元学习的不确定性特征构建及初步分析
2022-03-01李艳,郭劼,范斌
李 艳,郭 劼,范 斌
(1.河北大学数学与信息科学学院,河北保定 071002;2.河北省机器学习与计算智能重点实验室(河北大学),河北保定 071002;3.北京师范大学珠海校区应用数学与交叉科学研究中心,广东珠海 519087)
0 引言
特征提取一直是机器学习的重要研究内容之一,而元学习正是一种充分利用数据本身特性的学习机制。元学习可被定义为一种应用机器学习的方法(元算法)寻求问题的特征(元特征)与算法相对性能测度间的映射,从而形成元知识的学习过程。在此学习过程中,首先要收集先前学习任务和模型的元数据,包括训练模型的精确算法配置、结果模型评估(例如准确性和训练时间)、学习的模型参数(例如神经网络的训练权重)以及任务本身的可测量属性(也称为元特征);然后从这些先前的元数据中学习、提取和传递知识,指导为新任务寻找最佳模型[1]。
1992 年Aha[2]在算法选择中引入元学习的概念,发现了问题本身的特征(即元特征)与算法的性能测度之间的关系。近年来有关数据特征提取的研究[3-4]有了很大进展。元学习的核心问题之一是元特征的构建。2003 年文献[5]对元特征的提取进行了初步的探讨,定义了多种数据的复杂度度量,并分析了它们对算法性能的影响;2006 年文献[6]分别从几何角度和拓扑角度研究了高维空间中点集的特征属性,得到了不同特征的数据集上分类算法的优劣;文献[7]将数据复杂度与学习器的表现整合生成综合数据集来判断学习器的学习能力。标记式学习[8-11]试图通过直接测量一些简单有效的学习算法本身的性能作为模型相关的元特征来确定特定学习问题在所有学习问题空间中的位置;文献[12-15]用数据集中的类重叠程度刻画分类问题的难度。文献[16-21]的工作通过在人工生成数据上进行实验,探讨了可能与分类问题复杂性相关的数据特征,之后有研究分析了数据复杂度对特定分类算法的影响,讨论类重叠、特征空间维数和类密度等一些数据特征对不同分类器的影响[22-25]。以上研究中所定义的元特征大部分是数据的统计特征,没有针对数据和模型中的不确定性建立相应的元特征。
不确定性建模相关研究[26-28]表明,数据和模型的不确定性对学习系统有着显著影响。文献[29]研究了根据问题复杂度调整不确定性对分类泛化的影响;文献[30]研究了不确定性度量对早期时间序列分类的影响;文献[31]提出了一种基于邻域粗糙集的特征选择方法,使用基于邻域熵的不确定性度量从基因表达数据进行癌症分类;文献[32]提出了一种新的基于Jensen-Shannon 散度的直觉模糊集距离度量方法来表示信息的不确定性;文献[33]对分类任务的神经网络预测中的不确定性进行了测量。
本文从不同角度考虑数据和模型可能存在的不确定性,提取多种不确定性指标作为数据的元特征,给出了具体的计算方法,并在大量的人工数据集、真实数据集上利用多个分类算法的测试结果分析了这些元特征之间的相关性,以及它们对学习性能的影响。
1 数据集中不确定性的表示方法
不确定性包括数据本身的不确定性、近似模型构建过程的不确定性,以及系统输出的不确定性和特征空间的不确定性。其中,数据的不确定性主要指属性的模糊性、属性值的随机性、概念边界的不分明,具体可表现为语言值数据、不一致、缺失和噪声分布等。本文中模型学习过程的不确定性主要是指系统输出的不确定性,此时模型学习的结果往往是以概率分布或可能性分布的形式呈现。
以下定义了几种数据的不确定性度量,并说明了计算方法。为降低计算耗费,均采用尽可能简单直接的计算方式。其中数据为人工或真实的待分类数据集。决策属性为样本的类别标号。条件属性或属性代表数据中样本的特征。
1.1 不一致性
不一致性指条件属性相同但决策属性不同的现象,导致不一致性的原因可能有随机性、噪声等因素。一般地,不一致性的标准为判别属性相同但决策属性不同的样本的个数。但由于存在连续值属性无法仅通过属性值的异同来进行度量,本文使用基于距离的计算方法。距离d小于某一阈值ε但决策类不同的样本定义为不一致样本,数据集中不一致样本所占总样本数的比例为不一致度。其中阈值定义如下:
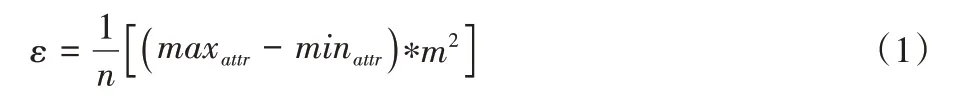
其中:maxattr、minattr为属性值的最大值和最小值;m为属性个数;n为样本数。样本数的多少决定数据集的密度大小,样本数越多则密度越大,阈值应越小;属性维数越多则样本间距离增大,阈值相应变大。
1.2 边界复杂度
边界复杂度即为数据集中类别之间边界的复杂程度,不确定性越大可能边界越复杂,体现问题本身的难度。边界点定义为不能由其周围的点正确分类的样本点。本文使用K最近邻(K-Nearest Neighbor,KNN)方法,查看数据集中不能被其K近邻正确分类的样本点的个数,得到数据集中边界样本点占总样本数的比例即为边界复杂度。K近邻算法使用欧氏距离公式计算距离最近的K个样本。

1.3 模型输出的不确定性
模型输出的不确定性即为分类算法对数据集进行分类后输出分类类别的不确定性度量。输出的不确定性反映了数据集分类的难度,具体为其中每一个样本分类熵的均值。本文使用模糊K近邻算法对数据集进行处理得到所有样本点的针对不同类别标签的权值,得到权值矩阵后根据式(3)计算得到数据集的输出不确定性:

其中:xij为第i个样本点被分到j类的权值;m为属性维数;n为样本点总数。
1.4 线性可分度
目前还没有单一的方法可以得到一个数据集的线性可分程度,大部分的做法是通过多个指标来进行度量。本文通过使用线性分类器对数据集进行划分,查看划分的准确率作为数据集的线性可分度量,即通过使用线性分类器对数据分类的效果来衡量问题的线性可分性。线性分类算法优化问题公式如下:

1.5 属性的重叠度
属性的重叠度指属性取值的不可区分度。在分类任务中,一般认为属性值决定了一个样本点被分到哪一类当中。若不同类之间的属性值之间有着比较明显差异,分类算法就能较好地把不同类区分开来,而如果不同类间的属性重叠在一起则会使分类算法的准确率下降。在相关工作中类间重叠度的计算方法是查看待测样本点与周围样本点类别的差异。本文中通过计算每一个独立属性的重叠度,将特征空间近似为高维立方体,具体计算连续值属性重叠度的方法如式(5)所示:

其中:m为属性维数;lap(attri)为属性i上取值的重叠范围,即在属性i中包含多个决策类的属性值范围;是属性i的最大值和最小值。
1.6 特征空间的不确定性
前面几种不确定性度量都是在有监督的情况下对分类结果进行的不确定性度量,都需要考虑数据集决策类的分布情况。特征空间不确定性则是考察无监督的情况下对原数据集进行聚类得到的结果,反映了数据的特征空间对可能的分类结果所产生的影响。使用模糊k均值(fuzzyk-means)算法对数据集进行聚类,得到每一个样本点的聚类权值xi,xi是样本点i对k个聚类的权值向量。再用式(6)计算数据集的聚类不确定性:
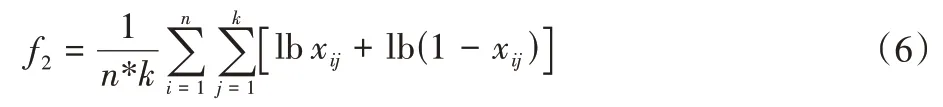
其中:xij为第i个样本点对第j个聚类中心的权值;k为聚类个数;n为样本点总数。
2 实验和结果
本文在290 个人工生成的和17 个真实数据集上,计算第1 章提出的各种不确定性度量,研究它们和分类性能之间的关系,以及各指标之间的相关性;发现不确定性作为数据的元特征的重要依据,以及它们之间的相互关系。
2.1 人工数据集上的相关性分析
首先在人工生成的数据集上对之前提到的几种不确定性度量进行计算。使用sklearn 库中的生成数据函数make_circles、make_blobs、make_classification 和make_moons函数来生成数据集,每个数据集包含500 个随机样本点,属性维数为2。通过改变噪声、类间距离、数据团大小和属性范围等参数得到不同的数据集。
图1 中是两组不同参数所生成的数据集,都含有三个决策类、两个属性。它们的类间距不相同,图1(a)类间区别明显,分类算法很容易可以将不同类别的样本分辨开来;而图1(b)中类间距很小甚至为负,类别之间纠缠在一起,使得分类算法较难以分辨开不同的类别。通过改变函数中噪声、聚类大小、密度等参数可以生成多样的数据集,它们能够具有明显不同的不确定性大小。可以在这些数据集上计算第2 章中提出的几种度量作为数据的特性,分析这些特征与分类结果之间的关联。以图1 中两个数据集为例,计算得到不同特征的度量以及分类准确率如表1 所示。
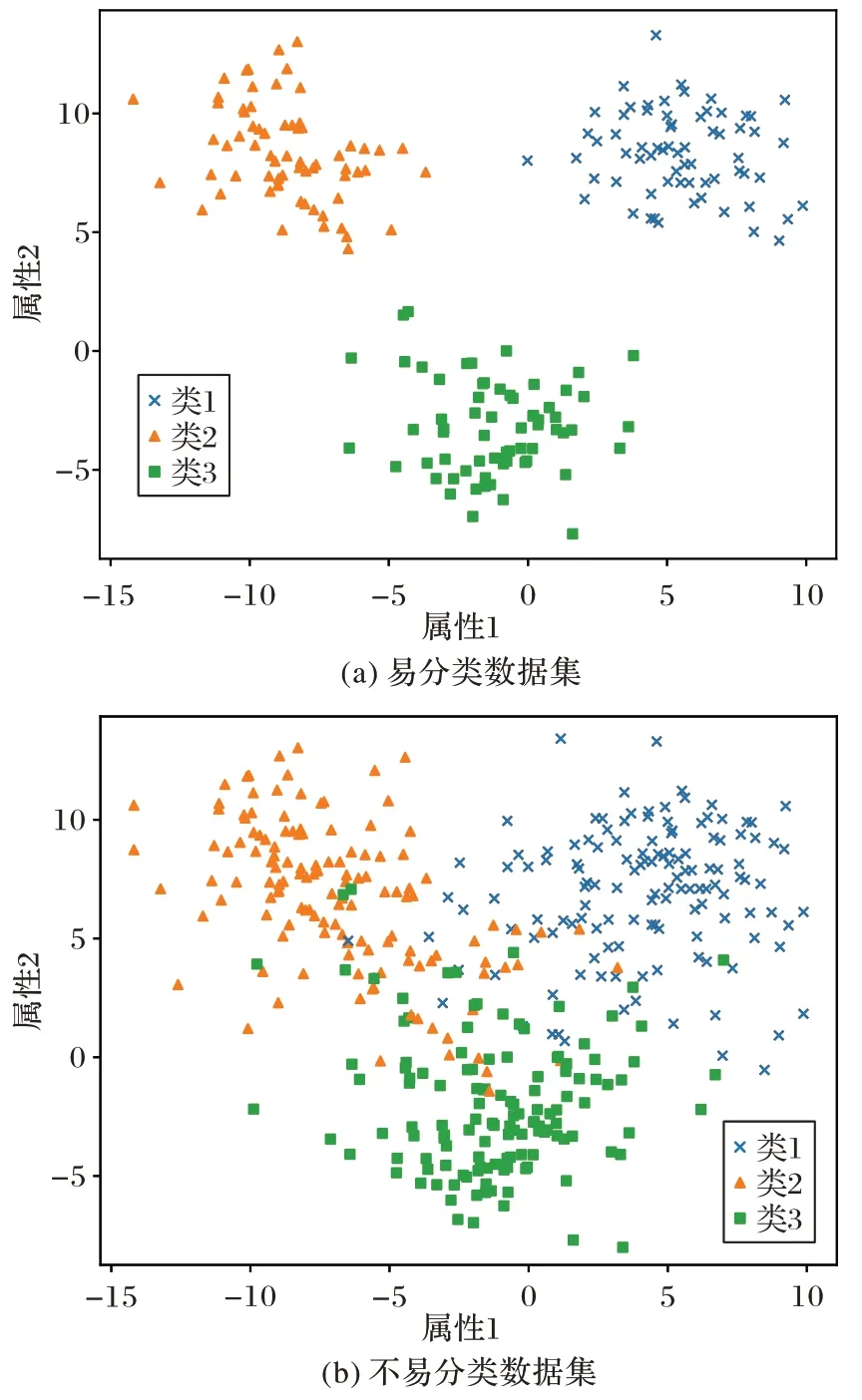
图1 不同参数生成的数据集Fig.1 Generated datasets with different parameters

表1 图1中两数据集的不确定性度量Tab.1 Uncertainty measures of easily and difficultly classified datasets
可以看到两个数据集的特征值具有明显的差异:易分类数据集的多数特征值明显大于不易分类数据集,线性可分度也高于不易分类数据集,分类准确率也显示了同样的结果。
这样,通过改变参数生成不同数据。将参数变化范围设为0.2,从小到大每一次改变一个参数随机生成10 个数据集,共生成290 个。在这290 个数据上对之前提出的6 种不确定性进行度量。同时对每一个数据集用多个经典分类算法进行分类,包括K近邻算法、神经网络、支持向量机和决策树算法。对每一个数据集输出这4 分类算法的分类准确率,之后计算上述不确定性度量与分类算法准确率之间的相关性,查看不确定性与平均分类结果之间的相关关系。计算相关性使用皮尔森相关系数(Pearson Correlation Coefficient,PCC):
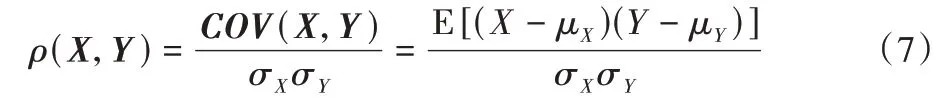
其中:COV(X,Y)为协方差矩阵;σXσY为标准差的乘积;μX和μY是X和Y的平均值;E[]为正期望。相关系数为正表示两者为正相关,为负代表两者负相关。其中:|ρ|<0.3 表示弱相关性,0.3<|ρ|<0.7 为中度相关,|ρ|>0.7 代表强相关关系。数据不确定性与分类结果具体相关系数如表2 所示。

表2 不确定性度量与平均分类结果的相关性Tab.2 Correlations between uncertainty measures and average classification results
从表2 可以看出,与分类结果相关度最高的是边界复杂度和模型输出的不确定性,相关度绝对值为0.97;不一致度和特征空间的不确定性相关度在0.70 左右;相关度最低的特征是属性重叠度,相关度绝对值为0.65。因此不一致度、边界复杂度、输出不确定性和特征空间的不确定性特征与分类结果之间的关系为强相关关系;属性重叠度为中等相关关系接近强相关关系。说明这几个特征对分类结果具有较为显著的影响。其中不一致度、边界复杂度和属性重叠度为负相关关系,表明这三个特征越大时分类结果的效果越差,与直觉吻合。因为不一致度代表属性值相近但决策类不同的样本比例,边界复杂度代表边界的样本比例,而属性重叠度代表类间属性值重叠区域占整个属性空间的比例。从这三个特征的定义可以看出它们对分类算法都是负面影响,因此这些特征的增大意味着分类效果的下降。输出不确定性、线性分类准确率和特征空间的不确定性与分类结果都是正相关,即这三个特征值越大分类效果越好。
另外还测量了各个不确定性度量之间的相关度,它们之间的相关度见表3。其中相关度最高的是输出的不确定性与边界复杂度,它们之间的相关度绝对值为0.98,说明这两个特征度量之间具有极强的相似性,边界越复杂意味着不确定性越大;反之亦然。其次是不一致度和特征空间不确定性、不一致度与输出不确定性之间的相关性都约为0.7,相关性较强,其余特征之间的相关性较低,说明其余特征之间相对独立。
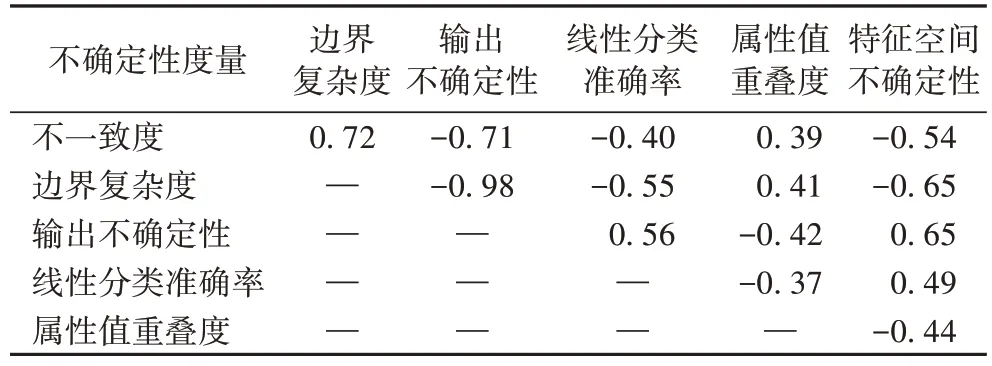
表3 不确定性度量互相之间的相关性Tab.3 Correlations between uncertainty measures
2.2 实际数据集上的相关性分析
本文同时收集了一些真实数据集并在其上进行了不确定性特征的测量和分类准确率的测量,分析它们之间的联系,是否与在人工数据集上得到的数据相仿。真实数据集如表4 所示,所有数据均取自UCI 数据集,这些数据集都是机器学习分类任务中较为常用的数据集,
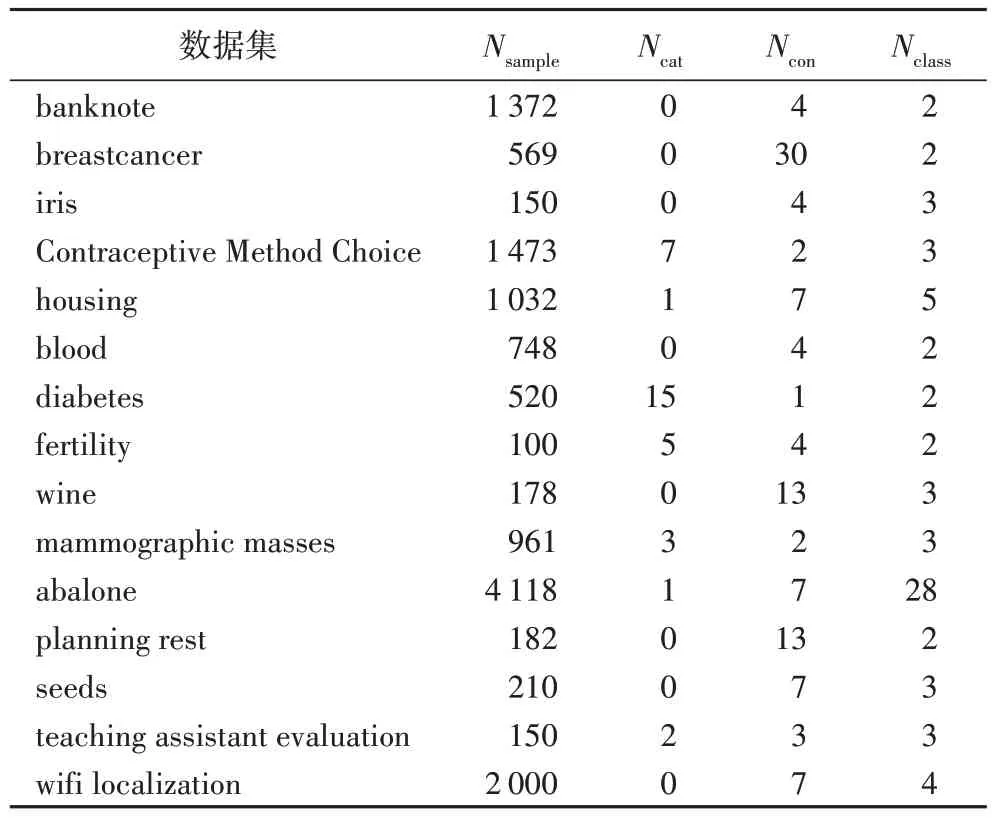
表4 真实数据集Tab.4 Real datasets
其中的样本都有清晰且数量适中的决策类,属性包括离散属性和连续属性,样例数适中,便于对数据集进行后续处理和用分类算法对数据进行分类。其中:Nsample为数据集中的样本总数;Ncat为离散属性个数;Ncon为连续属性个数;Nclass是数据集中的类别数,共有几个不同的类。
由于其中一些真实数据集包含离散属性,因此对离散的字符型属性都进行了数值化处理;之后对所有属性进行标准化处理。标准化公式如下:

将原属性值减去该属性最小值再除以属性的范围即得到标准化后的属性值。
本文还在真实数据集中添加噪声来生成含有噪声的数据集,所有噪声点都为随机生成,噪声点的个数约为原数据集的1/3,噪声点随机分配类别;之后对所有的数据集计算不确定性度量的取值,最后共得到20 个数据集上的不确定性特征和分类算法准确率,见表5。其中后方标记有(noise)的数据是指通过向原始数据集中添加随机噪声后得到的。

表5 真实数据集上的不确定性度量与分类准确率Tab.5 Uncertainty measures and classification results on real datasets
实验结果显示不确定性度量与分类准确率之间的趋势大致相同,具体的相关度见表6,与在人工数据集上所得到的相关性大致相同。综上可以看出,本文所提出的几种不确定性度量能够显著影响分类器的学习性能,可以作为一类重要的元特征。

表6 真实数据集上的不确定性度量与分类准确率的相关度Tab.6 Correlation between uncertainty measures and classification accuracy on real datasets
3 结语
本文从不同方面考虑了数据和模型具有的不确定性,具体定义和给出了几种不确定性的标准和度量方法,并通过实验验证了它们与分类算法性能之间的关联。其中,不一致性反映了属性与类别的关系;边界复杂度、输出不确定性和线性可分度可以表示分类的复杂程度;属性重叠度显示类别之间的重合程度,特征空间不确定性不考虑类别仅对属性空间进行测量。这些度量是从数据的属性与类别的关系、分布的复杂程度、问题的难度,以及结合分类算法后输出的模糊程度等角度分别衡量数据本身的特性,各度量之间没有明确的理论上的关联,但在结果上可能有一定的相关性。大量人工和真实数据集上的结果表明所提出的几种不确定性均与使用经典分类算法的测试结果之间具有较强的相关性。其中模型输出的不确定性和边界复杂度与分类性能的相关系数超过0.9,说明边界越复杂不确定性越大,问题越困难,分类精度越低。此外还分析了这些度量之间的相关性,边界复杂度、不确定性与不一致度之间的相关度较高,可以整合为一种不确定性。这些初步分析可以为元学习框架下元特征体系的构建提供帮助。
