基于可变形卷积和自适应空间特征融合的硬币表面缺陷检测算法
2022-03-01王品学张绍兵秦小山
王品学,张绍兵,3*,成 苗,3,何 莲,秦小山
(1.中国科学院成都计算机应用研究所,成都 610041;2.中国科学院大学计算机科学与技术学院,北京 100049;3.深圳市中钞科信金融科技有限公司,深圳 518206)
0 引言
根据工业智能白皮书显示,工业智能成为了我国及业界高度重视的领域方向[1]。在印钞造币行业,人工对硬币缺陷进行检查不仅费时费力,而且还会因为主观差异造成对缺陷认定的不统一,很容易漏检微小缺陷,无法满足大规模的批量生产。而基于计算机视觉的表面缺陷检测具有高准确率和简单高效的优点,因此,需要在工业生产中引入机器视觉的机检方案;并且随着造币生产制造工艺的提升,彩喷、光油、机读等新兴工艺的出现,以及企业对硬币质量要求的提高,迫切需要提升当前的缺陷检测方案以达成智能制造、信息化建设和产品零漏废的目标。
目前在机器视觉上进行表面缺陷检测已有充分的研究,主要分为传统图像检测方法和利用深度学习的检测方法两大类。文献[2]利用形态学配准的方法,先将无缺陷样本作为模板图与待检测图同时经过二值化、滤波、边缘检测和进行形态学处理,再利用Harris 角点将两幅图片配准然后通过差分的方式来检出硬币镜面部分缺陷。文献[3]利用高斯混合模型和色调变换来匹配硬币中心,使用分块硬币的直方图来精确计算硬币旋转角度进行配准,再将对齐的硬币图像投影到图像空间中来降低噪声,并通过比较投影误差和自适应阈值来检测缺陷像素。
传统的硬币图像检测方案主要基于配准后的图像差分来检测缺陷,由于光照、反射、复杂的成像环境引入的噪声会对结果造成干扰,缺乏鲁棒性。随着深度学习的发展,基于卷积神经网络的算法被广泛应用到表面缺陷检测中。其中分为先进行候选框提取再进行回归定位的两阶段算法,如R-CNN(Regions with Convolutional Neural Network)[4]、Fast R-CNN[5]、Faster R-CNN[6]和Mask R-CNN[7]等网络和直接进行一阶段目标检测的SSD(Single Shot MultiBox Detector)[8]和YOLO(You Only Look Once)[9]系列算法。由于工业生产对实时性要求高,使用一阶段算法较多。文献[10]提出一种轻量级的卷积神经网络来检测钢轨表面缺陷。该网络加入了多尺度空洞空间池化金字塔模块来提取任意分辨率下的特征,使用损失注意力网络定位缺陷以计算惩罚系数,通过补偿前景、背景损失来解决类别不平衡问题。实验结果表明注意力机制重新调整了网络的学习能力,降低了原任务的难度,能快速学得最优权重和精确的缺陷预测。文献[11]使用轻量级网络(MobileNet)来代替YOLOv3[12]原有网络中的密集连接网络(Darknet-53)以减少参数,加入空洞卷积来提高小目标的检测能力,在网络结构的最后一层卷积中加入了Inception 结构,进一步减少参数总量并加深网络。文献[13]优化YOLOv3 提高了原始检测基准线,提出了一种新的使用数据驱动的金字塔特征融合策略,自适应学习各层融合参数,过滤空间上的冲突信息,进行不同尺度特征图融合以更好地检测不同大小的目标。文献[14]将原始SSD 主干网络中VGG16 的标准卷积替换为可变形卷积[15]来适应缺陷未知的几何形变并改进非极大值抑制算法解决正负样本不均衡问题,实验结果表明改进的网络较原始SSD 在检测大坝缺陷的精度上提升5.98%。PP-YOLO(Paddle Paddle YOLO)[16]替换主干网络为ResNet50,并在其后添加了可变形卷积DCNv2(Deformable Convolutional Network version 2)[17],提供了多个实用的训练技巧。在仅使用MixUp 进行数据增强的条件下,通过合理的技巧组合,使训练和推理更加高效,并通过多组消融实验证明了该观点。文献[18]提出了用于肝脏和肝肿瘤分割的可变形编码解码器网络,可变形卷积用于增强特征提取能力,使用多尺度膨胀率设计空间金字塔模块学习融合信息。
为了在硬币表面缺陷检测中保证检测实时性和检测精度,本文采用一阶段的检测方式,对YOLOv3 进行改进,并在网络输出特征进行上采样多尺度融合前加入可变形卷积层,使用自适应空间特征融合(Adaptive Space Feature Fusion,ASFF)网络替换FPN(Feature Pyramid Network)[19]来实现多尺度特征融合,提出基于可变形卷积和自适应空间特征融合的硬币表面缺陷检测算法DCA-YOLO(Deformable Convolutional and Adaptive space feature fusion-YOLO)。在模型训练上改进先验锚框和动态修改训练时类别权重,并通过实验对比各网络模型以及加入可变形卷积的位置和一些训练技巧对于网络性能的影响。
1 数据采集、分类和图像处理
1.1 数据采集和分类
硬币缺陷数据集来源于某造币厂生产的有缺陷的2020年鼠年硬币,缺陷主要包括粘坑和划痕。数据集包含1 224个粘坑、1 045 个划痕的1 872 幅硬币正面图像和包含1 130个粘坑、1 080 个划痕的1 845 幅硬币背面图像。使用穹顶光、同轴光和穹顶-同轴组合光源三种方式对硬币进行成像实验,比较各个光源下硬币缺陷的表现效果,如图1 所示。实验发现在穹顶光下,硬币缺陷表现更为明显,更易检出,所以最终使用该光源图片作为训练模型的输入图像。

图1 缺陷分类和不同光源下的成像表现Fig.1 Defect classification and imaging performance under different light sources
1.2 图像处理
由于生产时工业设备磨损、压印不足等原因,缺陷往往出现在同一位置,不同硬币的缺陷表现相似,所以面临小数据样本问题。基于真实缺陷的外观、形态、大小等特点,采用人工合成图像的方式来增加扩充样本,经过数据增强最终的图片有1 872 幅硬币正面图像和1 845 幅硬币背面图像。训练时将图像进行几何变换和颜色变换,如图2 所示。

图2 图像的几何变换和颜色变换Fig.2 Geometric transformation and color transformation of image
1.3 几何变换、颜色变换和Mosaic数据增强
几何变换:对图像进行尺寸缩放、随机翻转旋转、随机裁剪。
颜色变换:对图像加入高斯噪声,进行随机色域变换(色调、饱和度、亮度变换)等操作。
使用Mosaic 方式在训练时进行数据增强,每次读取4 幅图片,随机进行尺寸缩放、裁剪等几何变换操作,再拼接成1幅512×512~768×768 大小的图片作为输入图片,由于进行1/32 的下采样,图片尺寸需要为32 倍数,并修改相对应的XML注释。Mosaic 数据增强可以极大丰富训练图片内容,在不增加算力的基础上提升网络的检测性能。图3 为4 幅经过Mosaic 数据增强后的图片,每幅图片都分别由4 幅图拼接而成。

图3 Mosaic数据增强Fig.3 Mosaic data augmentation
2 硬币的表面缺陷检测
2.1 总体思路
本文改进了YOLOv3 网络,提出一种基于可变形卷积和自适应空间特征融合的硬币表面缺陷检测算法DCA-YOLO用于硬币的表面缺陷检测。网络整体结构如图4 所示。模型的主干网络采用Darknet53,由于数据量较小,当网络层数加深时使用该残差网络结构也一定程度上减小了计算量和网络的过拟合程度,同时保持了网络提取特征的能力。最后三个阶段输出宽高为原图像尺寸的1/8、1/16 和1/32 的特征图D3、D4、D5。使用SPP(Spatial Pyramid Pooling)对骨干网络的输出D5 进行三层卷积后,再将结果分别进行池化核大小为1×1、5×5、9×9、13×13 的四种不同尺度大小的池化操作,目的是融合多层感受野来增加网络的感受野信息量,将池化后的输出进行concatenate 合并得到固定大小的输出。

图4 硬币表面缺陷检测算法DCA-YOLO整体框架Fig.4 Overall framework of DCA-YOLO algorithm for coin surface defect detection
针对划痕细小、跨度大问题,设计了3 类可变形卷积网络。最终网络选择在SPP 模块输出的特征后,在Level 3 和Level 2 两个不同尺度的特征图进行上采样时增加3×3 的可变形卷积模块,该模块首先使用普通卷积层学习offset 偏移和调节权重参数,增强卷积对于缺陷形态特征的适应性,再将特征图和偏移值调节权重后输出,脖颈层采用自适应空间特征融合(ASFF)来自学习参数融合不同尺度特征信息,特征融合后再使用YOLOv3 head 部分进行预测是否包含目标、目标类别和位置信息。
2.2 可变形卷积
原始YOLOv3 对于形状多变的目标建模存在固有缺陷,固定的矩形结构只对特征图的固定位置进行采样,如图5 所示。而同一层中的特征图中的特征点的感受野是一样的,但不同位置可能对应着不同尺度和形状的物体,因此增加的可变形卷积模块对尺度或感受野进行自适应学习是进行精准定位所需要的。为了准确检测出在检测框中覆盖面积较小的条状划痕缺陷,本文在主干网络最后一阶段输出D5 特征后经过SPP 网络进行上采样到D4 和D3 尺度大小之前增加可变形卷积层,增强卷积的适应性。

图5 可变形卷积随机采样能力Fig.5 Random sampling ability of deformable convolution
2.2.1 可变形卷积模块操作步骤
1)输入最后一阶段D5 经过SPP 的特征图F,batch 为8(大小为b×H×W×C),经过普通卷积,卷积填充为same,即输入输出尺寸不变,对应的输出结果为(b×H×W×3C),偏移量记作offset,表示原始特征图batch 中每个像素索引的偏移量。其中的2C表示有x和y两个方向上的偏移值,剩下1C通道表示调节权重值Δm,它经过Sigmoid 函数后范围在0 到1。
2)将输入F中的像素的索引值与offset相加,得到偏移后的position(即各像素在F中的坐标值),需要将position的值限定在图片尺寸范围内。
3)因为position坐标是Float 类型的,为了可以得到准确的像素值并且可以进行反向传播,需要使用双线性插值的方式来获取坐标位置对应的像素。例如,取一个坐标值(a,b),将其转换为floor(a)、ceil(a)、floor(b)和ceil(b)四个整数,其中floor()和ceil()操作是将a,b进行向下或向上取整,得到(floor(a),floor(b))、(floor(a),ceil(b))、(ceil(a),floor(b))和(ceil(a),ceil(b))四个坐标。这四个坐标每个都对应F中的一个像素值,需要通过双线性插值的方式来计算得到(a,b)的像素值。
4)在得到position的所有像素后,各采样点经过Δmn调节权重将得到的新的特征图作为输入传递到下一层。如图6 所示。

图6 可变形卷积操作步骤Fig.6 Deformable convolution operation steps
2.2.2 算法解释
在可变形卷积中改进固定采样的位置,具体如下:
1)利用规则网格对输入特征矩阵F进行卷积采样,采样位置集合V可以通过Δpn(Δpn=1,2,…,N)实现采样位置偏移,从而增大感受野的范围,采样点通过Δmn来调节权重参数,其中的N为网格中的像素个数,结合式(1),对于输出特征图上的任意位置p0,可以得到:
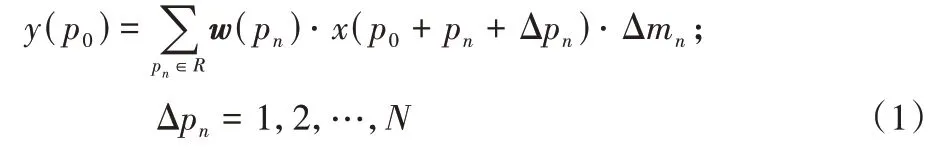
其中:w(pn)是采样位置的权重信息;V={(-1,-1),(-1,0),…,(1,0),(1,1)},为采样位置集合。
2)由于采样点是在不规则的偏移后的位置pn+Δpn上进行的,而偏移量Δpn通常是浮点数,无法获得所在位置的准确像素值,如果仅仅使用取整的方式会有一定误差,因此通过双线性插值可以得到任意位置的像素值:

其中:p=p0+pn+Δpn,表示偏移后的任意位置;x(q)是枚举了F周围相邻四个整数坐标处的像素值;G(·,·)为这四个整数坐标分表对应的权重。G(·,·)是二维的,分为两个一维内核:

其中:g(a,b)=max(0,1-|a-b|)。
通过以上的可变形卷积方式来自适应学习感受野,采样位置更符合物体本身的形状和尺寸,而非固定的几何结构采样,更利于缺陷特征提取。
2.2.3 三种可变形卷积网络模块
本文在不同的位置添加可变形卷积的模块设计了以下3 类网络模型(如图7 所示):
第1 类是借鉴PP-YOLO 的方式在主干网络D5 层输出后替换普通卷积,将SPP 网络中的3×3 卷积替换为可变形卷积,输出层尺寸小,拥有的感受野大,语义信息多,并且在进行SPP 后增强了感受野更有利于学习物体整体的形状类别。同时小尺寸的特征输入在计算偏离量时也相对较快。
第2 类是在多尺度融合进行上采样前添加3×3 的可变形卷积层,深层的可变形卷积学习图像高级语义信息,上采样后融合低层细节特征图再进行一次可变形卷积,两次卷积的特征进行了加强,不仅学习到了整体轮廓,未知形变的细节部分也能学到。
第3 类考虑到小目标较多,直接在D3、D4 两阶段的输出后添加3×3 的可变形卷积,多尺度融合时能更好地学习目标细节形变,相较于第2 类模型,细节部分更丰富,也会带来更大计算量。
图7(b)左侧虚线部分是参考FPN 增加的可选的卷积模块,用来调整通道数和加深网络,增加提取特征能力。

图7 不同位置添加可变形卷积Fig.7 Adding deformable convolution in different positions
2.3 自适应空间特征融合
特征金字塔网络(FPN)是目标检测中解决多尺度变换的常用方法,网络输出大、中、小三种尺寸的特征图,经过三个分支来进行预测,浅层特征图为高分辨率细粒度更注重细节,深层网络特征则包含更多的语义信息,如图8 所示。在这三个分支中,大尺寸的特征图感受野较小,适合于检测输入图片中的小目标,深层网络产生的小尺寸的特征图拥有较大的感受野,更适合检测大目标。然而对于一次检测的YOLO 而言,不同特征尺度之间的不一致是主要限制,例如当某个对象在某个级别的特征图中被认为是正样本时,将其他级别的特征图中的相应区域视为背景。因此,如果该区域同时包含大小两种目标时,则不同级别的特征之间的冲突往往会占据特征金字塔的主要部分。这种不一致的冲突会干扰训练期间的梯度运算,降低特征金字塔的有效性。

图8 自适应空间特征融合Fig.8 Adaptive spatial feature fusion
自适应空间特征融合(ASFF)提出一种类似空间注意力的算法,学习不同尺度的特征融合权重参数,各权重参数图与其输入进行逐点相乘,来决定输入特征图中各像素点的激活与抑制以解决冲突问题,这样可以更好地学习不同尺度特征图对于预测不同大小目标的贡献。具体步骤如下:
1)输入特征。输入骨干网络中的三种尺度的特征图。
2)特征缩放。输入特征分别为原图的1/32、1/16、1/8,缩放是为了解决下一步进行特征融合时的尺寸不一致问题。对于上采样,先使用1×1 的卷积调整通道数与l 层一致,再使用插值来调整尺寸提高分辨率。对于1/2 下采样,直接进行步长为2,大小为3×3 的卷积,对于1/4 的下采样,在步长为2,大小为3×3 的卷积操作前添加了一个步长为2 的最大池化操作。
3)特征融合。αl、βl、γl分别是在l层特征x1→l、x2→l、x3→l的权重参数图,其中xn→l表示经过特征缩放后获得的尺寸相同的输入特征,各权重图与其输入特征逐点相乘,来决定输入特征图中各像素点的激活与抑制。α、β、γ中各位置的取值由网络训练过程中习得。逐点相乘之后,将三个输入值进行相加,将其作为该检测分支的输入值。

3 特征图检测
3.1 改进先验锚框
由于硬币缺陷数据集和COCO 数据集[20]所包含的目标大小有较大差异,数据集主要以小目标缺陷为主,为了更好、更快速地收敛,首先使用聚类的方式获得anchor,但由于都为较小缺陷,多数样本宽高比例单一,无法利用多尺度检测的优势,因此本研究改进了聚类后的锚框进行线性尺度的缩放,将锚框尺寸往两边进行拉伸。
聚类首先不分类别地读取所有标注框;然后随机化初始位置并选择12 个框作为聚类中心并依次计算每个标注框与聚类中心的交并比;接着按照交并比大小分配给最适合的聚类中心;最后在分配结束后重新计算各聚类中心直至聚类中心不再发生变化。此时得到了12 个根据数据集获得的先验锚框。聚类时的损失以Lossc来表示:

其中:boxi为第i个标注框的面积;cenj为第j个聚类中心的面积;n为标注框总数;k为聚类中心个数。
对聚类后的锚框进行拉伸缩放以更好地发挥检测网络的多尺度检测能力,具体做法如下:


其中:α=0.5,β=2,将原来anchor 框的宽的最小值变为原先1/2,最大值变为2 倍。
3.2 动态修改类别权重
在初始化时,首先按照各类别缺陷的数量来分配权重,两个缺陷的权重参数和为1,缺陷少的类别权重高,提高学习效率。在每一轮Epoch 迭代训练后,记录下每个类别的AP(Average Precision),动态更新类别权重加快训练。配合Focal Loss[21]来解决类别不均衡和难样问题。
4 实验与结果分析
4.1 实验环境
实验显卡使用的是NVIDIA Tesla P100 16 GB,操作系统是Ubuntu 18.04,使用的深度学习框架是PyTorch 1.7.0,网络的模型训练测试都在NVIDIA Tesla P100 进行。
4.2 实验数据和评价指标
1)实验数据。
目标检测任务是有监督训练,需要提前标注好目标的类别和位置,目标的定位使用矩形框来表示。本文采用的数据集来源于某造币厂生产的有缺陷的鼠年硬币,包含粘坑和划痕两个类别,经过数据增强最终的图片有1 872 幅硬币正面图像和1 845 幅硬币背面图像。将85%的数据作为训练集,15%的数据作为测试集,在图像增强时保证尽量保证类别均衡。
2)评价指标。
实验为了评估缺陷图片的目标检测准确性、查全率和检测速度,采用以下5 个评价指标:召回率R、平均准确率P、平均精度均值(mean Average Precision,mAP)、F1 分数、帧率。
在工业缺陷检测中,召回率和准确率都很重要,使用F1分数来兼顾检测中的召回率和准确率。F1 分数被定义为精确率和召回率的调和平均数。具体计算方式如下:

4.3 对比方法
在硬币的表面缺陷数据集上,采用以下几种模型进行缺陷检测实验,和本文中所提出的DCA-YOLO 算法网络的检测效果进行对比,并比较在不同位置加入可变形卷积模块的性能。其中推理时图片大小为672×672。
1)Faster-RCNN:残差网络ResNet50 作为主干网络,Neck 层使用FPN,记录对比mAP 和帧率。
2)YOLOv3:使用Darknet53 作为主干网络,将最后三阶段的输出通过FPN 进行多尺度融合,使用SPP 融合输出的多重感受野,每个网格进行锚点预测。
3)YOLOv3-PAN:使用 PAN(Path Aggregation Network)[22]替换FPN 进行多尺度融合。
4)YOLOv3-tiny:使用类似于Ddarknet19 的7 层卷积网络进行特征提取,通过FPN 进行多尺度融合,网络简单、计算量小,输出两种尺度的预测结果。
5)DenseNet-tiny:密集网络有18 层残差块,每个残差包括两层卷积,使用FPN+SPP 作为多尺度融合,最后输出两个尺度的检测结果。
6)YOLOv3-ASFF:Darknet53 作为骨干网络,SPP 加强网络的感受野,ASFF 学习各层参数来自适应融合多尺度特征层,输出三个尺度的检测结果。并尝试在此网络的不同位置中增加可变形卷积模块进行对比实验。
在以上使用不同网络的基础上再使用一些技巧如修改锚框、激活函数使用Mish 等方式对比效果。
4.4 检测结果分析
在训练时首先使用k-means 算法针对数据集进行聚类,再根据第3 章中改进anchor 的方法拉伸先验锚框,使用Mish激活函数替换Leaky ReLU(Leaky Rectified Linear Unit)。网络训练1 000 个epoch,大约耗时25 h,学习率最初热身值为0.01,权重衰减系数为0.000 5,Batchsize 设置为8,动量为0.9,在10 个epoch 内学习率下降至0.001,动量变为0.93。图片尺寸每10 次迭代调整一次,调整范围是512×512~736×736,以32 的倍数调整大小。训练时尽量调整使各损失在总损失中占比一致,回归框误差权重参数1.03,分类误差权重为332.4,置信度误差权重设置为783.3。
由于现场生产环境对于速度的要求,在不损失太多精度的情况下选择一阶段的检测网络。表1 使用YOLOv3 作为基准baseline,对比Faster-RCNN、YOLO 系列的几个改进模型和DCA-YOLO 模型。从表1 可看出,本文提出的DCA-YOLO 在速度上优于两阶段的Faster-RCNN,精度上与之接近。检测效果对比如图9 所示。与YOLOv3 对比发现,增加了可变形卷积参数和各尺度层融合参数,但速度差别不大,并且mAP提升了3.3 个百分点,F1 提升了3.2 个百分点。对比只添加自适应空间特征融合的YOLOv3-ASFF 网络,mAP 提升了1.7个百分点,F1 提升了1.4 个百分点。为了更加快速地检测目标,使用YOLOv3-tiny 检测,将主干网络替换为更轻型的Darknet19 的改进版,在速度上有很大提升,在mAP 上却下降了17.4 个百分点,大量划痕缺陷未检出。加深网络结构,使用DenseNet-tiny 进行实验,发现mAP 同样下降严重,于是决定采用Darknet53 的残差网络结构作为主干网络。

图9 YOLOv3、Faster-RCNN与DCA-YOLO的检测效果对比Fig.9 Comparison of detection effect among YOLOv3,DCA-YOLO and Faster-RCNN

表1 不同模型的检测结果对比Tab.1 Comparison of different model detection results
在不同位置插入可变形卷积模块的检测结果如表2 所示。插入的位置在第2 章提到的3 类模型:1)替换SPP 中的3×3 卷积;2)D5 输出特征后经过SPP 增强感受野后上采样前再使用可变形卷积来适应缺陷未知的几何特征;3)直接在D3、D4 输出后增加可变形卷积。其中2.2 是在2.1 的基础上,在D3、D4 的输出后加入卷积核大小为1×1、3×3 和1×1 的普通卷积,用来调整通道数和加深网络,增加提取特征能力。实验结果表明,模型2.2 加上可选的卷积层在硬币缺陷数据集中表现最好,mAP 较baseline 提升了3.4 个百分点,F1 提升了3.2 个百分点,但是网络加深引入了额外的参数,每秒检测的图片减少了5 幅,相较于2.1 只在上采样前添加可变形卷积层,检测精度类似,但后者速度快很多。

表2 不同位置加入可变形卷积的检测结果对比Tab.2 Comparison of detection results of adding deformable convolution in different positions
对改进后的模型算法DCA-YOLO 进行消融实验,对比使用Mosaic 数据增强、Mish 激活函数、动态类别权重、拉伸先验锚框对于mAP 和F1 的值影响,如表3 所示。

表3 Mosaic数据增强、激活函数、动态类别权重和拉伸先验锚框对检测结果的影响Tab.3 Influence of Mosaic data augmentation,activation function,dynamic category weight and stretching priori anchor box on detection results
5 结语
为了改进现有的硬币表面缺陷检测的方式,同时考虑到速度和精度的要求,使用改进YOLOv3 网络的方式提出了基于可变形卷积和自适应空间特征融合的硬币表面缺陷检测算法DCA-YOLO,并且用F1 评价指标综合评价召回率和准确率,在硬币数据集中对比YOLOv3 模型,在帧率差别不大的情况下F1 获得了3.2 个百分点提升,检测性能也优于其他改进模型。实验研究了可变形卷积在不同位置对于模型检测效果的影响,最终确定在特征图上采样位置添加。自适应空间特征融合网络对于重合的大小目标检测效果提升显著。由于改进的可变形卷积网络在训练中会引入额外训练偏移参数,尝试替换轻型主干网络和剪枝对模型检测性能影响较大,后续可对网络结构进行进一步优化,使用更轻型网络在保证检测精度的同时提升检测速度,更好地应用于工业缺陷检测。
