基于数字图像处理的物流分拣方法及系统*
2021-11-23庄志豪卢裕贵
王 敏,王 康,庄志豪,卢裕贵,孙 硕
(南京信息工程大学 电子与信息工程学院,江苏 南京210044)
0 引言
近几年,快递公司普遍使用电子面单,为快递面单的统一做出了重要贡献,可以极大促进物流分拣的自动化程度。基于数字图像处理的物流分拣主要是对快递面单的地址进行识别进而分拣分流至下一站点,可以降低人力成本,提高自动分拣效率[1-2]。
字符识别主要采用光学字符识别技术,其中数字识别常用的方式包括采用基于笔画特征以及多特征联合等[3-4]的方法,而汉字识别部分主要采用神经网络[5]。LeCun 及其同事于1989年发表了卷积神经网络的研究成果[6],经过三十多年的发展,卷积神经网络的结构不断增大,网络层数不断加深,处理能力不断增强。但在字符快速识别领域,模板匹配法因识别算法简单、在图像变化较小的情况下识别率高,仍占据一席之地。
在机器视觉的背景下,并响应建设“ 智慧+ 共享物流” 的需要,本文基于数字图像处理技术,提出了一种物流快速按址分拣方法,包括快递面单分割、快递面单地址区域定位以及地址字符识别三部分。并设计了实现系统,由固定机位的CCD 工业相机采集包裹图像传输到计算机进行识别,将识别到的地址信息传输到分拣机器,从而提高分拣效率。
1 基于数字图像处理的物流分拣方法
本方法主要包括快递面单预处理、地址信息区域定位和地址字符识别等环节,流程如图1 所示。

图1 算法流程图
1.1 图像预处理
为了减小数据量以加快字符识别速度,需要将原图像进行灰度化预处理。本文对采集到的RGB彩色包裹图像进行加权平均灰度化,得到人眼视觉感受较好的灰度图像,如图2 所示。其中灰度化计算公式为:
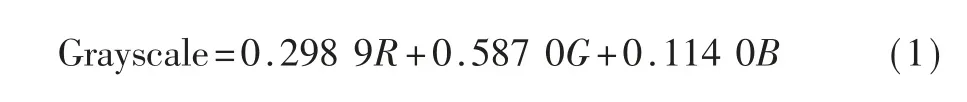

图2 灰度化结果
1.2 面单分割
模糊C 均值聚类算法(Fuzzy C - Means,FCM ) 是一种根据隶属度划分的聚类算法。其基本原理是将图像的所有像素划分为不同的类,使得同一类的像素之间的相似程度最高,不同类之间的相似程度最低。相比较普通C 均值算法对应图像数据的硬性划分,FCM 采用的是基于隶属度函数的柔性模糊划分[7-8]。模糊C 是一个不断迭代计算隶属度uij和簇中心cj的过程,直到目标函数(式(3)) 达到最优。
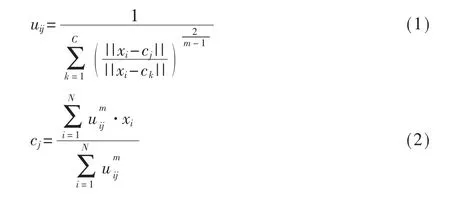
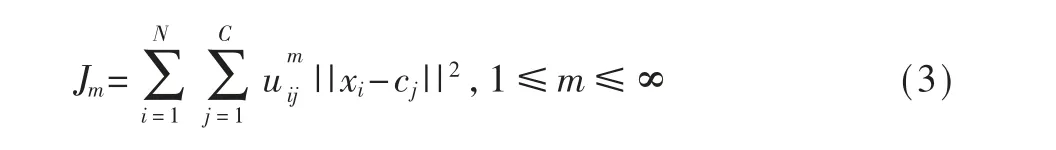
其中,m 是聚类的簇数;i,j 是类标号;uij表示样本xi属于j 类的隶属度。xi表示第i个样本,x 是具有d 维特征的一个样本。cj是j 簇的中心,||*|| 是欧几里得距离。单个样本xj对于每个簇的隶属度之和为1,即:

利用模糊C 均值算法将该灰度图像的每一个像素点按照最大隶属度划分为n个类,图3 所示为n 分别为2 、3 、4 时的处理效果,可以看出n 越大,类别就越多,效果更好,但相应的算法运行时间也越长,在一定程度上会降低算法效率。比较上述结果,同时考虑实际情况,当n =3 时图像处理结果较为理想,同时也比较符合语义,即将灰度化图像分别分为包裹背景颜色、快递面单底色和快递面单字迹颜色三个部分[9]。由于快递面单底色和快递面单字迹颜色截然相反,且快递面单字迹边框与快递面单边框极为靠近,因此无论包裹背景颜色与快递面单底色相近还是与快递面单字迹颜色相近,包裹背景颜色、快递面单底色和快递面单字迹颜色三者中至少有其一会与其他部分有明显区分,以此可以准确将快递面单分割出来。

图3 不同参数下的FCM 检测分割效果
1.3 边缘检测和直线检测
相对于其他边缘检测算子,Canny 算子的抗噪声性能和检测弱边缘的效果更好[10],因此本文使用Canny 算子进行边缘检测,得到快递面单的边缘信息,如图4(a) 所示。
霍夫变换将图像直角坐标空间转换到参数空间实现对不同形状的边缘进行检测[11-12]。以检测直线为例,设原图像为f(x,y),在其x-y 空间坐标上,其中一个点的坐标为(x0,y0),经过点(x0,y0) 的直线为:

其中,k 为直线的斜率,b 为截距。
过点(x0,y0) 的直线有无数条,对应有不同的斜率k 和截距b,将上式变换可得:

上式中,将x0和y0看成参数,b 和k 视为变量。这就完成了从坐标空间到参数空间的变换,即坐标空间内的一个点对应于参数空间的一条直线。对于坐标空间中所有经过直线y=kx+b 的点(xi,yi),其对应到参数空间就是所有经过点(k,b) 的直线。
对边缘检测图像进行Hough 变换运算,检测出图像中的直线。由于快递面单中的线段较多,且直线中各个信息区域的边框线段较为明显,同时该类直线角度都处于0°和90°附近,故遍历所有角度为-15°~15°以及75°~105°之间的直线,寻找出其中最长的线段,即可得到快递面单的边框,从而可以将快递面单单独切割出来进行处理,如图4(b) 所示。

图4 边缘和直线检测结果
1.4 直线检测和旋转切割
通过Hough 变换检测直线进行切割后得到的图像可能存在一定的倾斜,需要对图片进行一定的角度校正。通过Hough 变换得到直线的角度信息,对角度进行补偿,并通过双三次插值法完成图像旋转,如图5 所示。

图5 区域分割旋转以及校正图
1.5 地址信息区域定位和字符分割
再次对旋转修正后的图像进行Hough 变换,可以得到五条直线,该图像被切割成五个部分,如图6所示,只需要获取直线的位置就可以定位到感兴趣的收件地址区域。

图6 地址区域定位
如图7 所示,通过投影法可以准确定位到地址区域,并将单个地址字符分别分割出来,方便后续进行识别。
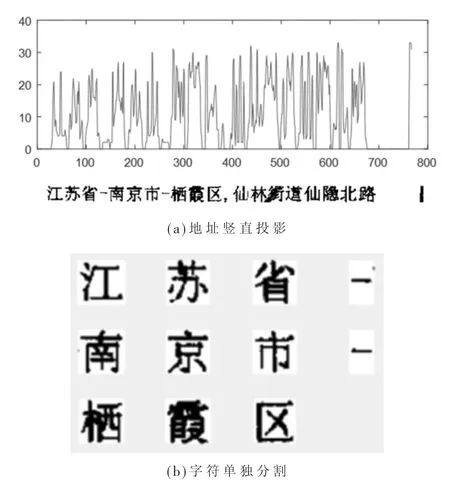
图7 地址竖直投影及字符单独分割图
1.6 地址信息识别
在地址信息识别中,分拣中心只需要识别出下一级地区的地址信息即可,同时电子面单的印刷字体一般较为标准,故在有限个地区中,可以采用模板匹配算法对地址信息进行识别[13-14]。具体步骤是: 将分割好的地址字符和准备好的模板进行归一化处理,对于每个待识别字符,遍历所有的标准库,并将重合度最高的标准库字符作为该输入待识别字符的识别结果。图8 为标准库中的部分字符。字符归一化处理后可能会出现模板字迹大小与面单地址字迹大小不一致的问题,进而影响后续匹配识别的结果。分别对模板和面单地址字迹通过膨胀和腐蚀进行形态学处理,如图9 所示,可以看出,膨胀后模板字迹图与面单地址字迹图像差距较小,故本文采用对模板字迹进行膨胀处理,最后采用模板匹配中的距离匹配识别算法对地址信息进行识别。

图8 标准库部分字符

图9 字迹处理结果
距离匹配识别是通过计算待识别样本的标准样本之间的距离来实现匹配的[15-16]。两幅图像的距离计算方法为: 对于待识别样本中的每一个白色像素点,在标准样本中找到与对应位置距离最近的白色像素点,计算两者的距离,遍历整幅图像后,得到所有距离的平均值即两幅图像之间的距离。设待识别样本为f (x,y),标准模板样本为g (x,y),fd(x,y) 为待识别样本的距离变换矩阵,gd(x,y) 为标准样本的距离变换矩阵。其中通过遍历整幅图像得到每个位置与其最近的白色像素点的距离的值构成该图像的距离变换矩阵,距离变换矩阵与原图像二维矩阵大小相同。两幅图像的距离D 越小说明其相似度越高。f 与g 的距离可用下式计算:
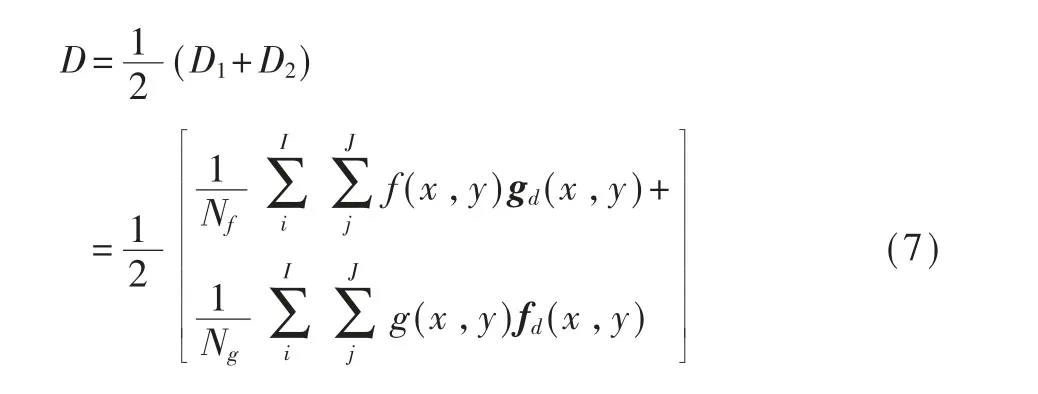
其中,Nf为f (x,y) 中前景点的数目,Ng为g (x,y) 中前景点的数目,I×J 为图像的大小。
2 系统实现
2.1 硬件系统
工业相机是物流分拣中的一个重要部分,如同人眼,承担原始数据采集的重要任务,并将拍照获取的图像转换为计算机可以处理的数字信号。
合适的光源是物流分拣系统提高可靠性和稳定性的重要因素之一。在物流自动分拣系统中,光源通过一定的角度进行照射,同时保持合适的光照强度,最理想的情况是成像可以明显区分快递面单和包裹以及背景,方便后续处理MATLAB 中快递面单的分割。LED 灯是常用且方便更换及安装的灯源,同时具有发热量低、性能稳定、功率消耗小、有效使用时长较长的特点。
本文采用CCD 工业相机对包裹图像进行采集,实际结构及连接如图10 所示。

图10 硬件系统结构
采集到的图像为彩色图像,光源为环形LDE灯,可减少过度曝光和环境偏暗对图像采集的影响。技术参数如下:
像素:300 万像素彩色;
分辨率:2048×153612 fps ;
镜头:6~12 mm 无畸变镜头;
支架: 万向调节支架;
光源: 环形LED 。
2.2 软件功能实现
本物流分拣系统软件部分采用MATLAB R2017a 实现,软件流程如图11 所示。

图11 软件流程图
软件运行可视化结果和时效测试如图12、图13 所示。可以看出,在MATLAB 中使用计数测时,经过多次测时,从图像输入到处理结果显示,总时长均为350 ms 左右,速度较快,较为符合实际运用场景。

图12 软件显示结果
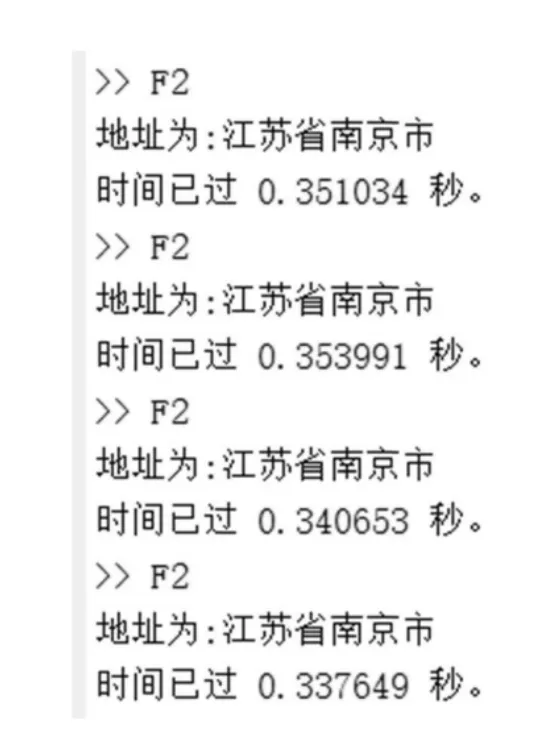
图13 软件时效测试结果
3 结论
本文针对快递分拣提出了一种基于数字图像处理技术的物流快速按址分拣方法,设计了实现系统,通过快递面单分割、快递面单地址区域定位以及地址字符识别等环节将快递面单上的地址自动识别出来,实验结果表明,该方法具有良好的识别效果和时效性。
