学术论文创新点的识别与检索入口研究
2021-12-21曹树金赵浜岳文玉等
曹树金 赵浜 岳文玉等






DOI:10.3969 / j.issn.1008-0821.2021.12.002〔中图分类号〕G250.2 〔文献标识码〕A 〔文章编号〕1008-0821 (2021) 12-0017-11
我国正在实施创新驱动发展战略, 科技创新和基础研究是创新驱动发展战略的重中之重。创新是科学研究的核心,是学术论文的本质要求。学术论文通常结构严谨,内容蕴藏着研究者的研究成果及科学发现, 是科学研究工作的结晶, 理论和应用价值丰富。蕴含创新内容的学术论文是支持科技创新的主要情报源。
据统计,全球科技文献的生产数量已达百万级别, 且以每年3%左右的速度持续增长,学术文献海量且类型多样、分布分散。学术论文创新点的获取,一方面是为了提高科研用户的科研效率,缓解信息过载现象;另一方面,从宏观角度来看, 监测创新、促进创新是科学研究发展的本质要求, 而创新本身及其表述的复杂性和多样性又为识别创新要素增添了难度。
当前, 在自然语言处理和深度学习方面的研究进展为文本的多粒度挖掘和组织提供了技术支持。已有研究从事件文档和句子级别对创新特征的自动识别进行了探索, 但在实际应用的检索系统中,并没有实现对文献创新特征的检索功能,文献创新点与创新要素仍有待揭示和描述。因此, 有必要对学术论文的创新点进行深度挖掘,提取出其中的结构化信息, 揭示不同粒度创新点表述的关联并进行存储, 以满足科研用户获取创新情报的需求, 提升情报服务的能力。
1相关研究
1.1学术创新的含义与测度
根据库恩的范式概念, 学术创新可以分为两类:一类是对已有研究进行补充和发展, 推动科学的累积式渐进; 另一类是对原有研究的颠覆, 具有革命性的创新意义。更进一步地, 关于学术论文的创新, 姜春林等认为, 学术论文的创新蕴含着从研究者的思想和观点到产生新知识的复杂过程。学术论文中的创新点可以认为是研究者研究中创新成果的文字体现。论文创新点的表现形式为作者在论文中使用的“知识主张” (Knowledge Claim), 论文作者使用的“新知识主张语句” 提供具有学术价值的新知识, 可以揭示论文的创新点。
在学术创新的相关研究中, 创新能力、水平或程度的测量一直是研究的热点之一。近年研究的热点聚焦于对学术成果本身创新性的测量, 一些研究者使用单个特征作为论文学术创新性的评价指标。比如以论文作者的h 指数、论文的被引量等单个指标为主的评价方法。从内容角度进行深层次、全面化的学术创新评价和揭示成为目前的主流趋势。如一些学者以语义相似度计算为核心, 分别从篇章级和句子级构建模型或函数测度学术成果的创新性。贺婉莹通过对不同机器学习模型的性能进行评价, 得出了适合进行创新力评价的机器学习模型。
从以上研究可以看出, 自然语言处理、机器学习等技术的不断发展促进了学术创新测度不断向更细粒度、更精准的趋势发展。这说明学术论文的创新点抽取或许可以为学术创新情报的挖掘提供一个新方向。
1.2学术信息的多粒度组织与检索
随着知识抽取技术的不断发展和学术论文全文本可获得性的不断提高, 从学术研究成果文本中获取多粒度信息并进行关联, 从而进行知识结构构建, 是一种可行且有必要的手段。
现有研究多聚焦于细粒度信息单元的获取与组织。在细粒度学术信息获取研究领域, 知识元抽取是近年的研究重点。现有知识元的抽取级别分为词级和句子级, 近年知识元抽取研究一般都以句子级为主。方法可以分为人工标注、基于规则的方法和机器学习方法。多粒度学术信息组织相对复杂, 单文档的多粒度信息组织方面, 如李湘东等提出一种基于加权特征的LDA模型和多粒度特征选择模型, 以抽取表意性较强的粗粒度特征; 多文档的多粒度信息組织方面, 如肖璐从词语、句子与文本粒度构建领域知识关联体系, 并将多个知识关联网络通过超网络技术融合成全联通的多粒度知识关联体系。
学术信息的多粒度或细粒度检索相关研究相对较少。如李祯静提出一种基于资源语义空间的科技文献细粒度语义检索方法。王忠义等基于关联数据提出数字图书馆多粒度集成知识服务方式, 并开发原型系统, 进行检索实验和评估。
总结以上研究可以看出, 虽然多粒度学术信息组织已有较多研究, 但以标注或模型构建的相关研究为主, 以检索为目的或者真正实现检索功能的研究不多。
1.3学术研究创新的识别与挖掘
学术创新的识别多指宏观层面, 而挖掘则更多指微观层面。宏观层面的学术创新识别主要包括两个研究方向: 颠覆性创新识别和探测与创新路径识别。关于颠覆性创新识别,已有不少学者进行了综述, 从对象方面一般可以分为基于专利和基于论文的颠覆性创新识别, 从方法上一般分为文献计量、文本挖掘等识别方法。关于创新路径的识别, 一般以3种方法为主:引文分析法、主题词分析法、基于多元关系融合的方法。这些研究主要是从宏观上探究学术创新的发展趋势。
对于学术论文创新点的挖掘, 除了通过相似度, 与知识元抽取类似, 一般还分为通过规则和通过算法抽取两种方法。如张帆等以领域词表和本体中的关系为基础构建识别规则, 采用基于主题词重叠度的算法评估创新点的有效性。周海晨等提出一个深度学习与规则结合的学术创新贡献识别方法, 实现了大规模学术全文本创新贡献的自动抽取。
以上研究为本文提供了重要的理论前提和方法基础。但将创新句的抽取扩展到全文的研究较少,也没有研究将句子级创新点的抽取结果应用于检索。因此, 本研究以情报学期刊论文为例, 从学术论文的句子级创新点识别出发, 以创新对象和创新维度为线索, 对创新句、相关章节和论文本身进行多粒度关联, 并以此为数据基础设计创新点检索入口,探索对创新点进行检索的可行性。
需要强调的是, 本研究所进行的学术论文创新点识别, 是完全从客观层面对论文作者在文中表述的研究创新之处进行挖掘和特征分析, 不涉及研究者的主观判断。本研究所称“创新句” 指论文作者在文中表述的,旨在提示研究创新之处的句子。
2研究设计与方法
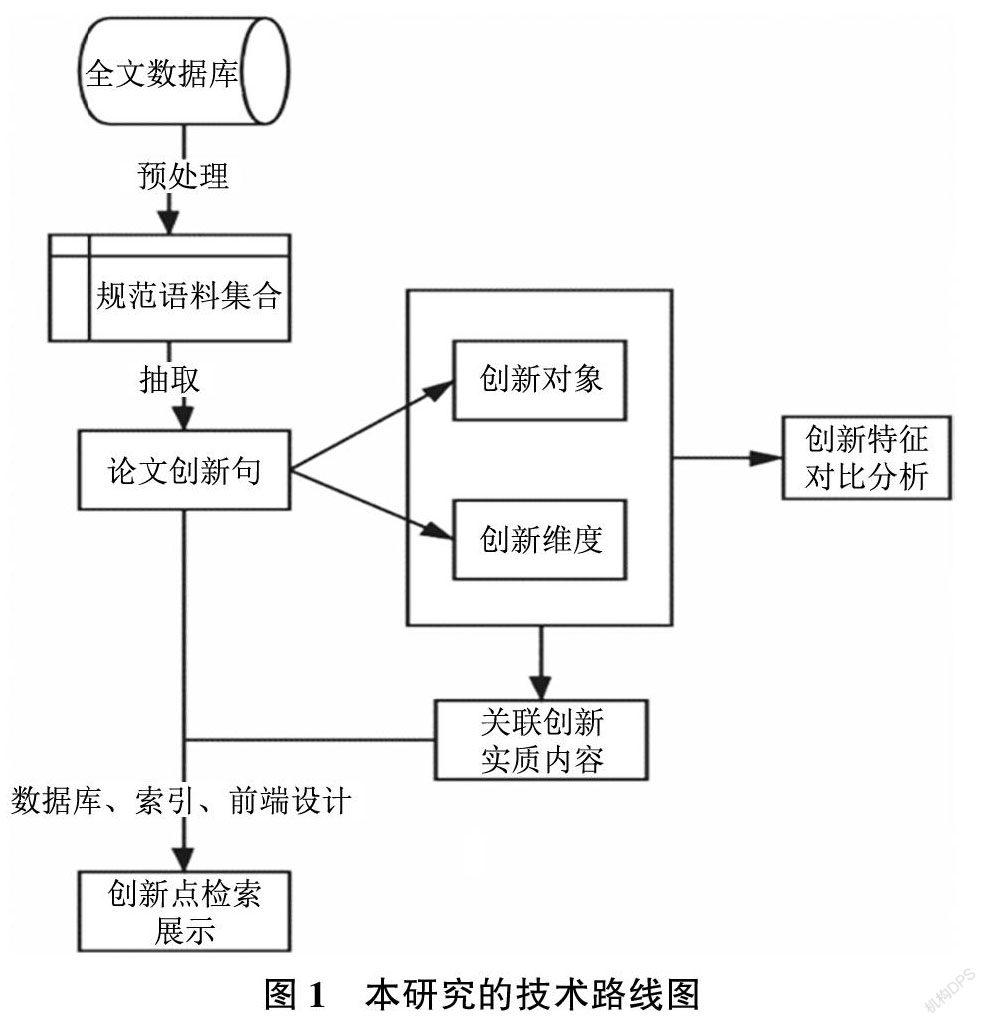
2.1研究设计 本研究分两个阶段进行, 第一阶段为领域学术论文创新句获取以及创新要素分析; 第二阶段为创新点检索入口及系统构建。由于近年情报学期刊论文写作规范化程度不断提高, 同时作者和标注人员对本领域相对熟悉, 因此选择情报学研究领域, 研究样本为情报学期刊论文。
2.1.1领域学术论文创新句获取以及创新要素分析
本阶段引入多层次研究设计, 解决“学术论文的创新点与创新要素如何获取?”这个问题。
在第一层次首先进行数据准备,包括样本数据获取、文本预处理和数据集标注。分别采集中英文各两种情报学期刊论文, 对论文文本按照一定的规则进行预处理,参考前序研究总结的创新引导词集,进行数据集划分和标注, 训练Bert语言模型进行创新句抽取; 第二层次是对创新句的进一步处理, 分析创新要素, 选择依存句法分析方法获取创新对象和创新维度。
2.1.2创新点检索入口及系统构建 本阶段通过构建创新点检索系统, 提供创新点检索入口, 解决“如何实现多粒度关联的创新点检索?” 的问题。基于上一阶段分析结果, 以创新对象和维度为线索进行创新点多粒度关联。具体来说, 提出关联章节的具体获取步骤, 将细粒度的创新句与中粒度的创新章节和粗粒度的论文本身进行关联, 实现学术论文创新内容的多粒度组织。构建创新点检索的原型系统, 选择Python 作为后端开发语言, 采用Django 作为Web框架, MySQL 作为系统数据库, 索引和检索模块由Faiss搭配Numpy实现。以识别部分进行的创新点多粒度关联为数据基础,輔以学术论文其他一些元数据导入数据库。
以“创新对象” 与“创新维度” 作为关键检索字段并在此基础上建立索引和查询, 设计前端界面并进行实验, 对检索功能模块和效果进行展示。
本研究的技术路线如图1 所示。
2.2 Bert 语言模型
Bidirectional Encoder Representations from Trans⁃formers(Bert) 是由Devlin J等与其谷歌同事于2018年在论文中提出的一种基于神经网络的机器学习技术, 来源于谷歌对Transformer 的研究成果。
Transformer 使用了注意力机制, 将序列中的任意两个位置之间的距离缩小为一个常量, 其次是避
免使用RNN 的顺序结构, 并行性更佳。因此,Bert 模型可以考虑到完整的上下文, 从而捕捉更丰富的文本语义信息。
2.3依存句法分析
现代依存句法理论由法国语言学家LucienTesniere 提出, 依存句法分析的主要目的是通过描述词之间的依存关系来揭示句子的语义结构。
Stanford CoreNLP基于标注算法先进、加工程度较深的宾州树库(Penn Treebank)作为分析器的训练数据, 面向英文、中文、德文等多语种提供句法分析功能。其优点一是支持语言的广泛性; 二是所用PCFG算法准确率高。除此之外, 其配套工具齐全, 有使用最大熵模型的词性标注工具, 基于概率解析器提供完整的语法解析的解析工具、实体识别等功能, 能够满足实验需求。
2.4 Faiss 相似性搜索库
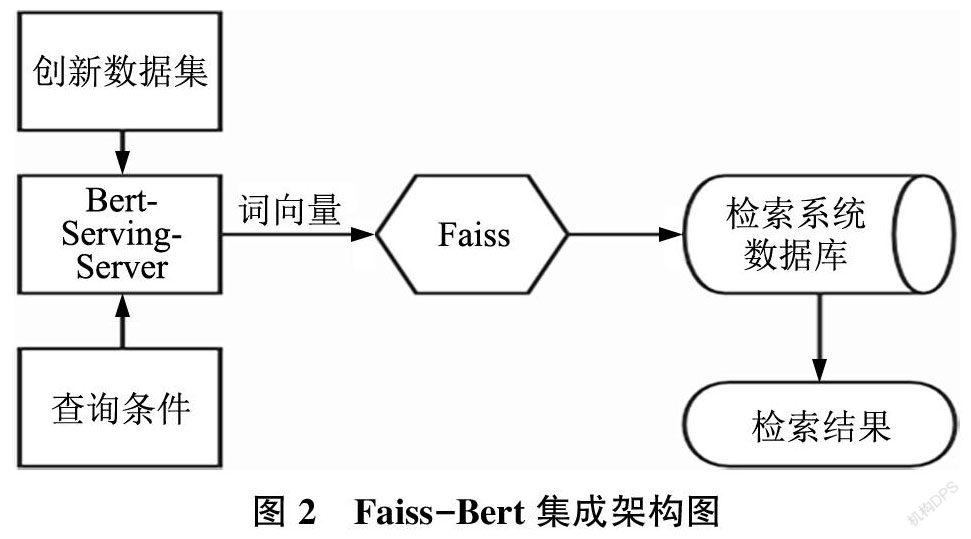
Facebook AI Similarity Search(Faiss)是FacebookAI团队开发的, 提供高效相似度搜索和稠密矢量聚类的近似近邻搜索库。Faiss 的核心是索引(In⁃dex)概念, 它封装了一组包含多种搜索任意大小的向量集, 以及用于算法评估和参数调整的代码库,并且可以选择是否进行预处理以高效地检索向量。可以预先通过Bert 模型将非结构化数据提取为特征向量, 同时利用开源的Bert-Serving-Server 启动一个Bert 向量服务, 便捷地调用训练好的词向量以及句向量, 然后通过Faiss 对这些特征向量进行计算, 实现对非结构化数据的分析与检索。本文使用的Faiss 和Bert 的集成架构如图2所示。
3创新点识别实验
3.1数据来源与文本预处理
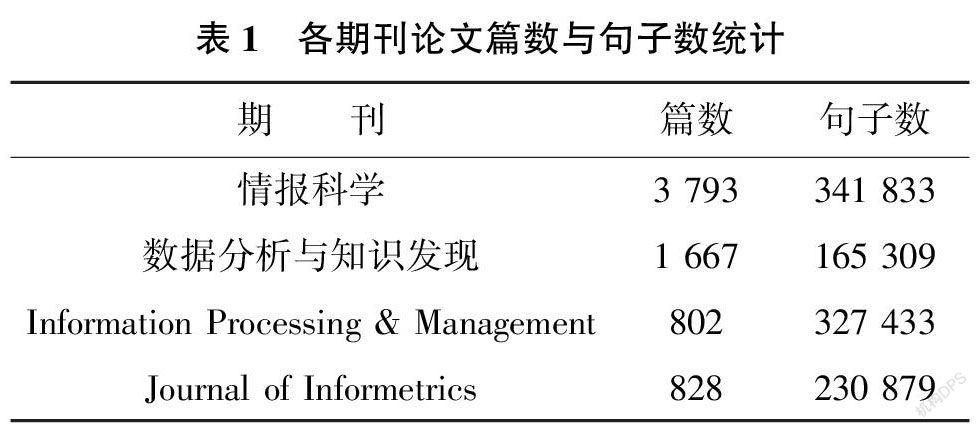
在样本的选取过程中, 主要选择高质量期刊,辅以论文易获取性和期刊影响力作为考量。经过筛选和分析, 中文情报学期刊论文以2009—2019 年《情报科学》和《数据分析与知识发现》(原《现代图书情报技术》)为数据来源, 英文情报学期刊论文选取“Information Processing & Management” 和“Journal of Informetrics” 两期刊2009—2019 年的论文作为数据来源。选择2009—2019 年发表的论文主要有两个原因, 一是截止时间较新, 能有效反映近年的创新情况; 二是时间区间较长, 获取到的论文数量多, 有利于时间角度的比较分析。研究所用到的中文期刊论文从CNKI 获取, 英文期刊论文从ScienceDirect 全文数据库获取。
获取的原始论文文本是非结构化的, 它包含了对本任务来说不必要的标记、图表等, 需要进行预处理以适用于模型。处理顺序与规则如下所示: 1)初步去除“本刊讯”、会议预告、征稿通知、“Editorial Board” 等非学术论文。
2)用Pdfminer 库进行PDF—纯文本转换。
3)分句,同时对文内不必要的部分进行剔除处理, 如分类号、参考文献、作者贡献说明、作者信息、关键词等, 保留摘要与全文内容。
最终用于实验的论文数以及分句后的句子数统计结果如表1 所示。
3.2创新点抽取
创新点的抽取分为不同粒度。与更粗粒度(如章节) 相比, 句子级抽取技术得到了更迅速的发展, 句子级别的自然语言处理技术也有更好的研究基础; 另一方面, 本研究的出发点之一是解决科研用户信息超载的问题, 用户需要的是粒度更细的创新点, 语词不能清晰完整地描述一项创新, 能够完整描述创新点的最小单元是句子。因此, 本研究选择能够揭示更完整语义且粒度较细的句子级别进行创新点抽取, 一个创新句对应一个创新点。
研究采用随机抽样的方式, 从上述分句结果集中, 抽取中文和英文总数分别为9328和11272句的两个数据集作为训练样本数据。
实验共招募3名硕士研究生进行创新点的人工标注。本文使用的创新句判别标准分为两类:
一是论文作者明确表达的创新点, 对学术论文创新的界定按创新程度粗略分为两子类, 即对已有成果的改进和与已有研究成果完全不同的“全新” 。前者包括但不限于对问题/ 方法/ 理论/ 结论的优化、修正、补充, 通常附有改进点或改进效果的说明, 如表2 例句。这一大类一般有明显的创新引导词(组), 如各种比较级句式、“首次提出” “改进” “Novel”等。后者包括: ①提出新理论; ②界定新概念; ③首创新的方法; ④针对特定问题提出不同的解决方案; ⑤构建新的系统、框架、模型等; ⑥属于新的学科交叉点或首次引入其他学科的理论、模型、方法; ⑦在理论空白点上得出新结论等。如表2例句, 即为针对特定问题提出一套不同的解决方案。
二是论文作者对创新点的隐含表达, 如表2 例句就属于一种典型的语义预设, 因为预设了“本文研究的路由排队策略” 存在的前提而得以成立。此外, 对于在综述等处提及的其他论文的创新点予以剔除, 如例句和例句。标注后得到中文情报学论文创新句占数据集总句数的9.5%, 英文情报学论文创新句占数据集总句数的4.3%。以此作为创新点识别模型构建与抽取的基础。
类别的标注示例如表2所示。
本实验均基于Python 编程语言, 使用GoogleColab 作為实验的开发环境, 使用的深度学习框架为Tensorflow, 中文语料调用由Google已完成预训练的Bert-base-Chinese 12层模型, 英文语料调用Bert-base-uncased 12层模型。
加入分类训练样本对模型进行微调后将模型用于完成创新句抽取任务。在训练超参数设定上, 经过多轮迭代调优后, batch_size 设定为32, 英文读取序列最大长度为128, 中文读取字符最大长度为256。迭代Epoch 次数为4 0, 学习率指数为2e-5。
在模型训练过程中将上文构建的人工标注数据集随机分为训练集和测试集, 选取分层十折交叉验证的方式, 每轮选取9 份作为训练集, 剩余1份作为测试集。对每轮生成的模型分别计算精度(Accu⁃racy)、查准率(Precision)、查全率(Recall)与调和平均数(F1), 测评模型识别效果, 得出最佳模型的评价指标, 如表3所示。
从表3 可以看到, 两模型的查全率和F1 值都不太高, 分析认为类别不平衡是一个重要原因。针对这个问题, 本实验分别进行了上采样和下采样的尝试, 在测试集上的指标结果有明显提高, 但预测结果明显较差。因此, 为保证训练集、测试集、预测集的类别同分布, 实验最终没有采用上采样或下采样的方法, 而是保持原数据分布情况进行训练和预测。
3.3创新点抽取结果
中文情报学论文总句集为507142句,加上标注的创新句共抽取到9 699个创新句, 平均每篇1.8句左右, 基本符合一般论文写作情况。其中2 323篇不存在创新句, 约占总数的42 5%。由于在抽取过程中以查准率为主要指标, 同时以现在的标准对较早论文的创新句进行抽取也可能产生错漏, 因此不存在创新句的论文篇数较多。创新句的平均长度约为94个字。
英文情报学论文总句集为558 312句, 加上标注的创新句共抽取到14689个创新句, 平均每篇9句左右。其中322篇不存在创新句, 约占总数的19.8%。创新句的平均单词数约为31个。
3.4创新对象和创新维度的获取
创新对象和创新维度往往构成一项创新的主要内容。创新对象是创新的客体, 回答的是“对什么进行创新” 的问题。创新维度可以理解为创新句所论述的创新对象的某个方面, 一般反映创新对象的领域特征。一个创新对象可对应一个或多个创新维度, 一篇论文的若干个创新句可以反映不同的创新维度。
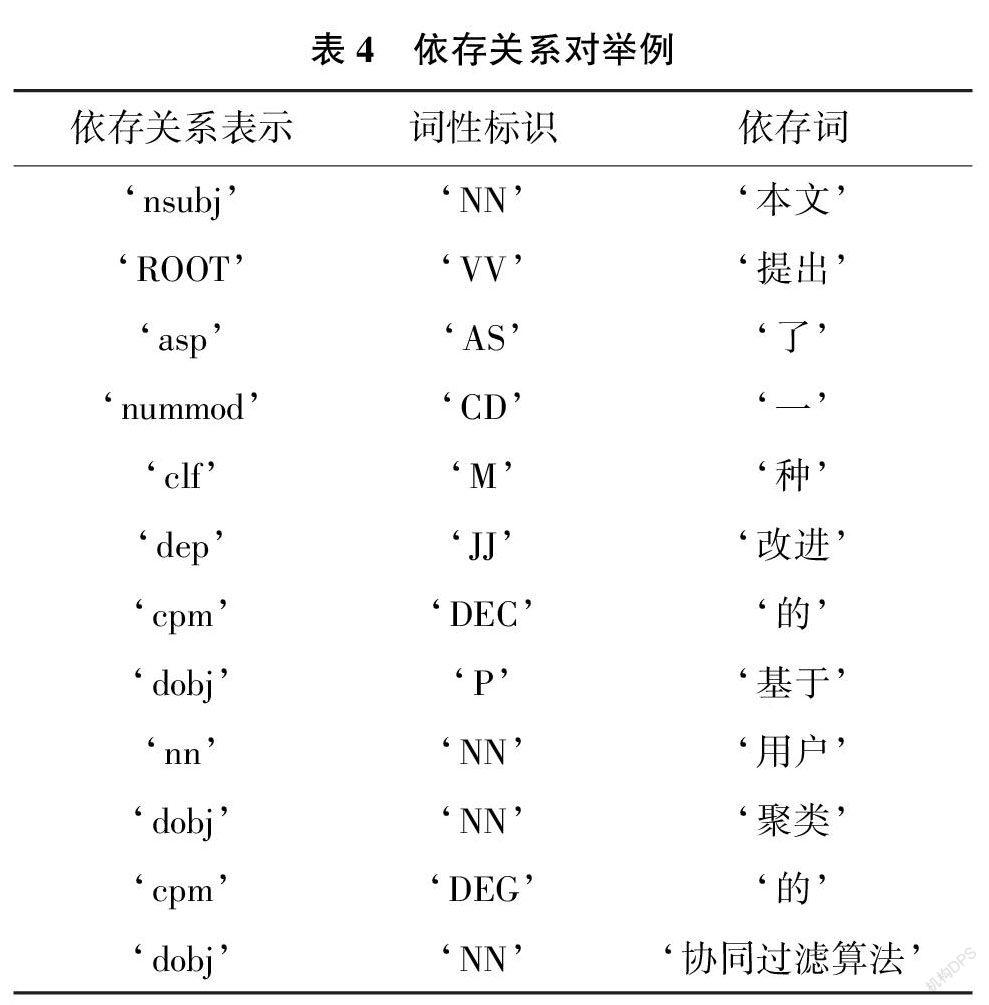
通过对创新句进行依存句法分析, 并构建规则抽取创新对象和创新维度。如对于一个句子, “本文提出了一种改进的基于用户聚类的协同过滤算法”。用Stanford CoreNLP 进行语法解析和依存句法分析的结果如表4所示。
其中“提出” 即为本句核心词, 以“dobj”依存标识引导的关系为“‘提出’ ‘基于’ ‘用户’‘聚类’ ‘的’ ‘协同过滤算法’”, 其中“基于用户聚类的协同过滤算法” 构成本句的一个直接宾语, 因此抽取“协同过滤算法” 作为创新对象;同时“用户” “聚类” 构成一个复合名词, 因此得到创新维度为“用户聚类”。依存句法分析后结果如图3 所示。
4创新点检索入口实验
4.1以创新对象和创新维度为线索的多粒度关联
作为构建创新点检索入口的数据基础, 多粒度关联的主要任务是实现创新句与相应章节的关联。需要强调的是, 这里“相应章节” 并不是创新句所在章节, 而是描述创新点的具体内容的章节。仍以3.4节所举“本文提出了一种改进的基于用户聚类的协同过滤算法” 为例, 所要定位到的章节并非这一句子所在的原文引言部分, 而是原文第四节“改进的基于用户聚类的协同过滤方法”。根据对知识多粒度的划分, 介于粗粒与细粒之间的中粒可以有很多个。在创新对象和维度优先级的问题上, 对象作为创新动作的直接客体, 能够更好地表现创新内容的本质, 因此创新对象的匹配优先级高于维度。具体定位步骤如下:
1)对论文文本进行章节识别和层级分割, 提取各级标题;
2)由最深层标题开始, 以某一创新句的对象词进行精确匹配, 匹配到即跳转至第6步;
3)若未匹配到, 则以创新句的维度词(组)重复上一步, 匹配到即跳转至第6步;
4)若仍未匹配到, 则对维度词组进行分词,以分词后的各维度词倒序分别重复第2步,匹配到即跳转至第6步;
5)若无法进一步分词或仍未匹配到, 将创新对象/维度词(组)的匹配范围扩大至全文,统计各小节(即最深层标题下)出现的次数(不包括文献综述/ 相关工作/ 相关研究部分), 返回频率最高的小节;
6)若某一步匹配到两个或以上数量的小节,则将创新对象和维度词(组)进行AND 连接在匹配结果中进一步检索,返回更精确匹配到的小节; 若仍存在多个, 则返回更高级别的标题, 同级别情况下全部返回; 若不存在则以跳转上一步匹配到的小节为准,此时若存在多个则返回多个, 若为父子关系则返回父标题;
7)回到全文定位匹配到的标题, 返回标题及标题下的内容;
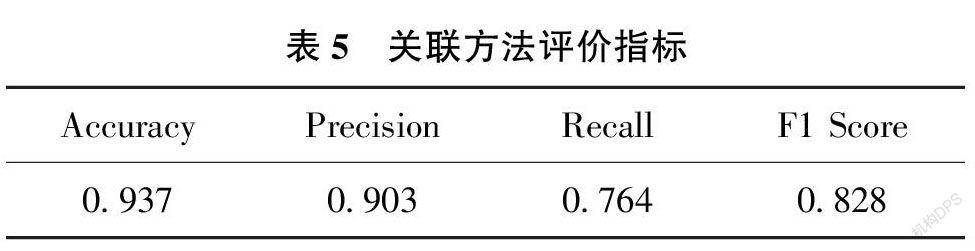
8)将返回内容与创新句关联。随机抽取中文情报学22 篇文献的111个创新句进行人工标注, 与依据上述方法进行定位的结果进行对比, 得到评价指标如表5 所示, 可以认为上述方法具有一定的合理性和可行性。
最终经过分析整理得到创新句与创新章节段落的对应关系, 部分结果如表6 所示。
4.2创新点检索系统架构设计
本文通过构建创新点检索系统提供创新点检索入口, 探索对创新点进行细粒度检索。如图4 所示, 创新点检索系统主要包括3个部分, 即数据存储、索引与检索模块和前端展示模块。所用数据来自采用3.4节方法获取的创新对象、维度及4.1节关联的创新句、相关章节和论文3种粒度的数据,辅以论文的其他元数据,包括作者、发表时间、中图分类号等, 所有数据保存至MySQL 数据库。
索引与查询模块是整个系统的核心, 主要负责完成特征提取、建立索引、排序等任务。Faiss通过Bert模型将非结构化数据提取为特征向量,对这些特征向量进行计算并建立索引, 索引库会存储相应的索引信息。
前端展示模块是系统与用户交互的界面,向用户展示搜索界面及最终的创新点检索结果。通过基于Django框架搭建的后台,索引与检索模块的检索组件会根据查询语句进行检索排序, 然后将结果返回给页面展示模块。
4.3索引与检索模块的设计与实现
索引与检索模块是通过为稠密向量提供高效相似度搜索和聚类的Faiss 构建。Faiss 提供了多种索引方法,且便于开发者根据需要选择最恰当的索引类型, 本文预选方案为基础的IndexFlatL2, 这是一种简单的检索L2 距离的索引, 可以精确遍历计算索引向量,不需要做训练操作。
利用Bert-serving-server 启动Bert 向量服务,调用微调好的Bert 模型中的词向量以及句向量,然后通过Faiss 对这些特征向量进行计算,构建索引。
当索引就绪后, 一系列Search-time 的参数可供开发者在精确度和搜索时间之间进行权衡、优化。同时,Faiss配有自动调参机制, 能扫描参数空间, 提供最佳操作点(Operating Points)。
4.4数据库设计
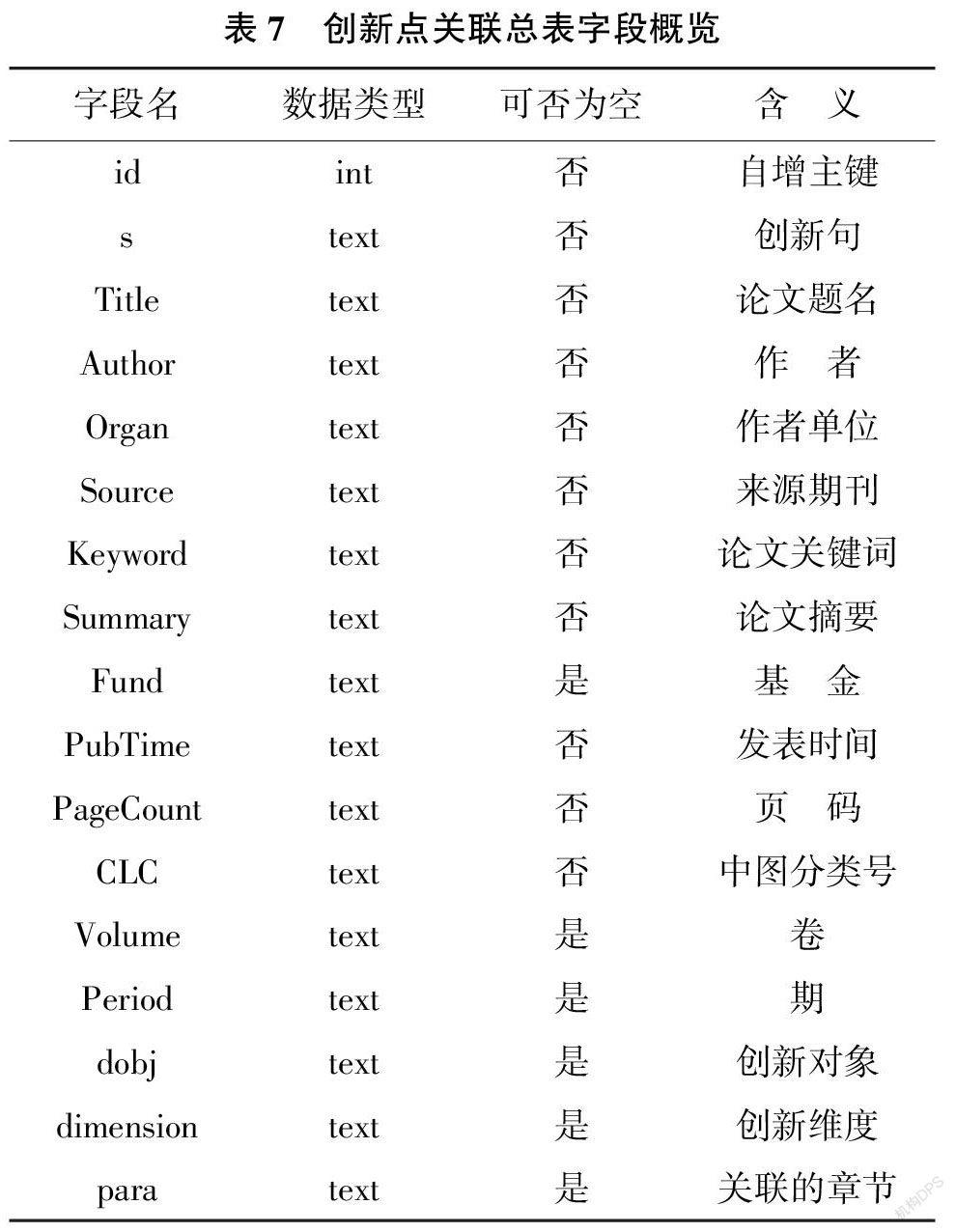
本研究采用的数据库为MySQL。在Django 框架中可以动态加载实际所需管理的内容, 以本系统中的创新点关联总表为例, 生成的创新点关联总表结构如表7 所示。
4.5前端展示模块设计与实现
在數据库和索引与检索模块搭建好后, 还需要借助Web框架,将检索结果以恰当的方式反馈给用户。
在Django 中为搜索引擎配置环境, 利用Djan⁃go 以及Numpy 实现Faiss 完整的接口支持。采用HTML+CSS+JS 技术实现系统前端的设计, Python作为后端开发语言实现系统业务层需求。项目在集成开发环境Spyder 下进行。
用户可以像使用一般的学术搜索引擎那样, 在搜索框输入查询条件, 然后点击“检索” 按钮查看检索结果。
检索入口所支持的字段类型越多越有针对性,越有利于检索效率的提高。在考虑平衡性的情况下, 在入口的可选字段,设置了针对创新句与创新章节的“创新对象” “创新维度” 关键检索字段, 以及“作者”“发表时间”“刊物”等作为可选检索字段。针对创新句与创新章节的“创新对象” “创新维度” 是加工程度较深的字段, 也是本研究的核心内容。
输入查询语句既支持单个检索词, 也支持短语检索,系统则将调用分词模块对查询语句进行分词与语义分析,例如:针对创新句输入“协同过滤算法” 作为“创新对象”的检索词, 得到检索结果如图6所示。
由图6 可以看到, 在检索结果的展示界面主要由创新句、创新对象、创新维度、题名、作者、来源刊物及发表时间等几部分构成。
类似的, 针对创新句输入“协同过滤算法”作为“创新维度” 的检索词, 得到检索结果如图7所示。
为了节省界面空间将创新句等较长字段做了压缩处理,鼠标移至创新句可完整显示; 同时通过点击右侧的“详细” 按钮, 可在详情页面获取更多信息, 如创新句的关联章节, 以及论文相关的其他元数据,辅助用户进行决策和判断, 创新句详情页如图8所示。
5结论与展望
5.1主要研究结论
从论文中识别和组织创新内容并将其用于学术检索系统, 提供创新点检索入口, 对于科学研究的创新与发展具有重要意义。研究得出以下结论:
1)Bert模型可以用于句子级创新点抽取任务,即使是在类别非常不平衡(创新句与非创新句)的数据集上也有不错的表现, 可以成功抽取出情报学研究论文中的创新句; 在创新句关联创新章节这一类问答任务上也有良好的效果。
2)以中文情报学论文为例提出以创新对象和创新维度为线索的多粒度创新内容关联方法, 并证明了其有效性和可行性。以关联后的多粒度数据为基础设计创新点检索入口, 不仅便于用户高效检索论文的创新点, 及时发掘科研新方向, 还可以通过创新内容的分解与重组进行细粒度、多维度的论文创新点分析, 以响应更多样的用户需求。同时也利于促进创新点检索系统、创新点知识图谱等应用的落地, 成为现有创新性评价体系的补充。
3)本研究的尝试表明, 通过深度学习和句法分析对论文创新点进行分析具有一定的可行性和价值。这表现为不仅可以借助这种方法对论文创新性进行更细粒度的分析, 进而对整个领域的研究创新进展有所把握, 实现监测的目的, 从而促进科学研究创新。将论文中的创新内容进行多粒度关联并用于检索, 同样具有可行性和巨大潜力, 可以为科研用户提供有力支持。
5.2研究局限及未来工作展望
本研究对学术论文创新点的识别与检索进行探究, 但信息组织和检索是复杂的系统工程, 由于理论水平和时间的限制, 本研究也存在一定的局限性: ①研究只选取了国内外各两种情报学期刊的论文, 样本的覆盖面还不够全面; ②Stanford CoreN⁃LP处理中文分词不够准确,导致句法分析存在不准确的情况,一定程度上影响了创新对象和创新维度的获取; ③定位创新章节关联时,由于所依据的文本是经过预处理的, 纯文本中图表都被清除,公式也有缺失或乱码的情况, 因此在检索系统中展示信息的还原性和完整性有待提高。
针对以上提到的研究局限性, 提出后续的研究工作展望: ①扩大样本选取的学科和期刊范围, 检验方法的普适性, 助力更广范围的创新点组织和检索; ②进一步完善创新句和相关章节的关联方法,提高检准率和检全率; ③考虑更广范围的多粒度创新内容关联, 打破篇章限制, 将不同论文的创新句、创新章节以某种机制进行关联, 形成知识图谱, 实现更强大的情报发现功能; ④将创新点组织和检索的整套流程集成到统一的系统, 或将创新内容的多粒度关联嵌入到已有学术信息检索系统, 并证明其可行性和有效性。
(责任编辑: 郭沫含)
