基于卷积神经网络交互的用户属性偏好建模的推荐模型
2022-03-01潘仁志钱付兰张燕平
潘仁志,钱付兰*,赵 姝,张燕平
(1.安徽大学计算机科学与技术学院,合肥 230601;2.计算智能与信号处理教育部重点实验室(安徽大学),合肥 230601;3.信息材料和智能感知安徽省实验室(安徽大学),合肥 230601)
0 引言
在浏览电影等网页时,面对数以万计的电影或者商品,用户很难从其中发现自己喜欢的电影或者商品,推荐系统(Recommender System,RS)[1-2]可以帮助用户选择用户可能感兴趣的电影或者商品。RS 通过考虑用户的历史交互[3]以及自身偏好,可以从海量数据中挖掘用户可能感兴趣的电影或者商品,并推荐给用户。
潜在因子模型(Latent Factor Model,LFM)如矩阵分解(Matrix Factorization,MF)[4]以其优异的性能已经成为学术界以及工业界广泛研究和应用的推荐模型。MF 模型的思路是将仅有部分评分数据用户-物品评分矩阵分解为用户的潜在因子矩阵和项目的潜在因子矩阵,其中用户与项目的潜在因子矩阵的每一行都代表用户与项目的潜在向量表示,然后将缺失评分的用户的潜在向量表示和项目的潜在向量表示相乘得到该用户对该项目的评分,尽管其结构简单,但MF模型已被证明在各种推荐任务中是有效的。虽然MF 在推荐上被证明是有效的,但是其存在数据稀疏性问题。当用户-项目交互数据不足时,尤其是当模型增加了一个新的用户或者一个新的项目,新的用户和项目几乎没有评分记录,这就会导致模型学习的用户和项目表示不够准确,从而影响推荐效果。为了克服这一不足,近几年有些工作提出了引入辅助信息学习用户和项目的表示。例如,考虑到用户对项目的评论里包含了一些对用户和项目的特性描述,文献[5]中提出了一种具有个性化关注的神经推荐(Neural Recommendation with Personalized Attention,NRPA)模型,从评论中学习用户和项目的向潜在向量表示。除了评论信息之外,利用用户和项目的自身属性信息也能够帮助模型学得更准确的用户和项目的向量表示,因此文献[6]和文献[7]中提出了利用属性信息学得更准确的用户或项目的向量表示。文献[8]中提出了一种基于注意力的内容与协作模型(attention-based model named Attentional Content &Collaborate Model,ACCM),该模型结合了基于内容(Content-Based,CB)和协同过滤(Collaborative Filtering,CF),并且利用注意力机制控制CB和CF 两种类型的信息的比例。虽然利用辅助信息可以学得更准确的用户和项目表示,但是这些LFM 在建模时仍然存在一些问题。例如:第一,LFM 在对用户建模时候,忽略了用户如何根据其特征偏好对项目作出决策。如图1 所示,年龄6 岁的用户更喜欢卡通片,职业为IT 的可能更喜欢科技类电影等。第二,在进行特征交互时,通常采用内积的交互方式,然而,这些方法隐含地假设嵌入维度彼此独立,这就违背了潜在维度的语义[9]。
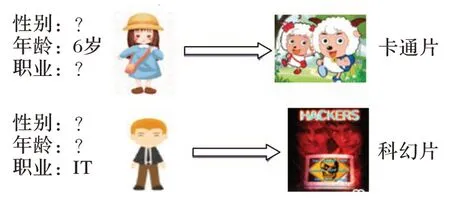
图1 不同属性的用户喜爱的项目不同的示意图Fig.1 Schematic diagram of preferences of users with different attributes to different items
为了解决上述问题,本文提出了基于卷积神经网络(Convolutional Neural Network,CNN)交互的用户属性偏好建模的推荐模型(recommendation model for User Attribute preference Modeling based on CNN interaction,UAMC)。该模型首先获得用户id 嵌入表示的用户一般偏好、用户的属性嵌入和项目嵌入,然后将用户的属性和项目嵌入进行交互,目的是探索用户不同的属性对不同项目的偏好;接着将交互过的用户的偏好属性送入CNN 层,利用CNN 探索用户不同偏好属性的不同维度的关联性,得到用户的最终属性向量表示;之后采用注意力机制将用户的一般偏好和CNN 层得到的用户偏好属性结合起来,得到用户的向量表示;最后采用点积的方式计算用户对项目评分。
本文的主要工作如下:
1)本文提出的UAMC 通过建模用户自身的不同属性对不同的项目的偏好性,挖掘用户的细粒度偏好,能有效提升推荐效果;
2)在建模时候考虑到用户的不同属性对不同项目的倾向性以及用户不同属性维度之间的相关性来增强了UAMC,从而获得更好的推荐效果。
1 相关工作
矩阵分解在多数数据集上都能产生良好的结果,因此使用矩阵分解的潜在因子模型因其优异的性能得到广泛应用。一些典型的LFM 被提出用于解决不同的问题,例如基于马尔可夫链蒙特卡罗的贝叶斯概率矩阵分解(Bayesian Probabilistic Matrix Factorization using Markov chain Monte Carlo,PMF)[10]是针对以前许多协同过滤模型不能处理大数据集的问题而提出的。基于粒度计算的混合粒度评级推荐算法(Hybrid Granular Algorithm for Rating recommendation,HGAR)[11]是探索多粒度的交互信息,对用户的显式反馈和隐式反馈进行预测的模型。虽然这些改进的LFM 能够提升推荐效果,但是其始终是利用用户-项目的评级信息推测用户的偏好。然而,用户自身的辅助信息有时候对用户的偏好选择也起着重要的作用,例如年龄6 岁更喜欢卡通片,所以在LFM 中增加用户的辅助信息可以更准确地刻画用户的偏好,从而提升推荐效果,并且利用属性信息建模用户的偏好可以在一定程度上解决冷启动用户带来的推荐效果不佳的问题。
为了捕获用户的喜好,文献[6]中提出了自注意力整合网络推荐(Self-Attentive Integration NetWork for recommendation,SAIN),利用了用户属性信息和物品的属性信息,适当地将用户-项目反馈信息与内容信息相结合,用以解决冷启动问题。虽然SAIN 考虑到了特征之间的高阶交互以及结合内容信息和反馈信息,但是它将项目和用户视为独立的。
文献[12]中提出了一种用户-项目耦合关系学习的深度协同过滤推荐模型(learning explicit and implicit user-item couplings in recommendation for deep Collaborative Filtering,coupledCF),认为将用户和项目视为独立的会忽略了用户和项目之间的丰富耦合,从而导致有限的性能改进,因此它使用用户和项目的交互得到用户的交互偏好,并将用户和项目的属性融入用户的交互偏好中以此学习用户的最终偏好。文献[13]中提出一种属性感知的注意力图卷积网络(Attribute-aware Attentive GCN model for recommendation,A2-GCN),利用图形卷积网络来表征用户、项目、属性之间的复杂交互,从而学习用户的偏好。虽然这些模型利用用户的属性对用户的偏好或者利用项目属性对项目进行了建模,但是其捕获的仅仅是用户对项目属性之间的粗粒度偏好,忽略了用户是根据其某一个属性对项目作出选择的细粒度偏好。
在利用属性建模用户和项目的表示时,探索有意义的特征组合可以进一步提升推荐效果。因子分解机(Factorization Machine,FM)模型[14]学习所有与用户和项目相关的特征作为潜在因子,并根据特征之间的二阶交互作用预测评级,但是FM 模型实际应用中受限于计算复杂度,一般只考虑到二阶交叉特征。随着深度学习技术在计算机视觉的巨大成功,将深度学习技术引入推荐系统已成为人们研究的热点。Cheng 等[15]提出了广度和深度学习推荐模型(wide &deep learning for recommendation systems),该模型结合了深度神经网络的泛化能力和线性模型的记忆能力,用于学习特征交互。文献[16]提出了一种稀疏数据预测的神经网络分解机(Neural Factorization Machine for sparse predictive analytics,NFM),NFM 利用因子分解机的二阶线性和神经网络具有的高阶非线性特点进行特征交互。文献[17]中提出了一种特征级深层自我注意网络(Feature-level Deeper Self-Attention nerwork for sequential recommendation,FDSA)用于序列推荐,先利用自注意力机制对特征分配不同的权重,再利用多层感知机进行高阶特征交互。虽然这些深度学习模型对特征进行了交互,但是这些模型隐含地假设嵌入维度彼此独立,违背了潜在维度的语义[9]。面对这样的问题,文献[18]和文献[19]都提出了利用CNN 学习特征交互的模型,解决了普通的深度学习网络(Deep Neural Network,DNN)只能隐式地和逐位地生成特征交互的问题,充分考虑了不同特征之间潜在维度之间的交互。
本文提出了一种基于卷积神经网络交互的用户属性偏好建模的推荐模型。在本文研究的模型中,本文模型不仅引入用户的属性信息来丰富用户的潜在向量表示,同时对用户的属性信息进行细粒度偏好的建模,除此之外,本文模型还引入了3D 卷积神经网络对用户的特征进行交互建模,用于解决DNN 进行特征交互假设不同特征维度是独立的问题。
2 UAMC
UAMC 有效地结合了用户的属性偏好和用户的一般偏好进行评分预测任务。图2 为UAMC 的整体结构。模型由以下五部分组成:1)输入和嵌入层。获得经过one-hot 编码后用户id、项目id 和用户属性的潜在空间表示。2)属性偏好层。将获得的用户属性向量和项目id 嵌入向量对应相乘交互,模型中这一层的作用就是探索用户不同的属性对不同项目的偏好程度。3)立体卷积层。将属性偏好层获得的用户偏好特征向量进行立体卷积操作,用于解决传统全连接层采用内积交互没有考虑到用户不同属性维度之间的关联问题,得到用户最终偏好属性的向量表示。4)注意力结合层。将立体卷积操作获得的用户偏好属性向量表示和用户id 嵌入得到的用户一般偏好表示结合起来,获得最终的用户向量表示。5)输出层。将注意力结合层获得的用户向量表示和项目的id 嵌入表示点积,输出用户对项目的评分。
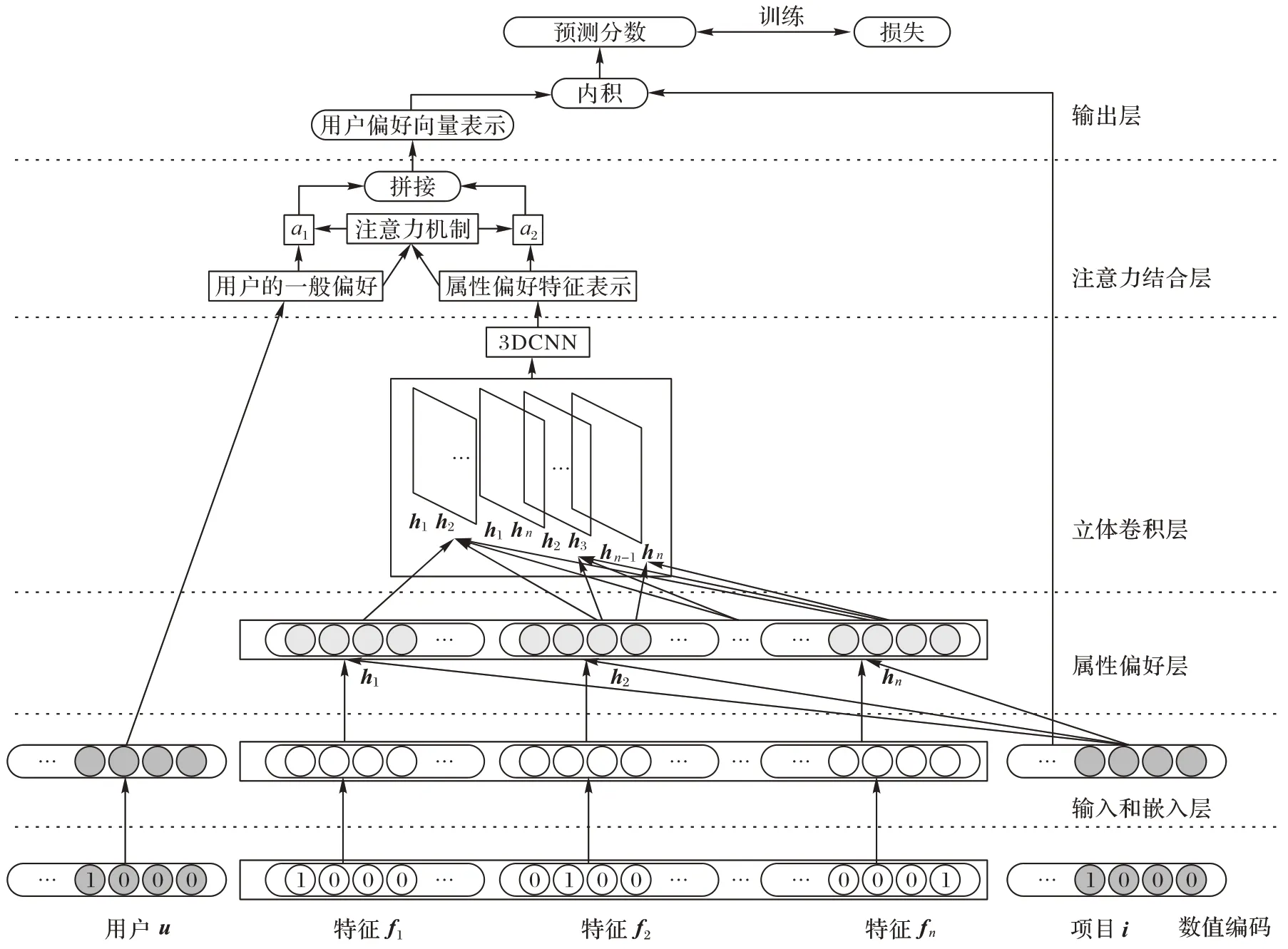
图2 UAMC的整体结构Fig.2 Overall structure of UAMC
2.1 输入和嵌入层
输入和嵌入层作用是为了获得用户、项目和用户属性的初始潜在空间向量表示。本文模型使用从0 开始的数值分别来编码用户id、项目id 和用户不同属性的值表示,然后通过一个完全连接层将其嵌入到连续低维表示空间中。本文模型使用U∈Rm×d、I∈Rn×d和F∈Rl×d分别表示用户、项目和用户属性的嵌入矩阵,即完全连接层,矩阵U、I和F的初始值是通过随机初始化而得到的,其中d为潜在嵌入空间的维度,m、n和l分别是用户、项目和用户属性的数量。矩阵U、I和F是通过模型训练所学的模型参数。通过用户、项目和用户属性的数值编码分别取得嵌入矩阵U、I和F对应行向量,得到d维的密集潜在向量表示,分别用uj、ij和f={f1,f2,…,fn}表示,uj、ij和fj分别为矩阵U、I和F的第j行。
2.2 属性偏好层
在这一部分将介绍如何通过建模去解决用户如何根据其不同特征对不同项目作出决策。
经过输入和嵌入层,得到了用户、项目和用户属性的潜在向量u、i和f={f1,f2,…,fn}。如果只是简单地将用户的属性向量f={f1,f2,…,fn}经过全连接层拼接起来,在与用户的一般偏好表示uid进行拼接得到用户的潜在空间向量表示[6-7],通过这样的模型仅仅是捕获用户对项目的粗粒度偏好,没有考虑到用户是因为自身具备的哪一点属性导致用户喜欢这一个项目,因此通过这样的方式得到用户的表示向量没有考虑到用户的细粒度偏好的建模。
为了解决上面这一问题,在属性偏好层本文模型将项目嵌入i和用户的每一个属性嵌入fk进行交互,如果用户的某一个属性fk越偏好某一个项目i,则它们在潜在空间的相似性越高,从而用户的这个属性向量对这个项目的倾向性越高。例如属性年龄6 岁的用户倾向动画片,职业IT 的更倾向黑客电影。其描述公式如式(1)所示:
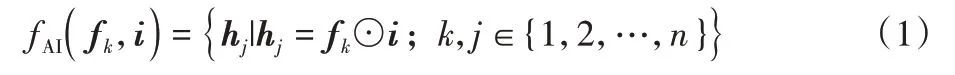
其中:fAI(x,y)表示对两个向量进行点击操作。
2.3 立体卷积层
在经过属性偏好层之后,得到了用户属性偏好向量的表示h={h1,h2,…,hn}。
在得到用户的特征表示之后,大多数模型[11,13-14]都会进行特征交互操作,特征交互的意义在于探索不同的交互特征对用户的选择的影响。然而,对于两个特征向量fi={a1,a2,…,an}和fj={b1,b2,…,bn},大多数模型都采用内积进行特征交互,从而得到用户属性向量集合h的最终属性向量表示,如式(2)所示。

这样的特征交互操作存在一个问题,即对任意两个属性向量fi和fj,这些模型隐含地假设嵌入维度彼此独立,没有探索a1b2的交互带来的作用,这违背了潜在维度的语义关系[6],故本文模型采用外积的交互方法去探索每一个属性维度之间的关联性,如式(3)所示:
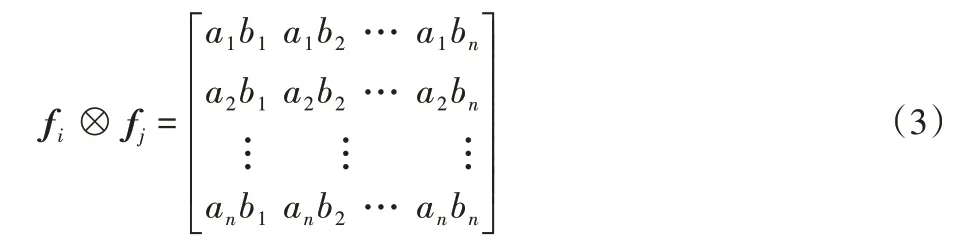
从式(3)可以看出,本文模型对任意两个属性向量的不同维度之间进行了交互。
对于任意两个偏好特征向量hi和hj,经过式(3)的操作之后,本文模型得到任意两个特征向量的外积表示L={Lk|Lk=hi⊗hj,i,j∈[1,2,…,n]}。集合L中的每一个元素相当于一张“图片”,通过将集合L中的每一个元素进行拼接操作,再送入到3DCNN 中,最终得到用户的属性向量表示。通过这样的方式得到的用户属性向量避免了采用内积交互假设嵌入维度彼此独立的问题。如式(4)所示:

其中:f3DCNN(·)表示立体卷积操作;fu表示最终的用户属性向量。
在进行3D 卷积操作时,对于Movielens 数据集,因为其用户属性为3 个,所以本文模型设置输入通道数和输出通道数都为1,卷积核kernel_size 的大小为(3,3,3),卷积步长stride为8;而对于Book-crossing 数据集,因为其用户属性为2 个,所以设置输入通道数和输出通道数都为1,卷积核kernel_size 的大小为(1,1,1),卷积步长stride 为8。在进行CNN 操作时候,为了防止模型过拟合情况的发生,本文模型引入了dropout 函数,在Movielens-100K 和Movielens-1M 和Book-crossing 的dropout 参数分别为0.07、0.5 和0.2。
2.4 注意力结合层
注意力机制[20]是用于对不同的信息分配不同的权重,对于结果重要的信息分配更多的权重。基于注意力机制的特点,本文模型利用注意力机制将立体卷积层获得的用户属性偏好向量fu和用户id 嵌入得到的用户一般偏好uid结合起来,获得最终的用户向量urep表示。如式(5)所示。

其中a为注意力分数,计算公式如式(6)所示:

其中:g(·)表示全连接层。
本文模型利用注意力机制来结合这两个信息的原因在于:根据交互数据的数量给予两种信息不同的权重[8]。如果用户和项目的交互数据是足够多的,那么交互信息是更值得挖掘的信息,因此应该给交互信息更大的权重。另一方面,如果一个用户在系统中的交互数据较少时,应该给用户属性偏好信息更多的权重,通过偏好特征向量挖掘用户可能喜欢的项目。
2.5 输出层
通过注意力机制层,本文模型得到了用户的最终表示向量urep,最后,通过内积的计算方法计算用户对项目i的相对偏好分数y。y的计算公式如式(7)所示。

3 优化
本文模型UAMC 进行评分预测任务,因此使用均方根误差(Root Mean Square Error,RMSE)度量该模型预测的分数与真实分数的差距。RMSE 的公式如式(8)所示。
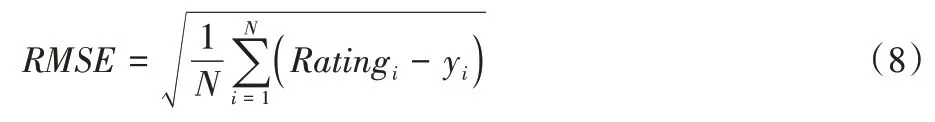
在进行损失训练时,本文模型的损失函数不仅包含了最终的预测评分,同时也包含了用户的一般偏好u对项目的评分,即用户id 嵌入向量对项目id 嵌入向量的评分,以及经过立体卷积层的属性偏好向量fu对项目的评分。通过对这三个损失的综合评分进行最小化训练,用户向量和用户特征潜在向量被独立地训练,模型的准确度得到进一步提高,因此,本文的损失函数公式如式(9)所示:
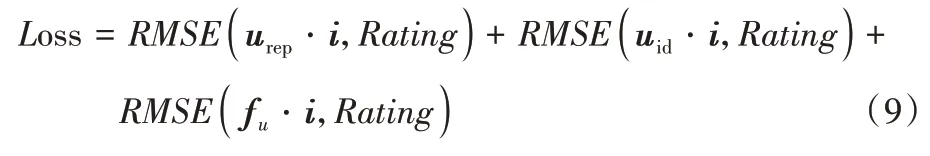
4 实验与结果分析
本文从三个问题上对UAMC 的性能进行评估。
问题1:与最先进的潜在因子模型相比,本文模型UAMC的性能是否更好。
问题2:引入的外积操作在进行探索高阶特征交互能否提升模型的性能。
问题3:Attention 机制的运用是否能够提升模型的性能。
4.1 数据集
本文模型是利用用户属性和评分进行评分预测任务,为了评估UAMC 的性能,本文选取了三个具有评分以及具有用户属性的数据集。处理后的数据集的统计如表1 所示。对于这三个数据集,本文模型按照8∶1∶1 的比例将其分为训练集、验证集和测试集。每个数据集的详细介绍如下:
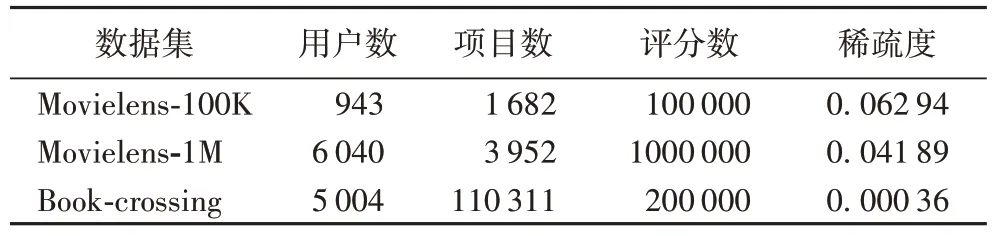
表1 数据集统计Tab.1 Datasets statistics
1)Movielens-100K,是推荐领域最受欢迎的数据集之一,主要是用于电影推荐领域,包含用户对电影的评级、用户的属性信息和项目的属性信息。数据集最初是由Grouplens构建的。Movielens-100K 包含了943 位用户,1 682 部电影以及943 位用户对1 682 部电影的100 000 条评分记录。在这个数据集中,本文模型所用到的用户属性信息有性别、年龄和职业。
2)Movielens-1M,也是推荐领域最受欢迎的数据集之一。Movielens-1M 和Movielens-100K 包含的信息类别是相同的,本文模型所用到的用户属性信息和Movielens-100K 相同。相较于第一个数据集,这个数据集包含的评分信息较多,用户项目之间的交互更丰富。Movielens-1M 包含了6 040位用户,3 952 部电影以及它们之间的1 000 000 条评分记录。
3)Book-crossing,是关于用户对于图书评分的数据集,用户的属性值有年龄以及地址。它有5 004 位用户和110 311 本图书,用户对图书的评价记录只有200 000 条,该数据集具有显式和隐式两种评分信息。Book-crossing 数据集是最不密集的数据集之一。
4.2 评价指标
在评分预测的任务中,均方根误差RMSE 和平均绝对误差(Mean Absolute Error,MAE)是常用的两个评价指标。RMSE 是用来衡量观测值与真实值之间的偏差,常用来作为机器学习模型预测结果衡量的标准,如式(8)所示;MAE 是绝对误差的平均值,可以更好地反映预测值与真实值误差的实际情况,公式如式(10)所示。对于这两个评价指标,值越小越好。

4.3 对比模型
本文模型UAMC 使用了评分以及用户属性信息,因此将UAMC 与使用评分或者使用评分和用户属性的模型进行了比较:
1)MF[4]:在2009 年的Netflix Prize 竞赛中被提出,它只使用了用户-物品交互数据。MF 被广泛应用于推荐任务,特别是评级预测任务中。
2)神经网络协同过滤(Neural Collaborative Filtering,NCF)[21]:是由深度学习和矩阵分解两部分组成的推荐模型,其包含广义矩阵分解(Generalized Matrix Factorization,GMF)、多层感知机(Multi-Layer Perceptron,MLP)和融合层三部分,它分别使用GMF 和MLP 两个部分对用户项目的交互进行建模,模型框架简单而且通用。
3)NFM[16]:神经因子分解机在二阶特征交互中利用了因子分解机的线性,在高阶特征交互中利用了神经网络的非线性,并且该模型建模时减少了更多训练参数的引入。
4)JICO(Joint Interaction with Context Operation for collaborative filtering)[22],是结合交互信息与上下文信息的上下文感知推荐模型。在两个Movielens 数据集上用到的上下文信息只有用户的年龄、性别和职业。它通过解决以前的上下文感知推荐模型无法准确地捕捉环境的影响,进一步正确地建模用户/项目和上下文之间的关系。
5)多分量图卷积协同过滤(Multi-component graph Convolutional Collaborative Filtering,MCCF)模型[23],它的思想是探讨用户-项目二分图中简单边下的购买动机之间的差异。具体来说,MCCF 内部有两个精心设计的模块:decomposer 和combiner。前者首先对用户-商品二分图中的边进行分解,以识别可能导致购买关系的潜在成分;后者自动重组这些潜在的成分,以获得统一的嵌入预测。
6)HGAR[11],是结合显式反馈和隐式反馈的推荐模型。输入的数据是用户-项的交互信息,该模型的核心思想是探索交互信息的多粒度,对用户的显式反馈和隐式反馈进行预测,HGAR 采用奇异值分解模型来获取外显信息,而隐式信息可以通过深度学习的多层感知得到。
4.4 具体实现
本文使用pytorch 实现本文的模型。在三个数据集上,本文模型对用户、项目和用户属性采用的嵌入维度为64。在三个数据集上,模型所采用的学习率和l2正则化各不相同。在Movielens-100K 数据集上,模型所使用的学习率和l2正则化分别为2E-4 和5E-5;在Movielens-1M 数据集上,模型所使用的学习率和l2正则化分别为6E-4 和2E-5;在Bookcrossing 数据集上,模型所使用的学习率和l2正则化分别为1E-2 和0.1。
4.5 实验分析
4.5.1 UAMC的性能
将本文模型UAMC 和对比模型在三个数据集上进行了比较,结果见表2。表2 没有给出MCCF 在Movielens-1M 和Book-crossing 数据集的结果,因为这两个数据集相较于MCCF 模型来说是很大的数据集,训练时间过于长久;而JICO 模型则是因为没有获得到它的源码。从表2 可以看出,本文模型UAMC 在Movielens-100K 和Book-crossing 数据集上的两个评价指标都优于所有的对比模型;在Movielens-1M 数据集上的MAE 评价指标相较于JICO 和HGAR 的模型结果要差一些。在Book-crossing 数据集上,可以看出UAMC 在RMSE 和MAE 评价指标上相较于每一个对比模型改进的效果较差,相较于仅仅使用评分信息的MF[4]降低仅为0.39%和1.10%,相较于使用了属性信息的NFM 降低了0.25%和0.66%;Movielens-100K 相较于MF 降低了1.68%和1.21%,相较于NFM 降低了1.75%和1.97%;Movielens-1M 相较于MF 降低了1.78%和1.57%,相较于NFM 降低了2.78%和2.43%。经过分析得出可能有三点原因:1)Book-crossing 数据集本身过度稀疏;2)数据集提供的用户属性种类较少,仅有两种;3)将地址作为用户的一个属性并不能确切地反映用户的偏好。在Movielens-100K 数据集上,本文模型相较于JICO 模型在RMSE 和MAE 的增益为4.82% 和4.78%,在Movielens-1M 数据集上,增益为1.02%和-1.77%,虽然本文模型在Movielens-1M 上的MAE 增益为-1.77%,但是总体结果都是优于JICO 模型的。同理,在两个数据集上的总体结果优于HGAR 模型。本文模型总体优于对比模型的原因在于:1)相较于仅仅使用了用户项目交互信息的模型,本文模型引入了用户属性这一辅助信息,使得用户的表示更加准确;2)相较于使用了用户属性信息的模型,本文模型在建模时候考虑了用户的不同属性对用户决策的影响。

表2 不同模型之间的性能比较Tab.2 Performance comparison of different models
4.5.2 外积操作对模型的影响
从以前的工作[11-14]可以了解到,探索特征交互对提升推荐效果是有帮助的,因此这部分将讨论使用外积操作进行特征高阶交互与内积操作进行特征交互两种方式,哪一种更能提升模型的性能。为了体现引入的外积操作能够进一步提升推荐效果,将UAMC 上的立体卷积层用内积交互代替,并将其命名为UAMC-C(缺失立体卷积层的用户偏好建模)。在Movielens-100K、Movielens-1M 和Book-crossing 三个数据集上对UAMC 和UAMC-C 的模型性能进行比较,结果见表3。
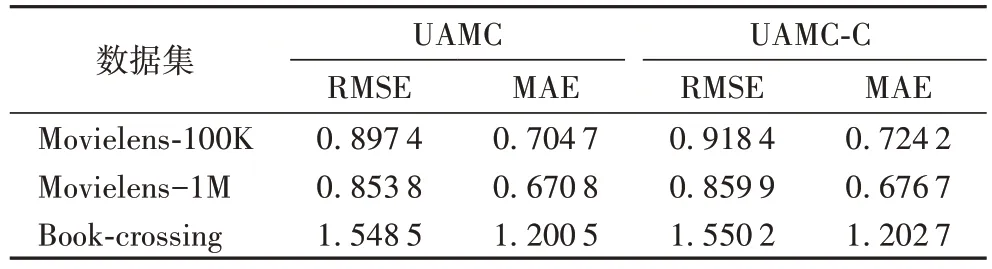
表3 引入外积操作对模型的影响Tab.3 Influence of the introduction of outer product operation on the model
从表3 的结果可以看出,UAMC 在三个数据集上的RMSE 和MAE 的评价指标结果都优于UAMC-C。在Movielens-100K 数据集上,RMSE 和MAE 的结果降低了2.29%和2.69%;在Movielens-1M 数据集上RMSE 和MAE 的结果降低了0.71% 和0.87%;在Book-crossing 数据集上RMSE 和MAE 的结果降低了0.11%和0.18%。由此可见,利用外积代替内积探索高阶交互,考虑到了不同特征之间维度的关联,从而对模型能起到提升推荐精度的作用。
4.5.3 Attention机制对模型的影响
根据第2 章的注意力结合层可知,本文模型的注意力机制的作用是根据交互数据的数量给与两种信息不同的权重,从而提升推荐精度。因此为了验证注意力机制分配权重对提升推荐效果的有效性,在这一部分本文进行了实验验证。
本文将UAMC 的注意力机制去除,对用户的属性信息和交互信息分配相同的权重,并命名为UAMC-A(缺失注意力结合层的用户偏好建模),将其与分配了注意力权重的UAMC 在两个数据集上进行了对比,实验结果见表4。从表4的结果可以看出,在模型预测的过程中,利用注意力机制根据用户-项交互信息量的大小分配了权重的模型UAMC 的结果明显优于不分配权重的模型UAMC-A 的结果。这是因为如果用户和项目的交互数据是足够多的,那么交互信息是更值得挖掘的信息,因此模型应该给交互信息更多的权重。另一方面,如果一个用户在系统中的交互数据较少时,模型应该给用户属性偏好信息更大的权重,通过偏好特征挖掘用户可能喜欢的项目。

表4 引入Attention对模型的影响Tab.4 Influence of the introduction of attention on the model
5 结语
本文提出了基于卷积神经网络交互的用户属性偏好建模的推荐模型(UAMC),该模型从细粒度的角度建模用户的不同属性对不同项目的偏好,从而学得了用户更准确的潜在向量表示。UAMC 模型对用户的每一个属性和项目进行了交互,为了能够更好地探索用户不同的属性对选择不同项目的倾向性,在进行特征交互时,本文模型采用外积的交互方式并充分地考虑到了不同特征之间维度的关联性。此外本文模型利用注意力机制用来区分用户的一般偏好和属性偏好的重要性,进一步提升了推荐效果。本文模型在真实数据集Movielens-100K、Movielens-1M 和Book-crossing 上进行了实验,实验结果表明,本文模型优于最先进的潜在因子模型。
