基于被引延迟指数识别出65篇“睡美人”论文。其中两类方法识别出的26篇共同“睡美人”论文基本信息如表2所示。
2.3.1“睡美人”论文的睡眠特征分析
从表2可以看出,在睡眠深度方面,26篇“睡美人”论文的睡眠深度范围为0.11~1.63次,其中3篇文献睡眠深度大于1,处于浅度睡眠状态,而大部分文献睡眠深度小于1,为深度睡眠状态,可以发现,神经科学领域的“睡美人”论文在沉睡期间被引频次极低,很难引起学者的关注,唤醒难度较大;在沉睡时长方面,26篇文献的睡眠时长范围为6~16年,其中14篇文献睡眠时长超过了10年,平均时长为9.88年;在唤醒强度方面,26篇“睡美人”论文唤醒强度范围为5~13次,与睡眠深度相比有大幅度提升,表示文献已经被领域学者充分发掘和利用,最大程度实现了文献的科学价值。
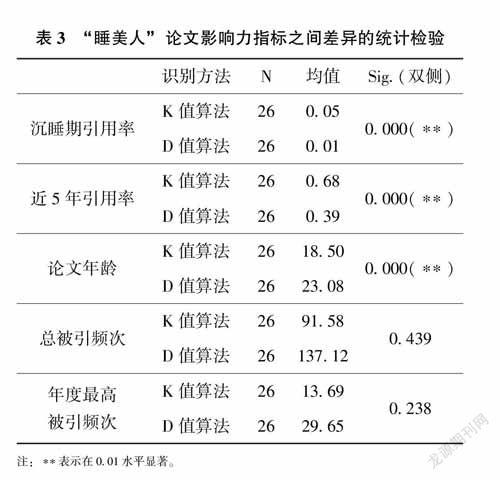
2.3.2“睡美人”论文识别方法的识别效果差异从表2可以看出,两种方法识别出的“睡美人”论文并非是同一批文献,差异极大,指标排名靠前的26篇文献几乎没有相同的。此外,两类方法识别出的“睡美人”论文在沉睡期引用率和近5年引用率等指標方面也存在较大差异。借鉴赵又霖等[18]学者的定义,测算出“睡美人”论文的如下指标:①沉睡期引用率:文献发表年至唤醒年期间的年均被引次数与整个引文窗内最大被引次数的比值,保证“睡美人”论文在沉睡期一定的低被引。②近5年引用率:从“睡美人”论文引用周期截至年向前推4年,此期间论文的平均引用次数与最大被引次数的比值,保证“睡美人”论文觉醒之后保持一定的高被引。通过对K值算法与三指标组合法(简称K值算法)识别出的26篇“睡美人”论文与被引延迟指数(简称D值算法)排名靠前的26篇“睡美人”论文影响力指标之间差异进行T检验,检验的结果如表3所示。
由表3可以看出,“睡美人”论文沉睡期引用率、近5年引用率和论文年龄3个指标在K值算法与D值算法识别结果之间存在显著差异。其中K值算法与三指标组合法识别出的“睡美人”论文沉睡期引用率和近5年引用率显著高于被引延迟指数识别出的论文,说明K值算法识别出的“睡美人”论文睡眠期和唤醒之后仍然保持一定的高被引,避免被引频次达到峰值后突然下降。然而,D值算法下的“睡美人”论文年龄显著高于K值算法,表明D值算法对早期发表的“睡美人”论文更敏感。总被引频次和年度最高被引频次没有显著差异,但在均值上看,K值算法能够识别出总被引频次和年度被引频次较低的“睡美人”论文。
2.3.3“睡美人”论文的引文曲线分析
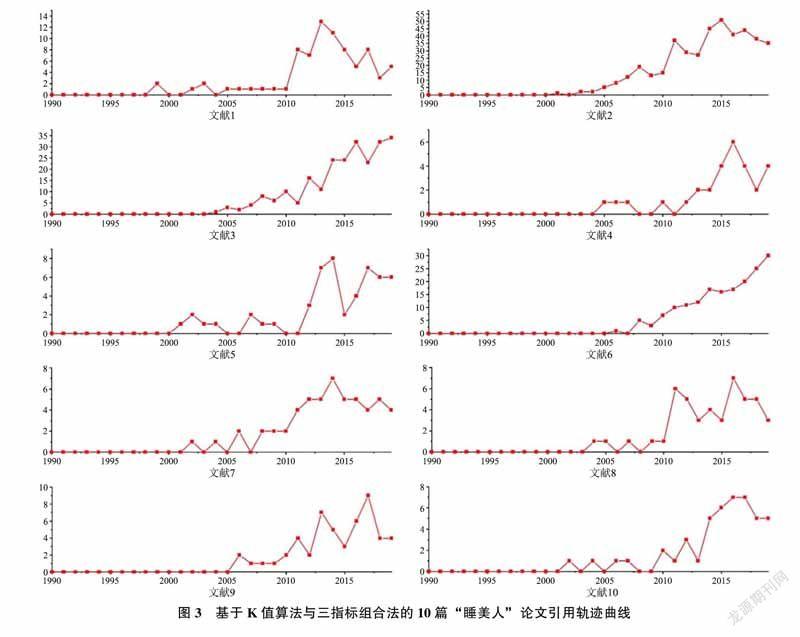
基于K值算法与三指标组合法共识别出26篇“睡美人”论文,其中K值较大的前10篇论文的引用轨迹曲线如图3所示。此外,被引延迟指数识别出的65篇“睡美人”论文中,被引延迟指数(简称D值)较大的10篇“睡美人”论文引用轨迹曲线如图4所示。
从图3和图4“睡美人”论文的引用轨迹可以看出,两种方法识别出的“睡美人”论文均存在有效性。K值算法能够较为客观高效地识别出“睡美人”论文,计算过程较为简单,能够考察论文的整个引用窗口。但是在实际操作中发现,文献K值区分度不够,除两端外,中间值分布紧密。若将K值从大到小排列并选取文献总量的0.01%作为“睡美人”论文,很大程度上忽视了文献总量的0.01%~0.1%这一部分文献,造成识别结果准确度不够。此外,三指标法因其主观性较大,若直接使用则准确度较低。因此,将三指标法运用于K值识别方法之后,能够进一步识别特征明显的“睡美人”论文,提高了“睡美人”论文的识别效率与准确率。从图3“睡美人”论文的被引次数随时间变化的曲线可以发现,组合识别法的识别准确率极高,“睡美人”论文引用轨迹极为明显。然而图4显示的被引延迟指数识别出的部分“睡美人”论文引用轨迹不是特别明显。被引延迟指数反映了文献累计被引次数增长的速度,具有计算过程简单,且对于高被引文献识别准确度较高的优点。由图4可以发现,对总被引次数大于50次的文献识别准确率较高,而对总被引次数较少的文献识别准确率较低,识别误差大。同时,在实际计算过程中无法明确界定指数增长型文献,需要对被引延迟指数范围进行进一步的界定,存在一定的主观性。
2.3.4“睡美人”论文影响因素分析
由于K值算法与三指标组合法识别出的“睡美人”论文更加准确,因此,以K值算法与三指标组合法识别出的26篇“睡美人”论文为计量分析对象,量化分析论文作者数量、期刊影响因子、论文篇幅、论文年龄、总被引频次和最高被引频次对26篇“睡美人”论文K值的影响。然而表4所示的实证结果表明,K值与6个指标均不显著相关。为了扩大样本考察哪些计量指标影响“睡美人”论文K值,将实验数据扩展至K值较大的50篇“睡美人”论文(包含已识别出的26篇“睡美人”论文)。50篇论文的作者数量、期刊影响因子、论文篇幅、论文年龄、总被引频次和最高被引频次与“睡美人”论文K值之间的Person相关性分析结果如表5所示。
从表4可以看出,尽管作者数量、期刊影响因子、论文篇幅、论文年龄、总被引频次和最高被引频次与“睡美人”论文K值之间的相关系数处于-0.264~0.77之间,然而显著性水平全部大于0.05,说明这些计量指标并没有显著影响“睡美人”论文K值。为了平衡样本数量少的影响,表5扩展样本数量后的相关性分析结果显示,总被引频次与“睡美人”论文K值之间存在-0.193的显著负相关,即总被引频次越低,识别“睡美人”K值反而越高。这说明“睡美人”论文并非都是高被引文献,反而倾向于低被引文献。同时也说明K值组合法能够识别出总被引频次较低的“睡美人”论文。除总被引频次外,作者数量、期刊影响因子、论文篇幅、论文年龄和最高被引频次与“睡美人”论文K值之间全部负相关性,且相关性都较弱,处于-0.118~-0.026,显著性全部大于0.05,说明文献原文特征及引文特征并不能显著影响“睡美人”论文K值。从相关性的负值可以看出,文献原文特征及引文特征值越大,反而更容易被早期发现和使用,不易成为“睡美人”论文。例如影响因子越高的期刊,论文刊载后可能受到科学家关注和广泛利用的程度越高,反而不易成为“睡美人”论文。
3结语
神经科学领域“睡美人”论文识别方法的融合及其应用研究,以及“睡美人”论文计量特征及影响因素的量化分析,有助于全面展示神经科学领域的“睡美人”论文概况,最大程度实现领域潜在高价值文献的科学价值。本文在前人研究的基础上,为提高識别的有效性与准确度,提出主客观结合的识别方法,采用K值算法与三指标法融合的方法以及计算文献被引延迟指数的方法,识别出神经科学领域的“睡美人”论文。研究结果显示,①尽管K值算法与三指标组合法识别出的26篇“睡美人”论文远比被引延迟指数识别出的65篇“睡美人”论文数量少,然而K值算法与三指标组合法识别出的26篇“睡美人”论文引用轨迹更明显,呈现出前低后高、逐渐上升的典型“睡美人”论文引文曲线形态,识别准确率相对较高;②K值与三指标组合法识别出的“睡美人”论文与被引延迟指数识别出的“睡美人”论文在文献计量特征和引文特征方面差异较大,并且两类方法识别出的两批文献并不相同,K值与三指标组合法能够更容易识别出总被引频次较低的文献;③K值与三指标组合法识别出的26篇“睡美人”的睡眠深度范围为0.11~1.63次,睡眠时长范围为6~16年,平均时长达到9.88年,文献唤醒强度范围为5~13次;④K值较大的50篇“睡美人”论文作者数量、期刊影响因子、篇幅、论文年龄、总被引频次和最高被引频次6个指标与识别“睡美人”论文的K值之间呈现出-0.118~-0.026之间的负相关性,然而除总被引频次与K值显著负相关外,其他计量特征的显著性值全部大于0.05,说明这些计量特征并不能显著影响识别“睡美人”论文的K值。
本文的不足之处在于受数据量较大的影响,没有采用曲线拟合的方法,无法比较曲线拟合方法在识别“睡美人”论文效果的优劣。同时,本文的数据源为神经科学领域相关文献,无法得知K值与三指标组合法、被引延迟指数是否适用于其他学科,未来可以扩大数据样本的学科范围,以便进一步分析探讨。
3723500338258
